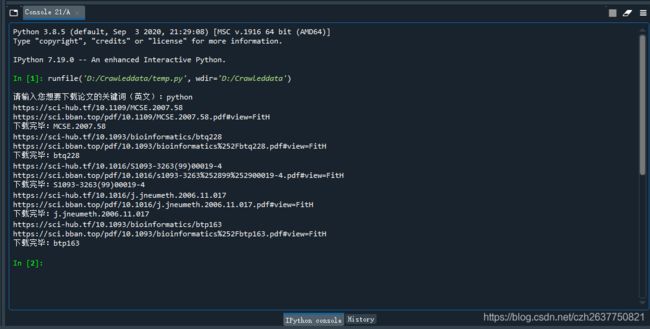
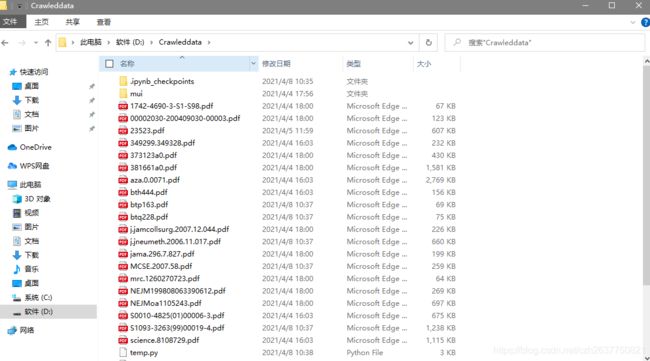
- Python实例之十大歌手评分
*濒危物种*
算法前端python
实例背景:十大歌手,为丰富校园文化生活,学校拟组织一场歌手大赛,从参赛选手中选拔出十名相对突出的学生,授予“校园十大歌手”称号。比赛之中设置有评委组,每名选手演唱完毕之后会由评委组的十名评委打分。为保证比赛公平公正、防止作弊和恶意打分,计算得分(即平均分)时会先去掉最高分和最低分要求实现:根据每位评委的输入分数,实现计算每位选手得分的功能。【重要步骤提示】定义列表放评委给分找出列表的最高分和最低分
- 如何用Python统计字符串(引用ASCII码)【两种方法】
*濒危物种*
python前端linux
要求实现:根据输入的字符串,统计其中大写字母、小写字母、数字、字符各有多少个【重要步骤提示】0-9的ASCII数字的ASCII码值取值范围为48-57;a-z小写英文字母的取值范围为97-122;A-Z大写英文字母的取值范围为65-90;Len()、append()方法的使用ord()函数获取字符对应的ASCII码值方法一#引到用户输入字符list1=list(input('请输入一行字符:'))
- Python机器学习元学习库higher
音程
机器学习人工智能python机器学习
higher是一个用于元学习(Meta-Learning)和高阶导数(Higher-ordergradients)的Python库,专为PyTorch设计。它扩展了PyTorch的自动微分机制,使得在训练过程中可以动态地计算参数的梯度更新,并把这些更新过程纳入到更高阶的梯度计算中。一、主要用途higher主要用于以下场景:元学习(Meta-Learning)比如MAML(Model-Agnosti
- Python Selenium 滚动到特定元素
Humbunklung
学海泛舟pythonselenium开发语言
文章目录PythonSelenium滚动到特定元素⚙️**1.使用`scrollIntoView()`方法(最推荐)**️**2.结合`ActionChains`移动鼠标(模拟用户行为)****3.使用坐标计算滚动(精确控制像素)**⚠️**4.处理复杂场景的进阶技巧****(1)元素在iframe中****(2)动态加载内容****(3)横向滚动****5.常见问题与解决方案****总结:根据场
- Python 常用正则表达式大全
朱公子的Note
python爬虫正则表达式
你是否在写Python爬虫时,总是卡在“正则提取”这一步?明明页面源码已经拿到,却怎么也匹配不到目标数据……不是提取失败,就是提取不全,搞得调试半天还抓不到核心字段?别急!今天我们就来一次**“正则一网打尽”**,专为爬虫而生的表达式宝典,让你写起爬虫来如虎添翼!在当下数据驱动时代,网络数据是企业的“金矿”,而Python爬虫则是挖掘这金矿的“利器”!从电商价格到社交媒体评论,爬虫技术让数据采集变
- 学校老师课堂点名管理系统带TkinterUI界面
深度学习乐园
oracle数据库
完整源码项目包获取→点击文章末尾名片!基于PythonTkinter的学生管理系统,有最基本的增删改查功能,还有随机点名、顺序点名功能##1、研究现状综述目前,在学生信息管理领域,各大高校面临的难题在于对学生信息管理的效率过低,传统的人工管理造成了资金和劳动力的浪费。因此,大部分学者研究的是针对高校的学生信息或成绩管理系统,而用python语言的也很少,其中大多用的是PyQt5模块。而且,针对低年
- 算法训练营|数组总结
慧泽huize
数据结构算法leetcodepythonc++
