HBase概念介绍及典型案例分析
本文来自于2018年10月20日由中国 HBase 技术社区在武汉举办的中国 HBase Meetup 第六次线下交流会。分享者为过往记忆。
目录
一、简单介绍一下 HBase 是什么
二、 HBase 是如何读写数据的
三、RowKey的设计要点
四、HBase 生态介绍
五、HBase 典型案例分析
一、简单介绍一下 HBase 是什么

HBase 最开始是受 Google 的 BigTable 启发而开发的分布式、多版本、面向列的开源数据库。其主要特点是支持上亿行、百万列,支持强一致性、并且具有高扩展、高可用等特点。
既然 HBase 是一种分布式的数据库,那么其和传统的 RMDB 有什么区别的呢?我们先来看看HBase表核心概念,理解这些基本的核心概念对后面我理解 HBase 的读写以及如何设计 HBase 表有着重要的联系。
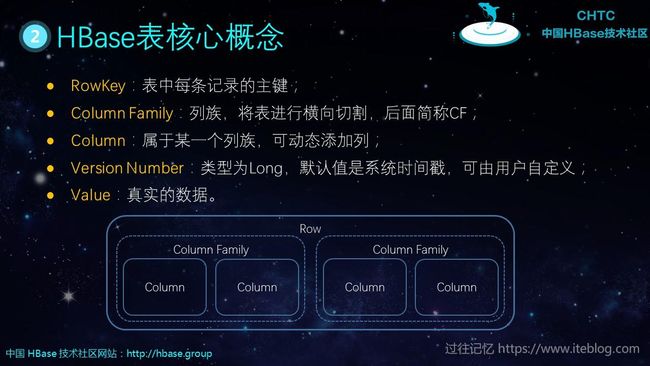
HBase 表主要由以下几个元素组成:
- RowKey:表中每条记录的主键;
- Column Family:列族,将表进行横向切割,后面简称CF;Region : 水平 拆分, Store :一个列族, 垂直 拆分
- Column:属于某一个列族,可动态添加列;
- Version Number:类型为Long,默认值是系统时间戳,可由用户自定义;
- Value:真实的数据。
大家可以从上面的图看出:一行(Row)数据是可以包含一个或多个 Column Family,但是我们并不推荐一张 HBase 表的 Column Family 超过三个。Column 是属于 Column Family 的,一个 Column Family 包含一个或 多个 Column。
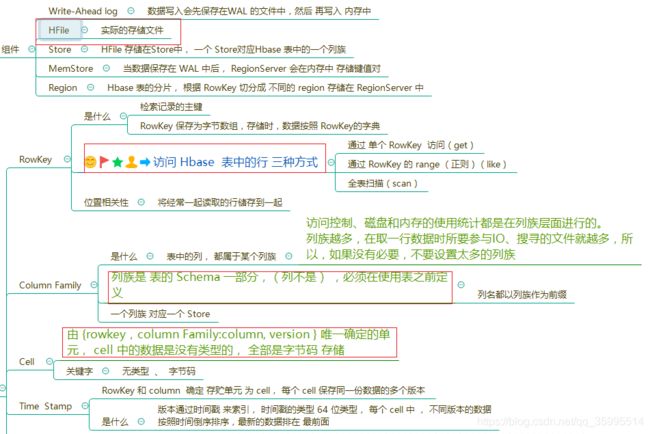
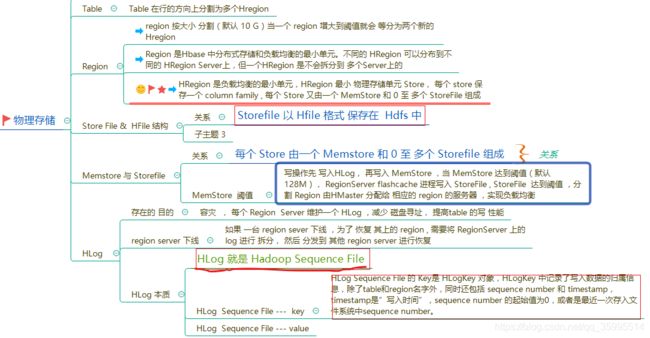
在物理层面上,所有的数据其实是存放在 Region 里面的,而 Region 又由 RegionServer 管理,其对于的关系如下:
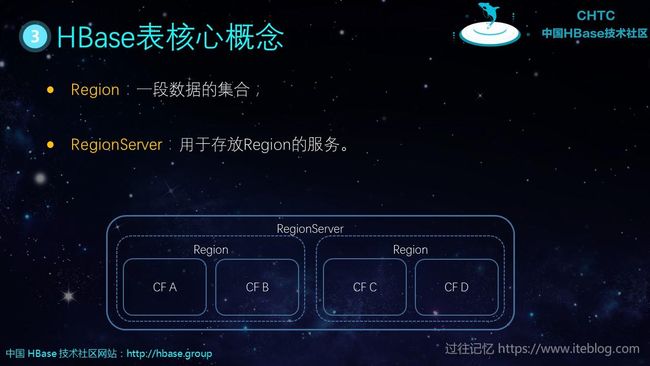
- Region:一段数据的集合;
- RegionServer:用于存放Region的服务。
从上面的图也可以清晰看到,一个 RegionServer 管理多个 Region;而一个 Region 管理一个或多个 Column Family。
到这里我们已经了解了 HBase 表的组成,但是 HBase 表里面的数据到底是怎么存储的呢?
