python Django 之 DRF(三)序列化的使用、源码分析
文章目录
- 前言
- 一、序列化的使用
-
- 1.序列化Serializer类的使用
- 2.序列化ModelSerializer类的使用
- 二、序列化源码分析
-
- 1.序列化参数源码
- 2.序列化源码总结
前言
在上篇的文章中,我们讲到了(DRF)django rest framework框架的源码、内置类、以及RESTful规范的规范、版本、解析器的使用方法,那么在本章中,还存在着序列化的操作、分页、视图、路由、渲染器。
而序列化的操作类似FORM表单验证,根据用户在数据库中的名字,来获取相应的值。并且通过继承相关内置类也可以进行表单验证的操作、钩子操作以及路由获取等等…
在我们通过models获取所有参数的时候,返回的结果为QuerySet对象(当然可以通过values_list),而该对象不能直接的通过json格式化,使得我们在传递数据的时候需要自己将其拆分成字符串后在json格式化,非常的麻烦,而DRF框架中其实就有将格式序列化的操作。
一、序列化的使用
使用前,我们需创建一个数据库表,models.py如下:
from django.db import models
from django.db import models
class UserGroup(models.Model):
title = models.CharField(max_length=32)
# Create your models here.
class UserInfo(models.Model):
user_type_choices = (
(1, '普通用户'),
(2, 'VIP'),
(3, 'SVIP'),
)
user_type = models.IntegerField(choices=user_type_choices)
group = models.ForeignKey("UserGroup", models.CASCADE)
username = models.CharField(max_length=32, unique=True)
password = models.CharField(max_length=64)
roles = models.ManyToManyField("Role")
class UserToken(models.Model):
user = models.OneToOneField(to="UserInfo", on_delete=models.CASCADE)
token = models.CharField(max_length=64)
class Role(models.Model):
title = models.CharField(max_length=32)
可以看到我们创建了四个表,而这四个表分别是:
- UserInfo用户登录信息表(
关联着UserGroup表、Role表) - UserGroup用户组信息表(
存放用户信息,这里就存放个名字) - UserToken用户认证表(
存放用户登录后的唯一标识,关联着UserInfo表) - Role角色表(
存放用户担任的角色)
创建好数据库后,我们在数据中插入一些值,插入数据如下:
Role表数据如下:
| id | title |
|---|---|
| 1 | 护士 |
| 2 | 老师 |
| 3 | 码农 |
| 4 | 老板 |
| 5 | 军人 |
| 6 | 农民 |
UserInfo表数据如下:
| id | user_type | username | password | group_id |
|---|---|---|---|---|
| 1 | 3 | cyy | 123 | 1 |
| 2 | 1 | cjy | 123 | 2 |
ManyToManyField关联表(UserInfo和Role关联)如下:
| id | userinfo_id | role_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 6 |
UserGroup表数据如下:
| id | title |
|---|---|
| 1 | 陈熠仪 |
| 2 | 陈君羊 |
1.序列化Serializer类的使用
插入完毕后我们添加url到路由上。
urls.py如下:
from django.urls import path
from api import views
urlpatterns = [
path('user/', views.UserInfoView.as_view()),
]
在视图中定义UserInfoView函数、以及序列化定义函数,并且继承于rest_framework的serializers类中。
views.py如下:
from django.shortcuts import render, HttpResponse
from rest_framework import serializers
from rest_framework.views import APIView
from api import models
import json
class UserInfoSerializer(serializers.Serializer):
username = serializers.CharField()
password = serializers.CharField()
user_type = serializers.IntegerField()
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = models.UserInfo.objects.all()
ser = UserInfoSerializer(instance=users, many=True)
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
该操作的流程大致是定义了一个serializers验证类,获取两个对象username、password、user_type (名字必须和数据库中定义的一样)。
通过get请求中的users向数据库获取用户表中所有数据后,将值传入给UserInfoSerializer类中(继承serializers.Serializer)的instance对象,之后many=True表示返回的对象是多个的,之后将返回参数传给ser,ser在调用data参数并将其json格式化,在返回。
此时访问http://127.0.0.1:8000/user/显示:

可以发现,返回的数据通过serializers类转化为了这三个数据,那么我现在如果想通过用户表的用户类型id来获取用户类型的名字,该怎么做呢?
在serializers.Serializer类中,我们可以在定义类型的时候可以在定义类型的时候加上一个source对象,该对象可以根据用户返回的是一个对象或是一个函数进行判断,此时如果定义了source对象后,定义的名字就可以不用和数据库中名字对应了。
views.py如下:
from django.shortcuts import render, HttpResponse
from rest_framework import serializers
from rest_framework.views import APIView
from api import models
import json
class UserInfoSerializer(serializers.Serializer):
username = serializers.CharField()
password = serializers.CharField()
xxx = serializers.CharField(source="get_user_type_display")
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = models.UserInfo.objects.all()
ser = UserInfoSerializer(instance=users, many=True)
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
可以看到,类型从int转化为CharField,因为我们需要获取的时用户类型名字,且我们定义serializers.Serializer类的对象时,通过source对象也不用根据数据库中指定的名字去定义了,内部就会根据get_user_type_display来获取对象了。
此时访问http://127.0.0.1:8000/user/显示:

可以看到,用户类型、用户组名数据正常显示,而通过我们serializers.Serializer类中自定义的xxx也成为了用户类型数据中的key值,并且也通过.的方式也获取到该数据相关联的其他用户信息了。
那我们现在如果想通过与UserInfo表向关联的UserToken表获取roles的值,之后通过roles.all获取Role表的所有对象信息,这该怎么做?
显然通过source一层一层的获取是做不到了,那么我们也可以通过serializers类中的SerializerMethodField函数来实现,该函数的使用方法是(截取之前的数据,通过自定义函数的方法返回给该函数(没返回为null),而自定义函数的前面必须以get_对象开头,且函数对象第一个参数是当前instance传入的对象)。
views.py如下:
from django.shortcuts import render, HttpResponse
from rest_framework import serializers
from rest_framework.views import APIView
from api import models
import json
class UserInfoSerializer(serializers.Serializer):
username = serializers.CharField()
password = serializers.CharField()
xxx = serializers.CharField(source="get_user_type_display")
gp = serializers.CharField(source="group.title")
rls = serializers.SerializerMethodField()
def get_rls(self, row):
role_obj_list = row.roles.all()
ret = []
for item in role_obj_list:
ret.append({
'id': item.id, 'title': item.title})
return ret
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = models.UserInfo.objects.all()
ser = UserInfoSerializer(instance=users, many=True)
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
可以看到该方法通过get_rls函数,获取了roles的对象并赋值给role_obj_list,在设置ret为[]遍历role_obj_list获取(当前用户对象关联的角色信息数据),之后在返回。
此时访问http://127.0.0.1:8000/user/显示:

可以看到每个用户对应关联的角色表的值也通过继承serializers.SerializerMethodField()的方式展示出来了。
既然我们之前提到过序列化的操作类似FORM表单验证那么它是否也同样有验证规则、is_valid、报错异常、自定义字段、钩子函数呢?
