bigquery
In the previous post of BigQuery Explained series, we reviewed the high level architecture of BigQuery and showed how to get started with BigQuery. In this post, we will look at the BigQuery storage organization, storage format and introduce one of the best practices of BigQuery to partition and cluster your data for optimal performance. Let’s dive right into it!
在BigQuery Explained系列的上一篇文章中,我们回顾了BigQuery的高级体系结构,并展示了如何开始使用BigQuery。 在本文中,我们将介绍BigQuery的存储组织,存储格式,并介绍BigQuery的最佳实践之一,以对数据进行分区和群集以实现最佳性能。 让我们开始吧!
BigQuery资源模型 (BigQuery Resource Model)
BigQuery organizes data tables into units called datasets. These datasets are scoped to your GCP project. These multiple scopes — project, dataset, and table — helps you structure your information logically. You can use multiple datasets to separate tables pertaining to different analytical domains, and you can use project-level scoping to isolate datasets from each other according to your business needs.
BigQuery将数据表组织到称为数据集的单元中。 这些数据集适用于您的GCP项目。 这些多个范围(项目,数据集和表)可帮助您从逻辑上构造信息。 您可以使用多个数据集来分离与不同分析域相关的表,并且可以使用项目级作用域来根据业务需要将数据集彼此隔离。
Projects
专案
- Root namespace for objects 对象的根名称空间
- Contain multiple datasets, jobs, access control lists and IAM roles 包含多个数据集,作业,访问控制列表和IAM角色
- Control billing, users, and user privileges 控制帐单,用户和用户权限
Datasets
数据集
- Collections of “related” tables/views together with labels and description “相关”表/视图的集合以及标签和描述
- Allow storage access control at Dataset level 允许在数据集级别进行存储访问控制
- Define location of data i.e. multi-regional (US, EU) or regional (asia-northeast1) 定义数据位置,即多区域(美国,欧盟)或区域(亚洲东北地区)
Tables
桌子
- Collections of columns and rows stored in managed storage 存储在托管存储中的列和行的集合
- Defined by a schema with strongly-typed columns of values 由具有强类型值列的架构定义
Allow access control at Table level and Column level
允许在表级别和列级别进行访问控制
Views
观看次数
- Virtual tables defined by a SQL query 由SQL查询定义的虚拟表
- Allow access control at View level 允许在视图级别进行访问控制
Jobs
工作
- Actions run by BigQuery on your behalf — load data, export data, copy data, or query data BigQuery代表您运行的操作-加载数据,导出数据,复制数据或查询数据
- Jobs are executed asynchronously 作业异步执行
When you reference a table from the command line, in SQL queries, or in code, you refer to it by using the following construct: project.dataset.table.
当您从命令行,SQL查询或代码中引用表时,可以使用以下结构来引用该表: project.dataset.table 。
仓储管理 (Storage Management)
Now let’s review how BigQuery manages the storage that holds your data. Traditional relational databases, like MySQL, store data row-by-row (record-oriented storage). This makes them good at transactional updates and OLTP (Online Transaction Processing) use cases. BigQuery, on the other hand, uses columnar storage, where each column is stored in a separate file block. This makes BigQuery an ideal solution for OLAP (Online Analytical Processing) use cases. You can stream (append) data easily to BigQuery tables and update or delete existing values. BigQuery supports mutations (INSERT, UPDATE, MERGE, DELETE) without limits.