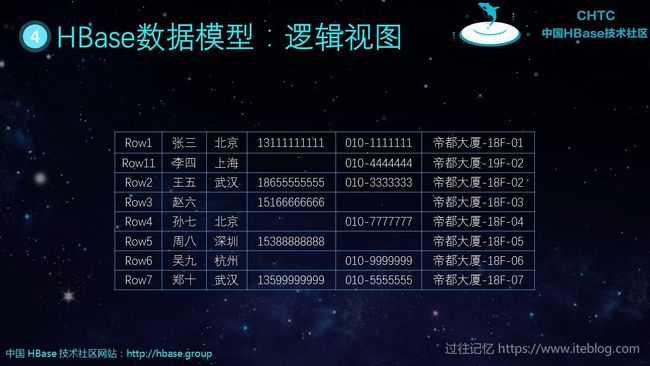
上面是一张从逻辑上看 HBase 表形式,这个和关系型数据库很类似。那么如果我们再深入看,可以看出,这张表的划分可以如下图表示。
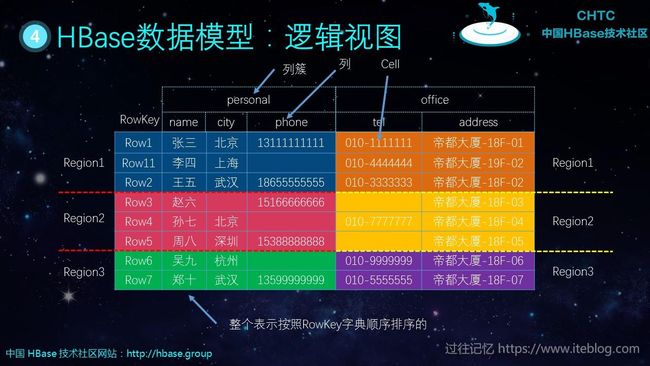
从上图大家可以明显看出,这张表有两个 Column Family ,分别为 personal 和 office。而 personal 又有三列name、city 以及 phone;office 有两列 tel 以及 address。由于存储在 HBase 里面的表一般有上亿行,所以 HBase 表会对整个数据按照 RowKey 进行字典排序,然后再对这张表进行横向切割。切割出来的数据是存储在 HFile 里面,而不同的 Column Family 虽然属于一行,但是其在底层存储是放在不同的 HFile 里。所以这张表我用了六种颜色表示,也就是说,这张表的数据会被放在六个 HFile 里面的,这就可以把数据尽可能的分散到整个集群。
在前面我们介绍了 HBase 其实是面向列的数据库,所以说一行 HBase 的数据其实是分了好几行存储,一个列 对应一行,HBase 的 KV 结构如下:
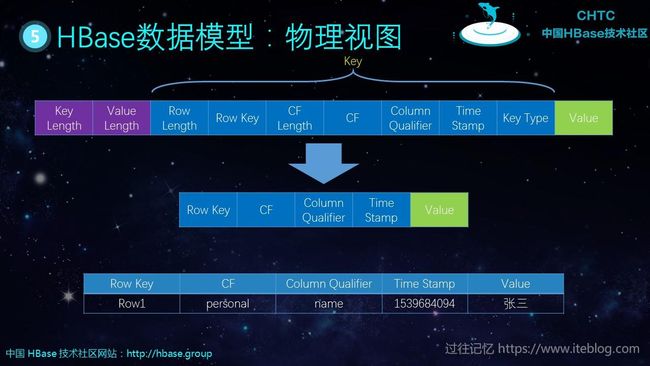
为了简便起见,在后面的表示我们删除了类似于 Key Length 的属性,只保留 Row Key、Column Family、Column Qualifier等信息。所以 RowKey 为 Row1 的数据第一列表示为上图最后一行的形式。以此类推,整个表的存储就可以如下表示:
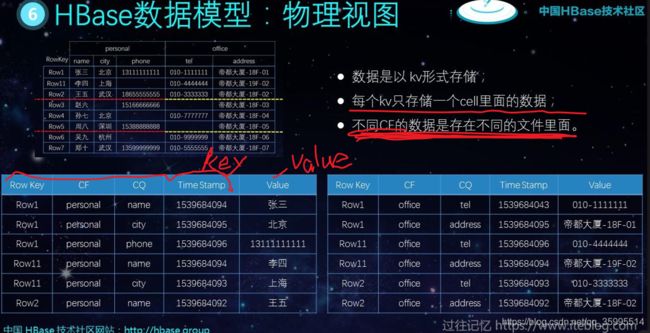
大家可以从上面的 kv 表现形式看出,Row11 的 phone 这列其实是没有数据的,在 HBase 的底层存储里面也就没有存储这列了,这点和我们传统的关系型数据库有很大的区别,有了这个特点, HBase 特别适合存储稀疏表。
我们前面也将了 HBase 其实是多版本的,那如果我们修改了 HBase 表的一列,HBase 又是如何存储的呢?
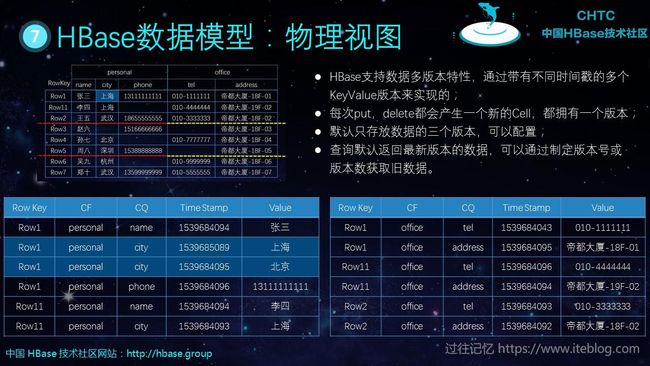
比如上图中我们将 Row1 的 city 列从北京修改为上海了,如果使用 KV 表示的话,我们可以看出其实底层存储了两条数据,这两条数据的版本是不一样的,最新的一条数据版本比之前的新。总结起来就是:
- HBase支持数据多版本特性,通过带有不同时间戳的多个KeyValue版本来实现的;
- 每次put,delete都会产生一个新的Cell,都拥有一个版本;
- 默认只存放数据的三个版本,可以配置;
- 查询默认返回最新版本的数据(排序实现),可以通过制定版本号或版本数获取旧数据。
二、 HBase 是如何读写数据的
到这里我们已经了解了 HBase 表及其底层的 KV 存储了,现在让我们来了解一下 HBase 是如何读写数据的。首先我们来看看 HBase 的架构设计,这种图来自于社区:
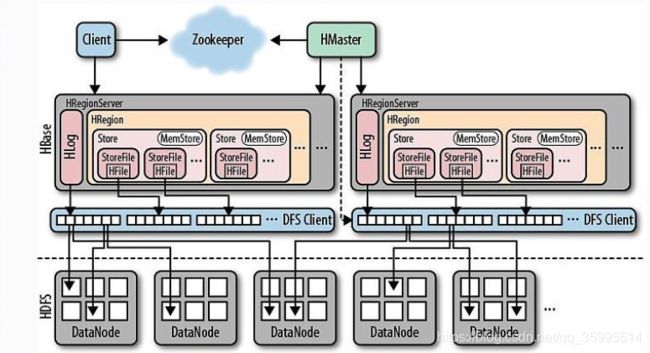
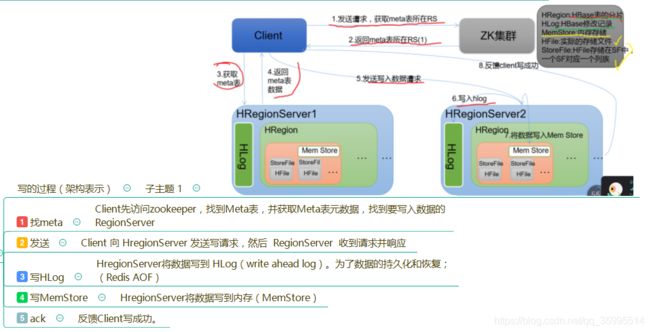
HBase 的写过程如下:
- 先将数据写到WAL(Write-Ahead Logging 预写日志----HLog)中;