时间复杂度:算法执行语句的次数空间复杂度:算法在运行过程中临时占存储空间大小数组(C++):存放在连续内存空间的相同类型固定大小的数据的集合,不能删除,只能覆盖列表(Python):数据可以是不同类型,列表长度可变1.二分查找循环不变量原则,清楚区间定义时间复杂度:O(logn)空间复杂度:O(1)2.双指针法快指针找到新数组元素,慢指针指向新数组下标时间复杂度:O(n)空间复杂度:O(1)3.双
- python正则匹配11个数字_python正则表达式re.match()匹配多个字符方法的实现
小馬锅
python正则匹配11个数字
1.*表示匹配任意多个字符\d*表示匹配任意多个数字字符importretext="123h1elloworld"text1="123Helloworld456"text2="helloworld"res=re.match("\d*",text)res1=re.match("\d*",text1)res2=re.match("\d*",text2)print(res.group())print(r
- 基于MATLAB的资源优化与工期固定-资源均衡分析方法研究【附代码】
拉勾科研工作室
matlab开发语言
算法与建模领域的探索者|专注数据分析与智能模型设计✨擅长算法、建模、数据分析matlab、python、仿真✅具体问题可以私信或查看文章底部二维码✅感恩科研路上每一位志同道合的伙伴!(1)资源均衡优化相关理论与问题分类在现代工程项目中,资源的合理分配和使用是确保项目按时完成、成本可控的关键因素。资源均衡优化作为项目管理中的核心环节,旨在通过调整资源的使用方案,使资源消耗在整个工期内尽可能平稳,避免
- 医学图像增强的层级化模糊与虚拟仪器无参考质量评价研究【附代码】
拉勾科研工作室
计算机视觉图像处理人工智能
算法与建模领域的探索者|专注数据分析与智能模型设计✨擅长算法、建模、数据分析matlab、python、仿真✅具体问题可以私信或查看文章底部二维码✅感恩科研路上每一位志同道合的伙伴!(1)层级模糊隶属度的X光医学图像增强算法针对X光医学图像普遍存在的对比度差、细节模糊等问题,本算法提出了一种基于层级模糊隶属度的增强方法。该方法的核心思想在于利用拉普拉斯金字塔分解图像,并在多尺度下分层计算模糊隶属度
- 【半夜爬起来学python】零基础学习Pygame|第一期|知识点+小球反弹游戏案例
奈樱.
python(pygame)pygame学习游戏pip
一.安装PygamePygame是跨平台Python模块,很多编译器不会向用户提供该模块,需要我们自己安装。安装步骤:打开Pygame官网:www.pygame.org点击PYGAME2.6.0-25JUN,2024下载好之后,解压压缩包,安装路径最好放在c盘里Administrator文件里在菜单栏点击搜索,输入cmd,找到“命令提示符”输入命令pipinstallpygame运行的时候会发现命
- 【Python】Pygame从零开始学习
宅男很神经
python开发语言
模块一:Pygame入门与核心基础本模块将引导您完成Pygame的安装,并深入理解Pygame应用程序的基石——游戏循环、事件处理、Surface与Rect对象、显示控制以及颜色管理。第一章:Pygame概览与环境搭建1.1什么是Pygame?Pygame是一组专为编写视频游戏而设计的Python模块。它构建在优秀的SDL(SimpleDirectMediaLayer)库之上,允许您使用Pytho
- 【python】判断值是否为NaN
MoFe1
python开发语言
importmathdefis_nan(value):returnisinstance(value,float)andmath.isnan(value)#测试print(is_nan(float('nan')))#输出:Trueprint(is_nan(None))#输出:Falseprint(is_nan('abc'))#输出:False
- print(3 or 5)的结果是什么?为什么?
