什么是序列化与反序列化
序列化是指把对象转换为字节序列的过程(Encoding an object as a byte stream is known as serializing the object.)
反序列化是指把字节序列恢复为对象的过程(The reverse process is known as deserializing it.)
序列化与反序列化面向的是成员变量,类的方法和静态变量不参与序列化与反序列化。
什么场景下需要用到序列化与反序列化
当两个进程进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。那么当两个Java进程进行通信时,能否实现进程间的对象传送呢?答案是可以的。如何做到呢?这就需要Java序列化与反序列化了。换句话说,一方面,发送方需要把这个Java对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出Java对象。
当我们明晰了为什么需要Java序列化和反序列化后,我们很自然地会想Java序列化的好处。其好处一是实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里),二是,利用序列化实现远程通信,即在网络上传送对象的字节序列。
即:涉及I/O(磁盘I/O 网络I/O),需要用到序列化与反序列化。
如何实现序列化与反序列化
以JDK实现方式为例,参考JDK中与I/O相关的类。
序列化
I/O OutputStream:
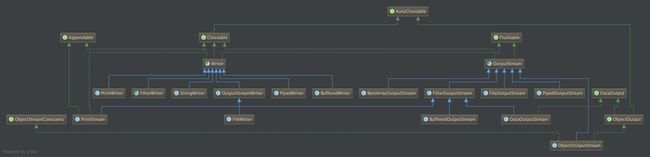
在序列化过程中,主要使用DataOutputStream(primitive Java data types) / ObjectOutputStream(primitive Java data types & objects) / OutputStream。
// serialize
public static byte[] serialize(T obj) {
ObjectOutputStream objectOutputStream = null;
ByteArrayOutputStream byteArrayOutputStream = null;
try {
byteArrayOutputStream = new ByteArrayOutputStream();
objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(obj);
return byteArrayOutputStream.toByteArray();
} catch (Exception e) {
logger.error("serialize error", e);
}
return null;
}
反序列化
I/O InputStream:
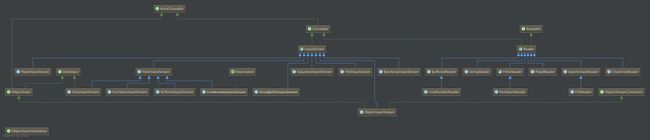
在反序列化过程中,主要使用DataInputStream(read primitive Java data types) / ObjectInputStream(read primitive data and objects) / InputStream。
// deserialize
@SuppressWarnings("unchecked")
public static T deserialize(byte[] bytes) {
try {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(byteArrayInputStream);
return (T) ois.readObject();
} catch (Exception e) {
logger.error("deserialize error", e);
}
return null;
}
transient
使用transient关键字修饰的实例变量不会参与默认的序列化及反序列化,如实例的敏感信息字段等:
public class Person implements java.io.Serializable {
...
private transient String phone;
...
}
这里提到了默认的序列化及反序列化,如果使用自定义序列化方式,则可以对transient关键字修饰的实例变量进行序列化及反序列化,以实现Externalizable接口自定义序列化、反序列化为例:
public class ExternalizablePerson implements java.io.Externalizable {
private static final long serialVersionUID = 1866740372404660450L;
private String name;
private Integer age;
private String career;
private transient String phone;
/**
* 自定义序列化方式
* @param out
* @throws IOException
*/
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(age);
out.writeUTF(career);
out.writeUTF(phone);
}
/**
* 自定义反序列化方式
* @param in
* @throws IOException
* @throws ClassNotFoundException
*/
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = in.readUTF();
age = in.readInt();
career = in.readUTF();
phone = in.readUTF();
}
}
关于Externalizable接口,可以参考:What is the difference between Serializable and Externalizable in Java
serialVersionUID
serialVersionUID的取值是Java运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的serialVersionUID的取值有可能会发生变化。
类的serialVersionUID的默认值完全依赖于Java编译器的实现,对于同一个类,用不同的Java编译器编译,有可能会导致不同的serialVersionUID。为了提高serialVersionUID的独立性和确定性,强烈建议在一个可序列化类中显示的定义serialVersionUID,为它赋予明确的值。
关于serialVersionUID,可以参考:What is a serialVersionUID and why should I use it?
