【Python爬虫】从零开始爬取Sci-Hub上的论文(串行爬取)
【Python爬虫】从零开始爬取Sci-Hub上的论文(串行爬取)
- 项目简介
- 步骤与实践
-
- STEP1 获取目标内容的列表
- STEP2 利用开发者工具进行网页调研
-
- 2.1 提取文章链接和分页链接的特征
- 2.2 提取文章 DOI 所在元素的特征
- 2.3 探索 sci-hub 上 pdf 资源的打开方式
-
- 2.3.1 梳理基本流程
- 2.3.2 查看 robots.txt
- 2.3.3 提取pdf资源的元素特征
- STEP3 开始写代码,就从"下载"入手吧
-
- 3.1 conda虚拟环境搭建、加载和使用
-
- 3.1.1 创建虚拟环境
- 3.1.2 配置下载包的镜像源
- 3.1.3 给虚拟环境安装所需模块
- 3.1.4 加载虚拟环境到我们的 IDE —— PyCharm
- 3.2 下载一个pdf文献的代码实现
-
- 3.2.1 用 requests 根据 DOI 获取文献对应网页的文本
- 3.2.2 提取 html 中的 pdf 资源链接 (3种方式)
-
- 正则表达式 (Regular Expression)
- Beautiful Soup
- Lxml ⋆ \star ⋆
-
- 在浏览器控制台中使用选择器
- 在代码中使用选择器
- 3.2.3 根据获得的 pdf 链接执行下载
- 3.2.4 看看哪些地方仍需改进
-
- 磁盘文件合法命名
- 获得文件所需的名称 —— 文献标题
- robots.txt 解析以及下载时间间隔设置
- 添加一个简单的缓存类 Cache
- 3.3 回到 Web of Science,提取搜索页的 DOI 列表
-
- 3.3.1 方法一:修改 doc 属性值快速构建 url,然后从中爬取 doi
- 3.3.2 方法二:结合 Web of Science 导出功能的"零封禁几率"方法
- STEP4 组装起来,形成终极接口:sci_spider()
-
- 4.1 流程梳理 ⋆ \star ⋆
- 4.2 组装起来,给它取个名字,就叫 "sci_spider" 好了
- 4.3 对第一次运行结果的分析与问题处理 ⋆ \star ⋆
-
- 4.3.1 运行结果分析
- 4.3.2 问题1:标题抓取为空 —— 用 DOI 作为名字
- 4.3.3 问题2:HTTP协议头重复 —— 添加判断去重
- 4.3.4 最后的调试
- 爬虫感想
- 资源 (见GitHub)
- References
WARNING:专业人士请速速撤离,否则将浪费至少半小时的时间!
2020-12-06 阴
是时候上手鸽了半个月的小项目了。。。
笔者为了偷懒,准备边做爬虫边记录过程,毕竟做完后还要花很多时间回顾,这里就直接省去回顾的过程,每完成一个步骤便做好相应的步骤记录。当你读到这段文字时,笔者尚未开始进行这个项目的实践,但也并非完全"从零开始" —— 在此之前笔者学了一些爬虫相关的先修知识,并作了实践环境和工具的一些配置,具体如下:
★ \bigstar ★ 先修知识 (每一项笔者都附上了教程链接,如有需要可以点击查看)
-
Web基础 (html5,只需看得懂网页层级结构和标签属性含义即可) → \rightarrow → 点击查看 html 基础教程
-
正则表达式 (能看懂并构建简单的表达式) → \rightarrow → 点击查看正则表达式基础教程
-
Python3 基础语法 (能编写函数和类,懂列表、字典等经典数据结构的操作) → \rightarrow → 点击回顾 Python3 基础知识
-
爬虫的基本操作 (对应文献1的前三章 [1])
-
网页调研 (了解html文本结构,分析元素特征,查看网页的 robots.txt 获取爬取的基本要求)
-
数据抓取 (获取html文本中的目标内容,如 url,列表项内容等,常用的方式有:① 正则表达式;② BeautifulSoup;③ Lxml 以及CSS选择器和Xpath选择器)
-
下载缓存 (
这个项目可能用不到)
-
★ \bigstar ★ 工具与环境
-
语言版本:Python3.6 (这个安装就不用我多说了吧,网上搜一下就有)
-
IDE:PyCharm Community Edition 2019.3.3 (同上)
-
虚拟环境管理:Anaconda3 → \rightarrow → 点此查看 ① PyCharm加载和使用虚拟环境;②conda环境管理
注:如果不清楚虚拟环境的意义,可以自行搜索了解,简单来说就是为爬虫用到的库单独创建一个容器,与爬虫相关的模块都放在这里,以防止各模块版本错乱,导致用 Python3 写的其余项目因版本问题出现错误。
好了,有了以上准备,我们就可以真正地"从零开始"我们的爬虫之旅了!
项目简介
开始构建爬虫之前,首先明确我们的需求:根据搜索文本从sci-hub上爬取论文(pdf格式),具体方式是:
-
在 Web-of-Science 网站上输入搜索文本,执行搜索后获取每一项搜索结果的 DOI (Digital Object Identifier,数字对象唯一标识)
-
根据得到的 DOI,依次在 Sci-Hub 上查找到论文资源并下载
当然,上述描述是可行的 (手动操作),但现在我们要通过爬虫来实现"无UI交互",即通过代码而不是人为浏览网页的方式达到目的。为此,需要细化以上过程的描述,这个过程笔者是边想边做的,当实现所有的描述时,任务也就完成了。
步骤与实践
先附上项目涉及的两个主要网站:
-
Web of Science: http://apps.webofknowledge.com
-
Sci-Hub: https://sci-hub.do/ (这个经常被封禁,如果用不了可以上网搜其他的域名)
补充:笔者使用的浏览器是Google Chrome,其实用哪个浏览器都行,只要能正常访问网页,且浏览器有开发者工具(按F12调出)即可。
STEP1 获取目标内容的列表
由用户手动在 Web-of-Science 上搜索某一内容(这里采用主题模式,搜索 “unity3D”),获得相应的列表,如下图所示:

注意:
-
搜索结果后面显示了查询结果个数,我们可以根据它来决定下载文件的数量
-
有一些是专利发表,不包含 DOI (如上图第2项),不过只要我们的爬虫不会错误地访问并下载它们就行
STEP2 利用开发者工具进行网页调研
对产生列表的网页进行html文本特征分析,发现列表每一项中并没有列出 DOI,这意味着两件事:
-
我们需要存储列表网页中的目标url (用一个列表结构存储),由于搜索结果可能不止一页,因此,我们保存的 url 中应既包括文章链接,也包括分页链接 (其他链接就不考虑了)。
-
我们需要访问每一个 url 列表中的链接,找到 DOI 所在的标签,分析其所在的嵌套层级以及它本身的特征 (标签的特征属性,如 ”href“、“id”、“class” 等),并把所有 DOI 也保存到一个列表中,甚至可以将它存到磁盘 (例如以 .csv 或 .txt 格式保存)。
先吃个饭,然后分析一波目标url的特征以及DOI所在标签的特征。。。
2.1 提取文章链接和分页链接的特征
那么,文章链接和分页链接怎么找呢?打开开发者工具(F12),使用 “选择元素” 功能 (Shift + Ctrl + C)选定页面中的目标元素,帮助我们缩小查找范围,甚至直接定位链接。下面分别给出了针对文章链接和分页链接的选择元素图例,以及各自的查找到的链接情况:
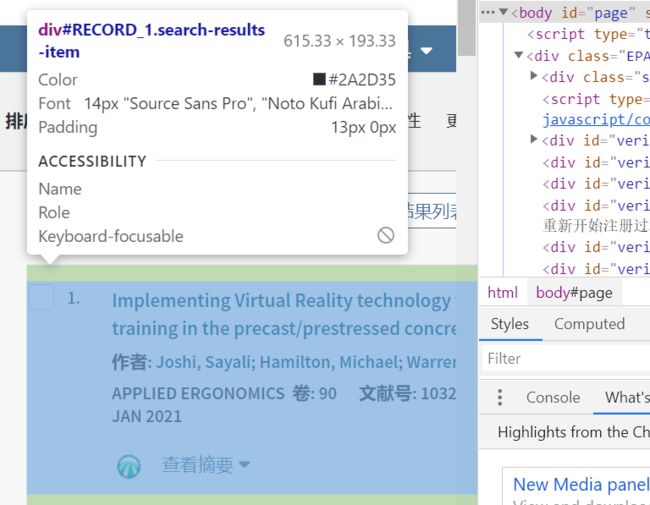
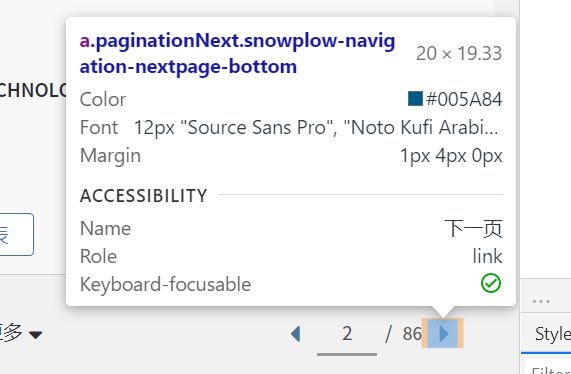
下面是找到的目标区域链接,依次为 文章链接 和 分页链接:
<a class="smallV110 snowplow-full-record"
href="/full_record.do?product=UA&search_mode=GeneralSearch&qid=2&SID=7ERiKiVBBTB6qFk3KUC&page=1&doc=1" tabindex="0" oncontextmenu="javascript:return IsAllowedRightClick(this);" hasautosubmit="true">
<value lang_id="">Implementing Virtual Reality technology for safety training in the precast/prestressed concrete industryvalue>
a>
<a class="paginationNext snowplow-navigation-nextpage-bottom"