Lauren_Lu
python
print(3or5)的结果是:3原因:在Python中,or是一个逻辑运算符,但当它作用于非布尔类型(比如整数)时,它的行为是:返回第一个为真的值;如果第一个值为假,则返回第二个值。具体分析:3是一个非零整数,在布尔上下文中被视为True所以3or5就是:如果3是True,就返回3;否则返回5由于3是True,所以返回的是3。类似例子:print(0or5)#输出5,因为0被视为Falsepri
- 深度学习实战:基于嵌入模型的AI应用开发
AIGC应用创新大全
AI人工智能与大数据应用开发MCP&Agent云算力网络人工智能深度学习ai
深度学习实战:基于嵌入模型的AI应用开发关键词:嵌入模型(EmbeddingModel)、深度学习、向量空间、语义表示、AI应用开发、相似性搜索、迁移学习摘要:本文将带你从0到1掌握基于嵌入模型的AI应用开发全流程。我们会用“翻译机”“数字身份证”等生活比喻拆解嵌入模型的核心原理,结合Python代码实战(BERT/CLIP模型)演示如何将文本、图像转化为可计算的语义向量,并通过“智能客服问答”“
- [python系列] 创建虚拟环境 venv
en-route
pythonvirtualenv
虚拟环境定义Python中的虚拟环境是一个隔离的运行环境,旨在为每个Python项目提供独立的执行空间,支持在不同的项目中分别管理依赖关系,而不会影响到其他项目或系统的原始Python安装。可以将虚拟环境视为每个Python项目的“独立容器”,每个容器具备以下特点:拥有独立的Python解释器拥有各自独立的包管理和安装的软件包与其他虚拟环境相互隔离允许同一包存在不同版本使用虚拟环境的重要性体现在以
- Python代理池的构建与应用:实现高效爬虫与防封禁策略
程序员威哥
python爬虫开发语言
在进行大规模网络数据抓取时,IP封禁是最常见的反爬虫手段之一。为了应对这一挑战,代理池成为了一个重要工具。通过构建代理池,爬虫程序可以随机切换代理IP,避免同一IP被频繁访问而导致封禁,确保数据抓取任务的稳定性和持续性。本文将详细介绍如何使用Python构建一个高效的代理池,并结合实际应用场景,讲解如何使用代理池提升爬虫的抓取能力和防封禁策略。一、代理池的工作原理代理池的基本工作原理是,爬虫请求时
- Python爬虫实战:用Tushare和Baostock爬取股票历史数据及K线图与技术指标计算
在金融数据分析和量化交易中,股票历史数据的获取是进行技术分析、回测和策略研究的第一步。传统上,投资者需要依赖付费数据服务,然而如今,借助Python强大的爬虫工具和开源数据接口,我们能够轻松地爬取免费的历史股票数据,并结合K线图与技术指标来进行深入分析。Tushare和Baostock是两个非常流行的开源金融数据接口。Tushare提供了丰富的国内外金融数据,特别是A股市场的历史数据和实时数据,而
- Python_计算两个省市之间的直线距离_2506
夏天里的肥宅水
PYTHONpythonspring开发语言
更新代码上一版链接importpandasaspdimporttimeimportpickleimportosimportsysfromgeopy.geocodersimportNominatimfromgeopy.distanceimportgeodesicfromtqdmimporttqdm#ConfigurationINPUT_FILE=r"距离.xlsx"#输入文件路径OUTPUT_FIL
- python中的*args 和 **kwargs
Hi_kenyon
pythonpython
简单来说,它们允许一个函数接收不定数量的参数。这在我们预先不知道会传递多少个参数给函数时非常有用。*args(任意数量的位置参数)*args用于在一个函数中接收任意数量的位置参数(positionalarguments)。当你在函数定义中使用*args时,Python会将所有传入的多余的位置参数收集到一个元组(tuple)中。这个名字args只是一个约定俗成的惯例(arguments的缩写),你也
- 用 Python 开发文字冒险游戏:从零开始的教程
晓天天天向上
pythonmicrosoft开发语言
