Scikit-learn中的机器学习算法
以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
————————————————
版权声明:本文为CSDN博主「林学森」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuesen_lin/
1.1 Scikit-learn中的机器学习算法
总的来说,Scikit-learn支持六大类别的机器学习任务,即Classification、Regression、Clustering、Dimensionality reduction、Model selection和Preprocessing。
1.1.1 Classification
分类任务就是识别出object所属的类别的过程。
表格 ‑ Scikit-learn支持的Classification算法
| Task |
Algorithms |
Modules |
Application |
| Classification |
SVM |
sklearn.svm |
Spam detection Image recognition |
| Nearest neighbors |
sklearn.neighbors |
||
| random forest |
sklearn.ensemble |
||
| Naïve Bayes |
sklearn.naive_bayes |
||
| Decision Trees |
sklearn.tree |
||
| Neural Network |
sklearn.neural_network |
可见主流的分类算法都在scikit-learn的支持范围。不过相对于tensorflow和caffe这种专注于深度学习的平台,scikit-learn的Neural Network通常只用于做一些规模较小的网络模型的训练和测试(毕竟“术业有专攻”)。
1.1.2 Regression
回归任务主要用于预测一个物体的连续值属性,无论在学术界还是工业界都有非常广泛的应用——比如预测股票价格或者药物反应。Scikit-learn同样提供了较为丰富的回归算法模型来满足开发者的需求,而且针对每种算法还附带了从原理到使用范例、scikit-learn api释义等一系列信息。
主要算法及相关信息描述如下表所示:
表格 ‑ Scikit-learn 支持的Regression算法
| Task |
Algorithms |
Modules |
Application |
| Regression |
LinearRegression |
sklearn.linear_model.LinearRegression |
Drug response, Stock prices |
| SVR |
sklearn.svm.SVR |
||
| Ridge Regression |
sklearn.linear_model.Ridge |
||
| Lasso |
sklearn.linear_model.Lasso |
||
| Multi-task Lasso |
sklearn.linear_model.MultiTaskLasso |
||
| Elastic Net |
sklearn.linear_model.ElasticNet |
||
| Multi-task Elastic Net |
sklearn.linear_model.MultiTaskElasticNet |
||
| Least Angle Regression |
sklearn.linear_model.Lars |
||
| LARS Lasso |
sklearn.linear_model.LassoLars |
||
| Orthogonal Matching Pursuit |
sklearn.linear_model.OrthogonalMatchingPursuit |
||
| Bayesian Ridge Regression |
sklearn.linear_model.BayesianRidge |
||
| Logistic regression |
sklearn.linear_model.LogisticRegression |
||
| Passive Aggressive Regressor |
sklearn.linear_model.PassiveAggressiveRegressor |
||
| Huber Regressor |
sklearn.linear_model.HuberRegressor |
1.1.3 Clustering
聚类属于无监督学习,用于自动化地将具有相似属性的对象进行归类。下表所示是Scikit-learn目前已经支持的一些clustering算法以及它们之间的区别比较:
表格 ‑ Scikit-learn支持的clustering算法比较

另外,scikit-learn还提供了上述这些clustering算法的可视化的对比结果,供开发人员比较选择。
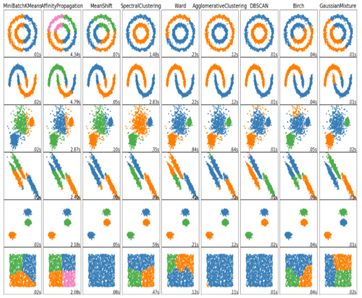
图 ‑ 各种clustering算法可视化比较
1.1.4 Dimensionality reduction
Dimensionality reduction,即降维指的是将高维空间的数据映射到低维度空间中的处理过程。比如下图所示是将4维的IRIS数据集降维到2维空间的结果:

图 ‑ 降维示例
Scikit-learn主要支持如下几种类型的降维手段 (每种类型可能还包含多个子类型):
l Principal component analysis (PCA)
n Incremental PCA
n PCA using randomized SVD
n Kernel PCA
n Sparse principal components analysis (SparsePCA and MiniBatchSparsePCA)
l Truncated singular value decomposition and latent semantic analysis
l Dictionary Learning
n Sparse coding with a precomputed dictionary
n Generic dictionary learning
n Mini-batch dictionary learning
l Factor Analysis
l Independent component analysis (ICA)
l Non-negative matrix factorization (NMF or NNMF)
n NMF with the Frobenius norm
n NMF with a beta-divergence
l Latent Dirichlet Allocation (LDA)
其中PCA可以说是应用最广泛的降维方法之一,我们在其它章节有详细讲解,请大家结合起来阅读。