现在,让我们回顾一下BigQuery如何管理保存数据的存储。 传统的关系数据库(如MySQL)逐行存储数据( 面向记录的存储 )。 这使他们擅长事务更新和OLTP (在线事务处理)用例。 另一方面,BigQuery使用列存储,其中每一列存储在单独的文件块中。 这使BigQuery成为OLAP (在线分析处理)用例的理想解决方案。 您可以轻松地将数据流式传输(追加)到BigQuery表中,并更新或删除现有值。 BigQuery 支持无限制的变异 (INSERT,UPDATE,MERGE,DELETE)。
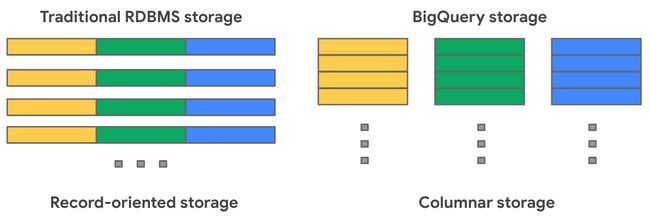
BigQuery uses variations and advancements on columnar storage. Internally, BigQuery stores data in a proprietary columnar format called Capacitor, which has a number of benefits for data warehouse workloads. BigQuery uses a proprietary format because the storage engine can evolve in tandem with the query engine, which takes advantage of deep knowledge of the data layout to optimize query execution. Each column in the table is stored in a separate file block and all the columns are stored in a single capacitor file, , which are compressed and encrypted on disk. BigQuery uses query access patterns to determine the optimal number of physical shards and how data is encoded.
BigQuery使用列式存储的变体和改进。 在内部,BigQuery以专有的列格式(称为Capacitor)存储数据,这对数据仓库工作负载有很多好处。 BigQuery使用专有格式,因为存储引擎可以与查询引擎一起发展,这利用了对数据布局的深入了解来优化查询执行。 表中的每一列都存储在一个单独的文件块中,所有列都存储在一个电容器文件中,该文件在磁盘上进行了压缩和加密。 BigQuery使用查询访问模式来确定最佳物理碎片数量以及如何编码数据。

The actual persistence layer is provided by Google’s distributed file system, Colossus, where data is automatically compressed, encrypted, replicated, and distributed. Colossus ensures durability using erasure encoding to store redundant chunks of data on multiple physical disks. This is all accomplished without impacting the computing power available for your queries. Separating storage from compute allows you to scale to petabytes in storage seamlessly, without requiring additional expensive compute resources. There are a number of other benefits of decoupling compute and storage.
实际的持久层由Google的分布式文件系统Colossus提供 ,该系统中的数据会自动压缩,加密,复制和分发。 Colossus使用擦除编码将冗余数据块存储在多个物理磁盘上,从而确保了持久性。 在不影响查询可用计算能力的情况下,所有这些都可以实现。 将存储与计算分开,使您可以无缝扩展至PB级,而无需其他昂贵的计算资源。 解耦计算和存储还有许多其他好处 。
利用长期存储 (Take Advantage of Long-Term Storage)
You can load data into BigQuery at no cost (for batch loads) because BigQuery storage costs are based on the amount of data stored (first 10 GB is free each month) and whether storage is considered active or long-term.
您可以免费 (大批量加载)将数据加载到BigQuery中,因为BigQuery的存储成本取决于存储的数据量(每月前10 GB可用),以及存储是活动的还是长期的。
- If you have a table or partition modified in the last 90 days, it is considered as active storage and incurs a monthly charge for data stored at BigQuery storage rates. 如果您在过去90天内修改了表或分区,则该表或分区将被视为活动存储,并且会每月按BigQuery存储速率存储数据。
If you have a table or partition that is not modified for 90 consecutive days, it is considered long term storage and the price of storage for that table automatically drops by 50% to the same cost as Cloud Storage Nearline. Discount is applied on a per-table, per-partition basis. If you modify the data in the table, the 90-day counter resets.
如果您有连续90天未修改的表或分区,则该表或分区被视为长期存储,该表的存储价格自动下降50% , 降至与Cloud Storage Nearline相同的成本。 折扣基于每个表,每个分区进行。 如果您修改表中的数据,则90天计数器将重置。

A best practice when optimizing costs is to keep your data in BigQuery. Rather than exporting your older data to another storage option (such as Cloud Storage), take advantage of BigQuery’s long-term storage pricing. This means not having to delete old data or architect a data archival process. Since the data remains in BigQuery, you can also query older data using the same interface, at the same cost levels, with the same performance characteristics.
