大数据手册(Spark)--Spark机器学习(PySpark版)
文章目录
- MLlib
- ML
-
- 常见的特征转换
- 模型拟合和描述
- 超参调优
Spark安装配置
Spark基本概念
Spark基础知识(PySpark版)
Spark机器学习(PySpark版)
Spark流数据处理(PySpark版)
MLlib
Apache Spark提供了一个名为 MLlib 的机器学习库,包含基于RDD的原始算法的API。此外,MLlib是目前唯一支持流媒体训练模型的库。从Spark2.0开始,ML是主要的机器学习库,它对DataFrame进行操作。
MLlib概括了其公开三个核心机器学习功能:
- 数据准备:特征提取、变换、选择、分类特征的散列和一些自然语言处理方法。
- 机器学习算法:实现了一些流行和高级的回归,分类和聚类算法。
- 实用程序:统计方法,如描述性统计、卡方检验、线性代数(稀疏稠密矩阵和向量)和模型评估方法。
MLlib的抽象类
- Vector:向量(mllib.linalg.Vectors)支持dense和sparse(稠密向量和稀疏向量)。区别在与前者的没一个数值都会存储下来,后者只存储非零数值以节约空间。
- LabeledPoint:(mllib.regression)表示带标签的数据点,包含一个特征向量与一个标签。注意,标签要转化成浮点型的,通过StringIndexer转化。
- Rating:(mllib.recommendation),用户对一个产品的评分,用于产品推荐
- 各种Model类:每个Model都是训练算法的结果,一般都有一个predict()方法可以用来对新的数据点或者数据点组成的RDD应用该模型进行预测
一般来说,大多数算法直接操作由Vector、LabledPoint或Rating组成的RDD,通常我们从外部数据读取数据后需要进行转化操作构建RDD。
具体代码:(摘自Learning Spark学习笔记 | 胡晓曼)
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.feature import HashingTF
from pyspark.mllib.calssification import LogisticRegressionWithSGD
spam = sc.textFile("spam.txt")
normal = sc.textFile("normal.txt")
#创建一个HashingTF实例来把邮件文本映射为包含10000个特征的向量
tf = HashingTF(numFeatures = 10000)
#各邮件都被切分为单词,每个单词被映射为一个特征
spamFeatures = spam.map(lambda email: tf.transform(email.split(" ")))
normalFeatures = normal.map(lambda email: tf.transform(email.split(" ")))
#创建LabeledPoint数据集分别存放阳性(垃圾邮件)和阴性(正常邮件)的例子
positiveExamples = spamFeatures.map(lambda features: LabeledPoint(1,features))
negativeExamples = normalFeatures.map(lambda features: LabeledPoint(0,features))
trainingData = positiveExamples.union(negativeExamples)
trainingData.cache#因为逻辑回归是迭代算法,所以缓存数据RDD
#使用SGD算法运行逻辑回归
model = LogisticRegressionWithSGD.train(trainingData)
#以阳性(垃圾邮件)和阴性(正常邮件)的例子分别进行测试
posTest = tf.transform("O M G GET cheap stuff by sending money to...".split(" "))
negTest = tf.transform("Hi Dad, I stared studying Spark the other ...".split(" "))
print "Prediction for positive test examples: %g" %model.predict(posTest)
print "Prediction for negative test examples: %g" %model.predict(negTest)
ML
ML库提供了基于DataFrame的API,可以用来构建机器学习工作流(Pipeline),ML Pipeline弥补了原始MLlib库的不足,向用户提供了一个基于DataFrame的机器学习工作流套件。
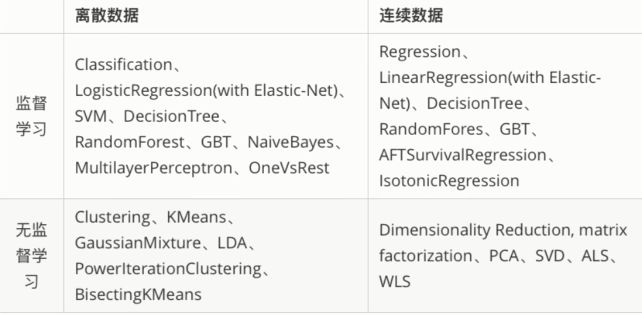
ML库提供了三个主要的抽象类:
-
转换器(Transformer):实现了一个方法.transform(),通常通过将一个或多个新列附加到DataFrame来转换为新的DataFrame。比如一个模型就是一个转换器,他可以把一个不包含预测标签的数据集打上标签。
-
评估器(Estimator):它是学习算法或在训练数据上的训练方法的抽象概念。在Pipeline里通常被用来操作一个DataFrame数据并生成一个Transformer。评估器实现了一个.fit()方法。比如随机森林算法就是一个评估器,它可以调用fit()方法训练特征数据从而得到一个随机森林模型。ML库目前包含的算法见上图。
-
管道(Pipeline):管道的概念用来表示从转换到评估(具有一系列不同阶段)的端到端的过程,这个过程可以对输入的一些原始数据(以DataFrame形式)执行必要的数据加工(转换),最后评估统计模型,返回PipelineModel。
pipeline(stages=[stage1,stage2,stage3,...])
