为什么80%的码农都做不了架构师?>>> 

上一节介绍了一下自然语言处理里面最基本的单边和双边的 ngram 模型,用 word embedding和ngram 模型对一句话中的某个词做预测,今天我们将使用LSTM来做判别每个词的词性,因为同一个单词有着不同的词性,比如book可以表示名词,也可以表示动词,所以我们需要训练一下网络来得到词性的判断。
LSTM 词性判断
LSTM的网络结构在之前已经介绍过了.首先,我们定义好一个LSTM网络,然后给出一个句子,每个句子都有很多个词构成,每个词可以用一个词向量表示,这样一句话就可以形成一个序列,我们将这个序列依次传入LSTM,然后就可以得到与序列等长的输出,每个输出都表示的是一种词性,比如名词,动词之类的,还是一种分类问题,每个单词都属于几种词性中的一种。
我们可以思考一下为什么LSTM在这个问题里面起着重要的作用。如果我们完全孤立的对一个词做词性的判断这样我们需要特别高维的词向量,但是对于LSTM,它有着一个记忆的特性,这样我们就能够通过这个单词前面记忆的一些词语来对其做一个判断,比如前面如果是my,那么他紧跟的词有很大可能就是一个名词,这样就能够充分的利用上文来做这个问题。
同时我们还可以通过引入字符来增强表达,什么意思呢?也就是说一个单词有一些前缀和后缀,比如-ly这种后缀很大可能是一个副词,这样我们就能够在字符水平得到一个词性判断的更好结果。
具体怎么做呢?还是用LSTM。每个单词有不同的字母组成,比如 apple 由a p p l e构成,我们同样给这些字符词向量,这样形成了一个长度为5的序列,然后传入另外一个LSTM网络,只取最后输出的状态层作为它的一种字符表达,我们并不需要关心到底提取出来的字符表达是什么样的,在learning的过程中这些都是会被更新的参数,使得最终我们能够正确预测。接下来我们开始上代码。
准备数据
training_data = [
("The dog ate the apple".split(), ["DET", "NN", "V", "DET", "NN"]),
("Everybody read that book".split(), ["NN", "V", "DET", "NN"])
]这是一个简单的训练数据,两句话,每句话的每个单词的词性由后面给出。
接着我们需要给这些单词和词性一个编码
word_to_idx = {}
tag_to_idx = {}
for context, tag in training_data:
for word in context:
if word not in word_to_idx:
word_to_idx[word] = len(word_to_idx)
for label in tag:
if label not in tag_to_idx:
tag_to_idx[label] = len(tag_to_idx)
这样每个单词就用一个数字表示,每种词性也用一个数字表示,这些之前都接触过。
alphabet = 'abcdefghijklmnopqrstuvwxyz'
character_to_idx = {}
for i in range(len(alphabet)):
character_to_idx[alphabet[i]] = i同时我们需要将从a到z的字符也编码。
字符LSTM
接着我们定义字符水平的LSTM
class CharLSTM(nn.Module):
def __init__(self, n_char, char_dim, char_hidden):
super(CharLSTM, self).__init__()
self.char_embedding = nn.Embedding(n_char, char_dim)
self.char_lstm = nn.LSTM(char_dim, char_hidden, batch_first=True)
def forward(self, x):
x = self.char_embedding(x)
_, h = self.char_lstm(x)
return h[1]看看上面的代码,首先定义好embedding和lstm,接着传入n个字符,然后通过nn.Embedding得到词向量,接着传入LSTM网络,得到状态输出h,然后通过h得到我们想要的hidden state。
这样我们对于每个单词,通过CharLSTM就能够得到相应的字符表示。
词性LSTM
接着我们来完成我们的目标,分析每个单词的词性,首先定义好LSTM网络
class LSTMTagger(nn.Module):
def __init__(self, n_word, n_char, char_dim, n_dim, char_hidden,
n_hidden, n_tag):
super(LSTMTagger, self).__init__()
self.word_embedding = nn.Embedding(n_word, n_dim)
self.char_lstm = CharLSTM(n_char, char_dim, char_hidden)
self.lstm = nn.LSTM(n_dim+char_hidden, n_hidden, batch_first=True)
self.linear1 = nn.Linear(n_hidden, n_tag)
def forward(self, x, word_data):
word = [i for i in word_data]
char = torch.FloatTensor()
for each in word:
word_list = []
for letter in each:
word_list.append(character_to_idx[letter.lower()])
word_list = torch.LongTensor(word_list)
word_list = word_list.unsqueeze(0)
tempchar = self.char_lstm(Variable(word_list).cuda())
tempchar = tempchar.squeeze(0)
char = torch.cat((char, tempchar.cpu().data), 0)
char = char.squeeze(1)
char = Variable(char).cuda()
x = self.word_embedding(x)
x = torch.cat((x, char), 1)
x = x.unsqueeze(0)
x, _ = self.lstm(x)
x = x.squeeze(0)
x = self.linear1(x)
y = F.log_softmax(x)
return y
看着有点复杂,我们慢慢来解释。首先n_word 和 n_dim来定义单词的词向量维度,n_char和char_dim来定义字符的词向量维度,char_hidden表示CharLSTM输出的维度,n_hidden表示每个单词作为序列输入的LSTM输出维度,最后n_tag表示输出的词性的种类。
接着开始前向传播,不仅要传入一个编码之后的句子,同时还需要传入原本的单词,因为需要对字符做一个LSTM,所以传入的参数多了一个word_data表示一个句子的所有单词。
然后就是将每个单词传入CharLSTM,得到的结果和单词的词向量拼在一起形成一个新的输入,将输入传入LSTM里面,得到输出,最后接一个全连接层,将输出维数定义为label的数目。
这就是基本的思路,我就不具体解释每句话的含义了,留给大家自己看看,特别要注意里面有一些unsqueeze和squeeze是因为LSTM的输入要求要带上batch_size,torch.cat里面0和1分别表示沿着行和列来拼接。
运行结果
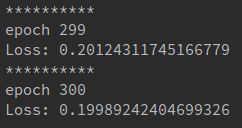
经过300个epoch,loss降到了0.2左右
最后我们来预测一下 Everybody ate the apple 这句话每个词的词性,一共有3种词性,DET,NN,V。最后得到的结果为

一共有4行,每行里面取最大的,那么第一个词的词性就是NN,第二个词是V,第三个词是DET,第四个词是NN。这个是相符的。
以上我们介绍了RNN在图像处理以及自然语言处理上的应用,RNN还有更多的应用,比如做image captioning,机器翻译等等,感兴趣的同学可以自己在github上找一找。
在这里,我整理发布了Pytorch中文文档,方便大家查询使用,同时也准备了中文论坛,欢迎大家学习交流!
Pytorch中文文档
Pytorch中文论坛
Pytorch中文文档已经发布,完美翻译,更加方便大家浏览:
Pytorch中文网:https://ptorch.com/
Pytorch中文文档:https://ptorch.com/docs/1/