centertrack
Centertrack模型转换小结
centertrack这个模型,其实总的来说这个模型还是比较简单的,但是由于其中有一个DCN卷积在onnx和tensorflow中不支持的自定义算子,所以转换起来有会有很多问题。
CenterNet
其实CenterNet一共是有两篇文章的,他们都是AnchorFree类型的网络,两个网络既有相似的地方也有本质的区别,都很具有启发意义,跟我们的CenterTrack都有很大的关系,所以在这里都介绍一下。
先讲一下《CenterNet: Keypoint Triplets for Object Detection》这篇论文。提到这个网络就不得不说一下在AnchorFree系列中举足轻重的CornerNet了。
CornerNet论文将对一个目标的检测看成一对关键点(左上和右下)的检测。具体来说,论文使用单个卷积神经网络来预测同一物体类别的所有实例的左上角的热力图,所有右下角的热力图,以及每个检测到的角点的嵌入向量。嵌入向量用于对属于同一目标的一对角点进行分组,本方法极大的简化了网络的输出,并且不需要设计Anchor boxes,下面是整个的网络流程图1:
 图1 CornerNet的网络模型图
图1 CornerNet的网络模型图
预测模块的第一部分是残差模块的修改版,修改后的残差模块中,将第一个卷积替换为一个Corner Pooling模块。这个残差模块首先通过具有C个通道的C个卷积模块的主干网络进行特征提取,然后应用C个Cornet Pooling层。残差模块之后,我们将池化特征输入到具有C个通道的的Conv+BN层,同时为这一层加上瓶颈结构。修改后的残差模块后面接一个具有C个通道的卷积模块和C个通道的C个Conv-ReLU-Conv来产生热力图,嵌入和偏移量。
而CornerNet的另外一个创新点是Corner Pooling,这是一种新型的池化层,可以帮助卷积神经网络更好的定位边界框的角点。
下面就来分别讲一下具体的每个细节部分。
1.1 检测角点
我们预测两组热力图,一组用于左上角角点,一组用于右下角角点。每一组热力图有C个通道,其中C是类别数(不包括背景),并且大小为HxW。每个通道都是一个二进制掩码,用于表示该类的角点位置。对于每个角点,有一个ground-truth正位置,其他所有位置都是负位置。在训练期间,没有同等地惩罚负位置,而是减少对正位置一定半径内的负位置给予的惩罚。这是因为如果一对假角点检测器靠近它们各自的ground-truth位置,它仍然可以产生一个与ground-truth充分重叠的边界框,如下图2所示:

图2 用于训练的“Ground-truth”热图。在正位置半径范围内(橙色圆圈)的方框(绿色虚线矩形)仍然与ground-truth(红色实心矩形)有很大的重叠。
所以我们通过确保在我们设定的这个半径(初始值)范围内的点生成的bbox和GT的IOU>0.7来确定所选物体的体积从而确定合适半径,其中惩罚量是由高斯函数确定的。
检测角点的损失函数如下:


其中N是一张图片中的目标的数量,后面的部分其实就是在Focalloss的基础上增加了对非目标点但是GT周围点的减弱惩罚项。
论文中还提出了位置偏移损失函数来弥补下采样时的偏移量损失。


其中n为下采样因子,所以从heatmap中映射回之前的图像的时候会有一定程度上的位置偏移,所以这个就是一个位置补偿。
1.2 分组角点
图像中可能出现多个目标,因此可能会检测到多个左上角和右下角。我们需要确定左上角和右下角的一对角点是否来自同一目标边界框,在这个基础上我们还需要尽可能的分离代表不同目标的角点。

这两个损失函数就很形象了,上面的pull代表将同一目标的角点拉近,下面的push代表将不同目标的角点推远。其中ek表示etk(左上角角点)和ebk(右下角角点)的均值。
这一部分也叫做embedding_loss。
1.3 Corner Pooling
通常没有局部视觉证据表明存在角点。要确定像素是否为左上角,我们需要水平地向左看目标的最左面边界,垂直地向上部看物体的最上边边界。因此,作者提出Corner Pooling通过编码显式先验知识来更好地定位角点。

这个损失函数也比较好理解,假定图像是HxW的假设现在要确定(i,j)是否是左上角的角点,那么ftij代表现在的这个点,然后tij就在(i,j)和(i,H)之间遍历寻找最大值,同理lij是在(i,j)和(W,j)寻找最大值。下图就看的很清楚了。