没错,在继承serializers.SerializerMethodField()中的返回值,是有该方法的,而且除了钩子函数(通过validate_字段名)不同,其他的使用方法都和Form表单一样。
根据我们之前学过的版本和获取URL的配置,我们可以通过自定义路由的方式来实现,通过获取路由上的id来展示对应的用户的数据。
settings.py如下:
REST_FRAMEWORK = {
"DEFAULT_VERSION": 'v1',
"ALLOWED_VERSIONS": ['v1', 'v2'],
"VERSION_PARAM": 'version',
"DEFAULT_VERSIONING_CLASS": "rest_framework.versioning.URLPathVersioning"
}
urls.py如下:
from django.urls import path, re_path
from api import views
urlpatterns = [
path('user/', views.UserInfoView.as_view()),
re_path(r'user/(?P[v1|v2]+)/group/' , views.UserGroupView.as_view()),
]
views.py如下:
from django.shortcuts import render, HttpResponse
from rest_framework import serializers
from rest_framework.views import APIView
from api import models
import json
# 自定义验证规则
class CustomField(object):
def __init__(self, base):
self.base = str(base)
def __call__(self, value):
# 判断value不是否以base的参数开头
if not value.startswith(self.base):
message = "标题必须以%s为开头" % self.base
raise serializers.ValidationError(message)
# 验证之前会先走的字段
def set_context(self, serializer_field):
pass
class UserGroupSerializer(serializers.Serializer):
title = serializers.CharField(error_messages={
'required': '标题不能为空'}, validators=[CustomField('哈哈哈')])
def validate_title(self, value):
return value + 'cyy'
class UserGroupView(APIView):
def post(self, request, *args, **kwargs):