- WAL 存放在HDFS之上;
- 每次Put、Delete操作的数据均追加到WAL末端;
- 持久化到WAL之后,再写到MemStore中;
- 两者写完返回ACK到客户端。
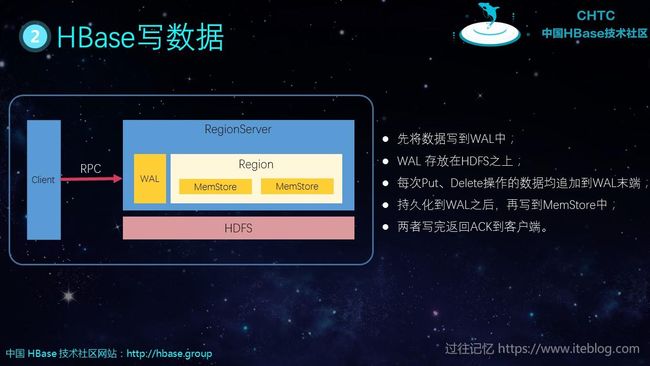
MemStore (数据有序)其实是一种内存结构
- 一个Store 对应一个 ColumnFamily
- 一个Column Family 对应一个MemStore
MemStore 里面的数据也是对 Rowkey 进行字典排序的,如下:

既然我们写数据都是先写 WAL,再写 MemStore ,而 MemStore 是内存结构,所以 MemStore 总会写满的,
将 MemStore 的数据从内存刷写到磁盘的操作成为 flush:
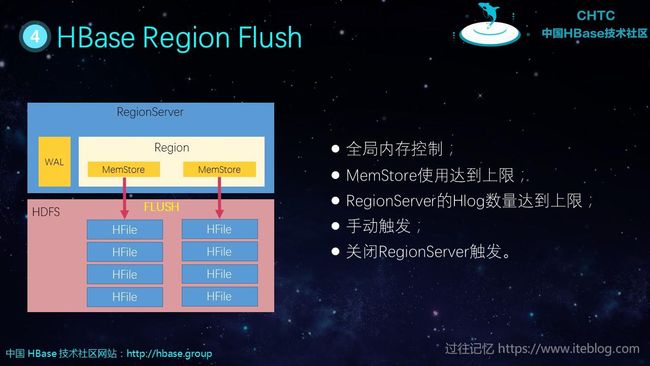
以下几种行为会导致 flush 操作
- 全局内存控制;
- MemStore使用达到上限;
- RegionServer的Hlog数量达到上限;
- 手动触发;
- 关闭RegionServer触发。

每次 flush 操作都是将一个 MemStore 的数据写到一个 HFile 里面的,所以上图中 HDFS 上有许多个 HFile 文件。文件多了会对后面的读操作有影响,所以 HBase 会隔一定的时间将 HFile 进行合并。
HFile Compaction
根据合并的范围不同分为 Minor Compaction 和 Major Compaction:
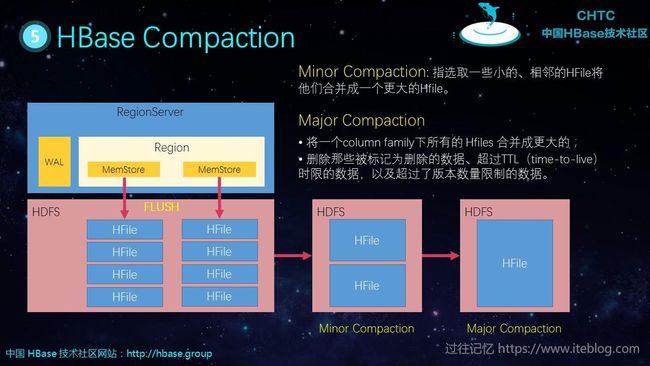