在Pipeline对象上执行.fit()方法时,所有阶段按照stages参数中指定的顺序执行。
stages参数是转换器和评估器对象的列表。
管道对象的.fit()方法执行每个转换器的.transform()方法和所有评估器的.fit()方法。 通常,前一阶段的输出会成为下一阶段的输入。
常见的特征转换
import pyspark.ml.feature as ft
from pyspark.ml import Pipeline
连续型变量分箱
Binarizer:根据指定的阈值将连续变量二分类
Bucketizer:根据阈值列表将连续变量离散化
QuantileDiscretizer:传递一个numBuckets参数通过计算数据的近似分位数分隔
df=spark.sql('select id,age from people')
discretizer=ft.QuantileDiscretizer(
numBuckets=5,
inputCol='age',
outputCol='discretized'
)
qdModel=discretizer.fit(df)
discretized=qdModel.transform(df)
# 获得分箱节点
qdModel.getSplits()
特征索引化:StringIndexer转换器可以把一列字符型特征(或label)进行编码,使其数值化。使得某些无法使用类别型特征的算法可以使用,并提高决策树等机器学习算法的效率。
索引的范围从0开始,索引构建的顺序为字符标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为0。
与StringIndexer相对应,IndexToString的作用是把特征索引的一列重新映射回原有的字符标签。
# 特征索引化
indexer=ft.StringIndexer(inputCol='discretized',outputCol='indexed')
indexed=indexer.fit(df).transform(df)
# 索引特征重新映射回字符
toString=ft.IndexToString(inputCol='indexed',outputCol='discretized')
indexString=toString.transform(indexed)
向量索引化:之前介绍的StringIndexer只对单个特征进行转换,如果所有特征已经本合并到特征向量features中,又想对其中某些单个分量进行处理时,ML包提供了VectorIndexer转化器来执行向量索引化。
VectorIndexer基于不同特征的数量来识别类别型,maxCategorise参数提供一个阈值,超过阈值的将被认为是类别型,会被索引化。
indexer=ft.VectorIndexer(
inputCol='features',
outputCol='indexed',
maxCategorise=2
)
indexerModel=indexer.fit(df)
indexed=indexerModel.transform(df)
# 获取被转换的特征及其映射
CategoricalFeatures=indexerModel.categoryMaps
one-hot 编码:OneHotEncoder方法来对discretized列进行编码。但是,该方法不接受StringType列,它只能处理数值类型,需要对特征进行索引化。
indexer=ft.StringIndexer(inputCol='discretized',outputCol='indexed')
index_model=indexer.fit(df)
indexed=index_model.transform(df)
encoder=ft.OneHotEncoder(inputCol='indexed',outputCol='encoded')
encoded=encoder.transform(indexed)
# 保存/加载索引化模型和one-hot模型
index_model.save('./index_model')
encoder.save('./one_hot_model')
index_model=ft.StringIndexerModel.load('./index_model')
encoder=ft.OneHotEncoder.load('./one_hot_model')
连续型标准化
MaxAbsScaler:将数据标准化到[-1.0,1.0]范围内
MinMaxScaler:将数据标准化到[0.0,1.0]范围内
StandardScaler:标准化列,使其拥有零均值和等于1的标准差。
Normalizer:该方法使用p范数将数据缩放为单位范数(默认为L2)
# 需要创建一个向量代表连续变量
vectorizer=ft.VectorAssemmbler(
inputCols=['age'],
outputCol='vector'
)
normalizer=ft.StandardScaler(
inputCols=vectorizer.getOutputCol(),
outputCol='normalized',
withMean=True,
withStd=True
)
pipeline=Pipeline(stages=[vectorizer,normalizer])
dataStandardized=pipeline.fit(df).transform(df)
其他常用转换器
VectorAssembler:特征向量化,将多个数字(包括向量)列合并为一列向量。常用于生成评估器的 featuresCol参数。