ser = UserGroupSerializer(data=request.data)
ret = {
}
if ser.is_valid():
ret = ser.validated_data
else:
ret = ser.errors
return HttpResponse(ret.get('title'))
此时访问http://127.0.0.1:8000/user/v1/group/如下:
可以看到通过验证规则,错误信息以及正确的信息都打印出来了。
2.序列化ModelSerializer类的使用
而在DRF框架中,还有一个帮我们封装好的内置函数serializers.ModelSerializer()类,该类方法继承于Serializer类,且类似于Django中的ModelForm验证,定义的规则也是类似的。
所以我们如果想通过自定义的方式写一个字段类,我们也同样可以通过继承其他字段的方式来进行重写、封装该字段类。
views.py如下:
from django.shortcuts import render, HttpResponse
from rest_framework import serializers
from rest_framework.views import APIView
from api import models
import json
class UserInfoModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserInfo
fields = "__all__"
depth = 1
class UserInfoSerializer(serializers.Serializer):
username = serializers.CharField()
password = serializers.CharField()
xxx = serializers.CharField(source="get_user_type_display")
gp = serializers.CharField(source="group.title")
rls = serializers.SerializerMethodField()
def get_rls(self, row):
role_obj_list = row.roles.all()
ret = []
for item in role_obj_list:
ret.append({
'id': item.id, 'title': item.title})
return ret
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = models.UserInfo.objects.all()
ser = UserInfoModelSerializer(instance=users, many=True)
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
