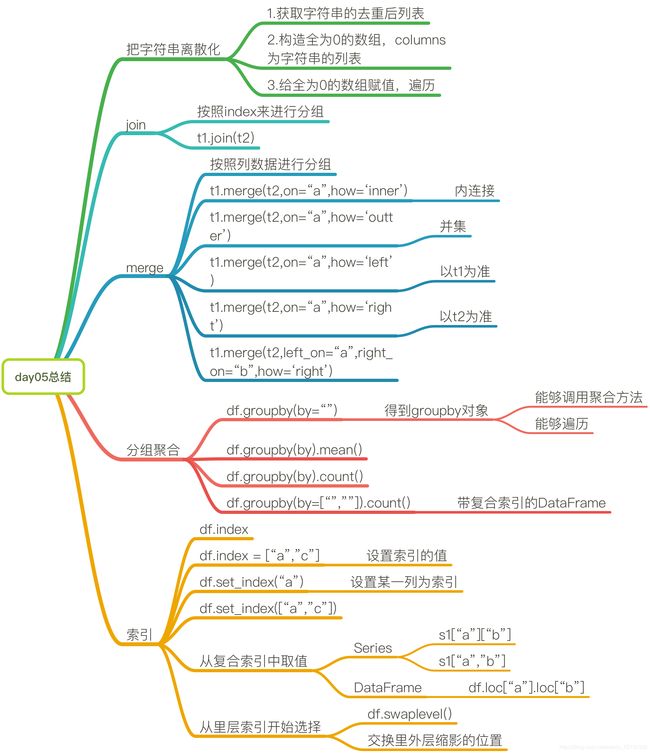
机器学习-数据科学库(HM)_第5节_数据的合并和分组
机器学习-数据科学库(HM)_第5节_数据的合并和分组
- pandas
-
- 数据分类
- 数据合并之join(行合并)
- 数据合并之merge(列合并)
- `df切片和索引,Series vs. df`
- pandas的分组和聚合
- 索引和复合索引
-
- Series复合索引
- DataFrame复合索引
- 应用:matplotlib绘制starbuck数据
- 应用:统计书本的数据
- 应用:不同类型紧急电话的次数的变化情况(TBC)
- 总结
pandas
数据分类
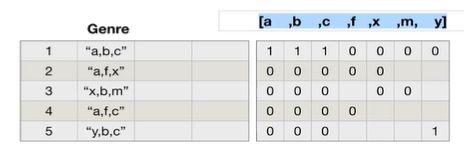
- 对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?(genre列的数据,每行有多个,由","分开)。
- 思路:重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1。
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "./IMBD-Movie-Data.csv"
df = pd.read_csv(file_path)
# 统计分类的列表
temp_list = df["Genre"].str.split(",").tolist() # [[], [], []]
genre_list = list(set([i for j in temp_list for i in j])) # 去重
# 构造全为0的数组,columns是每个genre的分类
zeros_df = pd.DataFrame(np.zeros(df.shape[0], len(genre_list)), columns=genre_list)
# 给每个电影出现分类的位置赋值1
for i in range(df.shape(0):
# zeros_df.loc[0, ["Sci-fi", "Musical"]] = 1
zeros_df.loc[i, temp_list[i]] = 1
# 统计每个分类的电影的数量和
genre_count = zeros_df.sum(axis=0)
# 排序
genre_count = genre_count.sort_values()
# 画图
_x = genre_count.index
_y = genre_count.values
plt.figure(figuresize = (20, 8). dpi = 80)
plt.bar(range(len(_x)), _y, width = 0.4, colors = "orange")
plt.xticks(range(len(_x)), _x)
plt.show()
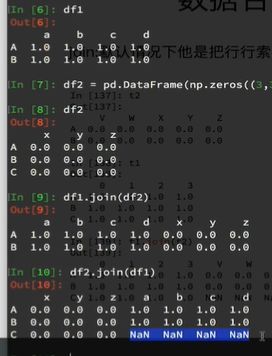
数据合并之join(行合并)
- join:默认情况下他是把行索引相同的数据合并到一起
- df1.join(df2):以df1的index为准
- df2.join(df1):以df2的index为准
数据合并之merge(列合并)
- merge:按照指定的列把数据按照一定的方式合并到一起
- 默认的合并方式how=“inner”,取intersection交集。
- df1.merge(df3, on=“a”):取df1和df3,a列中,值相同的行,也就是等于1的行,然后将df3合并到df3上来。在这里df1中a=1的有两行,所以df3中a=1的行分别对df1的两行赋值了两次。