ChiSqSelector:对于分类目标变量,特征筛选
PCA:使用主成分分析执行数据降维
Imputer:用于完成缺失值的插补估计器,使用缺失值所在列的平均值或中值。
模型拟合和描述
加载数据:以 iris 数据集为例
>>> import pyspark.feature as ft
>>> df = spark.read.csv("iris.csv.gz",header=True)
>>> df.show(5)
+------+------------+-----------+------------+-----------+-------+
|row.id|Sepal.Length|Sepal.Width|Petal.Length|Petal.Width|Species|
+------+------------+-----------+------------+-----------+-------+
| 1| 5.1| 3.5| 1.4| 0.2| setosa|
| 2| 4.9| 3.0| 1.4| 0.2| setosa|
| 3| 4.7| 3.2| 1.3| 0.2| setosa|
| 4| 4.6| 3.1| 1.5| 0.2| setosa|
| 5| 5.0| 3.6| 1.4| 0.2| setosa|
+------+------------+-----------+------------+-----------+-------+
only showing top 5 rows
>>> labelIndexer=ft.StringIndexer(
inputCol='Species',
outputCol='label'
).fit(df)
创建特征向量:将所有的特征整合到单一列(评估器必须)
featuresCreator=ft.VectorAssembler(
inputCols=list(df.columns)[1:-1],
outputCol='features'
)
创建评估器
from pyspark.ml.classification import LogisticRegression
# 创建评估器,指定特征向量和label
logistic = LogisticRegression(maxIter=10,
regParam=0.01,
featuresCol=featuresCreator.getOutputCol(),
labelCol='label')
创建管道
from pyspark.ml import Pipeline
pipeline=Pipeline(stages=[labelIndexer,featuresCreator,logistic])
拟合模型
train,test=df.randomSplit([0.7,0.3],seed=42) # 拆分训练集和测试集
model=pipeline.fit(train)
test_model=model.transform(test)
# lrModel位于管道的对应位置,可以提取并获得模型参数
lrModel=model.stages[2]
print(lrModel.coefficientMatrix)
print(lrModel.interceptVector)
管道通过调用.fit()方法返回用于预测的PipelineModel对象,将之前创建的测试集传递给.transform()方法获得预测。
logistic 模型模型输出了几列:rawPrediction是特征和β系数的线性组合的值,probability是为每个类别计算出的概率,最后prediction是最终的类分配。
模型评估
import pyspark.ml.evaluation as ev
evaluator=ev.MulticlassClassificationEvaluator(rawPredictionCol='probability',labelCol='label')
# rawPredictionCol可以是由评估器产生的rawprediction列,也可以是probability
accuracy=evaluator.evaluate(test) # 准确率
evaluator.evaluate(test,{
evaluator.metricName:'areaUnderROC'})
evaluator.evaluate(test,{
evaluator.metricName:'areaUnderPR'})
evaluator.setMetricName('f1').evaluate(test)
保存模型:PySpark允许保存管道定义以备以后使用。不仅可以保存管道结构,还可以保存所有转换器和评估器的定义:
pipelinePath="./pipeline"
pipeline.write().overwrite().save(pipelinePath)
# 可以随后加载,直接使用.fit()方法并预测
loadedPipeLine=Pipeline.load(pipelinePath)
test_model=loadedPipeLine.fit(train).transform(test)
# 还可以直接保存Pipeline模型,随后加载重用
from pyspark.ml import PipelineModel
modelPath="./pipelineModel"
model.write().overwrite().save(modelPath)
loadedModel=PipelineModel.load(modelPath)