此时访问获取到的数据就是UserInfo表中的所有数据了,不过如果我们不想获取全部数据,也可以通过fields来设置想获取的字段,且同样也是可以自定义一个字段类,之后将自定义字段类放入fields列表中即可。
而这个depth 则为从数据库中查找的深度(一般设置深度最多到1-4就可以了,太多效率不高),类似递归查询,查找该表是否有关联字段,然后将关联字段展示。
此时我们访问http://127.0.0.1:8000/user/如下:
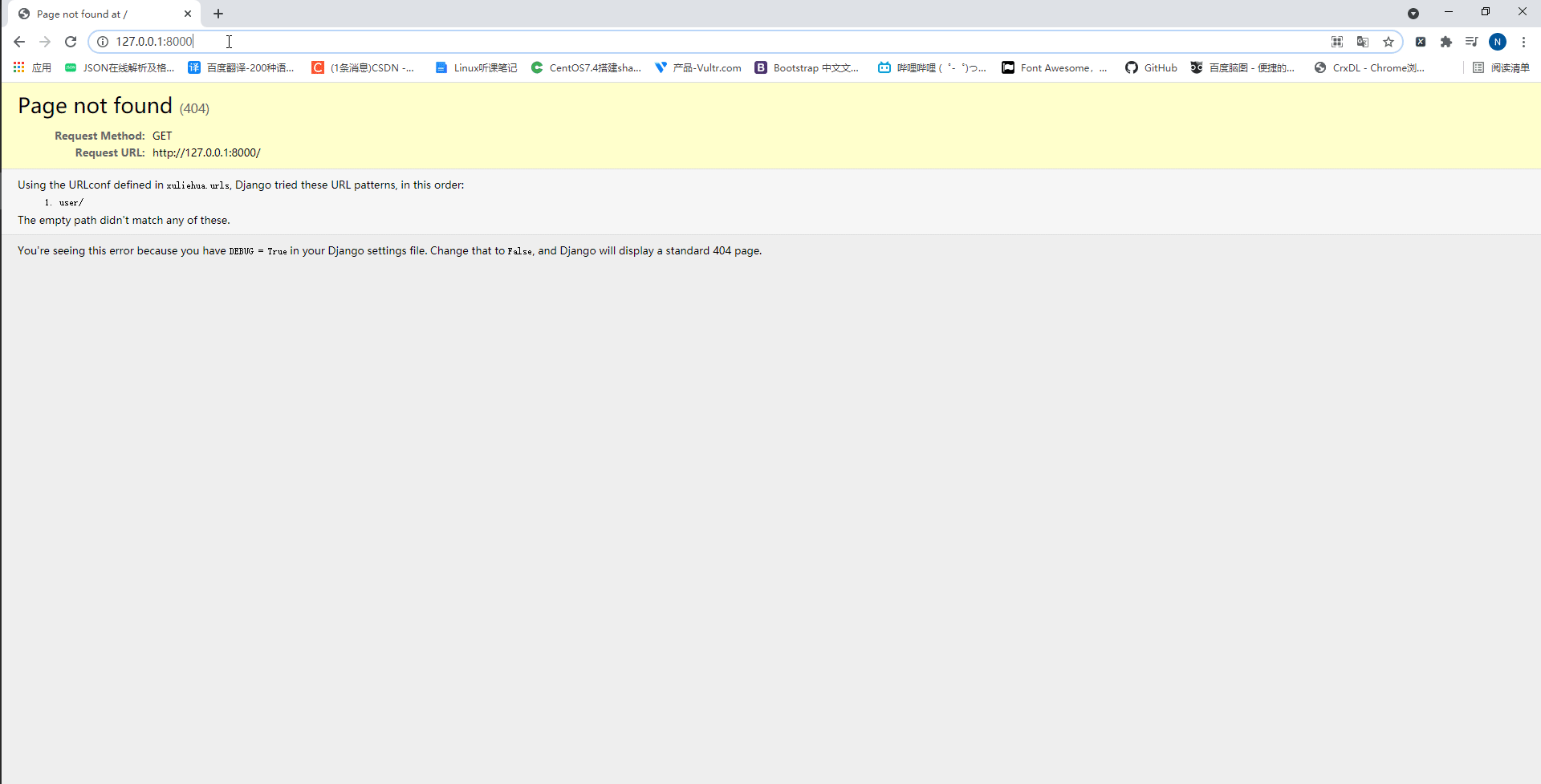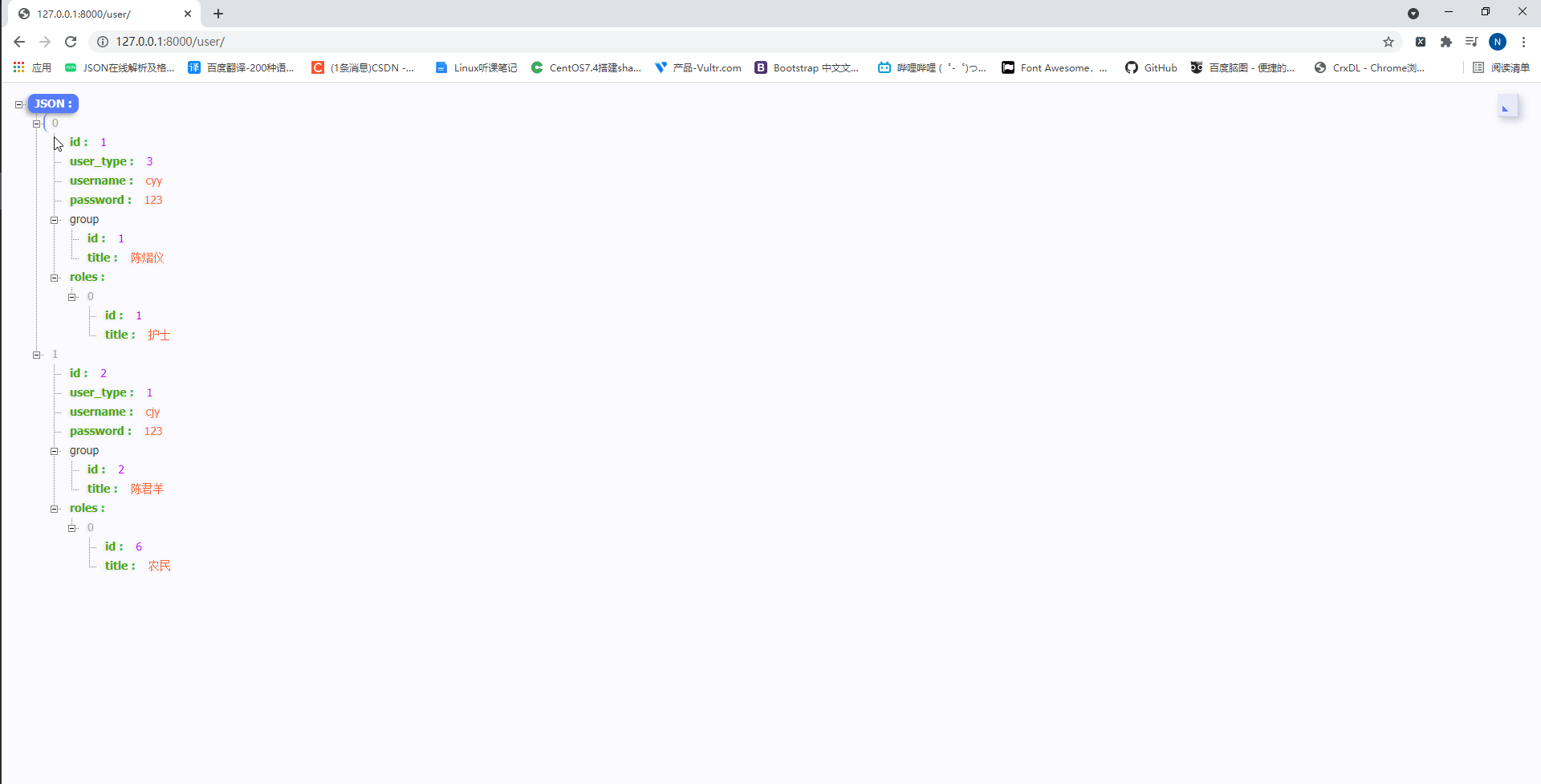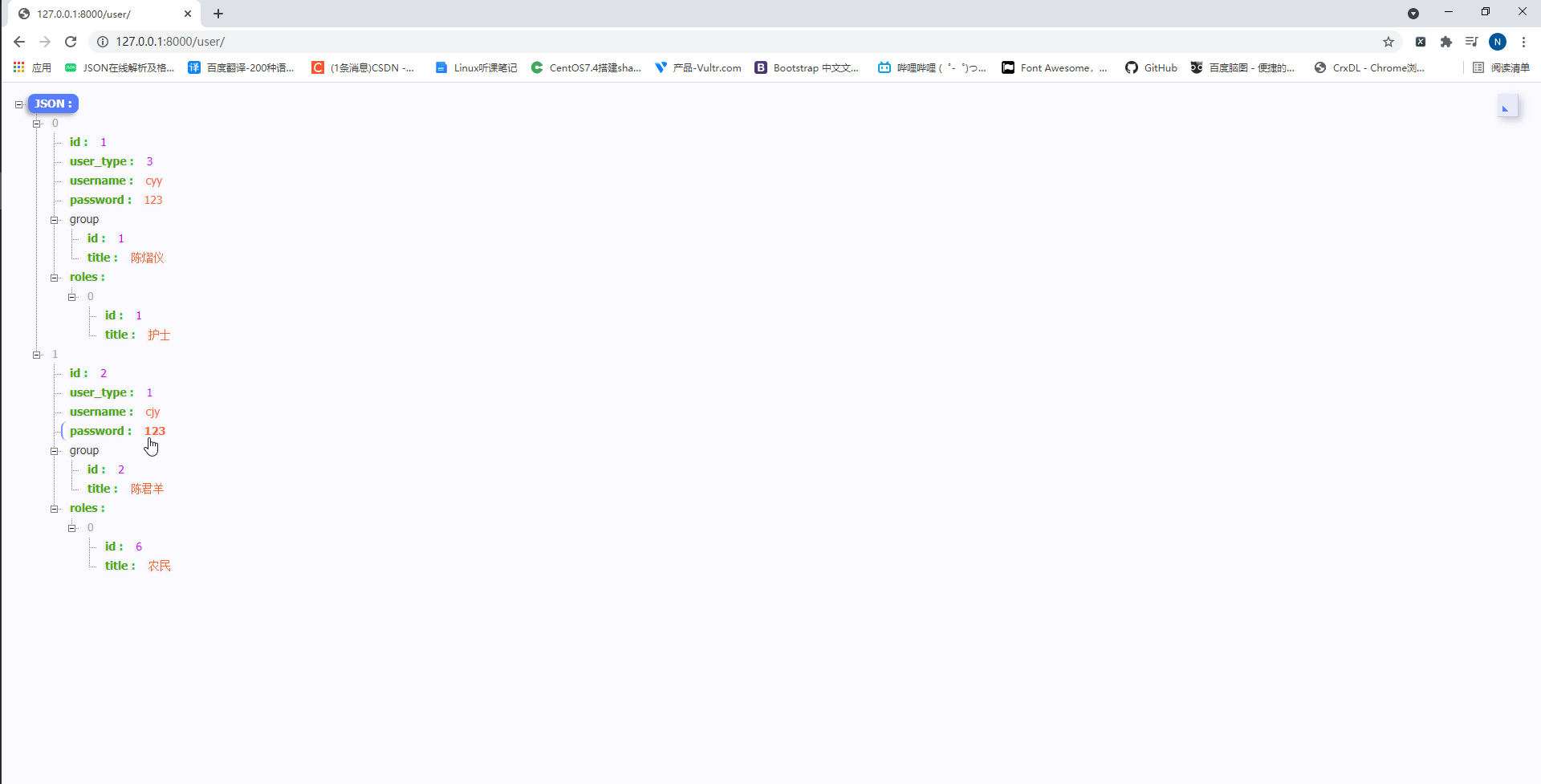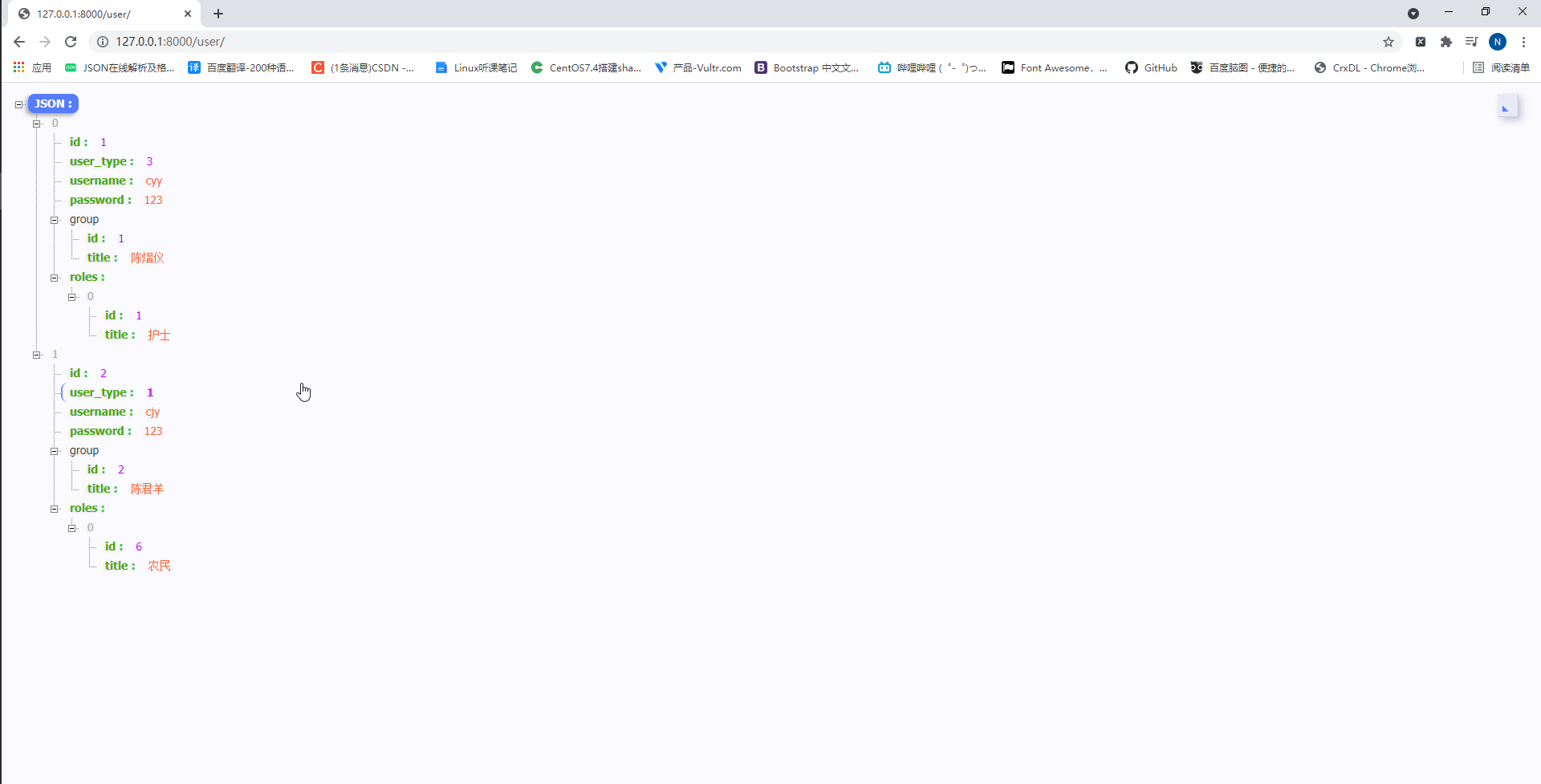
可以发现,通过depth =1的操作将所有和UserInfo关联的表数据都展示出来了。
那么如果我想通过传递给我的group数据是通过路由来访问到相关数据中的,那么该怎么做呢?
urls.py如下:
from django.urls import path, re_path
from api import views
urlpatterns = [
path('user/', views.UserInfoView.as_view() ),
re_path(r'user/(?P[v1|v2]+)/group/' , views.UserGroupView.as_view()),
re_path(r'user/(?P[v1|v2]+)/group/(?P\d+)$' , views.GroupView.as_view(), name="gp"),
]
views.py如下:
from django.shortcuts import render, HttpResponse
from rest_framework import serializers
from rest_framework.views import APIView
from api import models
import json
class GroupSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserGroup
fields = "__all__"
class GroupView(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
# 获取当前用户信息
obj = models.UserGroup.objects.filter(pk=pk).first()
ser = GroupSerializer(instance=obj, many=False)
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
可以看到接口我们已经定义好了,测试一下:

接口数据没有问题,现在我们需要将user表中的group设置成路由的形式来访问,那么该怎么做呢?