href="http://apps.webofknowledge.com/summary.do?product=UA&parentProduct=UA&search_mode=GeneralSearch&parentQid=&qid=2&SID=7ERiKiVBBTB6qFk3KUC&&update_back2search_link_param=yes&page=2" alt="下一页"
title="下一页" aria-label="下一页" tabindex="0" oncontextmenu="javascript:return IsAllowedRightClick(this);" hasautosubmit="true">
<i>i> a>
为了提取特征,笔者额外找了几个不同文献和不同分页的链接,发现了一些共同点,它们正是我们做爬虫的重要依据:
-
每一个文章链接都在
标签的href属性中,且标签class相同,均为"smallV110 snowplow-full-record";分页链接的class="paginationNext snowplow-navigation-nextpage-bottom" -
观察 url 本身,发现 文章链接 的 url 是个相对url,
/full_record.do?...打头,如果手动点击进入的话其链接为http://apps.webofknowledge.com/full_record.do?...;而 分页链接 的 url 是个绝对url,链接为http://apps.webofknowledge.com/summary.do?product...,我们需要的是绝对url,这说明我们对于 文章链接 还需要额外处理,加上http://apps.webofknowledge.com这一部分。
由于 文章链接 和 分页链接 的处理模式存在区别,而它们的 class 属性不同,因此我们可以创建两个队列,利用 class 属性区分两种链接,分别加入到相应的队列中,并且优先处理文章链接所在的队列,这意味着当且仅当文章链接的队列为空时,才会处理分页链接的队列。然而,还有更简单且高效的方法,不用一个个请求网页的内容,没有IP封禁的危险 (见 3.3 节)。
2.2 提取文章 DOI 所在元素的特征
下面我们把目光聚焦到 文章链接 打开的页面,找寻文章的DOI,其操作和上一节的一样。仅陈列页面布局和目标元素内容:

<div class="block-record-info">
<p class="FR_field">
...
p>
div>
<div class="block-record-info-source-values">
...
<p class="FR_field">
<span class="FR_label">文献号:span>
<value>103286value>
p>
<p class="FR_field">
<span class="FR_label">DOI:span>
<value>10.1016/j.apergo.2020.103286value>
p>
...
div>
通过对其父级标签 如此一来,我们便可以轻松获得多个文献的 DOI,并把它们存放于一个列表中,甚至写入磁盘文件。 假定我们已经有一个十分有效的方式得到合法的 DOI 列表 (然而现在我们并没有),那么下一步就是将 sci-hub 的手动下载模式转换为程序控制的批量作业。为此我们得先摸清手动操作是怎么个流程: wtf,校园网连接没有响应,访问不了 sci-hub 资源链接。。。那我先看会书,等回宿舍后再接着做吧 可能是今天网络问题 (事实上当时 sci-hub 在维护中),使得我无法通过输入 DOI 来访问 sci-hub 相应资源,不过没关系,我们先看看 sci-hub 的 robots.txt 文件 (主页域名后面加个 这个文件是一个非强制性的协议,每个良好的网络公民都应该遵守这些限制,否则有可能遭到封禁。该文件的解读方法 → \rightarrow → 爬虫之robots.txt 从该文件的内容可知,第一部分: (应该说只要用户代理不是 Twitterbot,那我们便可以"横着走"。) 2020-12-07 雪 我们随便找个文献的DOI,请求相应的链接。试了好久,终于成功进去了!! 审查网页中 save 按钮,定位其标签在超文本中的位置: 我们注意 太好了!这样我们的一轮流程就走完了,剩下的都是重复的迭代过程,就交给计算机处理了。因此,现在我们可以顺着以上的思路写代码了。 再次提一下,我们最终的期望是实现批量 pdf 下载,可见"下载"是我们的关键步骤(之一)。当我们的流水线到达下载这一步时,我们已经获得了一个 DOI 列表,我们需要根据这个 DOI 列表中的每一项来依次执行下载任务,2.3.3 节已经分析了 pdf 资源链接的构成,即 HTTP协议 + 冒号’:’ + location.href 的内容,最后一部分是从链接{ 可以跳过这部分内容 —— 虚拟环境不是必要的。但当你有多个项目正在开发时,虚拟环境可以有效管理安装包的版本,避免混乱。 现在笔者手上已有 PyCharm (ver 2019.3.3) 以及 Anaconda 3,使用的 Python3 版本为 3.6,OS 为 Win10。 我想你应该已经把 Python 语言以及 Anaconda 的环境变量配置好了,如果不确定的话可以查看 Python3 安装根目录下的Scripts文件夹所在路径,e.g: D:\…\Scripts Anaconda 安装根目录下Scripts文件夹所在路径,e.g: E:\…\Anaconda\Scripts 首先找到 Anaconda Prompt (笔者直接在开始菜单 'A’字母中的 Anaconda文件夹下找到),打开后如下: 输入 至此,虚拟环境安装完毕,我们本次项目要用到的所有包都放在这个环境中。 一般使用的是清华镜像源,里面有大量的包,我们可以按需从镜像源获取模块。 如果你已经配置过,那么不论之后是否创建新的虚拟环境,你都无需再配置了。 键入如下指令添加镜像源 (注意:HTTP协议不要用 如果你用的是其他操作系统,可能需要更改一波镜像源路径,具体可以去清华镜像站查看目录层级,比如修改 这样我们就可以在 下载源设置好了,下面我们可以安装包了。 我们来安装待会要用到的 回到 Anaconda Prompt,输入 输入 至此, 之后所有的包都是这么个安装流程:激活环境 → \rightarrow → 安装包 → \rightarrow → 退出环境。 如果读者用的是其他 IDE,没有关系,网上有很多介绍如何将虚拟环境加载到 IDE 的资料。笔者这里也不再赘述,仅给个PyCharm使用虚拟环境的链接 —— PyCharm加载和使用虚拟环境。 如果您是从头开始读到这里,那么,在这里说声,幸苦了!表面上看,我们的征途才刚刚开始,但笔者认为,现在已经快结束了 (可能有些夸张 (来自未来:太TM夸张了),但至少已经完成一半的工作了 (来自未来:这倒是没错))。后续基本上是代码的实践与细节,每一个步骤,笔者会先上代码,然后简要分析一下:①代码干了什么;②为什么这么写? 至于里面用到的一些模块函数的用法,我确定您是知道的 (至少有两种办法知道,其中一个方法是查看模块源文件;另一个是上网搜索解决方案)。因此笔者就偷个懒,省去一些功夫去解析它们 —— 我们这里更强调对模块函数的使用,了解接口的功能和用法就好了 (在PyCharm中,只需要把光标放在相应函数上,Ctrl + 鼠标左键 即可查看相应的函数定义)。 下面我们直接给出 获取特定 DOI 网页超文本 的 Python3 实现 (download.py): 运行结果: 对代码的说明: 简析一下函数原型: doi → \rightarrow → 文献的DOI号 user_agent → \rightarrow → 用户代理,根据sci-hub主页的 robots.txt 确定,默认值只要不是 proxies → \rightarrow → 代理,默认置为 num_retries → \rightarrow → 下载的重试次数,仅当请求状态码为 start_url → \rightarrow → 主页域名,绝对路径中固定的一部分,单独拧出来,默认为 因此简要概括这个函数的功能:根据传入的 DOI 号,抓取所在文献的 html 文本,以供后续提取 请求访问网站的关键函数: 下载搞定了,意味着我们得到了文献网页的 html,它将作为提取pdf资源链接的输入,也可称作"原材料"。 在 2.3.3 节我们已经大致分析了 pdf 资源链接的特征,我们的任务是从中找到一种模式 (pattern),它能较好地帮我们从冗长的 html 文本中筛选并匹配到目标元素。 为了方便说明笔者后续的提取方法,把 2.3.3 节目标所在位置的文本再陈列一遍 (原汁原味,没有任何修改,之前的为了美观,把一些空行、空格去掉了): 对比一下抓取到的 html 文本的相同部分: 我们由以上对比,我们可以发现两者的一些共性和区别: 各个标签之间有可能有空行、空格,也可能没有 前者的 这些细微的点如果不注意,将令我们编写正则表达式时吃尽苦头 (反正笔者已经"吃饱了")。 