test_model=loadedModel.transform(test)
超参调优
网格搜索+交叉验证:是一个详尽的算法,根据给定评估指标,循环遍历定义的参数值列表,估计各个单独的模型,从而选定一个最佳模型。
import pyspark.ml.tuning as tune
logistic = LogisticRegression(
featuresCol='features',
labelCol='label'
)
# 指定参数的列表
grid = tune.ParamGridBuilder() \
.addGrid(logistic.maxIter, [2, 10, 50]) \
.addGrid(logistic.regParam, [0.01, 0.05, 0.3]).build()
# 指定调优指标
evaluator=ev.MulticlassClassificationEvaluator(rawPredictionCol='probability',labelCol='label')
# 数据转化
pipeline = Pipeline(stages=[labelIndexer,featuresCreator])
data_transformer = pipline.fit(train)
# 交叉验证
cv = tune.CrossValidator(estimator=logistic,
estimatorParamMaps=grid,
evaluator=evalutor
)
# 拟合模型(cvModel将返回估计的最佳模型)
cvModel = cv.fit(data_transformer.transform(train))
# 模型评估
data_test = data_transformer.transform(test)
results = cvModel.transform(data_test)
accuracy=evaluator.evaluate(test) # 准确率
最佳模型的参数提取起来比较复杂,代码如下
results = [
(
[
{
key.name: paramValue}
for key, paramValue in zip(params.key(),
params.values())
], metric)
for params, metric in zip(
cvModel.getEstimatorParamMaps(),
cvModel.avgMetrics)
]
sorted(results,
key=lambda el: el[1],
reversed=True)[0]
网格搜索+Train-validation划分:为了选择最佳模型,TrainValidationSplit模型对输入的数据集(训练数据集)执行随机划分,划分成两个子集:较小的训练集和验证集。划分仅执行一次。
本例中,我们还是使用ChiSqSelector只选出前五个特征,以此来限制模型的复杂度:
import pyspark.ml.tuning as tune
# 特征筛选
selector=ft.ChiSqSelector(
numTopFeatures=5, # 指定要返回的特征数量
featuresCol=featuresCreator.getOutputCol(),
outputCol='selectedFeatures'
labelCol='label'
)
logistic = LogisticRegression(
featuresCol='selectedFeatures',
labelCol='label'
)
# 指定参数的列表
grid = tune.ParamGridBuilder() \
.addGrid(logistic.maxIter, [2, 10, 50]) \
.addGrid(logistic.regParam, [0.01, 0.05, 0.3]).build()
# 指定调优指标
evaluator=ev.MulticlassClassificationEvaluator(rawPredictionCol='probability',labelCol='label')
# 数据转化
pipeline = Pipeline(stages=[labelIndexer,featuresCreator,selector])
data_transformer = pipline.fit(train)
# Train-validation划分
tvs = tune.TrainValidationSplit(estimator=logistic,
estimatorParamMaps=grid,
evaluator=evalutor
)
# 拟合模型(cvModel将返回估计的最佳模型)
tvsModel = tvs.fit(data_transformer.transform(train))
# 模型评估
data_test = data_transformer.transform(test)
results = tvsModel.transform(data_test)
accuracy=evaluator.evaluate(test) # 准确率
参考链接:
-
Spark 编程基础 - 厦门大学 | 林子雨
-
Spark基本架构及运行原理
-
Spark入门介绍(菜鸟必看)
-
Spark 修炼之道
-
PySpark教程 | 编程字典
-
SparkSQL(Spark-1.4.0)实战系列
-
Machine Learning On Spark