神经网络--CNN的池化、激活函数、批处理归一化Batch Normalization
转自《百度人工智能学习课程》
如有侵权,请告知作者删除。感谢!
1. 池化(Pooling)
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。比如:当识别一张图像是否是人脸时,我们需要知道人脸左边有一只眼睛,右边也有一只眼睛,而不需要知道眼睛的精确位置,这时候通过池化某一片区域的像素点来得到总体统计特征会显得很有用。由于池化之后特征图会变得更小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。 如 图15 所示,将一个 2 × 2 2\times 2 2×2的区域池化成一个像素点。通常有两种方法,平均池化和最大池化。
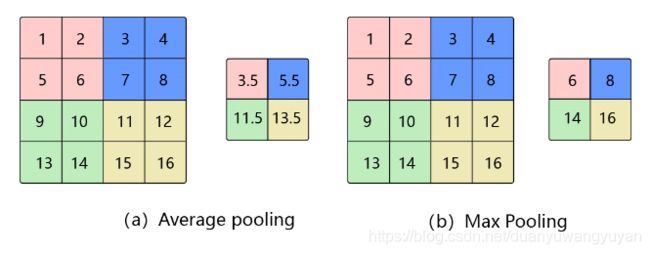
- 如图15(a):平均池化。这里使用大小为 2 × 2 2\times2 2×2的池化窗口,每次移动的步幅为2,对池化窗口覆盖区域内的像素取平均值,得到相应的输出特征图的像素值。
- 如图15(b):最大池化。对池化窗口覆盖区域内的像素取最大值,得到输出特征图的像素值。当池化窗口在图片上滑动时,会得到整张输出特征图。池化窗口的大小称为池化大小,用 k h × k w k_h \times k_w kh×kw表示。在卷积神经网络中用的比较多的是窗口大小为 2 × 2 2 \times 2 2×2,步幅为2的池化。
与卷积核类似,池化窗口在图片上滑动时,每次移动的步长称为步幅,当宽和高方向的移动大小不一样时,分别用 s w s_w sw和 s h s_h sh表示。也可以对需要进行池化的图片进行填充,填充方式与卷积类似,假设在第一行之前填充 p h 1 p_{h1} ph1行,在最后一行后面填充 p h 2 p_{h2} ph2行。在第一列之前填充 p w 1 p_{w1} pw1列,在最后一列之后填充 p w 2 p_{w2} pw2列,则池化层的输出特征图大小为:
H o u t = H + p h 1 + p h 2 − k h s h + 1 H_{out} = \frac{H+p_{h1}+p_{h2}-k_{h}}{s_{h}} + 1 Hout=shH+ph1+ph2−kh+1
W o u t = W + p w 1 + p w 2 − k w s w + 1 W_{out} = \frac{W+p_{w1}+p_{w2}-k_{w}}{s_{w}} + 1 Wout=swW+pw1+pw2−kw+1
在卷积神经网络中,通常使用2×2大小的池化窗口,步幅也使用2,填充为0,则输出特征图的尺寸为:
H o u t = H 2 H_{out} = \frac{H}{2} Hout=2H
W o u t = W 2 W_{out} = \frac{W}{2} Wout=2W
通过这种方式的池化,输出特征图的高和宽都减半,但通道数不会改变。
2. 激活函数
在神经网络发展的早期,Sigmoid激活函数用的比较多,而目前用的较多的激活函数是ReLU。这是因为Sigmoid函数在反向传播过程中,容易造成梯度的衰减。让我们仔细观察Sigmoid函数的形式,就能发现这一问题。
- Sigmoid激活函数定义如下:
y = 1 1 + e − x y = \frac{1}{1 + e^{-x}} y=1+e−x1
- ReLU激活函数的定义如下:
y = { 0 , ( x < 0 ) x , ( x ≥ 0 ) y= \begin{cases} 0, & {(x<0)} \\ x, &{(x\geq0)} \end{cases} y={ 0,x,(x<0)(x≥0)