最后总的loss函数就是:
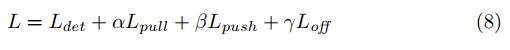
1.4 CenterNet: Keypoint Triplets for Object Detection
接下来才开始讲CenterNet的部分。由于下面还有一个网络也叫做CenterNet,所以下面我们把这一个网络叫做CenterNet1.
其实CenterNet1就是在前面的CornerNet的基础上进行了两个小改进。CornerNet最大的瓶颈是角点检测不准确,这正是因为它提出的Corner Pooling更加关注目标的边缘信息,而对目标内部的感知能力不强。
所以CenterNet1提出了基于两个角点结合推断出的中心点一起检测的方案。
求中心点的公式:


两张图结合应该很好理解了。
在此基础上作者还提出了了center_pooling和Cascade_corner_pooling来丰富中心店和角点的特征。
Center Pooling提取中心点水平方向和垂直方向的最大值并相加,给中心点提供除了所处位置以外的信息,这使得中心点有机会获得更易于区分于其他类别的语义信息。Center Pooling 可通过不同方向上的Corner Pooling 的组合实现,例如一个水平方向上的取最大值操作可由Left Pooling 和Right Pooling通过串联实现。同理,一个垂直方向上的取最大值操作可由Top Pooling 和Bottom Pooling通过串联实现。(其中作者为了加速这一过程特意将这部分写成了C++代码)
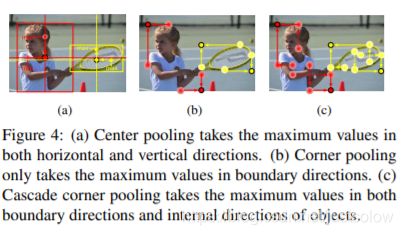
图a 表示Center_point pooling的过程,图b表示Corner_point pooling的过程,图c 就是两者的级联

Cascade Corner Pooling:这一模块用于预测目标的左上角和右下角角点,一般情况下角点位于物体外部,所处位置并不含有关联物体的语义信息,这为角点的检测带来了困难。这篇论文提出了Cascade Corner Pooling,它首先提取出目标边缘最大值,然后在边缘最大值处继续向物体内部提取最大值,并和边界最大值相加,以此给角点提供更丰富的关联目标语义信息。
最后的损失函数如下:
![]()
1.5 Object as Points
这是同年的另一篇CenterNet,下面我们把他叫做CenterNet2。这篇文章的思路跟前面的两篇都不太一样,这篇寻找目标的方法跟前面是反着的,先找到目标的中心点然后向两边扩散直到寻找到目标的边界值。
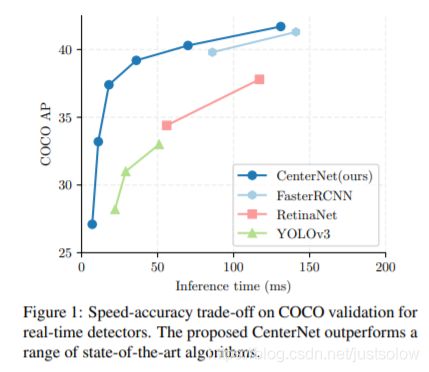
效果吊打了yolov3和faster-rcnn。
论文中介绍了实现3D目标检测和人体姿态估计任务。具体来说对于3D目标检测,直接回归得到目标的深度信息,3D目标框的尺寸,目标朝向;对于人体姿态估计来说,将关键点位置作为中心的偏移量,直接在中心点回归出这些偏移量的值。
如下图:

网络的backbone是基于Hourglass-104的。跟上面的centernet1一样。
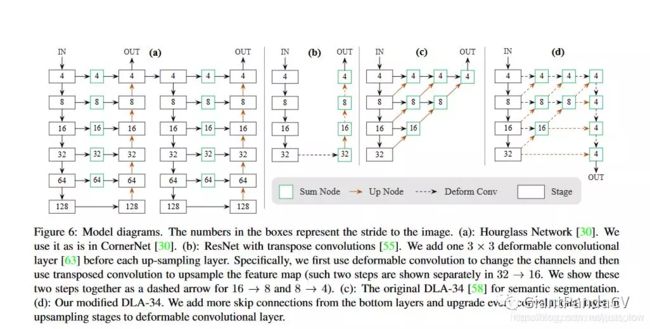
图片来源网络
注意这几个结构都是Backbone网络,最后只需要在输出特征图上接卷积层映射结果即可。比如在目标检测任务中,用官方的源码(使用Pytorch)来表示一下最后三层,其中hm为heatmap、wh为对应中心点的width和height、reg为偏置量
1.5.1 目标损失
目标损失跟上面的CornerNet的角点损失一致都是基于像素的Focalloss,不过上面是检测角点的而这里是检测中心点的。