优化成本的最佳做法是将数据保留在BigQuery中。 无需将旧数据导出到其他存储选项(例如Cloud Storage),而是利用BigQuery的长期存储价格。 这意味着不必删除旧数据或设计数据归档过程。 由于数据保留在BigQuery中,因此您也可以使用相同的接口,相同的成本级别和相同的性能特征来查询较旧的数据。
分区和聚类 (Partitioning and Clustering)
Keeping data in BigQuery is a best practice if you’re looking to optimize both cost and performance. Another best practice is using BigQuery’s table partitioning and clustering features to structure your data to match common data access patterns.
如果您想同时优化成本和性能,则将数据保存在BigQuery中是一种最佳做法。 另一个最佳做法是使用BigQuery的表分区和集群功能来组织数据,以匹配常见的数据访问模式。
分区 (Partitioning)
A partitioned table is a special table that is divided into segments, called partitions, that make it easier to manage and query your data. You can typically split large tables into many smaller partitions using data ingestion time or TIMESTAMP/DATE column or an INTEGER column. BigQuery’s decoupled storage and compute architecture leverages column-based partitioning simply to minimize the amount of data that slot workers read from disk. Once slot workers read their data from disk, BigQuery can automatically determine more optimal data sharding and quickly repartition data using BigQuery’s in-memory shuffle service.
分区表是一种特殊的表,分为几部分,称为分区,使您可以更轻松地管理和查询数据。 通常,您可以使用数据提取时间或TIMESTAMP / DATE列或INTEGER列将大表分成许多较小的分区。 BigQuery的分离式存储和计算体系结构利用基于列的分区来最大限度地减少插槽工作人员从磁盘读取的数据量。 老虎机工作人员从磁盘读取数据后,BigQuery可以使用BigQuery的内存随机播放服务自动确定更多最佳数据分片并快速重新分区数据。
Data written to a column-based time partitioned table is automatically delivered to the appropriate partition based on the value of the data. Similarly, queries that express filters on the partitioning column can reduce the overall data scanned, which can yield improved performance and reduced query cost for on-demand queries.
写入基于列的时间分区表中的数据将根据数据的值自动传递到适当的分区。 同样,在分区列上表示过滤器的查询可以减少扫描的总体数据,从而可以提高性能并降低按需查询的查询成本。
BigQuery supports following ways to create partitioned tables
BigQuery支持以下创建分区表的方法
Ingestion time partitioned tables
摄取时间分区表
- Partitioned on the data’s ingestion time or arrival time. 根据数据的获取时间或到达时间进行分区。
- BigQuery automatically loads data into daily, date based partitions reflecting the data’s ingestion or arrival time. BigQuery会自动将数据加载到基于日期的每日分区中,以反映数据的摄取或到达时间。
BigQuery adds two pseudo columns to ingestion-time partitioned tables — a
_PARTITIONTIMEpseudo column containing a date-based timestamp for data and a_PARTITIONDATEpseudo column contains a date representation.BigQuery向摄取时间分区表中添加了两个伪列
_PARTITIONTIME伪列包含用于数据的基于日期的时间戳,而_PARTITIONDATE伪列包含日期表示。
DATE/TIMESTAMPcolumn partitioned tables
DATE/TIMESTAMP列分区表
Partitioned based on a
TIMESTAMPorDATEcolumn.根据
TIMESTAMP或DATE列进行分区。- BigQuery routes data to the appropriate partition based on the date value (expressed in UTC) in the partitioning column. BigQuery根据分区列中的日期值(以UTC表示)将数据路由到相应的分区。
BigQuery creates two special partitions: the
__NULL__partition for capturing rows NULL values in the partitioning column and the__UNPARTITIONED__partition for data outside the allowed range of dates.BigQuery创建了两个特殊的分区:
__NULL__分区,用于捕获分区列中的行NULL值;以及__UNPARTITIONED__分区,用于允许的日期范围之外的数据。- You can create partitions with granularity starting from hourly partitioning. 您可以从每小时分区开始创建具有粒度的分区。
INTEGERrange partitioned tables
INTEGER范围分区表
- Partitioned based on an integer column with start, end, and interval values. 根据具有开始,结束和间隔值的整数列进行分区。
BigQuery creates two special partitions: the
__NULL__partition for capturing rows NULL values in the partitioning column and the__UNPARTITIONED__partition for data outside the allowed range of integers.BigQuery创建两个特殊的分区:
__NULL__分区,用于捕获分区列中的行NULL值;以及__UNPARTITIONED__分区,用于允许的整数范围之外的数据。
Let’s look at partitioning in action. To see the difference in performance between a non-partitioned and a partitioned table, we will create non-partitioned and partitioned tables with the same dataset and check the query performance.