writeReplace()/writeObject()/readObject()/readResolve()
这四个方法在 java.io.ObjectStreamClass 中定义,用于自定义序列化、反序列化。如果在Java实体类中声明了这些方法,执行顺序如下(以反射的方式执行,如writeObject在ObjectOutputStream中被调用,readObject在ObjectInputStream中被调用):
| 执行顺序 | 方法名称 | 类型 | 作用 | 方法描述 |
|---|---|---|---|---|
| 1 | writeReplace | 序列化 | 在writeObject之前执行,可用于替换将要被序列化的实例(序列化代理) | private Object writeReplace() {} |
| 2 | writeObject | 序列化 | 对ObjectOutputStream中的byte执行序列化操作 | private void writeObject(java.io.ObjectOutputStream out) throws IOException {} |
| 3 | readObject | 反序列化 | 对ObjectInputStream中的byte执行反序列化操作 | private void readObject(java.io.ObjectInputStream out) throws IOException, ClassNotFoundException {} |
| 4 | readResolve | 反序列化 | 在readObject之后执行,可用于替换返回的反序列化实例(单例) | private Object readResolve() {} |
序列化与反序列化中的注意事项
谨慎实现java.io.Serializable接口
实现java.io.Serializable接口后,会造成以下影响:
- 一旦类被发布,会大大降低修改该发布类的灵活性
如果一个类实现了Serializable接口,它的字节流编码也变成了它导出API的一部分,它的子类都等价于实现了序列化,以后如果想要改变这个类的内部表示法(添加/修改/删除成员变量等),可能导致序列化形式不兼容。
- 增加了出现Bug和安全漏洞的可能性
一般对象是由构造器创建的,而序列化也是一种对象创建机制,反序列化也可以构造对象,默认的反序列化机制构造对象过程中,很容易遭到非法访问,使构造出来的对象,并不是原始对象,引发程序Bug和其他安全问题。
随着类的新版本发布,带来了更大的测试成本
性能开销变大
序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其他对象也进行序列化,从而增大系统开销
保护性编写readObject方法
反序列化可以绕过构造函数生成实例,如果实例在构造过程中存在业务上或逻辑上的限制,在序列化上使用了默认的序列化方式(即只继承java.io.Serializable接口),则可以通过反序列化方式绕过构造实例限制,从而生成不合法的实例。
以Peroid类为例,该类含有两个字段:start(起始时间),end(终止时间),业务规则限制初始化Period实例时,start < end,构造函数如下:
// all args constructor
public Period(Date start, Date end) {
this.start = new Date(start.getTime());
this.end = new Date(end.getTime());
// 检查起止时间
if (this.start.compareTo(this.end) > 0) {
throw new IllegalArgumentException(start + " after " + end);
}
}
现在通过以下byte[],反序列化生成Period实例:
private static final byte[] serializedBytes = new byte[] {
(byte)0xac, (byte)0xed, 0x00, 0x05, 0x73, 0x72, 0x00, 0x10, 0x64, 0x65, 0x66, 0x65, 0x6e, 0x73, 0x69, 0x76,
0x65, 0x2e, 0x50, 0x65, 0x72, 0x69, 0x6f, 0x64, 0x39, (byte)0xc0, (byte)0x85, 0x2d, 0x4a, (byte)0xc1, 0x6b,
0x44, 0x02, 0x00, 0x02, 0x4c, 0x00, 0x03, 0x65, 0x6e, 0x64, 0x74, 0x00, 0x10, 0x4c, 0x6a, 0x61, 0x76, 0x61,
0x2f, 0x75, 0x74, 0x69, 0x6c, 0x2f, 0x44, 0x61, 0x74, 0x65, 0x3b, 0x4c, 0x00, 0x05, 0x73, 0x74, 0x61, 0x72,
0x74, 0x71, 0x00, 0x7e, 0x00, 0x01, 0x78, 0x70, 0x73, 0x72, 0x00, 0x0e, 0x6a, 0x61, 0x76, 0x61, 0x2e, 0x75,
0x74, 0x69, 0x6c, 0x2e, 0x44, 0x61, 0x74, 0x65, 0x68, 0x6a, (byte)0x81, 0x01, 0x4b, 0x59, 0x74, 0x19, 0x03,