在DRF框架中,也有内置的serializers.HyperlinkedIdentityFieldl类提供给我们使用,使用的方法如下:
- 获取到该路由的name(
反向生成url) - 通过lookup_field='group_id’获取数据库中该用户组的id
- 通过lookup_url_kwarg='pk’获取路由中该用户组取值的key获取id
- 在
ModelSerializer实例化的时候通过context参数传递reuqest - 在ModelSerializer中重写group字段
views.py如下:
from django.shortcuts import render, HttpResponse
from rest_framework import serializers
from rest_framework.views import APIView
from api import models
import json
class UserInfoModelSerializer(serializers.ModelSerializer):
group = serializers.HyperlinkedIdentityField(view_name='gp', lookup_field='group_id', lookup_url_kwarg='pk')
class Meta:
model = models.UserInfo
fields = "__all__"
# fields = ['id', 'username', 'password', 'group', 'roles']
depth = 1
class UserInfoSerializer(serializers.Serializer):
username = serializers.CharField()
password = serializers.CharField()
xxx = serializers.CharField(source="get_user_type_display")
gp = serializers.CharField(source="group.title")
rls = serializers.SerializerMethodField()
def get_rls(self, row):
role_obj_list = row.roles.all()
ret = []
for item in role_obj_list:
ret.append({
'id': item.id, 'title': item.title})
return ret
class UserInfoView(APIView):
def get(self, request, *args, **kwargs):
users = models.UserInfo.objects.all()
ser = UserInfoModelSerializer(instance=users, many=True, context={
'request': request})