这里的![]()
也就是通过基于像素的高斯函数在GT中找到中心点。
但是位置补偿损失不太一样,由于图像下采样的时候,GT的关键点会因数据是离散的而产生偏差。
其中R是下采样的率,Op是预测的局部偏移,然后求其L1损失。注意这里的预测的局部偏移是所有类别的。
接下来就是找到边缘点了。
Anchor_base算法与CenterNet2算法的区别,CenterNet2是从中心向两边扩展寻找目标区域的。那么寻找目标区域的损失函数如下所示:

其中qk=((x1+x2)/2+(y1+y2)/2)表示中心点, 。
为了减少j计算负担,我们为每个目标种类使用单一的尺度预测 ,而且还不进行尺度归一化,解决方案就是在这个损失函数前面乘一个系数用来控制尺度问题。下面是总的loss函数:
![]()
接下来还有一个类似于NMS的筛选过程。在推理的时候,我们分别提取热力图上每个类别的峰值点。如何得到这些峰值点呢?做法是将热力图上的所有响应点与其连接的个临近点进行比较,如果该点响应值大于或等于其个临近点值则保留,最后我们保留所有满足之前要求的前100个峰值点。产生如下的bbox:

其中![]()
是偏移预测结果。
CenterNet2网络还可以用在3D目标检测上面。3D目标检测是对每个目标进行3D bbox估计,每个中心点都需要三个附加信息:depth,3D dimension, orientation。我们为每个信息分别添加head。对于每个中心点,深度值depth是一个维度的。然后depth很难直接回归。论文中对输出进行了变换,d=1/σ-1其中σ是sigmoid函数,在特征点估计网络上添加了一个深度计算通道D,该通道使用了由ReLU分开的两个卷积层,我们用L1损失来训练深度估计器。目标方向默认是单标量的值,然而这也很难回归。用两个bins来呈现方向,并在bins中做回归。特别地,方向用8个标量值来编码的形式,每个bin有4个值。对于一个bin,两个值用作softmax分类,其余两个值回归在每个bin中的角度。
CenterNet2网络还可以用在姿态估计,用来检测人体的17个2D关键点的位置,检测和回归的方法与检测中心点几乎一致。
1.6 CenterNetTrack
CenterNetTrack其实就是在CenterNet2的基础上进行了两个改进而已。
1、输入的维度增加了,由于要预测目标跟踪类型,所以输入是两幅图像和一个观测位置的heatmap,输出也就变成了两幅图像(可以是相邻两帧也可以有一定的跨帧,在作者的实验中就是跨了3帧)的目标中心位置,大小和相对偏移。
2、对于数据的关联性问题,作者通过中心点的距离来判断是否匹配,使用的是一种贪婪的模式,而不是业界常用的全局数据关联优化。
1.6.1 模型描述
网络的输入是连续两帧的的图像和上一帧的heatmap信息,其中包括其位置,大小,置信度得分和编号ID。我们的目标是检测和跟踪当前帧中的目标,并为每一个对象分配ID。
随之而来的有两个问题:一是如何在每一帧中找到所有的对象,包含被遮挡的对象;二是如何在时间上为这些对象建立联系。解决办法是:
1、Tracking-conditioned detection:利用先前帧的检测结果改善当前帧的检测;
2、Association through offsets:在时间轴上建立检测结果之间的联系
1.6.2 Tracking-conditioned detection
CenterTrack将上一帧图像的检测结果添加到输入中,具体做法是根据上一帧的检测结果绘制一张单通道heatmap,其中peak位置对应目标中心点,并使用与训练CenterNet过程中相同的高斯核渲染办法(根据目标大小调整高斯参数)进行模糊处理,为了降低误报概率,作者只对检测结果中得分高于一定阈值的目标进行渲染(即得分低的目标不会体现在新生成的heatmap上)。综上,CenterTrack与CenterNet模型结构几乎相同,但是输入通道多了4个:上一帧图像(3 channels)、渲染出的heatmap(1 channel)。
1.6.3 Association through offsets
为了能够在时间上建立检测结果直接的联系,CenterTrack添加了2个额外的输出通道,用于预测一个2维的偏移向量,即描述的是各对象在当前帧中的位置相对于其在前一帧图像当中的位置的X/Y方向的偏移量。此处的训练监督方式与CenterNet中对目标对象长宽或中心偏移情况的部分训练方式相同。
接下来只需要进行简单的贪婪匹配就好了,即优先匹配离目标点在
范围内的点,然后按照置信度进行排序,取最优即可。
在视频训练集和图片训练集上面的训练分别是:
1、在视频训练集上训练其实就是利用centerNet2的权重finetue,不过在模型推理的时候我们应尽量模拟一些test-time error,比如,随机高斯扰动模拟目标错误定位;在GT部分随机渲染出一些peak模拟误检;以一定的概率随机去掉一些结果模拟漏检。
2、在图片数据集上训练通过随机缩放和变换生成先前帧,达到模拟运动的目的
2、DCN卷积
在进入下一章的模型转换之前有必要了解一下DCN卷积的基础知识,这样才会理解我后面的操作是合理的。
DCN可变形卷积的原理就是通过在普通卷积的基础上加两个分别关于x和y方向的偏移量,然后经过网络的不断学习得到最后的结果。
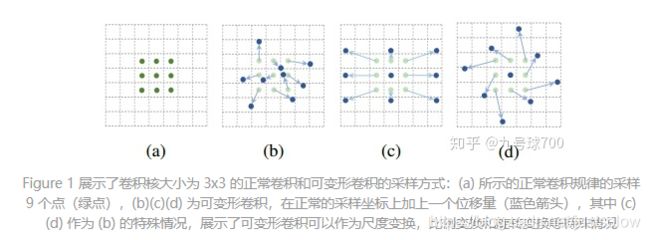
首先来看普通卷积,以3x3卷积为例对于每个输出y(p0),都要从x上采样9个位置,这9个位置都在中心位置x(p0)向四周扩散得到的gird形状上,(-1,-1)代表x(p0)的左上角,(1,1)代表x(p0)的右下角,其他类似。
用公式表示如下:
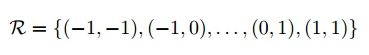
可变性卷积Deformable Conv操作并没有改变卷积的计算操作,而是在卷积操作的作用区域上,加入了一个可学习的参数∆pn。同样对于每个输出y(p0),都要从x上采样9个位置,这9个位置是中心位置x(p0)向四周扩散得到的,但是多了 ∆pn,允许采样点扩散成非gird形状。