文字冒险游戏(Text-basedAdventureGame)是一种经典的游戏类型,玩家通过输入文字指令与游戏世界互动。这种游戏不依赖复杂的图形界面,非常适合初学者学习编程逻辑和用户交互。在本篇博客中,我们将用Python开发一个简单的文字冒险游戏,体验游戏开发的乐趣。1.游戏设计思路游戏背景玩家醒来发现自己身处一个神秘的地下城,需要探索房间、收集物品、战胜敌人并找到出口。核心机制房间导航:玩家可
- 从零开始理解零样本学习:AI人工智能必学技术
AI天才研究院
AgenticAI实战AI人工智能与大数据AI大模型企业级应用开发实战ai
从零开始理解零样本学习:AI人工智能必学技术关键词:零样本学习、人工智能、机器学习、知识迁移、语义嵌入摘要:本文旨在全面深入地介绍零样本学习这一在人工智能领域具有重要意义的技术。首先阐述零样本学习的背景和基本概念,通过详细的解释和直观的示意图让读者建立起对零样本学习的初步认识。接着深入剖析其核心算法原理,结合Python代码进行详细说明,同时引入相关数学模型和公式并举例阐释。通过项目实战部分,带领
- Python训练营打卡——DAY16(2025.5.5)
cosine2025
Python训练营打卡python开发语言机器学习
目录一、NumPy数组基础笔记1.理解数组的维度(Dimensions)2.NumPy数组与深度学习Tensor的关系3.一维数组(1DArray)4.二维数组(2DArray)5.数组的创建5.1数组的简单创建5.2数组的随机化创建5.3数组的遍历5.4数组的运算6.数组的索引6.1一维数组索引6.2二维数组索引6.3三维数组索引二、SHAP值的深入理解三、总结1.NumPy数组基础总结2.SH
- Python的一点基础教程------文件读写
卡提西亚
python开发语言
最近在看大佬写的Python教程自学,但是感觉有点头痛,因为大佬讲了一些底层的结构和原理,但是又没那么详细,然后作为一个初学者自学的情况下,看的很费劲.看完就有感而发,想写一篇更基础的教程,教会大家怎么去用它,尽量少的去讲原理.但是当然,你也需要有一定的编程语言基础,了解基本的语法和函数等功能.正所谓师傅领进门,修行在个人,有时候我们学了一个东西,如果觉得很有趣,自然就会去了解关于它的更多信息,但
- 1.2 Python 的特点与优势
Utopia Reverie
pythonpython开发语言
1.语法简洁易读Python以简洁的语法著称,代码可读性强,减少了不必要的符号和冗余代码。例如,使用缩进来表示代码块,而非传统的大括号。这使得代码更易于理解和维护,尤其适合初学者。示例:python运行【#计算斐波那契数列的前10项n=10a,b=0,1for_inrange(n);print(a,end='')a,b=b,a+b#输出:0112358132134】2.开源与社区支持Python是
- 动手学Python:从零开始构建一个“文字冒险游戏”
network爬虫
pythonpython开发语言
动手学Python:从零开始构建一个“文字冒险游戏”大家好,我是你的技术向导。今天,我们不聊高深的框架,也不谈复杂的算法,我们来做一点“复古”又极具趣味性的事情——用Python亲手打造一个属于自己的文字冒险游戏(TextAdventureGame)。你是否还记得那些在早期计算机上,通过一行行文字描述和简单指令来探索未知世界的日子?这种游戏的魅力在于它能激发我们最原始的想象力。而对于我们程序员来说
- python 脚本 遍历目录,并把目录下的非utf-8文件改成utf8
还债大湿兄
python开发语言数据库
从网上下载的qt项目我本地编译里面经常包含中文,提示编译不过,实际上以前经常手动转,发觉还是用脚本不,毕竟这次下的有点大,我只改.h.cpp#pythonD:\python\filetoUtf.pyE:\EasyCanvas-master\EasyCanvas-masterimportosimportcodecsimportargparseimportsysdefconvert_to_utf8_b
- 树莓派中 Python+opencv打开摄像头
68lizi
光电设计python