Minor Compaction: 指选取一些小的、相邻的HFile将他们合并成一个更大的Hfile。
Major Compaction:
- 将一个column family下所有的 Hfiles 合并成更大的;
- 删除那些被标记为删除的数据、超过TTL(time-to-live)时限的数据,以及超过了版本数量限制的数据。

HBase 读操作
相对于写操作更为复杂,其需要读取 BlockCache、MemStore 以及 HFile。
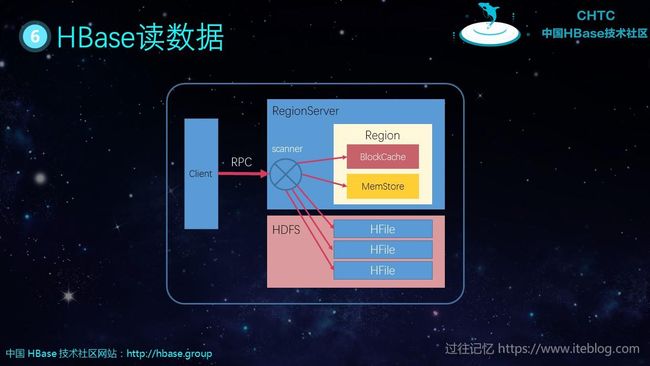
上图只是简单的表示 HBase 读的操作,实际上读的操作比这个还要复杂,我这里就不深入介绍了。
Hbase 读流程
zookeeper元数据-----> 找region---->MemStore---> bolockStore-----> SotreFile 找到回写blockStore ---->HFile
到这里,有些人可能就想到了,前面我们说 HBase 表按照 Rowkey 分布到集群的不同机器上,那么我们如何去确定我们该读写哪些 RegionServer 呢?
这就是 HBase Region 查找的问题
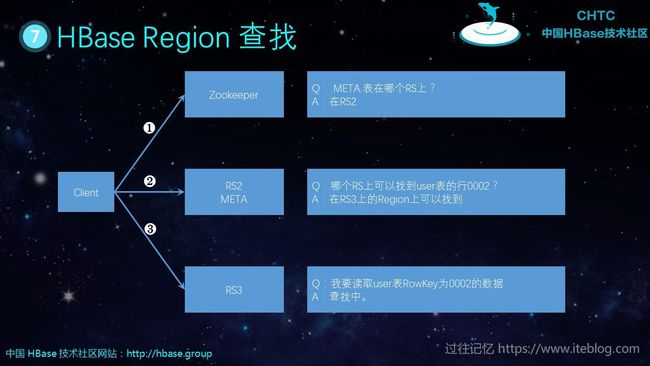
客户端按照上面的流程查找需要读写的 RegionServer 。这个过程一般是第一次读写的时候进行的,在第一次读取到元数据之后客户端一般会把这些信息缓存到自己内存中,后面操作直接从内存拿就行。当然,后面元数据信息可能还会变动,这时候客户端会再次按照上面流程获取元数据。