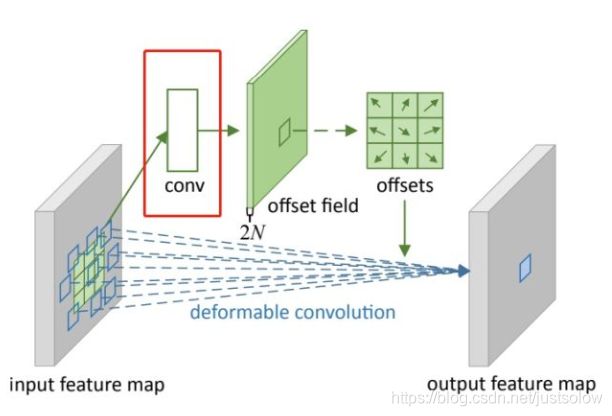
偏移量是通过对原始特征层进行卷积得到的。比如输入特征层是w×h×c,先对输入的特征层进行卷积操作,得到w×h×2c的offset field。这里的w和h和原始特征层的w和h是一致的,offset field里面的值是输入特征层对应位置的偏移量,偏移量有x和y两个方向,所以offset field的channel数是2c。offset field里的偏移量是卷积得到的,可能是浮点数,所以接下来需要通过双向性插值计算偏移位置的特征值。在偏移量的学习中,梯度是通过双线性插值来进行反向传播的。
Roi-pooling跟上面类似:

DCN v2
对于positive的样本来说,采样的特征应该focus在RoI内,如果特征中包含了过多超出RoI的内容,那么结果会受到影响和干扰。而negative样本则恰恰相反,引入一些超出RoI的特征有助于帮助网络判别这个区域是背景区域。
DCNv1引入了可变形卷积,能更好的适应目标的几何变换。但是v1可视化结果显示其感受野对应位置超出了目标范围,导致特征不受图像内容影响(理想情况是所有的对应位置分布在目标范围以内)。
为了解决该问题:提出v2, 主要有
1、扩展可变形卷积,增强建模能力
2、提出了特征模拟方案指导网络培训:feature mimicking scheme
所以自然能想到的解决方案就是加入权重项进行惩罚。(至于这个实现起来就比较简单了,直接初始化一个权重然后乘(input+offsets)就可以了)