如果你能熟练运用正则表达式,相信你会有 “万物皆可RegEx” 的信念,并且会更倾向于用它解决这类匹配问题 —— 即使它仍存在很多局限。如果想要了解它,笔者在文章开头就已经给出了教程,这里再附个有关 Python中使用正则表达式 的链接。 像笔者这种笨比,编写的正则表达式又臭又长,且经常需要修改很多遍才能弄好,不过好在有正则表达式在线测试网站,大大提高了正则表达式的编写效率。 我们可以根据其中一篇文献的下载链接来编写正则表达式,然后随机找几篇文献(不同领域)的下载链接对正则表达式验证,如果测试的那些没问题,我们就直接用吧。 下面给出 用正则表达式匹配超文本以获取匹配内容列表 的 Python3 实现 (scraping_using_regex.py): 运行结果: 对代码与结果的说明: 笔者编写这个正则表达式花了大约 1 个小时,中间遇到了很多坑,其中就包括了 3.2.2 节开头提到的点 (主要问题还是笔者的 RegEx 水平烂),最后写了个能用但很繁琐的表达式 灵活性高,可以随时调整;匹配速度比较快 对使用者的要求高,容易写错,复杂匹配的正则表达式晦涩难懂 十分脆弱,可能网页标签格式不对、或者网页稍微变一下,整个正则表达式就失效了 话虽如此,但还是有必要掌握基本的构造模式滴。 笔者选择了3个不同主题文献的 输出中有警告信息,暂且不要管 2020-12-08 晴 Beautiful Soup,不知道设计者为何取了个这个名字,但使用起来确实感觉 very beautiful 就是了。语法简单,而且可以对 html 网页的语法问题进行修复,唯一的瑕疵就是有些慢,不过能理解,毕竟是用纯 Python 编写的 (正则 和 Lxml 是 C 语言写的)。 需要安装两个模块 (别忘了先进入虚拟环境) : 直接上手,下面给出 用 BeautifulSoup 匹配超文本以获取匹配内容列表 的 Python3 实现 (scraping_using_bs4.py): 运行结果 (省去警告): 对代码的说明: 上面的代码采用了 BeautifulSoup + 正则表达式,主要做了如下几件事: 虽然没有直接导入 通过条件判断是否为 和 BeautifulSoup 一样,使用 Lxml 模块的第一步也是将有可能不合法的 html 解析为统一格式;同样地,Lxml 也可以正确解析属性两侧缺失的引号,并闭合标签,不过该模块没有额外添加 本小节我们将使用选择器来定位元素,包括 CSS选择器 和 XPath选择器。 对于它们的相关说明,读者可以通过以下参考链接查阅: 笔者这里列出几个基本但常用的选择器表达式,见下表: 在后续实践中可能用到的CSS选择器的补充: 我们可以在开发者工具的控制台 (Console) 中使用这些选择器来预先调试我们的选择器字符串,看看能否正常筛选。对于CSS选择器,其在浏览器中的选择器使用格式为 下面先演示CSS选择器在开发者工具中如何使用: 随意选一片文献,比如笔者选择了 https://sci-hub.do/10.1016/j.apergo.2020.103286 F12 打开开发者工具,切换到 Console 控制台 键入我们的CSS选择表达式: 对于XPath选择器,我们甚至可以直接找到 在浏览器中我们已经见识了选择器的方便与强大,下面看看代码中怎么使用它们。 安装 lxml 和 cssselect 模块: 下面给出 用 lxml 以及一种选择器匹配超文本以获取匹配内容列表 的 Python3 实现 (scraping_using_lxml.py): 运行结果 (省去警告): 对代码和结果的说明: 两种选择器最终都达到了目标要求,而且两种方法的代码只有一行的差别,即 lxml 模块函数 注意异常的处理 (第3个 doi 获取的网页是不合法的) 这里还没有筛选完,我们可以沿用 BeautifulSoup 小节的方式,采用正则表达式作为最后的筛选工作: 2020-12-09 晴 下载链接得到了,我们通过组装链接构成绝对 url,然后使用 request 模块的 下面给出 给定 DOI 执行一次相应文献的 pdf 下载 的 Python3 实现 (download.py): 运行结果: 注意 url 的拼接格式 注意是用 测试代码中使用的是 XPath 选择器提取下载链接,这里换成 3.2.2 节中任意一种方式都可行 (可能有一些细节需要变化) 这里的文件名暂时用一个比较固定的 对于文件名称,我们有以下要求: 不重复 (在目录中唯一地标识一个文件) 有意义 (便于查找) 综上,我们选择文献标题作为文件名 (不要抬杠)。那么问题来了,能不能不做任何转换就拿来用?比如其中一篇文献的题名为: Implementing Virtual Reality technology for safety training in the precast/ prestressed concrete industry. Applied Ergonomics, 90, 103286. 我们注意到,此标题中含有 运行结果: 从结果可见, 2020-12-10 晴 现在浏览器中用"选择元素" (Ctrl + Shift + C) 对标题定位一波,然后使用XPath选择器筛选出标题文本 (CSS选择器类似): 修改我们在 3.2.2 节写的 对代码的说明: 笔者后续实践中发现,不是所有文献标题都有 注意改动的部分 (后面加注了数字) 正则表达式和 Beautiful Soup也采用相似的修改方式,只需要多抓取一个标题名称就行,笔者在此仅给出主要修改处的代码,其余保持不变: 还记得 2.3.2 节提到的 我们可以在请求文献内容前进行进行一次 运行结果: 对代码和结果的说明: 代码可能有点长,但是其中很多函数在之前已经出现过了,大部分函数只作了很小部分的改动:比如, 主函数中我们使用了一个 从运行结果来看,似乎 robots.txt 中的约束比我们之前解读的要强很多 —— 它不允许我们爬取资源,但我们仍然可以 “知不可为而为之” (设置 有时候我们可能因为不可抗力 (比如断网、死机等) 而不得不中止我们的爬取,设想这样一个情况:我们要爬取1000个文件,然而我们在下载到第501个文件时出现了上述的意外,当一切恢复正常后,我们想要继续从第 501 个文件处开始下载,怎么办? 一种极简的方法是:设立一个变量以记录我们当前已经成功下载的文件个数,并且每当一个文件下载成功时,将此变量写入一个文件 (比如 .txt),重启下载时读取该变量值,从它的下一个序号开始下载即可。 以上方法适用于我们的 DOI 列表项顺序不变的情况,事实上对于我们这个小项目来说已经满足要求了;但还有一种普适性更强的方法,那就是按键值对存储已经下载的资源标识,这里我们可以选用 {文献url: pdf_url} 作为资源标识,借用 Python3 标准库中的 json 模块来实现缓存数据加载和存储。 由于我们的缓存在内存中以字典形式存储,与此同时需要访问外存,进行缓存读写,我们可以将缓存功能封装在一个类中,并通过特殊成员函数 下面构建一个 Cache 类 (cache.py): 要使用此类,我们得修改 sci_hub_crawler(),下面仅展示更改的代码 (download.py): 正如函数开头注释所说,虽然cache是个Cache类的对象,但是由于类中的特殊函数(上文已经提及),实现了运算符重载,我们可以像使用字典一样使用它。 下面我们可以简单测试一下新增的缓存功能 (cache.py): 运行结果与说明: 初次运行,文件下载符合预期,并且在代码的同级目录下生成了 cache.txt 文件,内容如下: 上述内容加载到内存后是一个 Python 字典,键是 sci-hub 上输入 doi 后搜索所得页面的 url,值是相应 pdf 资源的 url 第二次运行,由于文献已经下载过了,除了第三个异常的链接外,其余文献将不再执行下载,而是给出"已经下载"的提示: 虽然还存在很多可以改进的地方,但现在是时候打住了,现在的版本已经符合要求了 (再优化就写不完了)。 至此,我们已经翻过了最高的山,剩余工作很简单 —— 抓取 DOI 就完事了,它与 3.2 节的不同之处: 网站不同,意味着元素选择会有所改变 只有文本抓取,没有二进制数据流的下载过程 是不是非常简单?我们要做的是抓取 html 文本中的 DOI,然后用列表存起来,还可以把它写入磁盘。这些操作我们在 3.2 节已经见过了。但是 —— 你怎么获得搜索结果中所有的文献链接呢 (搜索结果往往分布在多个分页里) ?其实我们在 2.1 节已经讨论过了这个问题,并且给出了解决方案,笔者在此画个示意图,展现一下 Web of Science 搜索结果的层级结构: 该示意图其实展示了一个比较通用的爬虫模型 —— 链接爬虫 (Link Crawler),它可以通过一个源链接,跟踪页面中的其他链接,使得爬虫表现得更像普通用户 [1],降低封禁风险。