三、RowKey的设计要点
现在我们来看看 HBase RowKey 的设计要点。我们一般都会说,看 HBase 设计的好不好,就看其 RowKey 设计的好不好,所以RowKey 的设计在后面的写操作至关重要。我们先来看看 Rowkey 的作用
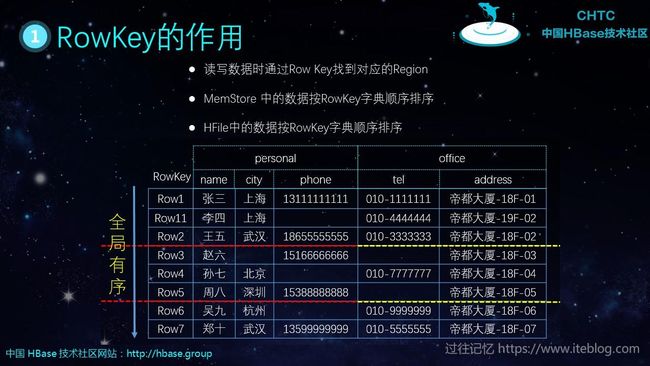
- 读写数据时通过Row Key找到对应的Region
- MemStore 中的数据按 RowKey 字典顺序排序
- HFile 中的数据按RowKey字典顺序排序
从下图可以看到,底层的 HFile 最终是按照 Rowkey 进行切分的,所以我们的设计原则是结合业务的特点,并考虑高频查询,尽可能的将数据打散到整个集群。

一定要充分分析清楚后面我们的表需要怎么查询。下面我们来看看三种比较场景的 Rowkey 设计方案。

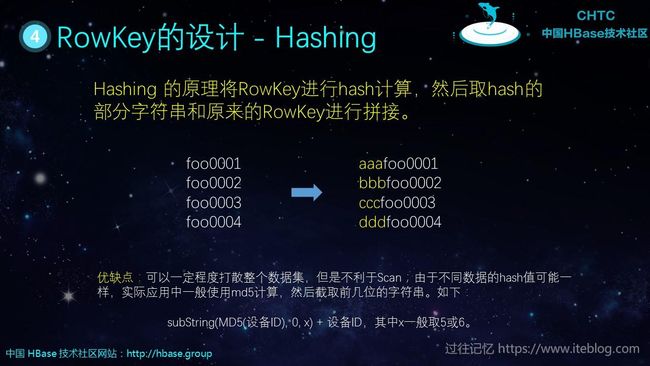

这三种 Rowkey 的设计非常常见,具体的内容图片上也有了,我就不打文字了。
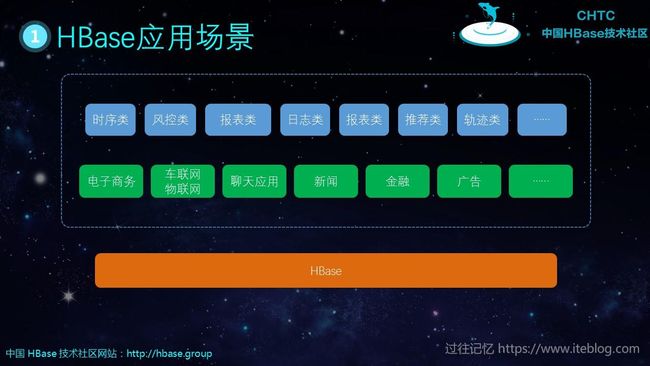
数据如果只是存储在哪里其实并没有什么用,我们还需要有办法能够使用到里面的数据。幸好的是,当前 HBase 有许多的组件可以满足我们各种需求。
四、HBase 生态介绍
如下图是 HBase 比较常用的组件:
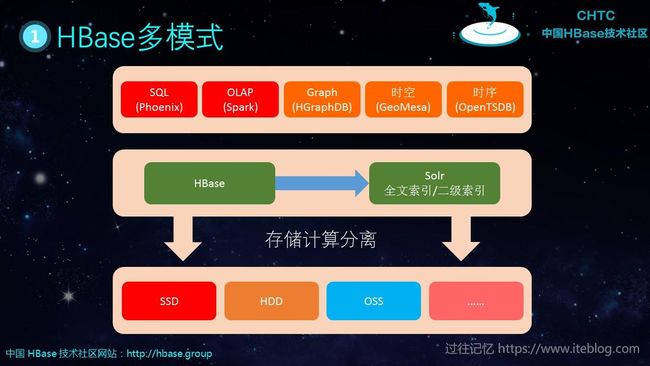
HBase 的生态主要有:
- Phoenix:主要提供使用 SQL 的方式来查询 HBase 里面的数据。一般能够在毫秒级别返回,比较适合 OLTP 场景。
