原创作品,转载请注明出处。
关注公众号「热薯条」获取更多精彩文章。

前言
上一期我们介绍了如何使用数据库中的原始数据,经过数据处理、特征工程后得到有用的特征,并且如何施加对业务上的理解和公式到特征中,得到最终总权重来为图计算做准备的。
本期我们将重点介绍如何进行绘图,从连通图中进行社区发现 (community detection),社区发现不同算法的介绍,以及是如何运用到我们的模型上找出嫌疑猫币黑市社区的。
绘图
绘图主要有两种方法:
- Gephi
- R 中的 igraph 包,Python 中的 networkx 包等
使用 Gephi 画连通图
下载最新版 Gephi (我使用的是 Gephi 0.92)
我们将之前得到的数据保存为 csv 格式,将列名分别改为 source, target, weight (这样 Gephi 就能够自动识别起始点,结束点和权重了)
将 csv 格式的数据导入到 Gephi 中:


这样导入后,就能得到类似下图的连通图了:

使用 R 画连通图
我们用 R 中的 igraph 包进行举例:
library(igraph)
g <- graph_from_data_frame(gdata, directed = FALSE)
plot(g)
这边 gdata 的格式和之前是一样的,同样也是 source, target, weight 的格式。
这样就可以得到连通图了,如果想要看到方向的话,就将 directed 选为 TRUE,但是由于后续有些社区发现的算法只支持无向的连通图,所以我们这边先暂时选为 FALSE
社区发现 (community detection)
首先,什么是社区?
(Newman and Gievan 2004)
A community is a subgraph containing nodes which are more densely linked to each other than to the rest of the graph or equivalently, a graph has a community structure if the number of links into any subgraph is higher than the number of links between those subgraphs.
Newman 和 Gievan 在2004年提出, 同一社区内的节点与节点之间的连接很紧密,而社区与社区之间的连接比较稀疏,如下图:

阴影部分的点各为一个社区
模块度 (Modularity)
一个给定的连通图,可以有很多种划分方法,所以在介绍算法前,我们要先有个定义去确认什么样的社区划分是最优的,这个定义就是模块度 (Modularity)
我们先定义:

并且:

定义模块度:
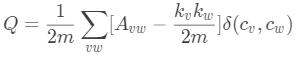
社区发现算法介绍
接下来我们将介绍一些算法,了解算法是具体如何确定出这种划分的
Girvan-Newman Algorithm

Girvan-Newman 算法步骤:
- 计算所有边的边中心度
- 将边中心度最高的边去掉
- 重新计算被去掉的边影响的边的边中心度
- 重复第二、三步直至去掉所有的边



社区发现算法实现
通过 Gephi 实现
在将数据导入到 Gephi 后,我们可以选择 Layout 为 Yifan Hu,Run Modularity,将 Modularity 运用到 Nodes Partition中:
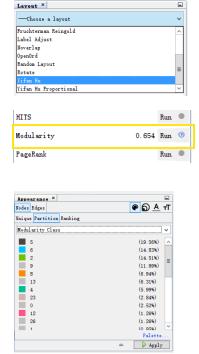
Gephi 选择步骤
选择完毕后即可得到:

Gephi 最终图, 图中同一个颜色的节点代表同一个社区
具体可参考 Gephi 官网:https://gephi.org/
通过 R 实现
我们使用 Fast Greedy 这个算法进行举例
fg <- cluster_fast_greedy(g)
这短短一行就可让R进行算法计算
在计算好之后可用以下函数来查看社区
groups(fg) #查看每个社区的节点
length(fg) #查看总社区数
sizes(fg) #查看个社区的大小
modularity(fg) #查看模块值
接下来我们需要将每个社区的节点导出来,再放到行为数据中进行下一步分析:
oldrid = data.table(rid = c(0), community = c(0))
for (i in 1:length(fg)){
object = fg[i][[1]]
newrid = data.table(rid = object, community = c(rep(i,length(object))))
newrid = rbind(newrid,oldrid)
oldrid = newrid
}
或提取出指定社区的节点,社区内的边,再画该社区的图
remove <- V(g)$name[! V(g)$name %in% groups(cl)$`15`]
g_com <- delete.vertices(g, remove)
plot(g_com)
g_15 <- as_data_frame(g_com)
write.table(V(g1)$name, "g_15")
具体可参考 igraph 文档 : http://igraph.org/r/
实际运用
将以上方法运用到用户数据中,即可得到许多个不同的社区,我们将对各个社区再进行分析,提取出一些可疑的社区,针对其他维度的行为进行分析
下期前瞻
下一期我们将重点介绍箱形图,以及如何使用箱形图对单个维度的数据提取异常值,从而得到猫币黑市中角色量化定义。
参考文献
[1] M. Girvan and M. E. J. Newman. (2002) Community structure in social and biological networks . Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC122977/
[2] Michael Bommarito. (2017) Summary of community detection algorithms in igraph 0.6. Retrieved from https://bommaritollc.com/2012/06/17/summary-community-detection-algorithms-igraph-0-6/?utm_source=rss&utm_medium=rss&utm_campaign=summary-community-detection-algorithms-igraph-0-6
更多精彩推荐:
猫币黑市第一期——通过大数据,机器学习揭露互联网直播行业黑产
猫币黑市第二期——技术流程、特征工程
猫币黑市第四期——使用箱形图判断异常值
猫币黑市第五期——猫币黑市规模、甄别手段评估
原创作品,转载请注明出处。
关注公众号「热薯条」获取更多精彩文章。