树莓派中Python+opencv打开摄像头注意不要使用cap=cv2.VideoCapture(0,cv2.CAP_DSHOW),我在树莓派使用这个的时候会报错,在windows不会报错,具体原因不清楚cap=cv2.VideoCapture(0)#使用cap=cv2.VideoCapture(0,cv2.CAP_DSHOW)会报错whileTrue:status,img=cap.read()i
- python实现读取文件的指定某行内容
Fitz1318
Python3学习python
python实现读取文件的指定某行内容最近有一个需求就是读取一个文件中的指定某行的内容,现将方法记录如下importlinecache#这里填写你自己的文件位置和行号text=linecache.getline("../TestFile/test_C1.json",2)print(text)
- [Python] 使用 dataclass 简化数据结构:定义、功能与实战
踏雪无痕老爷子
Pythonpython开发语言
在经典面向对象编程中,为了保存和操作数据往往需要定义多个类,手写__init__()、__repr__()、__eq__()等方法。Python3.7引入了@dataclass装饰器,它能自动生成这些常见方法,大幅减少样板代码。本文将介绍dataclass的定义与参数、比较与普通类的差别、实战示例,以及常见注意事项。一、什么是dataclass@dataclass是一种类装饰器,它通过类成员的类型
- 数据采集高并发的架构应用
3golden
.net
问题的出发点:
最近公司为了发展需要,要扩大对用户的信息采集,每个用户的采集量估计约2W。如果用户量增加的话,将会大量照成采集量成3W倍的增长,但是又要满足日常业务需要,特别是指令要及时得到响应的频率次数远大于预期。
&n
- 不停止 MySQL 服务增加从库的两种方式
brotherlamp
linuxlinux视频linux资料linux教程linux自学
现在生产环境MySQL数据库是一主一从,由于业务量访问不断增大,故再增加一台从库。前提是不能影响线上业务使用,也就是说不能重启MySQL服务,为了避免出现其他情况,选择在网站访问量低峰期时间段操作。
一般在线增加从库有两种方式,一种是通过mysqldump备份主库,恢复到从库,mysqldump是逻辑备份,数据量大时,备份速度会很慢,锁表的时间也会很长。另一种是通过xtrabacku
- Quartz——SimpleTrigger触发器
eksliang
SimpleTriggerTriggerUtilsquartz
转载请出自出处:http://eksliang.iteye.com/blog/2208166 一.概述
SimpleTrigger触发器,当且仅需触发一次或者以固定时间间隔周期触发执行;
二.SimpleTrigger的构造函数
SimpleTrigger(String name, String group):通过该构造函数指定Trigger所属组和名称;
Simpl
- Informatica应用(1)
18289753290
sqlworkflowlookup组件Informatica
1.如果要在workflow中调用shell脚本有一个command组件,在里面设置shell的路径;调度wf可以右键出现schedule,现在用的是HP的tidal调度wf的执行。
2.designer里面的router类似于SSIS中的broadcast(多播组件);Reset_Workflow_Var:参数重置 (比如说我这个参数初始是1在workflow跑得过程中变成了3我要在结束时还要
- python 获取图片验证码中文字
酷的飞上天空
python
根据现成的开源项目 http://code.google.com/p/pytesser/改写
在window上用easy_install安装不上 看了下源码发现代码很少 于是就想自己改写一下
添加支持网络图片的直接解析
#coding:utf-8
#import sys
#reload(sys)
#sys.s
- AJAX
永夜-极光
Ajax
1.AJAX功能:动态更新页面,减少流量消耗,减轻服务器负担
2.代码结构:
<html>
<head>
<script type="text/javascript">
function loadXMLDoc()
{
.... AJAX script goes here ...