可调节的RoIpooling也是类似的,公式如下:
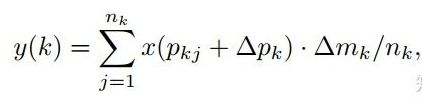
接下来讲一下DCN的代码实现部分。
首先offset是比较好实现的只需要额外加18(33卷积x,y两个方向,DCNV2有27个channel还有9个通道用来最终的区域放缩)个channel用于收集每个featuremap的偏移量信息即可。
class DeformNet(nn.Module):
def __init__(self):
super(DeformNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.offsets = nn.Conv2d(128, 18, kernel_size=3, padding=1)
self.conv4 = DeformConv2D(128, 128, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(128)
self.classifier = nn.Linear(128, 10)
def forward(self, x):
# convs
x = F.relu(self.conv1(x))
x = self.bn1(x)
x = F.relu(self.conv2(x))
x = self.bn2(x)
x = F.relu(self.conv3(x))
x = self.bn3(x)
# deformable convolution
offsets = self.offsets(x)
x = F.relu(self.conv4(x, offsets))
x = self.bn4(x)
print(x)
x = F.avg_pool2d(x, kernel_size=28, stride=1).view(x.size(0), -1)
x = self.classifier(x)
return F.log_softmax(x, dim=1)
然而这只是一个外壳而已,真正的DCN还需要双线性插值的支持。
下面简单说一下啊双线性插值的代码实现,下面是我们一般看到的双线性插值的公式实现,但是这样的计算结果在实际中是不可行的。
原因就是因为坐标系的选取问题,按照一些网上的公开实现,将源图像和目标图像的原点均选在左上角,然后根据插值公式计算目标图像每个点的像素,假设我们要将5x5的图像缩小成3X3,那么源图像和目标图像的对应关系如下图a所示,正确的做法是让两个图像的几何中心重合,并且目标图像的每个像素之间都是等间隔的,并且都和两边有一定的边距,如图b。