- Spark:我们可以使用 Spark 进行 OLAP 分析;也可以使用 Spark SQL 来满足比较复杂的 SQL 查询场景;使用 Spark Streaming 来进行实时流分析。
- Solr:原生的 HBase 只提供了 Rowkey 单主键,如果我们需要对 Rowkey 之外的列进行查找,这时候就会有问题。幸好我们可以使用 Solr 来建立二级索引/全文索引充分满足我们的查询需求。
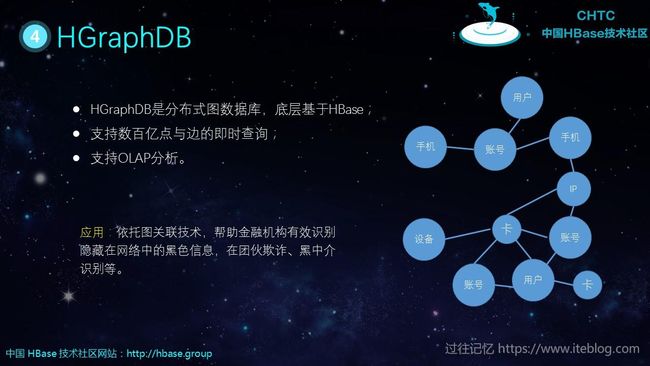
- HGraphDB:HGraphDB是分布式图数据库。依托图关联技术,帮助金融机构有效识别隐藏在网络中的黑色信息,在团伙欺诈、黑中介识别等。
- GeoMesa:目前基于NoSQL数据库的时空数据引擎中功能最丰富、社区贡献人数最多的开源系统。
- OpenTSDB:基于HBase的分布式的,可伸缩的时间序列数据库。适合做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储,查询。
下面简单介绍一下这些组件。





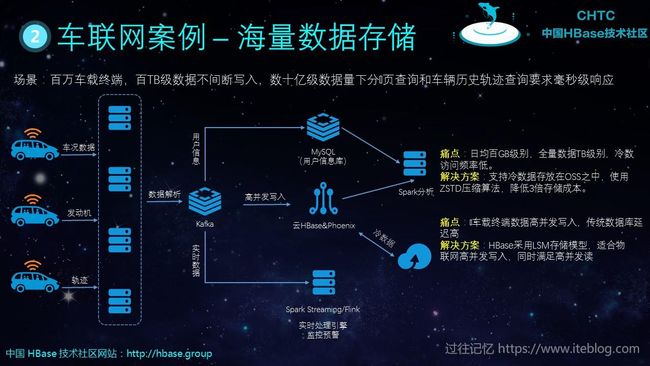
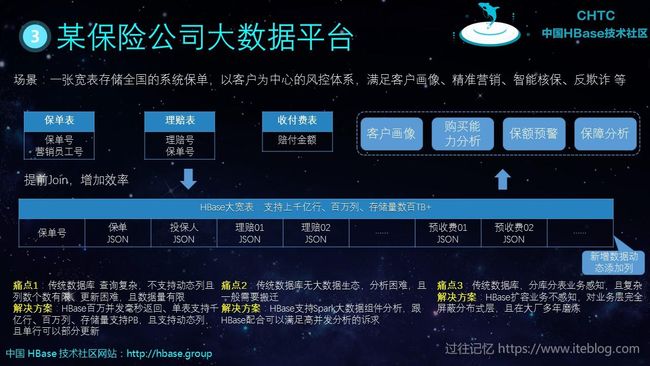
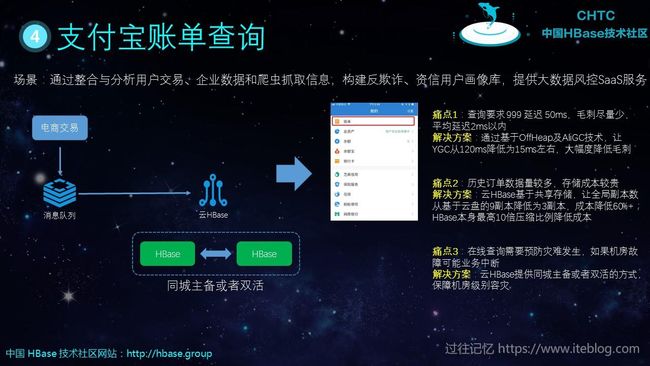
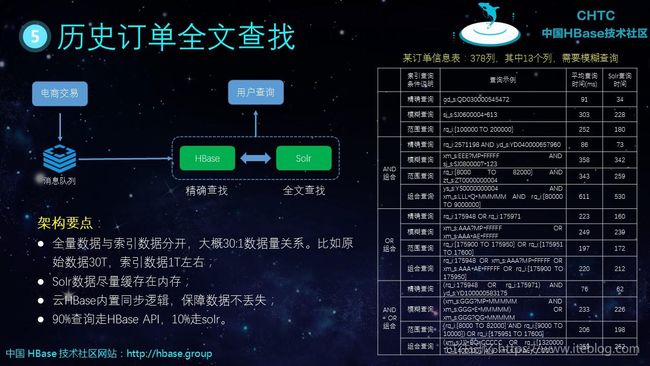
五、HBase 典型案例分析
HBase 在风控场景、车联网/物联网、广告推荐、电子商务等行业有这广泛的使用。下面是四个典型案例的架构,由于图片里有详细的文字。