- 在以下情况中,df1中a=1的行变为只有一行,因此,新merge的dataframe只有一行。

- df1.merge(df3, on=“a”):取df1和df3,a列中,值相同的行,也就是等于1的行,然后将df3合并到df3上来。在这里df1中a=1的有两行,所以df3中a=1的行分别对df1的两行赋值了两次。
- df1.merge(df3, on = “a”, how = “outer”):取union并集。NaN补全
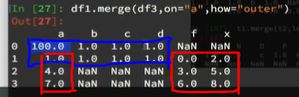
- df1.merge(df3, on = “a”, how = “left”):以左边的df1为准,取union并集。df1中所有的内容都会被呈现,df1有但是df3没有的则用NaN补全。

- df1.merge(df3, on = “a”, how = “right”):以右边的df3为准,取union并集。df3中所有的内容都会被呈现,df3有但是df1没有的则用NaN补全。

- 还可以left_on = “O”,right_on = “X”,使左边df的O列和右边df的X列对齐。

df切片和索引,Series vs. df
- 用但方括号为Series;双方括号为DataFrame

pandas的分组和聚合
- 现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
在读取数据后,可以查看df.info来确定数据是否有缺失。- df.groupby(by=“columns_name”)
- groupby返回的数据为
DataFrameGroupBy:每一个元素是一个元组,元组里面是(索引(分组的值),分组之后的DataFrame)-
可以进行遍历
for i, j in grouped: print(i) # i为国家名 print(j) # j为国家名是i的所有的行数据
-
可以调用聚合方法
grouped.count() # 结果如下图所示 grouped["Brand"].count() # 也可以针对某一列进行统计
-
其他DataFrameGroupBy对象可调用的方法:

-
import pandas as pd
file_path = "./starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
grouped_a = df.groupby(by = "Country")
country_count = grouped_a["Brand"].count()
# 美国和中国的星巴克数量哪个多
print(country_count["US"])
print(country_count["CN"])
# 统计中国每个省店铺的数量
china_data = df[df["Country"]=="CN"]
grouped_b = china_data.groupby(by="State/Province").count()["Brand"]
print(grouped_b)
- 对国家和省份同时进行分组统计
# 返回Series
grouped_c = df["Brand"].groupby(by=[df["Country"], df["State/Province"]]).count()
grouped_c = df.groupby(by=[df["Country"], df["State/Province"]])["Brand"].count()
grouped_c = df.groupby(by=[df["Country"], df["State/Province"]]).count()["Brand"]
# 返回DataFrame,df[["colname"]]使用双括号即可
grouped_c = df[["Brand"]].groupby(by=[df["Country"], df["State/Province"]]).count()
print(grouped_c)
- 运行结果:

索引和复合索引
- 如果是复合索引MultiIndex,则print(grouped.index)时,打印结果为
- MultiIndex(levels = [[…]], lables = [[…]], names=[…])
- index可使用的方法
- 获取index:df.index
- 指定index:df.index = [‘x’,‘y’]
- 重新设置index:df.reindex(list(“abcedf”)) 但新设置的df不影响原有的df。相当于从原df中提取了两行。

- 指定某一列作为index:df.set_index(“Country”, drop=False)
- 默认drop = True,此时,把Country列设置为index之后,删除Country列。
- drop = False,此时设置index之后,不删除Country列。

- 返回index的唯一值:df.set_index(“Country”).index.unique()
- 可以使用df[“colname”].unique()来统计列中出现的不同的值