图a 图b
所以代码实现就是:
class DeformConv2D(nn.Module):
def init(self, inc, outc, kernel_size=3, padding=1, bias=None):
super(DeformConv2D, self).init()
self.kernel_size = kernel_size
self.padding = padding
self.zero_padding = nn.ZeroPad2d(padding)
self.conv_kernel = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
# 注意,offset的Tensor尺寸是[b, 18, h, w],offset传入的其实就是每个像素点的坐标偏移,也就是一个坐标量,最终每个点的像素还需要这个坐标偏移和原图进行对应求出。
def forward(self, x, offset):
dtype = offset.data.type()
ks = self.kernel_size
# N=9=3x3
N = offset.size(1) // 2
#这里其实没必要,我们反正这个顺序是我们自己定义的,那我们直接按照[x1, x2, .... y1, y2, ...]定义不就好了。
# 将offset的顺序从[x1, y1, x2, y2, ...] 改成[x1, x2, .... y1, y2, ...]
offsets_index = Variable(torch.cat([torch.arange(0, 2*N, 2), torch.arange(1, 2*N+1, 2)]), requires_grad=False).type_as(x).long()
# torch.unsqueeze()是为了增加维度,使offsets_index维度等于offset
offsets_index = offsets_index.unsqueeze(dim=0).unsqueeze(dim=-1).unsqueeze(dim=-1).expand(*offset.size())
# 根据维度dim按照索引列表index将offset重新排序,得到[x1, x2, .... y1, y2, ...]这样顺序的offset
offset = torch.gather(offset, dim=1, index=offsets_index)
# ------------------------------------------------------------------------
# 对输入x进行padding
if self.padding:
x = self.zero_padding(x)
# 将offset放到网格上,也就是标定出每一个坐标位置
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# 维度变换
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
# floor是向下取整
q_lt = Variable(p.data, requires_grad=False).floor()
# +1相当于向上取整,这里为什么不用向上取整函数呢?是因为如果正好是整数的话,向上取整跟向下取整就重合了,这是我们不想看到的。
q_rb = q_lt + 1
# 将lt限制在图像范围内,其中[..., :N]代表x坐标,[..., N:]代表y坐标
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
# 将rb限制在图像范围内
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
# 获得lb
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], -1)
# 获得rt
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], -1)
# 限制在一定的区域内,其实这部分可以写的很简单。有点花里胡哨的感觉。。在numpy中这样写:
#p = np.where(p >= 1, p, 0)
#p = np.where(p other
mask = torch.cat([p[..., :N].lt(self.padding)+p[..., :N].gt(x.size(2)-1-self.padding),
p[..., N:].lt(self.padding)+p[..., N:].gt(x.size(3)-1-self.padding)], dim=-1).type_as(p)
#禁止反向传播
mask = mask.detach()
#p - (p - torch.floor(p))不就是torch.floor(p)呢。。。
floor_p = p - (p - torch.floor(p))
#总的来说就是把超出图像的偏移量向下取整
p = p*(1-mask) + floor_p*mask
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
# 插值的4个系数
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
# 插值的最终操作在这里
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
#偏置点含有九个方向的偏置,_reshape_x_offset() 把每个点9个方向的偏置转化成 3×3 的形式,
# 于是就可以用 3×3 stride=3 的卷积核进行 Deformable Convolution,
# 它等价于使用 1×1 的正常卷积核(包含了这个点9个方向的 context)对原特征直接进行卷积。
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv_kernel(x_offset)
return out
#求每个点的偏置方向
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = np.meshgrid(range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1), indexing='ij')
# (2N, 1)
p_n = np.concatenate((p_n_x.flatten(), p_n_y.flatten()))
p_n = np.reshape(p_n, (1, 2*N, 1, 1))
p_n = Variable(torch.from_numpy(p_n).type(dtype), requires_grad=False)
return p_n
@staticmethod
#求每个点的坐标
def _get_p_0(h, w, N, dtype):
p_0_x, p_0_y = np.meshgrid(range(1, h+1), range(1, w+1), indexing='ij')
p_0_x = p_0_x.flatten().reshape(1, 1, h, w).repeat(N, axis=1)
p_0_y = p_0_y.flatten().reshape(1, 1, h, w).repeat(N, axis=1)
p_0 = np.concatenate((p_0_x, p_0_y), axis=1)
p_0 = Variable(torch.from_numpy(p_0).type(dtype), requires_grad=False)
return p_0
#求最后的偏置后的点=每个点的坐标+偏置方向+偏置
def _get_p(self, offset, dtype):
# N = 9, h, w
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
#求出p点周围四个点的像素
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)将图片压缩到1维,方便后面的按照index索引提取
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)这个目的就是将index索引均匀扩增到图片一样的h*w大小
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
#双线性插值法就是4个点再乘以对应与 p 点的距离。获得偏置点 p 的值,这个 p 点是 9 个方向的偏置所以最后的 x_offset 是 b×c×h×w×9。
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
#_reshape_x_offset() 把每个点9个方向的偏置转化成 3×3 的形式
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
v2的代码就是在v1的基础上加了权重项sigmoid。就不详细注释了。