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
class GroupSerializer(serializers.ModelSerializer):
class Meta:
model = models.UserGroup
fields = "__all__"
class GroupView(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
# 获取当前用户信息
obj = models.UserGroup.objects.filter(pk=pk).first()
ser = GroupSerializer(instance=obj, many=False)
ret = json.dumps(ser.data, ensure_ascii=False)
return HttpResponse(ret)
此时访问http://127.0.0.1:8000/user/如下:
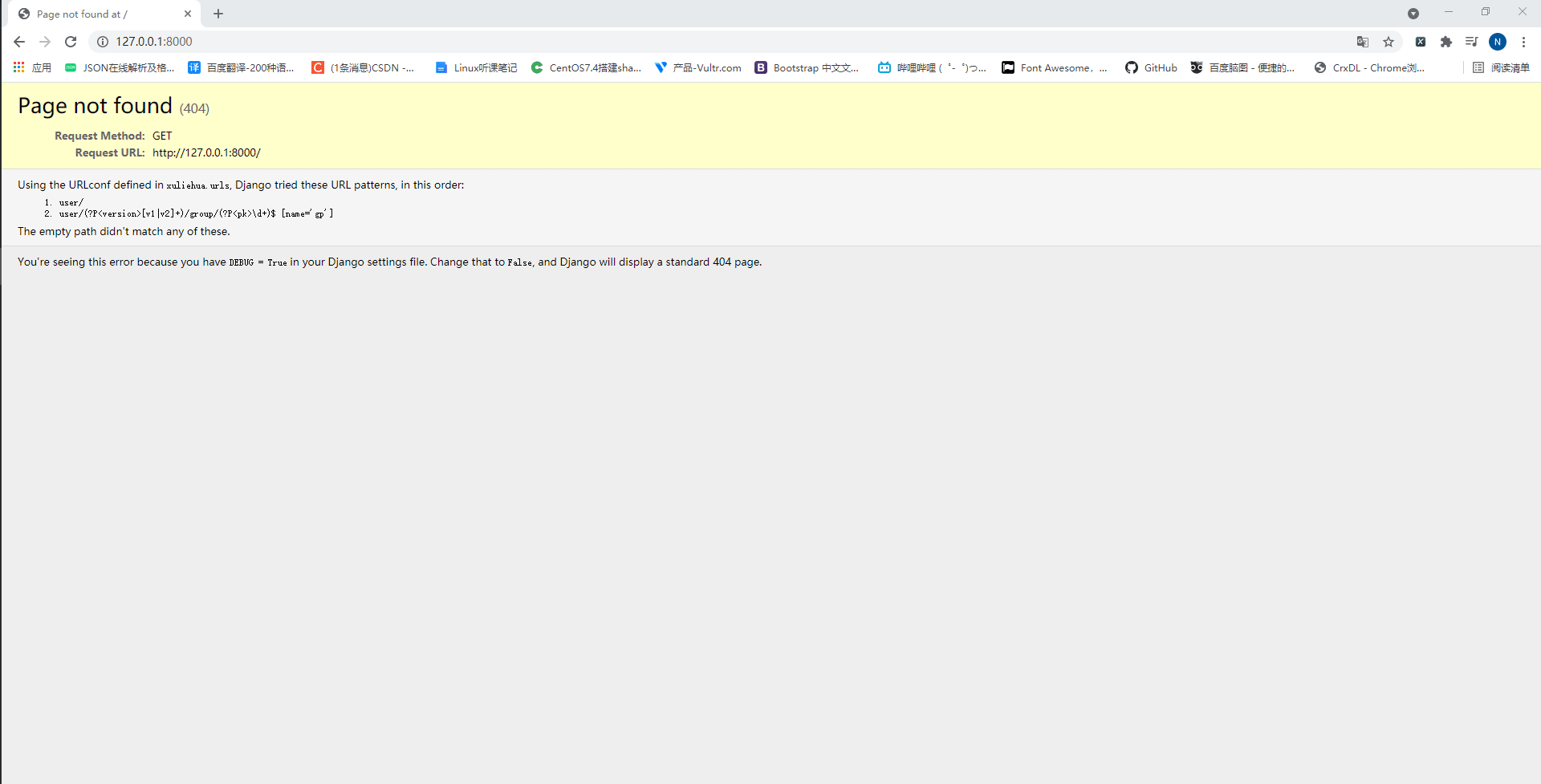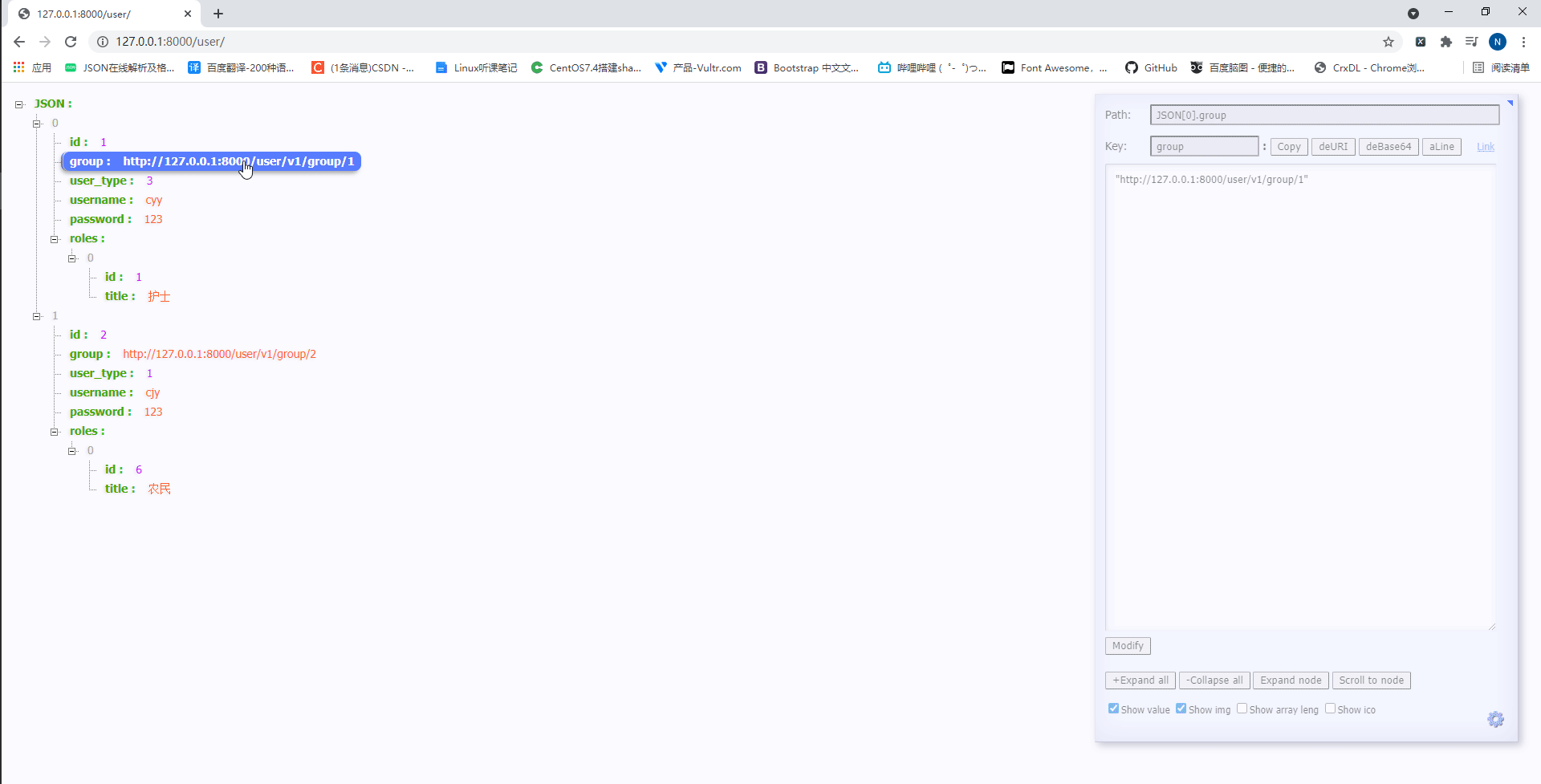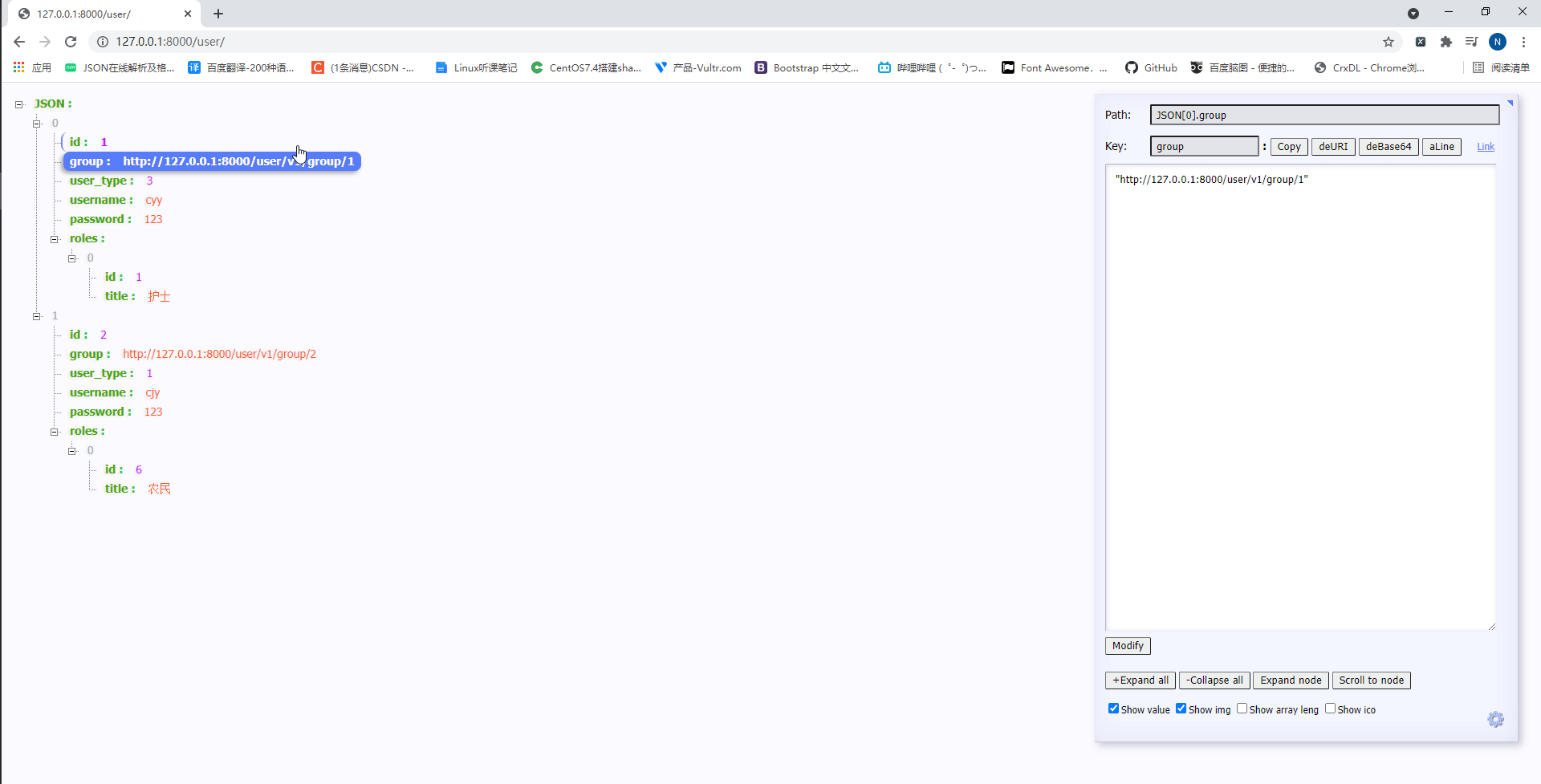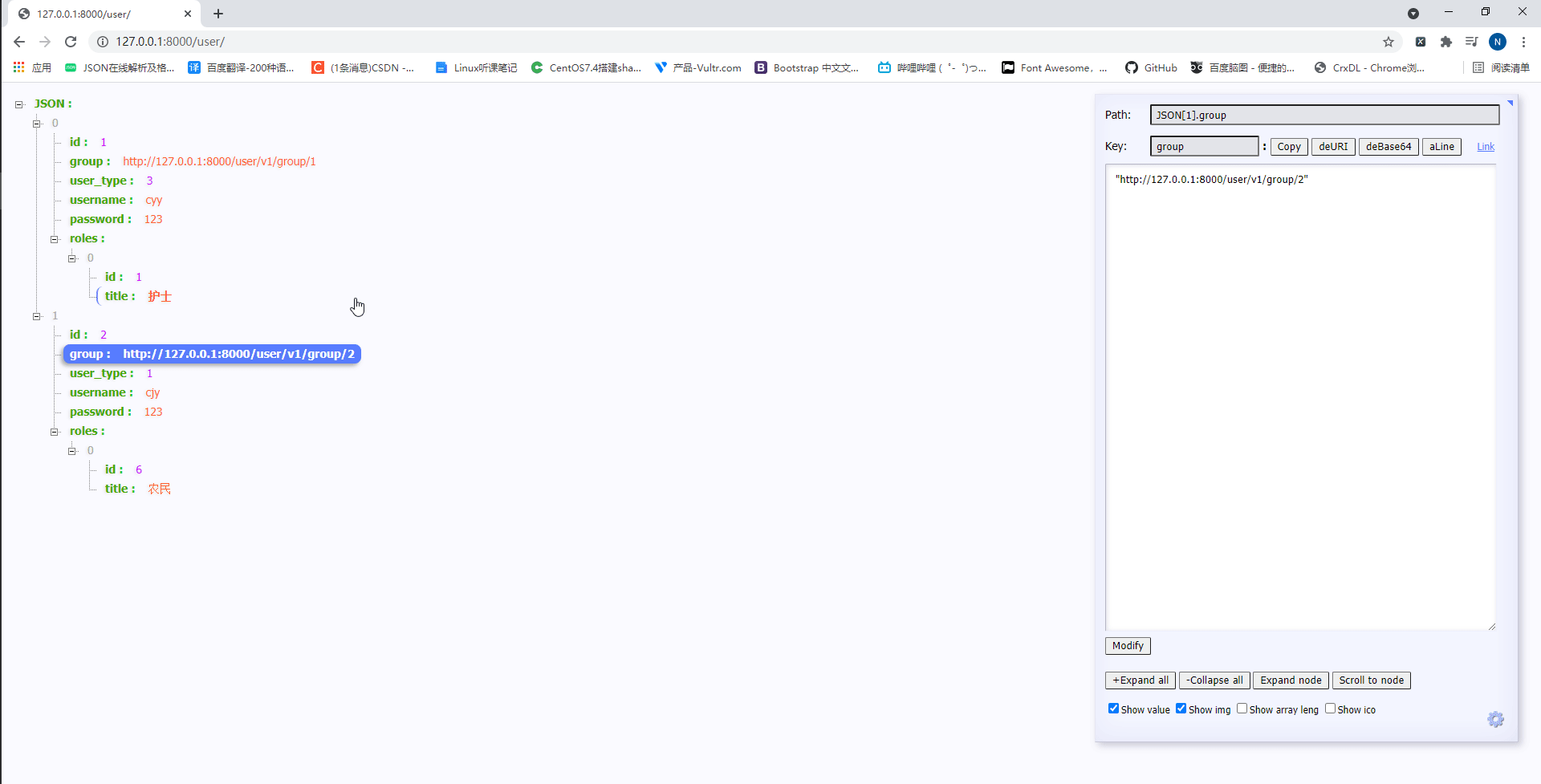
可以看到UserInfoModelSerializer类中的数据fields数据不但可以重写,也可以一个一个的展示,且路由也正确的显示了。
二、序列化源码分析
1.序列化参数源码
通过上面一系列的操作方法,大家也应该掌握序列化的一些基本操作,但是为了能让我们更好的去理解序列化,我们可以通过分析源码的方式来查看该类中,内部是如何实现的。
因为ModelSerializer类继承于Serializer类,所以在查看源码的时候我们可以通过查看Serializer方法,且在我们继承Serializer类的时候我们将其返回的结果以.data的形式获取了序列化的参数,所以我们可以通过查看Serializer类的data函数。
Serializer类/data函数如下:
@property
def data(self):
ret = super().data
return ReturnDict(ret, serializer=self)
该参数调用了父类的data函数,且通过@property装饰器,使得调用时无需传入括号,此时我们点击父类的data函数,发现该父类为BaseSerializer类。
且我们之前在实例化serializer对象的时候,传入过many参数(参数为布尔值),此时我们发现BaseSerializer类中有new方法,我们点击查看:
def __new__(cls, *args, **kwargs):
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
return super().__new__(cls, *args, **kwargs)
可以看到,该方法判断了many的值是否为True,如果不是则返回False,为Turn的时候访问many_init函数,而为False则访问父类的new方法。