(一页页地浏览,并且按顺序访问文献,的确符合 “普通用户” 的行为) 笔者这里不再对链接爬虫作过多展开,原因有二:其一,笔者爬取 Web of Science 的过程中没被封禁过,而且也没找到该网站的 robots.txt,再加上这是串行爬取,访问时也就省去了普通用户的控件操作时间,对网站服务器的负载贡献不大;其二,这种方法相对较慢,为了获取 doi,它还需要额外花时间爬取链接。 事实上,针对这个网站有更高效的方法。 2020-12-11 晴 这是笔者点进一篇文献的网站,观察 url 链接发现的一种方法,此方法不需要用到分页,可以直接获取每个文献链接。我们看一下第 1 页第 1 篇文献的 url: 试着解析一下这个 url: 如此一来,我们得到了如下三个子问题,并且都很好解决: url 转换,给定一个搜索结果源链接 (必须是文献链接而不是搜索页或分页链接),其格式为 抓取搜索结果总数:21,322,注意搜索结果总数中的逗号,要把它转变为整数。不过,笔者偷下懒,把这项任务交给用户,人眼"识别"结果总数,并传到接口的相应参数中。 抓取文献网页中的 DOI:标签特征在 2.2 节已经解析过,只需采用 3.2.2 节的一种抓取方法即可 (笔者使用XPath选择器: 下面是笔者 抓取一定数目搜索结果的 DOI 并构成列表 的 Python3 实现 (doi_crawler.py): 运行结果: 对代码与结果的说明: 虽然有很多函数,但函数结构非常简单,而且对函数参数和功能作了注释,就不过多解读了。读者可以从主函数片段中得知主要的函数接口 (有 3 个,分别是 doi_crawler() 、save_doi_list() 、 read_dois_from_disk() ) XPath选择器的构造参考了一位博主的博客 [2],链接:XPath 选取具有特定文本值的节点 笔者仅选取了搜索结果前 10 项,测试了多次,耗时在 9 - 15s 范围内,也就是大约 1 秒 1 个 doi,不知道读者能否接受这个速度呢 (反正笔者感觉还可以) 爬虫受网络因素影响,偶尔会爬取失败,重试几次就好了 (sci_hub_crawler() 也一样) 与 3.2 节的 sci_hub_crawler() 不同,本节给用户留了两个小任务:① 提供一个文献的链接;② 设定最大 doi 个数 上面的方法虽然通过找规律的方式省去了爬取文献链接的过程,提高了效率,但并不能保证在进行大量爬取时会免受封禁。好在 Web of Science 网站提供了一个便利的功能 —— 导出选择的选项。它通过一个按钮控件的点击事件触发,如下图所示: 笔者以 Unity3D 为主题,试着导出第 1 至 500 项,以 html 的格式保存文献数据。然后我们打开此文件 (savedrecs.html,即 save document records),找寻 DOI 所在位置, 如下所示: 根据笔者观察,几乎每一个 下面给出 根据导出的 html 记录,抓取其中的 DOI 并返回列表 的 Python3 实现 (advanced_doi_crawler.py): 运行结果: 对代码与结果的说明: xpath() 返回的是一个列表,只不过之前的实践我们经常只要其中第一项,这里存在多个匹配,所以我们全都要 doi_crawler() 中的文件读取用的是 read(),而不是用 readlines()。前者一次读取完;后者读取所有行,保存在一个列表中 [3] 从结果看,500 条记录中仅仅爬取了 206 个 DOI,这是正常的 —— Unity3D 的很多成果都是以会议形式发表的; 与 3.3.1 的方法相比,两种方法的时间开销完全不是一个级别的 —— 此方法 1s 之内即可完成;如果换作之前的方法,耗时将近 10 min 我们分别用 3.2 节 和 3.3 节 制作了 sci_hub_crawler() 和 doi_crawler() (笔者用 3.3.2 节的),并作了简单的测试,至少现在没看到问题。那么把它们组合起来会不会引入新问题呢?实践一下就知道了! 笔者先在此列出待调用函数的函数原型,作为流程梳理的参考: 注:尽管笔者可能在某一步骤使用了多种方法来实现,但此处笔者只选择一种方案,其余方案就不再展示实现方法了,但思路都是一致的。具体来说,笔者抓取标签内容使用的是 XPath 选择器;"获取 DOI 列表"采用的是 3.3.2 节的方法。 本节实际上是本爬虫的使用说明书。 打开 Web of Science,搜索感兴趣的内容,得到一个搜索结果列表 点击 “导出为其他文件格式” 按钮,记录条数自选,记录内容为作者、标题、来源出版物,文件格式选择HTML,然后点击"导出",记录该 html 文件的 绝对路径 调用 doi_crawler(filepath),返回一个 doi 列表,将之命名为 调用 sci_hub_crawler(doi_list, get_link=get_link_xpath, nolimit=True, cache=Cache(cache_dir)),如果不需要缓存,可以不传参至 睡上一觉,等待结果 上面流程已经说的很清楚了,组装起来不是什么难事,但需要注意:组装的这些函数的参数列表需要合理地合并。 下面就是笔者组装的情况 (sci_spider.py): 我们运行 sci_spider.py 中的主函数代码,结束后对结果进行分析。 之前也看到了,一共有 206 个 DOI,这个下载量比较大了,检查无误后,我们现在尝试运行一下: 我们可以轻松地从运行结果中提取以下数据: 206 个 doi 中下载成功的有 94 个,占比 45.6% 总共用时为 1664 秒,即 27 分 44 秒,成功下载单个文件的用时为 17.7 秒 另外,我们看看磁盘上的变化: cache.txt pdf 文件目录 笔者发现了七种不同类型的错误信息输出 (包括空标题),上述出错的 url 笔者都一一点开过,对于更详细的错误信息,笔者已经在上面作了注释。下面重点关注两个比较容易纠正且比较普遍的错误: 错误类型二:标题抓取为空 错误类型四:HTTP协议头重复 下面和笔者一起逐个解决~ 点开文献网址,页数有点多,加载片刻后如下图: 代码做以下调整: download.py 笔者假定字符数小于 5 时就采用 doi 命名。 (标题至少也得 5 个字符吧) 点进去一看,有些 onclick 内容中的链接自带HTTP协议头: 为此我们需要在代码中添加一层判断,首先看看有无HTTP协议头,如果没有才添加,修改的代码如下 (download.py): 运行结果: 从运行结果可见,上述问题都已经修复,而且没有带来额外的问题 (至少看起来是这样)。 下面我们删去 cache.txt 和 下载的 pdf (只是测试用的,不要舍不得),再度运行 sci_spider.py,休息半个小时后看看结果: 现在再看看数据,芜湖,起飞 ~ : 206 个 doi 中下载成功的有 150 个,占比 72.8% 总共用时为 2847 秒,即 47 分 27 秒,成功下载单个文件的用时为 18.98 秒 笔者再此基础上再运行了一次程序,用以测试缓存功能是否能正常运行,结果符合我们的预期: 至此项目结束。 笔者这次就分享这么多了,一共用了 6 天时间,一边学,一边写博客,一边码代码,花的时间比较长了。文章的长度远远超出我的预期,很多东西也就是顺着思路写的,没怎么整理,笔者想尽可能地还原这个从零到一的过程,不知各位读者觉得笔者是否做到了呢? 笔者写的这个爬虫十分简陋,涉及的爬虫知识也比较浅,爬虫中对于一些问题的处理也很粗糙,但至少还算能正常工作,可以满足一定程度的需求。毕竟,笔者接触爬虫也就是最近几个星期,实践过程中也从各个渠道学到了很多相关的知识,于个人而言已经很满足了。 其实在项目执行初期,笔者还有几个更大的想法,比如,并行下载、将缓存数据存至数据库 (redis) 、可视化下载进度、做个窗体程序等。但限于时间和篇幅,笔者在此都没有实现。另外,笔者发现,很多一开始的想法 (在 STEP1 和 STEP2 中提到的),可能到后面都用不上,其中原因的大多是当初调研时考虑不周全。但是,有谁能保证做一个从没做过的项目时能够预先进行完美设计呢?完美设计与否,最终还是要靠实践来检验和打磨,代码从简单到复杂,再又回到另一个境界的简单。 笔者起初打死都想不到,终极接口 笔者是一个无语言论者 (虽然用 C++ 和 C# 比较多),但通过这次实践,笔者真切感受到了 Python3 的优雅与强大 —— 它将我们从繁杂的语言细节中解放出来,让我们能集中精力处理去思考问题本身的解决方案。当然,也不能一味地依赖语言带来的强大功能,对于很多底层原理与细节,如有时间也应该去好好琢磨一下。 好了,这段爬虫之旅到此就要画上句号了。笔者做这个项目的初衷就是为了品尝用技术解决具体问题的喜悦,现在确实很满足。