让我们看一下实际的分区。 要查看未分区表和分区表之间的性能差异,我们将创建具有相同数据集的未分区表和分区表,并检查查询性能。
分区之前 (Before Partitioning)
By running the following SQL query, we will create a non-partitioned table with data loaded from a public data set based on StackOverflow posts by creating a new table from an existing table. This table will contain the StackOverflow posts created in 2018.
通过运行以下SQL查询,我们将通过从现有表创建一个新表 ,来创建一个非分区表,并从基于StackOverflow帖子的公共数据集中加载数据 。 该表将包含2018年创建的StackOverflow帖子。
CREATE OR REPLACE TABLE `stackoverflow.questions_2018` AS
SELECT *
FROM `bigquery-public-data.stackoverflow.posts_questions`
WHERE creation_date BETWEEN '2018-01-01' AND '2018-07-01'Let’s query the non-partitioned table to fetch all StackOverflow questions tagged with ‘android’ in the month of January 2018.
让我们查询未分区的表以获取2018年1月所有标记有'android'的StackOverflow问题。
SELECT
id,
title,
body,
accepted_answer_id,
creation_date,
answer_count,
comment_count,
favorite_count,
view_count
FROM
`stackoverflow.questions_2018`
WHERE
creation_date BETWEEN '2018-01-01' AND '2018-02-01'
AND tags = 'android';Before the query runs, caching is disabled to be fair when comparing performance with partitioned and clustered tables.
在查询运行之前,在与分区表和集群表进行性能比较时,为了公平起见, 禁用了缓存 。
From the query results, you can see that the query on a non-partitioned table took 5.6s to scan the entire 3.2GB of data with StackOverflow posts created in 2018.
从查询结果中可以看到,对非分区表的查询花费了5.6秒的时间来扫描 2018年创建的StackOverflow帖子的整个3.2GB数据 。
分区表 (Partition the Table)
Now let’s see whether partitioned tables can do better. You can create partitioned tables in multiple ways. We will create a DATE/TIMESTAMP partitioned table using BigQuery DDL statements. We chose the partitioning column as creation_date based on the query access pattern.
现在,让我们看看分区表是否可以做得更好。 您可以通过多种方式创建分区表。 我们将使用BigQuery DDL语句创建一个DATE / TIMESTAMP分区表。 我们根据查询访问模式将分区列选择为creation_date 。
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_partitioned`
PARTITION BY
DATE(creation_date) AS
SELECT
*
FROM
`bigquery-public-data.stackoverflow.posts_questions`
WHERE
creation_date BETWEEN '2018-01-01' AND '2018-07-01';Now let’s run the previous query on the partitioned table, with cache disabled, to fetch all StackOverflow questions tagged with ‘android’ in the month of January 2018.
现在让我们在分区表上运行上一个查询, 并禁用缓存 ,以获取2018年1月所有标记为'android'的StackOverflow问题。
SELECT
id,
title,
body,
accepted_answer_id,
creation_date,
answer_count,
comment_count,
favorite_count,
view_count
FROM
`stackoverflow.questions_2018_partitioned`
WHERE
creation_date BETWEEN '2018-01-01' AND '2018-02-01'
AND tags = 'android';With partitioned table query scanned only the required partitions in <2s processing ~290MB data compared to query running with non-partitioned table processing 3.2GB.
与使用 3.2GB的未分区表运行的查询相比, 使用分区表查询仅扫描<2s所需的分区即可处理约290MB数据 。
Partition management is key to fully maximizing BigQuery performance and cost when querying over a specific range — it results in scanning less data per query, and pruning is determined before query start time. While partitioning reduces cost and improves performance, it also prevents cost explosion due to user accidentally querying really large tables in entirety.