此时我们访问当many为True时访问的many_init函数如下:
@classmethod
def many_init(cls, *args, **kwargs)
allow_empty = kwargs.pop('allow_empty', None)
child_serializer = cls(*args, **kwargs)
list_kwargs = {
'child': child_serializer,
}
if allow_empty is not None:
list_kwargs['allow_empty'] = allow_empty
list_kwargs.update({
key: value for key, value in kwargs.items()
if key in LIST_SERIALIZER_KWARGS
})
meta = getattr(cls, 'Meta', None)
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
return list_serializer_class(*args, **list_kwargs)
我们大致的看一下,发现在赋值给meta的时候,判断是否有Meta函数(有则调用没则返回None),之后在赋值给list_serializer_class的时候去判断是否有meta函数。
很明显,在定义类的时候,我们根本就没写入该类,所以此时ListSerializer类将被调用,而该类的作用就是将Queryset的对象给序列化的操作了,反之如果many为False,则会执行该类的init构造方法:
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
if data is not empty:
self.initial_data = data
self.partial = kwargs.pop('partial', False)
self._context = kwargs.pop('context', {
})
kwargs.pop('many', None)
super().__init__(**kwargs)
此时当我们执行完new方法后,回到BaseSerializer类/data函数如下:
@property
def data(self):
if hasattr(self, 'initial_data') and not hasattr(self, '_validated_data'):
msg = (
'When a serializer is passed a `data` keyword argument you '
'must call `.is_valid()` before attempting to access the '
'serialized `.data` representation.\n'
'You should either call `.is_valid()` first, '
'or access `.initial_data` instead.'