然而,凡事都有个主次,笔者还有很多优先级更高的学业任务需要完成,所以可能会有一段时间不碰爬虫,很高兴能分享我的实践过程,也真心希望这些文字能给您带来帮助~ 笔者已经把本次实践的代码上传到 GitHub 上了,仅供学习用。如果各位只是想要使用的话,可以在 GitHub 上找到更好的爬虫。笔者这个用到的知识很少,功能也很简单,比较 low。 点此访问笔者的 GitHub 资源 笔者把主要的参考文献放在这里 (有些在文献中给出了链接),有需要的可以自行查阅。 [1] [德] Katharine Jarmul, 等.用Python写网络爬虫(第二版)[M].李斌, 译.北京:人民邮电出版社, 2018, pp. 1-78 [2] 知否知否呀.XPath 选取具有特定文本值的节点[EB/OL].https://blog.csdn.net/lengchun10/article/details/41044119, 2014-11-12. [3] 假装自己是小白.Python中read()、readline()和readlines()三者间的区别和用法[EB/OL].https://www.cnblogs.com/yun1108/p/8967334.html, 2018-04-28. [4] dcpeng.手把手教你如何在Pycharm中加载和使用虚拟环境[EB/OL].https://www.cnblogs.com/dcpeng/p/12257331.html, 2020-02-03. [5] PilgrimHui.conda环境管理[EB/OL].https://www.cnblogs.com/liaohuiqiang/p/9380417.html, 2018-07-28. [6] 奔跑中的兔子.爬虫之robots.txt[EB/OL].https://www.cnblogs.com/benpao1314/p/11352276.html, 2019-08-14. 欢迎读者朋友留言。 如有错误请务必批评指正,笔者在此给大佬们抱拳了~ 比对发现,它并不能区分DOI和其余同级内容。另外,在其所属的 ,这意味着我们可能需要分层筛选,但我们也可以简单粗暴直接匹配到 DOI,方法和细节稍后提及。
2.3 探索 sci-hub 上 pdf 资源的打开方式
2.3.1 梳理基本流程
http(s)://sci-hub.do
http(s)://sci-hub.do/10.1016/j.apergo.2020.103286,仅仅这一个DOI我们便能断言:资源链接的格式为 http(s)://sci-hub.do/{DOI}2.3.2 查看 robots.txt
/robots.txt 即可):User-agent: Twitterbot
Disallow:
User-agent: *
Allow: /lang/
Allow: /alexandra
Allow: /$
Disallow: /
该网页允许用 Twitterbot 作为用户代理爬取该网站上的任何东西 (更正,经笔者测试,如果用 Twitterbot 作为用户代理抓取网页,那么似乎会重定向,让你抓取其他网页的内容,所以不要用 Twitterbot ) ;第二部分:对所有用户代理都有效,但只允许了部分网站的爬取,那个 /$ 按照解释应该为允许任何以 (更正,似乎也不太对,只要不是 sci-hub 主页,即便没有以 / 结尾的 url/ 结尾也可以抓取) 。以上解释和实际的解析有些出入,笔者拿学习爬虫时做的 robots.txt 解析代码试了一下,发现 Twitterbot 的爬取不受任何限制, 其余用户代理除了主页不能爬取外,其余都能爬。不过,谁来 sci-hub 是为了爬取主页呀? 所以说,基本没有限制,我们可以"横着走"。
2.3.3 提取pdf资源的元素特征
(薛定谔的网络连接)
<div id="buttons">
<ul>
<li><a href="#"
onclick="location.href='//sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true'">⇣ savea>li>
ul>
div>
标签中的 onclick 属性内容,将 location.href 单引号中的内容拧出来,很容易发现:如果在前面加个 http(s):,那么就构成了绝对 url,直接把加了 http(s): 的上述内容 cv 到域名搜索框中,看看能否弹出下载页面 —— 实践告诉我们,输入后直接链接到了 pdf 资源,并自动开始了下载!(来自未来:这里笔者当时并没有考虑 HTTP协议头可能重复的问题)STEP3 开始写代码,就从"下载"入手吧
'http(s)://sci-hub.do' + '/' + DOI }对应的 html 中抓取的。思路有了,我们如果能实现一个文件的下载,那么批量下载无非就是加了个循环 (暂不涉及多线程)。但在此之前,为了符合"从零开始",我还是从搭建环境开始简单地演示一遍吧。3.1 conda虚拟环境搭建、加载和使用
Path 变量中是否包括如下路径:
3.1.1 创建虚拟环境

conda create -n <虚拟环境名> python=<版本号> 创建环境 (笔者用的Python的版本号为3.6)。比如下图中,笔者创建了名为 Python36_WebCrawler 的虚拟环境,过程中等待片刻后需要按个确认按钮: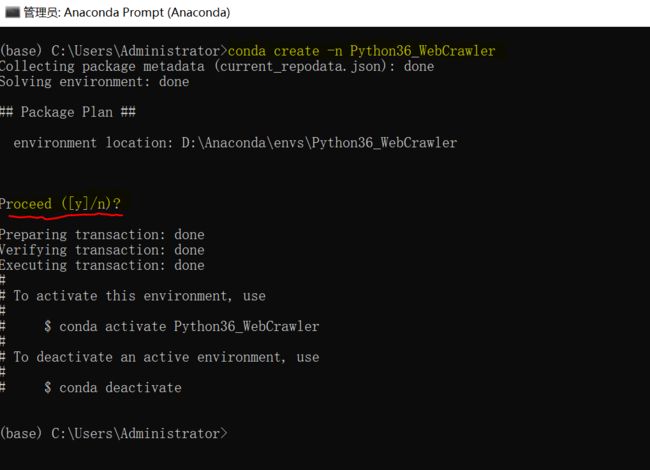
3.1.2 配置下载包的镜像源
https,否则有可能出现问题;另外,你的键入顺序就是搜索包的路径顺序,所以可以预先调研一波 —— 你所需要的包大多数在哪个目录下,那么就把该目录放在最前面)conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/win-64/
conda config --set show_channel_urls yes
/win-64。C:\Users\Administrator 下找到一个 .condarc,用记事本打开可以查看我们的设置:
3.1.3 给虚拟环境安装所需模块
requests 模块。
conda activate <你的虚拟环境名> 激活环境,光标跳转到 (Python36_WebCrawler) C:\Users\Administrator>conda install requests,找到下载源和相应版本后 (可能还附带该模块的依赖项),出现确认事件 Proceed ([y]/n)?,回车默认 yes,画面如下:
requests 模块安装完毕,我们键入 conda deactivate 退出 Python36_WebCrawler 环境。3.1.4 加载虚拟环境到我们的 IDE —— PyCharm
3.2 下载一个pdf文献的代码实现
3.2.1 用 requests 根据 DOI 获取文献对应网页的文本
import requests
def download(doi, user_agent="sheng", proxies=None, num_retries=2, start_url='sci-hub.do'):
headers = {
'User-Agent': user_agent}
url = 'https://{}/{}'.format(start_url, doi)
print('Downloading: ', url)
try:
resp = requests.get(url, headers=headers, proxies=proxies, verify=False)
html = resp.text
if resp.status_code >= 400:
print('Download error: ', resp.text)
html = None
if num_retries and 500 <= resp.status_code < 600:
return download(url, user_agent, proxies, num_retries-1)
except requests.exceptions.RequestException as e:
print('Download error', e)
return None
return html
# 简单的测试
if __name__ == '__main__':
doi = '10.1016/j.apergo.2020.103286'
print(download(doi))
print('Done.')
Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286 # 拼接好的 DOI 文献链接
D:\...\connectionpool.py:852: InsecureRequestWarning: ... # 一个警告,可以忽略,这与我们设置vertify=False有关
# 我们要的超文本
...