0x00, 0x00, 0x78, 0x70, 0x77, 0x08, 0x00, 0x00, 0x01, 0x63, 0x79, 0x21, 0x10, 0x00, 0x78, 0x73, 0x71, 0x00,
0x7e, 0x00, 0x03, 0x77, 0x08, 0x00, 0x00, 0x01, 0x63, (byte)0xb1, (byte)0xc7, 0x04, 0x00, 0x78
};
public static void main(String[] args) throws Exception {
// create instance via deserialize
Period illegalPeriod = SerializeUtil.deserialize(serializedBytes);
log.info("Period instance from deserialize: {}", illegalPeriod);
}
通过这种方式,我们构造出了实例属性start == 2018-05-31 00:00:00,end == 2018-05-20 00:00:00的非法实例。为了解决这一问题,需要通过编写readObject方法,禁止通过反序列化创建非法实例:
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
// check start < end
if (start.compareTo(end) > 0) {
throw new InvalidObjectException(start + " after " + end);
}
}
查看完整代码
使用序列化代理代替序列化实例
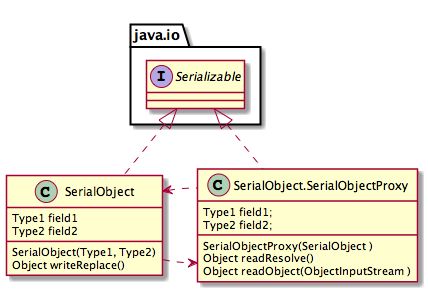
通过创建实例变量完全一致的静态内部类,作为序列化代理类,将序列化、反序列化过程交由序列化代理类完成:
/**
* 序列化代理类
*/
private static class PersonProxy implements Serializable {
private static final long serialVersionUID = -2902051239103230395L;
private String name;
private Integer age;
private String career;
private String phone;
public PersonProxy(Person p) {
log.info("PersonProxy(Person original)");
this.name = p.getName();
this.age = p.getAge();
this.career = p.getCareer();
this.phone = p.getPhone();
}
private Object readResolve() {
log.info("PersonProxy.readResolve()");
Person person = new Person(name, age, career, phone);
return person;
}
private void readObject(ObjectInputStream in) throws Exception {
log.info("PersonProxy.readObject");
in.defaultReadObject();
}
}
private Object writeReplace() {
log.info("Person.writeReplace()");
return new PersonProxy(this);
}
/**
* 本方法不会执行,因为序列化已经由PersonProxy实例代理
* @param out
*/
private void writeObject(ObjectOutputStream out) {
log.info("Person.writeObject()");
}
/**
* 防止攻击者伪造数据(age < 0 || age >> 100)
* @param in
* @return
* @throws InvalidObjectException
*/
private void readObject(ObjectInputStream in) throws InvalidObjectException {
throw new InvalidObjectException("Proxy required");
}
查看完整代码
通过使用序列化代理类,可以方便编写保护性的readObject方法,避免因序列化、反序列化使用不当造成潜在系统漏洞。
序列化与反序列化可能造成的系统漏洞
如“保护性编写readObject方法”所示,通过构造bytes可以在反序列化时生成不合法的实例,从而导致系统漏洞。
第三方序列化工具类介绍
Hessian
Hessian是一个轻量级的remoting on http工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
示例
import com.caucho.hessian.io.HessianInput;
import com.caucho.hessian.io.HessianOutput;
...
