六、特征工程
传统编程的关注点是代码。在机器学习项目中,关注点变成了特征表示。也就是说,开发者通过添加和改善特征来调整模型。
特征工程指的是将原始数据转换为特征矢量。
1、特征映射
(1)映射数值
整数和浮点数据不需要特殊编码,因为它们可以与数字权重相乘。例如,将原始整数值 6 转换为特征值 6.0 并没有多大的意义。
(2)映射分类值
分类特征具有一组离散的可能值,可能为字符串或其他可能的类型。由于模型不能将字符串与学习到的权重相乘,因此我们需要使用特征工程将字符串转换为数字值。
我们可以定义一个从特征值(词汇表)到整数的映射。但是如果词汇表中的特征值之间并没有一定的线性关系那么直接映射为数值将额外的引入一些问题。
当词汇表中的特征值之间没有线性关系时通常采用如下的方式(独热编码)。
为模型中的每个分类特征创建一个二元向量来表示这些值,对于适用于样本的值,将相应向量元素设为1,将所有其他元素设为0。
该向量的长度等于词汇表中的元素数。当只有一个值为 1 时,这种表示法称为独热编码;当有多个值为 1 时,这种表示法称为多热编码。
独热编码会扩展到不希望直接与权重相乘的数字数据,例如邮政编码。
稀疏表示,一种张量表示法,仅存储非零元素。
2、良好特征的特点
(1)避免很少使用的离散特征值
良好的特征值应该在数据集中出现大约 5 次以上。如果某个特征的值仅出现一次或者很少出现,则模型就无法根据该特征进行预测。
(2)最好具有清晰明确的含义
每个特征对于项目中的任何人来说都应该具有清晰明确的含义,不应该是某种含义不清的编码。
(3)实际数据内不要掺入特殊值
良好的浮点特征不包含超出范围的异常断点或特殊的值。
为解决特殊值的问题,需将该特征转换为两个特征。一个特征只存储正常值,不含特殊值;一个特征存储布尔值,表示该值是否缺失。
(4)考虑上游不稳定性
特征的定义不应随时间发生变化。
3、数据清理
作为一名机器学习工程师,您将花费大量的时间挑出坏样本并加工可以挽救的样本。
(1)缩放特征值
缩放是指将浮点特征值从自然范围(例如 100 到 900)转换为标准范围(例如 0 到 1 或 -1 到 +1)。
如果特征集包含多个特征,则缩放特征可以带来以下优势:
-帮助梯度下降法更快速地收敛。
-帮助避免“NaN 陷阱”。
-帮助模型为每个特征确定合适的权重(模型会对范围较大的特征投入过多精力)。
(2)处理极端离群值
一种方法是对每个值取对数;
一种方法是将最大特征值“限制”为某个任意值。
(3)分箱
有时特征值变现为数值形式,但特征值的真实意义却并不存在线性关系。此时可以采用独热编码的方式进行分箱。
(4)清查
在现实生活中,数据集中的很多样本是不可靠的,原因有以下一种或多种:
-遗漏值。例如,有人忘记为某个房屋的年龄输入值。
-重复样本。例如,服务器错误地将同一条记录上传了两次。
-不良标签。例如,有人错误地将一颗橡树的图片标记为枫树。
-不良特征值。例如,有人输入了多余的位数,或者温度计被遗落在太阳底下。
直方图是一种用于可视化集合中数据的很好机制。
此外,收集如下统计信息也会有所帮助:
-最大值和最小值
-均值和中间值
-标准偏差
良好的机器学习依赖于良好的数据。
七、特征组合
特征组合是指通过将两个或多个输入特征相乘来对特征空间中的非线性规律进行编码的合成特征。
1、特征组合的种类
-[A X B]:将两个特征的值相乘形成的特征组合。
-[A x B x C x D x E]:将五个特征的值相乘形成的特征组合。
-[A x A]:对单个特征的值求平方形成的特征组合。
通过采用随机梯度下降法,可以有效地训练线性模型。因此,在使用扩展的线性模型时辅以特征组合一直都是训练大规模数据集的有效方法。
2、组合独热特征矢量
在实践中,机器学习模型很少会组合连续特征。不过,机器学习模型却经常组合独热特征矢量,将独热特征矢量的特征组合视为逻辑连接。
假设我们的模型需要根据以下两个特征来预测狗主人对狗狗的满意程度:行为类型(吠叫、叫、偎依等)和时段
假设对两个特征矢量创建了特征组合:[behavior type X time of day]
最终获得的预测能力将远远超过任一特征单独的预测能力,例如,如果狗狗在下午 5 点主人下班回来时(快乐地)叫喊,可能表示对主人满意度的正面预测结果。如果狗狗在凌晨 3 点主人熟睡时(也许痛苦地)哀叫,可能表示对主人满意度的强烈负面预测结果。
线性学习器可以很好地扩展到大量数据。对大规模数据集使用特征组合是学习高度复杂模型的一种有效策略。
3、组合过度
虽然特征组合可以让模型了解到特征之间的某些特定关联性,但是过度的特征组合会快速的增加模型的复杂度,很用易产生过拟合。
八、正则化
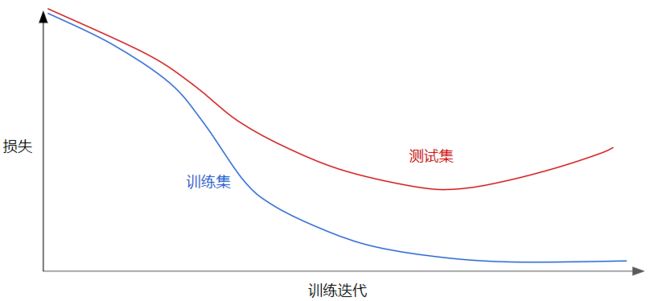
下显示的是某个模型的训练损失逐渐减少,但验证损失最终增加。换言之,该泛化曲线显示该模型与训练集中的数据过拟合。根据奥卡姆剃刀定律,我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。
经验风险最小化:
结构风险最小化:
此时训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度。
这里衡量模型复杂度的两种方式:
-将模型复杂度作为模型中所有特征的权重的函数。
-将模型复杂度作为具有非零权重的特征总数的函数。
L2正则化
在公式中,接近于 0 的权重对模型复杂度几乎没有影响,而离群值权重则可能会产生巨大的影响。
执行 L2正则化对模型具有以下影响:
-使权重值接近于 0(但并非正好为 0)
-使权重的平均值接近于 0,且呈正态(钟形曲线或高斯曲线)分布。
lambda
模型开发者通过以下方式来调整正则化项的整体影响:用正则化项的值乘以名为lambda(又称为正则化率)的标量。
在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡:
-lambda 值过高,则模型会非常简单,但是将面临数据欠拟合的风险。
-lambda 值过低,则模型会比较复杂,并且将面临数据过拟合的风险。
将 lambda 设为 0 可彻底取消正则化。在这种情况下,训练的唯一目的将是最小化损失,而这样做会使过拟合的风险达到最高。
理想的 lambda 值取决于数据,因此需要手动或自动进行一些调整。
假设某个线性模型具有两个密切相关的特征;也就是说,这两个特征几乎是彼此的副本,但其中一个特征包含少量的随机噪点。如果我们使用 L2 正则化训练该模型,会使特征的权重几乎相同,大约为模型中只有两个特征之一时权重的一半。