```python
import torch
from torch import nn
class DeformConv2d(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation:
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
offset = self.p_conv(x)
if self.modulation:
m = torch.sigmoid(self.m_conv(x))
dtype = offset.data.type()
ks = self.kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1)
m = m.unsqueeze(dim=1)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
根据上面的代码,我们可以清楚的知道DCN卷积的作者用了一种巧妙的转化思想,其真正做法并不是像他的论文中给出的图一样是对卷积核进行offset而是对像素点进行offset!这样就不会有GPU上加速的问题了。
3、模型转化
首先就是对这个DCN卷积部分的处理,我使用了一个插件的形式来方便插入到onnx中,这是由于onnx支持自定义算子的实现。
插件部分:(类似于这样的插件定义的形式)
当然实际转模型的时候还是有很多环境的问题的,这就需要你不断的建立各种适配的环境然后进行尝试了,我的运气比较好一个环境走遍天下没出太多问题。
我的环境是:
pytorch=1.1
protobuf v3.8.x
cuda=10.0
cudnn7.6.5.32-cuda10.2
opencv4.2.0
onnx=1.1(1.6也尝试过,没啥区别,照样没有报错,不过最后是用1.1成功的,1.6没试过不清楚)
然后就是onnx模型转tensorflow了。
首先打开转好的onnx模型图,检查有无什么大问题的,然后就按照手册进行操作。
先安装工具包onnx2pbConvert-1.1.0-py3-none-any.whl(当然最好虚拟环境,因为你不清楚你最后是什么环境能成功)
下面就说说我碰到的情况吧
1、当然就是我的自定义的插件不支持
所以我暂时先使用了围魏救赵的方法,将DCN替换成了普通的Add+卷积的形式(因为DCN有四个输入一个输出(两个卷积的输入,还有权重和bias)),所以你得先用Add把两个卷积的输入接进来,但是这时候就会伴随着出现一个问题,一个节点替换成两个节点,那么中间的节点之间怎么连接呢?节点序号是连续的,你这样的话中间的节点不就冗余了呢。。。所幸是有解决办法的,你可以用几个不同的字符串作为中间的连接节点。
插件OP不支持
str_list = ['q','w','e','r','t','y','u','i','o','p','a','s','d','f','g','h']
不能再原节点上修改,定义不一样,可以看上文DCN插件的定义
然后报了一个困扰了我一天的错误。。。
插入节点必须用insert不能用append
拓扑排序不对?怎么回事,图里面是连起来,我和施红宇还有张迪想了很多解决方案,比如说,1、扩大节点之间的间隔然后再插入节点,但是这样还是不行。2、舍弃Add节点,一换一的策略,fail 3、不添加新的节点直接在原插件节点上进行修改参数值,fail 最后发现是我的代码写错了。
append换成insert就好了,insert是在节点的地方插入,而append是在节点后添加,所以图里面虽然看不出问题,但是实际上内部还是会有区别的,以前的时候没有注意list的这个问题,没想到这个小问题愁了我整整一天。(所以说基础规范很重要!)
这时候我意识到一个重要的问题,DCN实际上是利用网络学习出来的offset参数对原图像素进行偏移,所以我的网络中的Add其实没有存在的必要。所以之后我就去掉了。
看错误似乎是我们的反卷积部分出现问题了,后来咨询了一下公司的张迪大佬,大佬一针见血的指出了是onnx的bug,ConvTranspose函数的group不支持高维的,所以应该改成group=1,下面的权重信息也得进行pad成grup的维度。
这里有一个代码的小问题,你修改参数以后一定要记得把你修改的参数再赋值给原来的传入参数(注意是最原来的传入参数!)
新建立的卷积节点没有pad
又是张迪大佬找到的问题的源头,32-28=4,所以推测出来是不是我的修改DCN卷积的时候忘记pad了。
参考文献
https://github.com/Duankaiwen/CenterNet/blob/master/models/py_utils/_cpools/src/top_pool.cpp
https://arxiv.org/pdf/1904.08189.pdf
https://arxiv.org/pdf/1808.01244.pdf
https://arxiv.org/pdf/1904.07850.pdf
https://github.com/ChunhuanLin/deform_conv_pytorch
https://github.com/onnx/onnx-tensorflow
https://github.com/Duankaiwen/CenterNet/blob/master/models/py_utils/_cpools/src/top_pool.cpp
https://github.com/xingyizhou/CenterTrack
https://arxiv.org/abs/2004.01177
https://github.com/zzzxxxttt/pytorch_simple_CenterNet_45
https://github.com/dlunion/tensorRTIntegrate
附录:
CenterNet是一个经典的Anchor-Free目标检测方法,图片进入网络流程如下:
1、对图片进行resize,长和宽一般相等,并且至少为4的倍数。
2、图片经过网络的特征提取后,得到的特征图的空间分辨率依然比较大,是原来的1/4。这是因为CenterNet采用的是类似人体姿态估计中用到的骨干网络,基于heatmap提取关键点的方法需要最终的空间分辨率比较大。
3、训练的过程中,CenterNet得到的是一个heatmap,所以标签加载的时候,需要转为类似的heatmap热图。
4、测试的过程中,由于只需要从热图中提取目标,这样就不需要使用NMS,降低了计算量。
GT部分处理
代码分析:
def __getitem__(self, index):
img_id = self.images[index]
img_path = os.path.join(
self.img_dir, self.coco.loadImgs(ids=[img_id])[0]['file_name'])
ann_ids = self.coco.getAnnIds(imgIds=[img_id])
annotations = self.coco.loadAnns(ids=ann_ids)
labels = np.array([self.cat_ids[anno['category_id']]
for anno in annotations])
bboxes = np.array([anno['bbox']
for anno in annotations], dtype=np.float32)
if len(bboxes) == 0:
bboxes = np.array([[0., 0., 0., 0.]], dtype=np.float32)
labels = np.array([[0]])
bboxes[:, 2:] += bboxes[:, :2] # xywh to xyxy
img = cv2.imread(img_path)
height, width = img.shape[0], img.shape[1]
# 获取中心坐标p
center = np.array([width / 2., height / 2.],
dtype=np.float32) # center of image
scale = max(height, width) * 1.0 # 仿射变换
flipped = False
if self.split == 'train':
# 随机选择一个尺寸来训练
scale = scale * np.random.choice(self.rand_scales)
w_border = get_border(128, width)
h_border = get_border(128, height)
center[0] = np.random.randint(low=w_border, high=width - w_border)
center[1] = np.random.randint(low=h_border, high=height - h_border)
if np.random.random() < 0.5:
flipped = True
img = img[:, ::-1, :]
center[0] = width - center[0] - 1
# 仿射变换
trans_img = get_affine_transform(