- df的index可以重复,可以用unique方法来删除掉重复的数据行。也可以加len()方法来求长度

- 可以使用df[“colname”].unique()来统计列中出现的不同的值
- 设置符复合index

Series复合索引

- 只想取索引“h”对应的值时:使用df.swaplevel()

DataFrame复合索引
- 不可以直接用series的方法,因为df会默认传入的是column名字。需要使用df.loc[“外层index名”].loc[“内层index名”]
- 也可使用df.swaplevel()方法

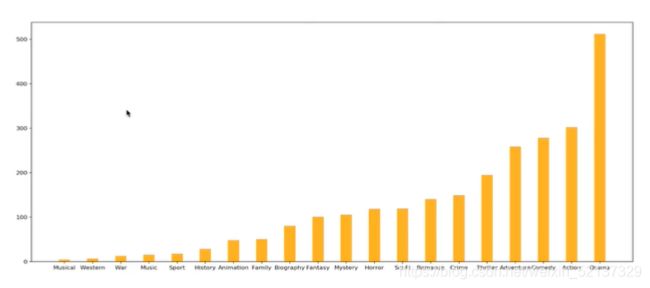
应用:matplotlib绘制starbuck数据
- 使用matplotlib呈现出店铺总数排名前10的国家
import pandas as pd
from matplotlib impot pyplot as plt
file_path = "./starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
# 准备数据
data1 = df.groupby(by="Country").count()["Brand"].sort_values(ascending=False)[:10]
_x = data1.index
_y = data1.values
# 画图
plt.figure(figuresize=(20, 8), dpi=80)
plt.bar(range(len(_x)), _y)
plt.xticks(range(len(_x)), _x)
plt.show()

- 使用matplotlib呈现出每个中国每个城市的店铺数量
import pandas as pd
from matplotlib impot pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname = "/Library/Fonts/Songti.ttc")
file_path = "./starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
df = df[df["Country"] == "CN"]
# 准备数据
data1 = df.groupby(by="Country").count()["Brand"].sort_values(ascending=False)[:25]
_x = data1.index
_y = data1.values
# 画图
plt.figure(figuresize=(20, 12), dpi=80)
plt.barh(range(len(_x)), _y, height=0.3, color="orange")
plt.yticks(range(len(_x)), _x, fontproperties=my_font)
plt.show()

应用:统计书本的数据
- 现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题:
- 不同年份书的数量
- 不同年份书的平均评分情况
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt
file_path = "./books.csv"
df = pd.read_csv(file_path)
# 不同年份书的平均评分情况
# 只去除original_publication_year列中nan的行,因此不使用df.dropna()
data1 = df[pd.notnull(df["original_publication_year"])]
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).mean()
# 画图
_x = grouped.index
_y = grouped.values
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
# 把刻度变为list,然后步长取为10,避免x轴的刻度重叠
plt.xticks(list(range(len(_x)))[::10],_x[::10].astype(int),rotation=45)
plt.show()

应用:不同类型紧急电话的次数的变化情况(TBC)
- 现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
- 不同类型的紧急情况的次数
# coding=utf-8
from matplotlib import pyplot as plt
import numpy as np
df = pd.read_csv("./911.csv")
# 获取分类
temp_list = df["title"].str.split(": ").to_list()
cate_list = list(set([i[0] for i in temp_list])) # 这里用的遍历效率也比较低,可以再考虑有没有更好的方法
# 构造全为0的数组
zeros_df = pd.DataFrame(np.zeros((df.shape[0], len(cate_list))), columns=cate_list)
# 根据分类,把全为0的数组选择性赋值为1,方法一:
for cate in cate_list:
zeros_df[cate][df["title"].str.contains(cate)] = 1
# 根据分类,把全为0的数组选择性赋值为1,方法二:效率比方法一低很多
# for i in range(df.shape[0]):
# zeros_df.loc[i, temp_list[i][0]] = 1
sum_ret = zeros_df.sum(axis = 0)
print(sum_ret)
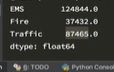
- 不同月份不同类型紧急电话的次数的变化情况:这个问题需要用到时间序列,在下一个section具体讲解。
总结