)
raise AssertionError(msg)
if not hasattr(self, '_data'):
if self.instance is not None and not getattr(self, '_errors', None):
self._data = self.to_representation(self.instance)
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else:
self._data = self.get_initial()
return self._data
通过data函数可以发现我们在判断是否有_data对象是否有属性,没有的话就执行to_representation函数,且传入的参数为instance(即我们从数据库传入的对象信息),此时我们查看一下to_representation函数(因为是子类先调用的,所以查找顺序是先从子类慢慢向父类延申)。
此时我们通过查找Serializer类中找到了to_representation函数如下:
ef to_representation(self, instance):
ret = OrderedDict()
fields = self._readable_fields
for field in fields:
try:
attribute = field.get_attribute(instance)
except SkipField:
continue
check_for_none = attribute.pk if isinstance(attribute, PKOnlyObject) else attribute
if check_for_none is None:
ret[field.field_name] = None
else:
ret[field.field_name] = field.to_representation(attribute)
return ret
可以看到,该函数调用了fields进行遍历,而遍历的结果(则为我们定义的字段类型数据),然后通过字段类型的数据调用了自己的get_attribute函数方法,此时我们通过查看serializers.CharField字段类中的get_attribute函数,通过查找没有发现,然后继续往父类Field类中找到get_attribute函数如下:
def get_attribute(self, instance):
try:
return get_attribute(instance, self.source_attrs)
except BuiltinSignatureError as exc:
msg = (
'Field source for `{serializer}.{field}` maps to a built-in '
'function type and is invalid. Define a property or method on '
'the `{instance}` instance that wraps the call to the built-in '
'function.'.format(
serializer=self.parent.__class__.__name__,
field=self.field_name,
instance=instance.__class__.__name__,
)
)
raise type(exc)(msg)
except (KeyError, AttributeError) as exc:
if self.default is not empty:
return self.get_default()
if self.allow_null:
return None
if not self.required:
raise SkipField()
msg = (
'Got {exc_type} when attempting to get a value for field '
'`{field}` on serializer `{serializer}`.\nThe serializer '
'field might be named incorrectly and not match '
'any attribute or key on the `{instance}` instance.\n'
'Original exception text was: {exc}.'.format(
exc_type=type(exc).__name__,
field=self.field_name,
serializer=self.parent.__class__.__name__,
instance=instance.__class__.__name__,
exc=exc
)
)
raise type(exc)(msg)
我们看到该方法返回了get_attribute(instance, self.source_attrs)函数,且带上了source_attrs参数,我们点进去查看一下:
def bind(self, field_name, parent):
assert self.source != field_name, (
"It is redundant to specify `source='%s'` on field '%s' in "
"serializer '%s', because it is the same as the field name. "
"Remove the `source` keyword argument." %
(field_name, self.__class__.__name__, parent.__class__.__name__)
)
self.field_name = field_name
self.parent = parent
if self.label is None:
self.label = field_name.replace('_', ' ').capitalize()
if self.source is None:
self.source = field_name
if self.source == '*':
self.source_attrs = []
else:
self.source_attrs = self.source.split('.')
可以看出该参数即为我们传入的source中获取的数据库参数的值,通过分割的方式进行参数,所以self.source_attrs即为分割后的列表,此时我们继续往走Field函数返回的get_attribute函数如下:
def get_attribute(instance, attrs):
for attr in attrs:
try:
if isinstance(instance, Mapping):
instance = instance[attr]
else:
instance = getattr(instance, attr)
except ObjectDoesNotExist:
return None
if is_simple_callable(instance):
try:
instance = instance()
except (AttributeError, KeyError) as exc:
raise ValueError('Exception raised in callable attribute "{}"; original exception was: {}'.format(attr, exc))
return instance
可以发现,该函数将我们返回的self.source_attrs分割后的列表进行遍历,且判断了一下类型,如果该类型为函数则通过调用该函数方法,反之将遍历的列表值为key取相应的value值,而判断是否为函数的方法即为is_simple_callable函数如下:
def is_simple_callable(obj):
if inspect.isbuiltin(obj):
raise BuiltinSignatureError(
'Built-in function signatures are not inspectable. '
'Wrap the function call in a simple, pure Python function.')
if not (inspect.isfunction(obj) or inspect.ismethod(obj) or isinstance(obj, functools.partial)):
return False
sig = inspect.signature(obj)
params = sig.parameters.values()
return all(
param.kind == param.VAR_POSITIONAL or
param.kind == param.VAR_KEYWORD or
param.default != param.empty
for param in params
)
可以看到此时该函数调用了isfunction函数如下:
def isfunction(object):
return isinstance(object, types.FunctionType)
可以发现该函数就表示,该类型是否为函数类型,是为True防止False。
2.序列化源码总结
此时通过序列化的获取值的源码就已经讲完了,那么我们就来个源码总结:
- 从Serializer类实例化之后走data函数
- Serializer类的data函数调用BaseSerializer父类data
- BaseSerializer父类中走new方法判断many是否为Queryset类型(
通过类型进行数据解析) - BaseSerializer父类的data函数调用to_representation
- 因为执行顺序关系走Serializer类的to_representation函数
- Serializer类的to_representation函数遍历了字段类
- 通过字段类调用了它自己的get_attribute函数
- 字段类没有get_attribute函数调用Fields父类的get_attribute函数
- Fields父类的get_attribute函数传入(
解析好的数据和通过source传入的数据并分割成列表) - 调用 get_attribute函数判断类型取相应数据并返回
同理,如果我们想查看HyperlinkedIdentityField类的时候也可以通过查询其to_representation函数方法,之后在调用解析成路由的get_url函数将获取到的参数通过reverse反向生成url,这里就不详细讲解了,方法都是类似的,而钩子函数则从is_valid验证中去查找(从子类向父类延申)。