center, scale, 0, [self.img_size['w'], self.img_size['h']])
img = cv2.warpAffine(
img, trans_img, (self.img_size['w'], self.img_size['h']))
# 归一化
img = (img.astype(np.float32) / 255.)
if self.split == 'train':
# 对图片的亮度对比度等属性进行修改
color_aug(self.data_rng, img, self.eig_val, self.eig_vec)
img -= self.mean
img /= self.std
img = img.transpose(2, 0, 1) # from [H, W, C] to [C, H, W]
# 对Ground Truth heatmap进行仿射变换
trans_fmap = get_affine_transform(
center, scale, 0, [self.fmap_size['w'], self.fmap_size['h']]) # 这时候已经是下采样为原来的四分之一了
# 3个最重要的变量
hmap = np.zeros(
(self.num_classes, self.fmap_size['h'], self.fmap_size['w']), dtype=np.float32) # heatmap
w_h_ = np.zeros((self.max_objs, 2), dtype=np.float32) # width and height
regs = np.zeros((self.max_objs, 2), dtype=np.float32) # regression
# indexs
inds = np.zeros((self.max_objs,), dtype=np.int64)
# 具体选择哪些index
ind_masks = np.zeros((self.max_objs,), dtype=np.uint8)
for k, (bbox, label) in enumerate(zip(bboxes, labels)):
if flipped:
bbox[[0, 2]] = width - bbox[[2, 0]] - 1
# 对检测框也进行仿射变换
bbox[:2] = affine_transform(bbox[:2], trans_fmap)
bbox[2:] = affine_transform(bbox[2:], trans_fmap)
# 防止越界
bbox[[0, 2]] = np.clip(bbox[[0, 2]], 0, self.fmap_size['w'] - 1)
bbox[[1, 3]] = np.clip(bbox[[1, 3]], 0, self.fmap_size['h'] - 1)
# 得到高和宽
h, w = bbox[3] - bbox[1], bbox[2] - bbox[0]
if h > 0 and w > 0:
obj_c = np.array([(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2],
dtype=np.float32) # 中心坐标-浮点型
obj_c_int = obj_c.astype(np.int32) # 整型的中心坐标
# 根据一元二次方程计算出最小的半径
radius = max(0, int(gaussian_radius((math.ceil(h), math.ceil(w)), self.gaussian_iou)))
# 得到高斯分布
draw_umich_gaussian(hmap[label], obj_c_int, radius)
w_h_[k] = 1. * w, 1. * h
# 记录偏移量
regs[k] = obj_c - obj_c_int # discretization error
# 当前是obj序列中的第k个 = fmap_w * cy + cx = fmap中的序列数
inds[k] = obj_c_int[1] * self.fmap_size['w'] + obj_c_int[0]
# 进行mask标记
ind_masks[k] = 1
return {'image': img, 'hmap': hmap, 'w_h_': w_h_, 'regs': regs,
'inds': inds, 'ind_masks': ind_masks, 'c': center,
's': scale, 'img_id': img_id}
然后还有这个半径确定的问题:
def gaussian_radius(det_size, min_overlap=0.7):
# gt框的长和宽
height, width = det_size
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / (2 * a1)
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / (2 * a2)
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / (2 * a3)
return min(r1, r2, r3)
源代码:
def gaussian_radius(det_size, min_overlap=0.7):
height, width = det_size
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / 2
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / 2
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / 2
return min(r1, r2, r3)
将高斯分布添加到heatmap上
def gaussian2D(shape, sigma=1):
m, n = [(ss - 1.) / 2. for ss in shape]
y, x = np.ogrid[-m:m + 1, -n:n + 1]
h = np.exp(-(x * x + y * y) / (2 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
# 限制最小的值
return h
def draw_umich_gaussian(heatmap, center, radius, k=1):
# 得到直径
diameter = 2 * radius + 1
gaussian = gaussian2D((diameter, diameter), sigma=diameter / 6)
# sigma是一个与直径相关的参数
# 一个圆对应内切正方形的高斯分布
x, y = int(center[0]), int(center[1])
height, width = heatmap.shape[0:2]
# 对边界进行约束,防止越界
left, right = min(x, radius), min(width - x, radius + 1)
top, bottom = min(y, radius), min(height - y, radius + 1)
# 选择对应区域
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
# 将高斯分布结果约束在边界内
masked_gaussian = gaussian[radius - top:radius + bottom,
radius - left:radius + right]
if min(masked_gaussian.shape) > 0 and min(masked_heatmap.shape) > 0: # TODO debug
np.maximum(masked_heatmap, masked_gaussian * k, out=masked_heatmap)
# 将高斯分布覆盖到heatmap上,相当于不断的在heatmap基础上添加关键点的高斯,
# 即同一种类型的框会在一个heatmap某一个类别通道上面上面不断添加。
# 最终通过函数总体的for循环,相当于不断将目标画到heatmap
return heatmap
另外在训练模型的时候注意要把将cudnn的batch norm关闭.
torch.backends.cudnn.benchmark = true(False)
那么cuDNN使用的非确定性算法就会自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题
一般来讲,应该遵循以下准则:
1.如果网络的输入数据维度或类型上变化不大,设置 torch.backends.cudnn.benchmark = true 可以增加运行效率;
2. 如果网络的输入数据在每次 iteration 都变化的话,会导致 cnDNN 每次都会去寻找一遍最优配置,这样反而会降低运行效率。