- 创业OR读研
随便小屋
创业
现在研一,有种想创业的想法,不知道该不该去实施。因为对于的我情况这两者是矛盾的,可能就是鱼与熊掌不能兼得。
研一的生活刚刚过去两个月,我们学校主要的是
- 需求做得好与坏直接关系着程序员生活质量
aijuans
IT 生活
这个故事还得从去年换工作的事情说起,由于自己不太喜欢第一家公司的环境我选择了换一份工作。去年九月份我入职现在的这家公司,专门从事金融业内软件的开发。十一月份我们整个项目组前往北京做现场开发,从此苦逼的日子开始了。
系统背景:五月份就有同事前往甲方了解需求一直到6月份,后续几个月也完
- 如何定义和区分高级软件开发工程师
aoyouzi
在软件开发领域,高级开发工程师通常是指那些编写代码超过 3 年的人。这些人可能会被放到领导的位置,但经常会产生非常糟糕的结果。Matt Briggs 是一名高级开发工程师兼 Scrum 管理员。他认为,单纯使用年限来划分开发人员存在问题,两个同样具有 10 年开发经验的开发人员可能大不相同。近日,他发表了一篇博文,根据开发者所能发挥的作用划分软件开发工程师的成长阶段。
初
- Servlet的请求与响应
百合不是茶
servletget提交java处理post提交
Servlet是tomcat中的一个重要组成,也是负责客户端和服务端的中介
1,Http的请求方式(get ,post);
客户端的请求一般都会都是Servlet来接受的,在接收之前怎么来确定是那种方式提交的,以及如何反馈,Servlet中有相应的方法, http的get方式 servlet就是都doGet(
- web.xml配置详解之listener
bijian1013
javaweb.xmllistener
一.定义
<listener>
<listen-class>com.myapp.MyListener</listen-class>
</listener>
二.作用 该元素用来注册一个监听器类。可以收到事件什么时候发生以及用什么作为响
- Web页面性能优化(yahoo技术)
Bill_chen
JavaScriptAjaxWebcssYahoo
1.尽可能的减少HTTP请求数 content
2.使用CDN server
3.添加Expires头(或者 Cache-control) server
4.Gzip 组件 server
5.把CSS样式放在页面的上方。 css
6.将脚本放在底部(包括内联的) javascript
7.避免在CSS中使用Expressions css
8.将javascript和css独立成外部文
- 【MongoDB学习笔记八】MongoDB游标、分页查询、查询结果排序
bit1129
mongodb
游标
游标,简单的说就是一个查询结果的指针。游标作为数据库的一个对象,使用它是包括
声明
打开
循环抓去一定数目的文档直到结果集中的所有文档已经抓取完
关闭游标
游标的基本用法,类似于JDBC的ResultSet(hasNext判断是否抓去完,next移动游标到下一条文档),在获取一个文档集时,可以提供一个类似JDBC的FetchSize
- ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务 的解决方法
白糖_
ORA-12514
今天通过Oracle SQL*Plus连接远端服务器的时候提示“监听程序当前无法识别连接描述符中请求服务”,遂在网上找到了解决方案:
①打开Oracle服务器安装目录\NETWORK\ADMIN\listener.ora文件,你会看到如下信息:
# listener.ora Network Configuration File: D:\database\Oracle\net
- Eclipse 问题 A resource exists with a different case
bozch
eclipse
在使用Eclipse进行开发的时候,出现了如下的问题:
Description Resource Path Location TypeThe project was not built due to "A resource exists with a different case: '/SeenTaoImp_zhV2/bin/seentao'.&
- 编程之美-小飞的电梯调度算法
bylijinnan
编程之美
public class AptElevator {
/**
* 编程之美 小飞 电梯调度算法
* 在繁忙的时间,每次电梯从一层往上走时,我们只允许电梯停在其中的某一层。
* 所有乘客都从一楼上电梯,到达某层楼后,电梯听下来,所有乘客再从这里爬楼梯到自己的目的层。
* 在一楼时,每个乘客选择自己的目的层,电梯则自动计算出应停的楼层。
* 问:电梯停在哪
- SQL注入相关概念
chenbowen00
sqlWeb安全
SQL Injection:就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
具体来说,它是利用现有应用程序,将(恶意)的SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
首先让我们了解什么时候可能发生SQ
- [光与电]光子信号战防御原理
comsci
原理
无论是在战场上,还是在后方,敌人都有可能用光子信号对人体进行控制和攻击,那么采取什么样的防御方法,最简单,最有效呢?