Person person = new Person();
person.setName("Tom");
person.setAge(25);
person.setCareer("engineer");
person.setPhone("15201726287");
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
// serialize
HessianOutput hessianOutput = new HessianOutput(byteArrayOutputStream);
hessianOutput.writeObject(person);
byte[] bytes = byteArrayOutputStream.toByteArray();
log.info("serialized result: {}", bytes);
// deserialize
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
HessianInput hessianInput = new HessianInput(byteArrayInputStream);
Person deserializedPerson = (Person) hessianInput.readObject();
log.info("deserialized result: {}", deserializedPerson);
应用
Hessian
Protobuf
Protobuf是一种轻便高效的结构化数据存储格式,用于结构化数据序列化。它很适合做数据存储或RPC数据交换格式,可用于通讯协议、数据存储等领域。Protobuf是一种跨语言、跨平台、可扩展的序列化结构数据格式。
示例
// Filename: person.proto
syntax="proto2";
option java_package = "protobuf.bean";
message Person {
required string name = 1;
required int32 age = 2;
required string phone = 3;
required string career = 4;
}
# generate Java class
protoc --java_out=[dir] [.proto file path]
PersonOuterClass.Person.Builder personBuilder = PersonOuterClass.Person.newBuilder();
personBuilder.setName("Jerry");
personBuilder.setAge(20);
personBuilder.setCareer("teacher");
personBuilder.setPhone("15112933840");
PersonOuterClass.Person person = personBuilder.build();
log.info("build result: {}", person);
// serialize
byte[] bytes = person.toByteArray();
log.info("serialized result: {}", bytes);
// deserialize
PersonOuterClass.Person deserializePerson = PersonOuterClass.Person.parseFrom(bytes);
log.info("deserialized result: {}", deserializePerson);
应用
gRPC
Kryo
Kryo是一个快速高效的Java序列化框架,旨在提供快速、高效和易用的API。无论文件、数据库或网络数据Kryo都可以随时完成序列化。Kryo还可以执行自动深拷贝(克隆)、浅拷贝(克隆)。这是对象到对象的直接拷贝,非对象->字节->对象的拷贝。
示例
序列化/反序列化:
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
...
Kryo kryo = new Kryo();
// declare Output stream
Output output = new Output(new FileOutputStream("file.bin"));
Person person = new Person();
person.setName("Tom");
person.setAge(25);
person.setCareer("engineer");
person.setPhone("15201726287");
// serialize
kryo.writeObject(output, person);
output.close();
// declare Input stream
Input input = new Input(new FileInputStream("file.bin"));
// deserialize
Person deserializePerson = kryo.readObject(input, Person.class);
log.info("deserialize result: {}", deserializePerson);
input.close();
深拷贝/浅拷贝:
Kryo kryo = new Kryo();
Engineer engineer = new Engineer();
engineer.setName("Tom");
engineer.setAge(25);
engineer.setCareer("engineer");
engineer.setPhone("15201726287");
// non primary type
List skills = new ArrayList<>();
skills.add("math");
skills.add("programming");
skills.add("system");
skills.add("algorithm");
engineer.setSkills(skills);
// deep copy
Engineer deepCopyEngineer = kryo.copy(engineer);
log.info("deep copy result: {}, is skills equal: {}",
deepCopyEngineer, engineer.getSkills() == deepCopyEngineer.getSkills());
// shallow copy
Engineer shallowCopyEngineer = kryo.copyShallow(engineer);
log.info("shallow copy result: {}, is skills equal: {}",
shallowCopyEngineer, engineer.getSkills() == shallowCopyEngineer.getSkills());
应用
Hive Spark Storm Akka
总结
关于序列化与反序列化的知识还有很多,如:
- java.util.HashMap、java.util.ArrayList 等集合类中关于序列化及反序列的自定义处理,为什么这么处理
- Kryo、Protobuf等第三方序列化工具做了哪些工作,使得序列化、反序列化速度相比JDK自带的序列化、反序列速度优秀很多
等,在后续系列博客中将继续探索。