Done.
def download(doi, user_agent="sheng", proxies=None, num_retries=2, start_url='sci-hub.do'):
Twitterbot 就行None5xx 时执行重试,像 4xx 之类的就没必要重试了sci-hub.do (其他能用的也行).pdf 文件链接。requests.get(...),必须传入 url,其余都是可选的;为了让我们的爬虫请求网页时能更加可靠 (更像个人,而不是机器),我们传入额外参数 user-agent 和 proxies,前者构成请求时发送给浏览器的头信息 headers,后者设置代理支持,默认设置为 None。requests.get() 参数列表中的 verify=False 不能少,否则很有可能出现 SSL: CERTIFICATE_VERIFY_FAILED 的错误:Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286
Download error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:748)
Done.
3.2.2 提取 html 中的 pdf 资源链接 (3种方式)
<div id="buttons">
<ul>
<li><a href="#" onclick="location.href='//sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true'">⇣ savea>li>
ul>
div>
href="#" 和后者的 href = #,其中有两处不同:① = 前后是否有空格; ② # 是否有引号。关于 2,这是因为 href="#" 有特殊意义。正则表达式 (Regular Expression)
import re
def get_links(pattern, html):
regex = re.compile(pattern, re.IGNORECASE)
return regex.findall(html)
if __name__ == '__main__':
from download import download
dois = ['10.1016/j.apergo.2020.103286', # VR
'10.1016/j.jallcom.2020.156728', # SOFC
'10.3964/j.issn.1000-0593(2020)05-1356-06'] # 飞行器
# 笔者又臭又长的正则表达式
pattern = '''\s*.*?\s*
Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286
D:\Anaconda\...\connectionpool.py:852: InsecureRequestWarning:...
Downloading: https://sci-hub.do/10.1016/j.jallcom.2020.156728
D:\Anaconda\...\connectionpool.py:852: InsecureRequestWarning:...
Downloading: https://sci-hub.do/10.3964/j.issn.1000-0593(2020)05-1356-06
D:\Anaconda\...\connectionpool.py:852: InsecureRequestWarning:...
# 我们获取的 pdf 链接结果
['//sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true']
['//sci-hub.do/downloads/2020-11-23/ac/tsvinkinberg2021.pdf?download=true']
[]
def compile() 将一个正则表达式转变为 pattern 对象, def findall(pattern, string, flags=0): 进行非重叠匹配,返回模式中小括号 () 里的内容组成的列表,如果有多个小括号,则以元组 (tuple) 形式返回所有结果组成的列表;在结果列表中会包含空结果。下面是 标准模块 re.py 中的源码:def compile(pattern, flags=0):
"Compile a regular expression pattern, returning a pattern object."
return _compile(pattern, flags)
def findall(pattern, string, flags=0):
"""Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result."""
return _compile(pattern, flags).findall(string)
\s*.*?\s*
DOI 组成了一个列表,从运行结果可见,飞行器那篇文献匹配为空,笔者特意手动打开链接,发现不能正常访问,这说明我们得到的 pdf 资源列表中可能存在不可用的项,需要筛选那些为空的项 (在后续方法中会考虑这点);另外,能访问的链接也未必能正常下载,需要额外考虑这些情况。
Beautiful Soup
conda install beautifulsoup4
conda install html5libfrom bs4 import BeautifulSoup
import re
def get_link_using_bs4(html, parser='html5lib'):
# parse the HTML
try:
soup = BeautifulSoup(html, parser)
except:
print('parser not available, now use the default parser "html.parser"...')
parser = 'html.parser'
soup = BeautifulSoup(html, parser)
soup.prettify()
div = soup.find('div', attrs={
'id': 'buttons'})
if div:
a = div.find('a', attrs={
'href': '#'})
if a:
a = a.attrs['onclick']
return re.findall(r"location.href\s*=\s*'(.*?)'", a)[0]
return None
if __name__ == '__main__':
from download import download
dois = ['10.1016/j.apergo.2020.103286', # VR
'10.1016/j.jallcom.2020.156728', # SOFC
'10.3964/j.issn.1000-0593(2020)05-1356-06'] # 飞行器
links = []
for doi in dois:
html = download(doi)
# print(html)
link = get_link_using_bs4(html)
if link:
links.append(link)
for link in links:
print(link)
Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286
Downloading: https://sci-hub.do/10.1016/j.jallcom.2020.156728
Downloading: https://sci-hub.do/10.3964/j.issn.1000-0593(2020)05-1356-06
//sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true
//sci-hub.do/downloads/2020-11-23/ac/tsvinkinberg2021.pdf?download=true
soup.prettify() → \rightarrow → 修复 html 文本存在的问题,规范格式soup.find() → \rightarrow → 根据所给标签属性定位元素位置,下面是定义 (element.py): def find(self, name=None, attrs={
}, recursive=True, text=None,
**kwargs):
"""Return only the first child of this Tag matching the given
criteria."""
r = None
l = self.find_all(name, attrs, recursive, text, 1, **kwargs)
if l:
r = l[0]
return r
re.findall(pattern, string) → \rightarrow → 其中 string 是前面获得的 onclick 属性的内容,内容很规整,此时采用正则表达式处理更方便 (来自未来:其实是笔者不太熟悉 BeautifulSoup…)html5lib,但不代表不需要 (除非你只需要用 html.parser)None,初步筛选了用不了的链接Lxml ⋆ \star ⋆
和 标签,这些都不是标准 XML 的要求,因此对于 Lxml 来说,插入它们是不必要的。[1]
选择器描述
XPath选择器
CSS选择器
选择所有链接
‘//a’
‘a’
选择类名为"main"的 div 元素
‘//div[@class=“main”]’
‘div.main’
选择ID为"list"的 ul 元素
‘//ul[@id=“list”]’
‘ul#list’
从所有段落中选择文本
‘//p/text()’
None
选择所有类名中包含’test’的 div 元素
‘//div[contains(@class, ‘test’)]’
None
选择所有包含链接或列表的 div 元素
‘//div[a|ul]’
‘div a, div ul’
选择 href 属性中包含 google.com 的链接
‘//a[contains(@href, “google.com”)]’
None
*a > spana spana[title=Home]$('选择器表达式');对于XPath选择器,其在浏览器中的选择器使用格式为 $x('选择器表达式')在浏览器控制台中使用选择器
$('div#buttons a') 或者 $('div#buttons > ul > li > a'),发现正确选择了我们的目标标签 :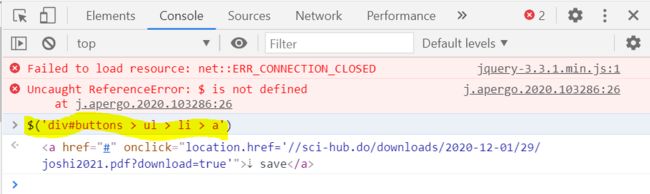
onclick 属性内容,只需输入$x('//div[@id="buttons"]/ul/li/a')[0].attributes[1].textContent:
在代码中使用选择器
conda install cssselect 、conda install lxmlfrom lxml.html import fromstring
def get_link_cssselect(html):
try:
tree = fromstring(html)
a = tree.cssselect('div#buttons > ul > li > a')[0] # 区别
onclick = a.get('onclick')
return onclick
except Exception as e:
print('error occurred: ', e)
return None
def get_link_xpath(html):
try:
tree = fromstring(html)
a = tree.xpath('//div[@id="buttons"]/ul/li/a')[0] # 区别
onclick = a.get('onclick')
return onclick
except Exception as e:
print('error occurred: ', e)
return None
def test_selector(selector):
from download import download
dois = ['10.1016/j.apergo.2020.103286', # VR
'10.1016/j.jallcom.2020.156728', # SOFC
'10.3964/j.issn.1000-0593(2020)05-1356-06'] # 飞行器
links = []
for doi in dois:
html = download(doi)
# print(html)
link = selector(html)
if link:
links.append(link)
for link in links:
print(link)
print('Done')
if __name__ == '__main__':
print('test_cssselect(): ')
test_selector(get_link_cssselect)
print('test_xpath(): ')
test_selector(get_link_xpath)
test_cssselect():
Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286
Downloading: https://sci-hub.do/10.1016/j.jallcom.2020.156728
Downloading: https://sci-hub.do/10.3964/j.issn.1000-0593(2020)05-1356-06
error occurred: Document is empty
location.href='//sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true'
location.href='//sci-hub.do/downloads/2020-11-23/ac/tsvinkinberg2021.pdf?download=true'
Done
test_xpath():
Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286
Downloading: https://sci-hub.do/10.1016/j.jallcom.2020.156728
Downloading: https://sci-hub.do/10.3964/j.issn.1000-0593(2020)05-1356-06
error occurred: list index out of range
location.href='//sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true'
location.href='//sci-hub.do/downloads/2020-11-23/ac/tsvinkinberg2021.pdf?download=true'
Done
tree.cssselect() 以及 tree.xpath() 调用的那一行fromstring(...) 用于统一 html 格式,并返回一个 document 或 element 对象cssselect() 和 xpath() 均返回一个匹配列表,鉴于 sci-hub 目标元素所在层级中只存在一个匹配,所以我们取列表中的 0 位置元素return re.findall(r"location.href\s*=\s*'(.*?)'", onclick)[0],读者可以自行补上 (需要导入 re 模块)
3.2.3 根据获得的 pdf 链接执行下载
get() 方法请求资源,最后将获得的内容以二进制流的操作写入文件即可。import requests
def download_pdf(url, user_agent="sheng", proxies=None, num_retries=2):
headers = {
'User-Agent': user_agent}
url = 'https:{}'.format(url) # 改动1
print('Downloading: ', url)
try:
resp = requests.get(url, headers=headers, proxies=proxies, verify=False)
if resp.status_code >= 400:
print('Download error: ', resp.status_code)
if num_retries and 500 <= resp.status_code < 600:
return download(url, user_agent, proxies, num_retries-1)
# ok, let's write it to file
with open('file.pdf', 'wb') as fp: # 改动2,注意 'wb' 而不是 'w'
fp.write(resp.content)
except requests.exceptions.RequestException as e:
print('Download error', e)
# 简单的测试
if __name__ == '__main__':
doi = '10.1016/j.apergo.2020.103286'
html = download(doi) # 获取文献资源网页的 html 文本
from scraping_using_lxml import get_link_xpath
url = get_link_xpath(html) # 提取下载链接
download_pdf(url) # 执行下载
print('Done.')