在特定范围内进行查询时,分区管理是完全最大化BigQuery性能和成本的关键-它导致每个查询的扫描数据更少,并且在查询开始之前就确定了修剪。 分区不仅可以降低成本并提高性能,而且还可以防止由于用户意外查询整个大型表而导致的成本激增。
Tip: You can control and optimize storage costs by configuring table expiration to remove unneeded tables and partitions.
提示:您可以通过配置表过期以删除不需要的表和分区来控制和优化存储成本。
Learn more about partitioned tables here.
在此处 了解有关分区表的更多信息 。
聚类 (Clustering)
When a table is clustered in BigQuery, the table data is automatically organized based on the contents of one or more columns in the table’s schema. The columns you specify are used to collocate related data. Usually high cardinality and non-temporal columns are preferred for clustering.
在BigQuery中对表格进行聚类时,表格数据将根据表格架构中一个或多个列的内容自动进行组织。 您指定的列用于并置相关数据。 通常,最好使用高基数列和非时间列进行聚类。
When data is written to a clustered table, BigQuery sorts the data using the values in the clustering columns. These values are used to organize the data into multiple blocks in BigQuery storage. The order of clustered columns determines the sort order of the data. When new data is added to a table or a specific partition, BigQuery performs automatic re-clustering in the background to restore the sort property of the table or partition. Auto re-clustering is completely free and autonomous for the users.
将数据写入群集表后,BigQuery会使用群集列中的值对数据进行排序。 这些值用于将数据组织到BigQuery存储中的多个块中。 聚簇列的顺序决定了数据的排序顺序。 将新数据添加到表或特定分区时,BigQuery在后台执行自动重新聚类以恢复表或分区的sort属性。 自动重新群集对于用户是完全免费和自主的。

Clustering can improve the performance of certain types of queries, such as those using filter clauses and queries aggregating data.
群集可以提高某些类型的查询的性能,例如使用过滤器子句和聚合数据的查询。
- When a query containing a filter clause filters data based on the clustering columns, BigQuery uses the sorted blocks to eliminate scans of unnecessary data. 当包含filter子句的查询根据聚类列过滤数据时,BigQuery使用排序的块来消除对不必要数据的扫描。
- When a query aggregates data based on the values in the clustering columns, performance is improved because the sorted blocks collocate rows with similar values. 当查询基于聚类列中的值聚合数据时,由于排序的块将具有相似值的行并置在一起,因此性能得到了改善。
BigQuery supports clustering over both partitioned and non-partitioned tables. When you use clustering and partitioning together, your data can be partitioned by a DATE or TIMESTAMP column and then clustered on a different set of columns (up to four columns).
BigQuery支持在分区表和非分区表上进行集群。 当同时使用群集和分区时,可以通过DATE或TIMESTAMP列对数据进行分区,然后将其群集在一组不同的列(最多四列)上。
Coming back to the previous query, let’s find out how the query with clustered table performs.
回到上一个查询,让我们找出带有聚簇表的查询的性能。
聚簇表 (Cluster the Table)
You can create clustered tables in multiple ways. We will create a new DATE/TIMESTAMP partitioned and clustered table using BigQuery DDL statements. We chose the partitioning column as creation_date and cluster key as tag based on the query access pattern.
您可以通过多种方式创建集群表。 我们将使用BigQuery DDL语句创建一个新的DATE / TIMESTAMP分区和群集表。 根据查询访问模式,我们选择分区列作为creation_date ,将集群键作为tag 。
CREATE OR REPLACE TABLE `stackoverflow.questions_2018_clustered`
PARTITION BY
DATE(creation_date)
CLUSTER BY
tags AS
SELECT
*
FROM
`bigquery-public-data.stackoverflow.posts_questions`
WHERE
creation_date BETWEEN '2018-01-01' AND '2018-07-01';Now let’s run the query on the partitioned and clustered table, with cache disabled, to fetch all StackOverflow questions tagged with ‘android’ in the month of January 2018.