我们这里有几个山寨的办法,可能有些作用,大家如果有兴趣可以去实验一下
根据光
- oracle 11g新特性:Pending Statistics
daizj
oracledbms_stats
oracle 11g新特性:Pending Statistics 转
从11g开始,表与索引的统计信息收集完毕后,可以选择收集的统信息立即发布,也可以选择使新收集的统计信息处于pending状态,待确定处于pending状态的统计信息是安全的,再使处于pending状态的统计信息发布,这样就会避免一些因为收集统计信息立即发布而导致SQL执行计划走错的灾难。
在 11g 之前的版本中,D
- 快速理解RequireJs
dengkane
jqueryrequirejs
RequireJs已经流行很久了,我们在项目中也打算使用它。它提供了以下功能:
声明不同js文件之间的依赖
可以按需、并行、延时载入js库
可以让我们的代码以模块化的方式组织
初看起来并不复杂。 在html中引入requirejs
在HTML中,添加这样的 <script> 标签:
<script src="/path/to
- C语言学习四流程控制if条件选择、for循环和强制类型转换
dcj3sjt126com
c
# include <stdio.h>
int main(void)
{
int i, j;
scanf("%d %d", &i, &j);
if (i > j)
printf("i大于j\n");
else
printf("i小于j\n");
retu
- dictionary的使用要注意
dcj3sjt126com
IO
NSDictionary *dict = [NSDictionary dictionaryWithObjectsAndKeys:
user.user_id , @"id",
user.username , @"username",
- Android 中的资源访问(Resource)
finally_m
xmlandroidStringdrawablecolor
简单的说,Android中的资源是指非代码部分。例如,在我们的Android程序中要使用一些图片来设置界面,要使用一些音频文件来设置铃声,要使用一些动画来显示特效,要使用一些字符串来显示提示信息。那么,这些图片、音频、动画和字符串等叫做Android中的资源文件。
在Eclipse创建的工程中,我们可以看到res和assets两个文件夹,是用来保存资源文件的,在assets中保存的一般是原生
- Spring使用Cache、整合Ehcache
234390216
springcacheehcache@Cacheable
Spring使用Cache
从3.1开始,Spring引入了对Cache的支持。其使用方法和原理都类似于Spring对事务管理的支持。Spring Cache是作用在方法上的,其核心思想是这样的:当我们在调用一个缓存方法时会把该方法参数和返回结果作为一个键值对存放在缓存中,等到下次利用同样的
- 当druid遇上oracle blob(clob)
jackyrong
oracle
http://blog.csdn.net/renfufei/article/details/44887371
众所周知,Oracle有很多坑, 所以才有了去IOE。
在使用Druid做数据库连接池后,其实偶尔也会碰到小坑,这就是使用开源项目所必须去填平的。【如果使用不开源的产品,那就不是坑,而是陷阱了,你都不知道怎么去填坑】
用Druid连接池,通过JDBC往Oracle数据库的
- easyui datagrid pagination获得分页页码、总页数等信息
ldzyz007
var grid = $('#datagrid');
var options = grid.datagrid('getPager').data("pagination").options;
var curr = options.pageNumber;
var total = options.total;
var max =
- 浅析awk里的数组
nigelzeng
二维数组array数组awk
awk绝对是文本处理中的神器,它本身也是一门编程语言,还有许多功能本人没有使用到。这篇文章就单单针对awk里的数组来进行讨论,如何利用数组来帮助完成文本分析。
有这么一组数据:
abcd,91#31#2012-12-31 11:24:00
case_a,136#19#2012-12-31 11:24:00
case_a,136#23#2012-12-31 1
- 搭建 CentOS 6 服务器(6) - TigerVNC
rensanning
centos
安装GNOME桌面环境
# yum groupinstall "X Window System" "Desktop"
安装TigerVNC
# yum -y install tigervnc-server tigervnc
启动VNC服务
# /etc/init.d/vncserver restart
# vncser
- Spring 数据库连接整理
tomcat_oracle
springbeanjdbc
1、数据库连接jdbc.properties配置详解 jdbc.url=jdbc:hsqldb:hsql://localhost/xdb jdbc.username=sa jdbc.password= jdbc.driver=不同的数据库厂商驱动,此处不一一列举 接下来,详细配置代码如下:
Spring连接池
- Dom4J解析使用xpath java.lang.NoClassDefFoundError: org/jaxen/JaxenException异常
xp9802
用Dom4J解析xml,以前没注意,今天使用dom4j包解析xml时在xpath使用处报错
异常栈:java.lang.NoClassDefFoundError: org/jaxen/JaxenException异常
导入包 jaxen-1.1-beta-6.jar 解决;
&nb