对代码的说明:
'wb',即二进制流写入的方式打开的文件file.pdf,如果执行批量下载,我们肯定得找一个能概括此文献的文本作为其名称,以方便我们后续查阅,容易想到文献标题是一个不错的名称候选,因此我们在下载之前,还需要抓取文献的标题 (或其他能唯一标识文献的文本),3.2.4 节会介绍改进方法3.2.4 看看哪些地方仍需改进
磁盘文件合法命名
/,而文件名称不能含有 \ / ? * < > | : " (共9个字符),所以不能直接拿来作为文件名称。我们需要作一些转换使得以标题作为文件名合法,且限制长度在操作系统要求的最大值之内 (WIn10 是 260字节,但经笔者测试实际最大命名长度低于此值。保险起见,我们默认设置长度为 128 字节)。代码非常简单:import re
def get_valid_filename(filename, name_len=128):
# return re.sub(r'[/\\|*<>?":]', '_', filename)[:name_len] # '\n' 来自未来:这些转义符号会算作合法,但会出错
return re.sub(r'[^0-9A-Za-z\-,._;]', '_', filename)[:name_len] # 这个可以
if __name__ == '__main__':
title = r'''Implementing Virtual Reality technology for safety training in the precast/ prestressed concrete industry. Applied Ergonomics, 90, 103286.'''
print(get_valid_filename(title))
print(get_valid_filename(title, 40))
Implementing Virtual Reality technology for safety training in the precast_ prestressed concrete industry. Applied Ergonomics, 90, 103286.
Implementing Virtual Reality technology
/ 被替换成了下划线 _,其余合法字符没变;另外,第二行输出被限制了长度。
获得文件所需的名称 —— 文献标题
$x('//div[@id="citation"]/i/text()')[0],然后笔者写好代码套用该选择器时,发现某些文献标题并没有 标签,所以需要加判断 (比如零长度等等)scraping_using_lxml.py,之前我们只返回了一个 onclick 中的下载链接,我们现在要额外返回一个标题名称,使用字典是一个不错的选择:from lxml.html import fromstring
import re
def get_link_cssselect(html):
try:
tree = fromstring(html)
a = tree.cssselect('div#buttons > ul > li > a')[0]
onclick = a.get('onclick')
title = tree.cssselect('div#menu > div#citation > i') # 1
if len(title) == 0: # 2
title = tree.cssselect('div#menu > div#citation')
title = title[0].text # 3
onclick = re.findall(r"location.href\s*=\s*'(.*?)'", onclick)[0]
return {
'title': title, 'onclick': onclick} # 4
except Exception as e:
print('error occurred: ', e)
return None
def get_link_xpath(html):
try:
tree = fromstring(html)
a = tree.xpath('//div[@id="butdtons"]/ul/li/a')[0]
onclick = a.get('onclick')
onclick = re.findall(r"location.href\s*=\s*'(.*?)'", onclick)[0]
title = tree.xpath('//div[@id="citation"]/i/text()') # 1
if len(title) == 0: # 2
title = tree.xpath('//div[@id="citation"]/text()')
return {
'title': title[0], 'onclick': onclick} # 3
except Exception as e:
print('error occurred: ', e)
return None
标签,因此需要加个判断,即当匹配列表为空时,匹配其父级内容作为标题# Beautiful Soup (scraping_using_bs4.py)
def get_link_using_bs4(html, parser='html5lib'):
try:
...
except:
...
# 修改的部分
try:
div = soup.find('div', attrs={
'id': 'buttons'})
if div:
a = div.find('a', attrs={
'href': '#'})
if a:
a = a.attrs['onclick']
onclick = re.findall(r"location.href\s*=\s*'(.*?)'", a)[0]
div = soup.find('div', attrs={
'id': 'citation'})
title = div.find('i')
if title:
title = title.get_text()
else:
title = div.get_text()
return {
'title': title, 'onclick': onclick}
except Exception as e:
print('error occured: ', e)
return None
# ---------------------------------------------------------------------------
# regular expression (scraping_using_regex.py)
def get_links(pattern, html):
...
def get_link_using_regex(html):
pattern_onclick = '''\s*.*?\s*
robots.txt 解析以及下载时间间隔设置
robots.txt 吗?它是我们进行爬虫前的一个参考,为了降低爬虫被封禁的风险,我们需要遵守其中的约束,可以在 网站域名 + /robots.txt 查看文件要求,我们在 2.3.2 节已经初步分析过了,只要我们的用户代理不是 Twitterbot 并且不以它为子串,那么就没有限制。尽管如此,我们还是可以设置一个下载的间隔时间,并且在发送请求前检查请求是否符合 robots.txt 的规定,这样我们的爬虫便可以适应更多的变化。robots.txt 验证,如果验证通过我们再执行下载,并设置下载时间间隔。我们正好借此机会调整一下之前的代码设计,尽可能减少功能之间的耦合 (download.py):import requests
from urllib.robotparser import RobotFileParser
import time
from urllib.parse import urlparse
from filename import get_valid_filename
def doi_parser(doi, start_url, useSSL=True):
"""Parse doi to url"""
HTTP = 'https' if useSSL else 'http'
url = HTTP + '://{}/{}'.format(start_url, doi)
return url
def get_robot_parser(robot_url):
"""解析robots.txt"""
rp = RobotFileParser()
rp.set_url(robot_url)
rp.read()
return rp
"""延时函数"""
def wait(url, delay=3, domains={
}):
"""wait until the interval between two
downloads of the same domain reaches time delay"""
domain = urlparse(url).netloc # get the domain
last_accessed = domains.get(domain) # the time last accessed
if delay > 0 and last_accessed is not None:
sleep_secs = delay - (time.time() - last_accessed)
if sleep_secs > 0:
time.sleep(sleep_secs)
domains[domain] = time.time()
def download(url, headers, proxies=None, num_retries=2):
print('Downloading: ', url)
try:
resp = requests.get(url, headers=headers, proxies=proxies, verify=False)
html = resp.text
if resp.status_code >= 400:
print('Download error: ', resp.text)
html = None
if num_retries and 500 <= resp.status_code < 600:
return download(url, headers, proxies, num_retries-1)
except requests.exceptions.RequestException as e:
print('Download error', e)
return None
return html
def download_pdf(result, headers, proxies=None, num_retries=2):
url = result['onclick']
url = 'https:{}'.format(url)
print('Downloading: ', url)
try:
resp = requests.get(url, headers=headers, proxies=proxies, verify=False)
if resp.status_code >= 400:
print('Download error: ', resp.status_code)
if num_retries and 500 <= resp.status_code < 600:
return download(result, headers, proxies, num_retries-1)
filename = get_valid_filename(result['title']) + '.pdf'
print(filename)
# ok, let's write it to file
with open(filename, 'wb') as fp:
fp.write(resp.content)
except requests.exceptions.RequestException as e:
print('Download error', e)
return False
return True
def sci_hub_crawler(doi_list, robot_url=None, user_agent='sheng', proxies=None,
num_retries=2, delay=3, start_url='sci-hub.do', useSSL=True, get_link=None, nolimit=False):
"""
给定文献doi列表,爬取对应文献的 pdf 文件
:param doi_list: doi列表
:param robot_url: robots.txt在sci-bub上的url
:param user_agent: 用户代理,不要设为 'Twitterbot'
:param proxies: 代理
:param num_retries: 下载重试次数
:param delay: 下载间隔时间
:param start_url: sci-hub 主页域名
:param useSSL: 是否开启 SSL,开启后HTTP协议名称为 'https'
:param get_link: 抓取下载链接的函数对象,调用方式 get_link(html) -> html -- 请求的网页文本
所使用的函数在 scraping_using_%s.py % (bs4, lxml, regex) 内
:param nolimit: 是否遵循 robots.txt 的约束,如果为True则不受其限制
:return:
"""
headers = {
'User-Agent': user_agent}
HTTP = 'https' if useSSL else 'http'
if not get_link:
print('Crawl failed, no get_link method.')