现在让我们在分区表和群集表上运行查询, 并禁用缓存 ,以获取2018年1月所有标记为'android'的StackOverflow问题。
SELECT
id,
title,
body,
accepted_answer_id,
creation_date,
answer_count,
comment_count,
favorite_count,
view_count
FROM
`stackoverflow.questions_2018_clustered`
WHERE
creation_date BETWEEN '2018-01-01'
AND '2018-02-01'
AND tags = 'android';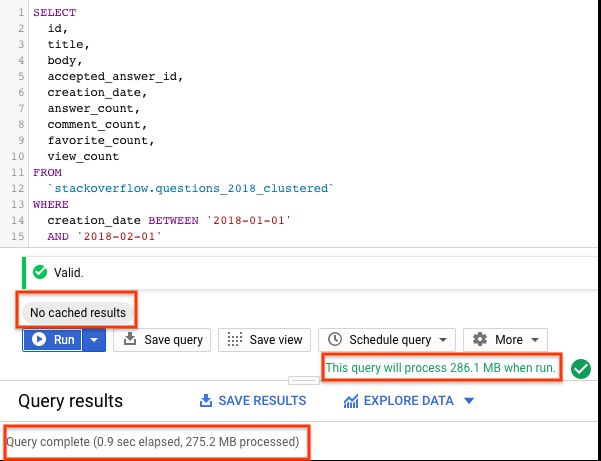
With a partitioned and clustered table, the query scanned ~275MB of data in less than 1s, which is better than a partitioned table. The way data is organized by partitioning and clustering minimizes the amount of data scanned by slot workers thereby improving query performance and optimizing costs.
使用分区表和群集表时,查询在不到1秒的时间内扫描了约275MB的数据,这比分区表要好。 通过分区和群集组织数据的方式可最大程度地减少插槽工作人员扫描的数据量,从而提高查询性能并优化成本。
Few things to note when using clustering:
使用集群时要注意的几点:
- Clustering does not provide strict cost guarantees before running the query. Notice in the results above with clustering, query validation reported processing of 286.1MB but actually query processed only 275.2MB of data. 在运行查询之前,群集不提供严格的成本保证。 请注意,在上面的群集结果中,查询验证报告的处理量为286.1MB,但实际上查询仅处理了275.2MB的数据。
- Use clustering only when you need more granularity than partitioning alone allows. 仅当您需要比单独分区允许更多的粒度时,才使用群集。
Learn more about working with clustered tables here.
在此处 了解有关使用聚簇表的更多信息 。
接下来是什么? (What Next?)
In this article, we learned how BigQuery organizes and manages storage holding the data, how you can improve query performance by partitioning and clustering the tables, and how you can retain data in BigQuery with long-term storage pricing for inactive data.
在本文中,我们了解了BigQuery如何组织和管理保存数据的存储,如何通过对表进行分区和集群化来提高查询性能,以及如何以对非活动数据的长期存储定价在BigQuery中保留数据。
Check out demo on Partitioning and Clustering with BigQuery
查看有关使用BigQuery进行分区和集群的演示
Learn when to use clustering and partitioning
了解何时使用群集和分区
Codelab to try BigQuery partitioning and clustering on your BigQuery Sandbox
Codelab在您的BigQuery沙盒上尝试BigQuery分区和集群
In the next post, we will look at how you can ingest data into BigQuery and analyze the data.
在下一篇文章中,我们将研究如何将数据提取到BigQuery中并分析数据。
Stay tuned. Thank you for reading! Have a question or want to chat? Find me on Twitter or LinkedIn.
敬请关注。 感谢您的阅读! 有问题或想聊天? 在Twitter或LinkedIn上找到我。
Thanks to Yuri Grinshsteyn and Alicia Williams for helping with the post.
感谢 Yuri Grinshsteyn 和 Alicia Williams 为这个职位提供的帮助。
翻译自: https://medium.com/google-cloud/bigquery-explained-storage-overview-70cac32251fa
bigquery