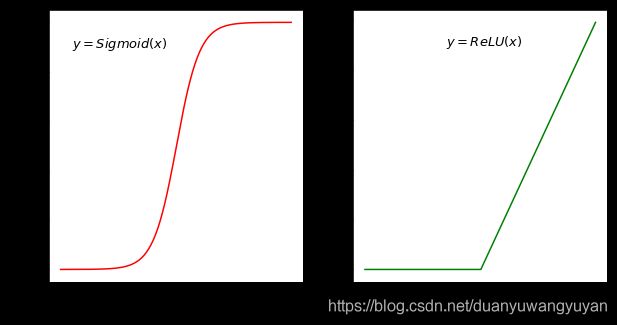
2.1 梯度消失现象
在神经网络里,将经过反向传播之后,梯度值衰减到接近于零的现象称作梯度消失现象。
从上面的函数曲线可以看出,当xxx为较大的正数的时候,Sigmoid函数数值非常接近于1,函数曲线变得很平滑,在这些区域Sigmoid函数的导数接近于零。当xxx为较小的负数时,Sigmoid函数值也非常接近于0,函数曲线也很平滑,在这些区域Sigmoid函数的导数也接近于0。只有当xxx的取值在0附近时,Sigmoid函数的导数才比较大。对Sigmoid函数求导数,结果如下所示:
d y d x = − 1 ( 1 + e − x ) 2 ⋅ d ( e − x ) d x = 1 2 + e x + e − x \frac{dy}{dx} = -\frac{1}{(1+e^{-x})^2} \cdot \frac{d(e^{-x})}{dx} = \frac{1}{2 + e^x + e^{-x}} dxdy=−(1+e−x)21⋅dxd(e−x)=2+ex+e−x1
从上面的式子可以看出,Sigmoid函数的导数 d y d x \frac{dy}{dx} dxdy最大值为 1 4 \frac{1}{4} 41。前向传播时, y = S i g m o i d ( x ) y=Sigmoid(x) y=Sigmoid(x);而在反向传播过程中,x的梯度等于y的梯度乘以Sigmoid函数的导数,如下所示:
∂ L ∂ x = ∂ L ∂ y ⋅ ∂ y ∂ x \frac{\partial{L}}{\partial{x}} = \frac{\partial{L}}{\partial{y}} \cdot \frac{\partial{y}}{\partial{x}} ∂x∂L=∂y∂L⋅∂x∂y使得xxx的梯度数值最大也不会超过y的梯度的 1 4 \frac{1}{4} 41 。
由于最开始是将神经网络的参数随机初始化的,xxx的取值很有可能在很大或者很小的区域,这些地方都可能造成Sigmoid函数的导数接近于0,导致x的梯度接近于0;即使x取值在接近于0的地方,按上面的分析,经过Sigmoid函数反向传播之后,x的梯度不超过yyy的梯度的 1 4 \frac{1}{4} 41,如果有多层网络使用了Sigmoid激活函数,则比较靠后的那些层梯度将衰减到非常小的值。
ReLU函数则不同,虽然在 x < 0 x\lt 0 x<0的地方,ReLU函数的导数为0。但是在 x ≥ 0 x\ge 0 x≥0的地方,ReLU函数的导数为1,能够将yyy的梯度完整的传递给x,而不会引起梯度消失。
3. 批处理归一化Batch Normalization
批归一化方法(Batch Normalization,BatchNorm)是由Ioffe和Szegedy于2015年提出的,已被广泛应用在深度学习中,其目的是对神经网络中间层的输出进行标准化处理,使得中间层的输出更加稳定。
通常我们会对神经网络的数据进行标准化处理,处理后的样本数据集满足均值为0,方差为1的统计分布,这是因为当输入数据的分布比较固定时,有利于算法的稳定和收敛。对于深度神经网络来说,由于参数是不断更新的,即使输入数据已经做过标准化处理,但是对于比较靠后的那些层,其接收到的输入仍然是剧烈变化的,通常会导致数值不稳定,模型很难收敛。BatchNorm能够使神经网络中间层的输出变得更加稳定,并有如下三个优点:
-
使学习快速进行(能够使用较大的学习率)
-
降低模型对初始值的敏感性
-
从一定程度上抑制过拟合
BatchNorm主要思路是在训练时以mini-batch为单位,对神经元的数值进行归一化,使数据的分布满足均值为0,方差为1。