return None
if not robot_url:
robot_url = HTTP + '://{}/robots.txt'.format(start_url)
try:
rp = get_robot_parser(robot_url)
except Exception as e:
rp = None
print('get_robot_parser() error: ', e)
domains={
} # save the timestamp of accessed domains
download_succ_cnt: int = 0 # the number of pdfs that're successfully downloaded
for doi in doi_list:
url = doi_parser(doi, start_url, useSSL)
if rp and rp.can_fetch(user_agent, url) or nolimit:
wait(url, delay, domains)
html = download(url, headers, proxies, num_retries)
result = get_link(html)
if result and download_pdf(result, headers, proxies, num_retries):
download_succ_cnt += 1
else:
print('Blocked by robots.txt: ', url)
print('%d of total %d pdf success' % (download_succ_cnt, len(doi_list)))
if __name__ == '__main__':
from scraping_using_lxml import get_link_xpath, get_link_cssselect
from scraping_using_bs4 import get_link_using_bs4
from scraping_using_regex import get_link_using_regex
from random import choice
dois = ['10.1016/j.apergo.2020.103286', # VR
'10.1016/j.jallcom.2020.156728', # SOFC
'10.3964/j.issn.1000-0593(2020)05-1356-06'] # 飞行器
get_links_methods = [get_link_xpath, get_link_cssselect, get_link_using_bs4, get_link_using_regex]
get_link = choice(get_links_methods)
print('use %s as get_link_method.' % get_link.__name__)
print('obey the limits in robots.txt: ')
sci_hub_crawler(dois, get_link=get_link, user_agent='sheng')
print('no any limit: ')
sci_hub_crawler(dois, get_link=get_link, user_agent='sheng', nolimit=True)
print('Done.')
use get_link_xpath as get_link_method.
obey the limits in robots.txt:
Blocked by robots.txt: https://sci-hub.do/10.1016/j.apergo.2020.103286
Blocked by robots.txt: https://sci-hub.do/10.1016/j.jallcom.2020.156728
Blocked by robots.txt: https://sci-hub.do/10.3964/j.issn.1000-0593(2020)05-1356-06
0 of total 3 pdf success
no any limit:
Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286
Downloading: https://sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true
Implementing Virtual Reality technology for safety training in the precast_ prestressed concrete industry. Applied Ergonomics, 9.pdf
Downloading: https://sci-hub.do/10.1016/j.jallcom.2020.156728
Downloading: https://sci-hub.do/downloads/2020-11-23/ac/tsvinkinberg2021.pdf?download=true
Tsvinkinberg, V. A., Tolkacheva, A. S., Filonova, E. A., Gyrdasova, O. I., Pikalov, S. M., Vorotnikov, V. A., … Pikalova, E. Y. .pdf
Downloading: https://sci-hub.do/10.3964/j.issn.1000-0593(2020)05-1356-06
error occurred: Document is empty
2 of total 3 pdf success
Done.
download() 和 download_pdf() 不再传入 doi,而是传入对应的 url。另外,新增了 doi_parser() 转换函数,这样就实现了解耦,能让 download() 具有通用性;新增的 get_robot_parser() 以及 can_fetch() 函数实现了 robots.txt 的解析,并遵循其中的约束; wait() 函数设置了下载间隔时间sci_hub_crawler() 集成了"根据给定的 DOI 列表批量(串行)爬取对应的 pdf 文件"的功能,其参数列表的说明在函数开头标注了。如此一来,当我们爬取到 doi 列表后,只需要调用 sci_hub_crawler() 并睡上一觉就行了get_links_methods 列表存储了所有抓取方法,然后使用 random.choice() (伪)随机选取了其中一个,传给了 sci_hub_crawler() 的 get_link 参数,这其实就是多态性的一种体现 —— 同一种调用(get_link(html)),不一样的方法。这类似于 C# 中的委托 (delegate) 或是 C/C++ 的函数指针。但要求 get_link_methods 中的所有函数参数列表一致,从实用性来看,要保证非默认参数的个数和顺序相同。nolimit=True)。只不过为了降低可能的封禁隐患,我们可以让下载间隔大一些(比如 5 - 10s,这样按照两分钟一个的速率一夜也能爬个200+文件,这够多了)。不过也别高估了这个 sci_hub_crawler(),它就是个串行爬虫,想让服务器崩溃可没那么容易,所以我们还是可以放心爬 (大不了就是几天的封禁嘛)添加一个简单的缓存类 Cache
__getitem__() 和 __setitem__() 使得类对象的操作行为类似于字典对象。import json
import os
class Cache:
def __init__(self, cache_dir):
self.cache_dir = cache_dir # 缓存文件的路径
self.cache = self.read_cache() # 加载缓存数据,是个字典
def __getitem__(self, url): # 例如,对于类对象cache,执行 cache[url] 将调用此方法
if self.cache.get(url):
return self.cache[url]
else:
return None
def __setitem__(self, key, value): # key -> url value -> pdf_url 执行 cache[url] = pdf_url 将调用此方法
"""将{url: pdf_url} 追加到字典中,并写入外存"""
filename = self.cache_dir
self.cache[key] = value
if os.path.exists(filename):
with open(filename, 'r') as fp:
if os.path.getsize(filename):
cache = json.load(fp)
else:
cache = {
}
cache.update({
key: value})
with open(filename, 'w') as fp:
json.dump(cache, fp, indent=0) # 加换行符
def read_cache(self):
"""加载json数据成为Python字典对象,至少也是个空字典"""
try:
filename = self.cache_dir
if os.path.exists(filename):
if os.path.getsize(filename):
with open(filename, 'r', encoding='utf-8') as fp:
return json.load(fp)
else:
return {
}
else:
with open(filename, 'w', encoding='utf-8'):
return {
}
except Exception as e:
print('read_cache() error: ', e)
return {
}
def sci_hub_crawler(doi_list, robot_url=None, user_agent='sheng', proxies=None,num_retries=2,
delay=3, start_url='sci-hub.do', useSSL=True, get_link=None, nolimit=False, cache=None):
"""
...
:param cache: 应传入一个缓存类对象,在此代码块中我们应把它当作字典使用
...
"""
...
try:
...
for doi in doi_list:
...
if cache and cache[url]: # 如果缓存中存在对应 url,那么跳过后续下载步骤
print('already downloaded: ', cache[url])
download_succ_cnt += 1
continue
if rp and rp.can_fetch(user_agent, url) or nolimit:
...
if result and download_pdf(result, headers, proxies, num_retries):
if cache:
cache[url] = 'https:{}'.format(result['onclick']) # cache
...
if __name__ == '__main__':
from download import sci_hub_crawler
from scraping_using_lxml import get_link_xpath
cache_dir = './cache.txt'
dois = ['10.1016/j.apergo.2020.103286', # VR
'10.1016/j.jallcom.2020.156728', # SOFC
'10.3964/j.issn.1000-0593(2020)05-1356-06'] # 飞行器
sci_hub_crawler(dois, get_link=get_link_xpath, user_agent='sheng', nolimit=True, cache=Cache(cache_dir))
print('Done.')
{
"https://sci-hub.do/10.1016/j.apergo.2020.103286": "https://sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true",
"https://sci-hub.do/10.1016/j.jallcom.2020.156728": "https://sci-hub.do/downloads/2020-11-23/ac/tsvinkinberg2021.pdf?download=true"
}
already downloaded: https://sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true
already downloaded: https://sci-hub.do/downloads/2020-11-23/ac/tsvinkinberg2021.pdf?download=true
Downloading: https://sci-hub.do/10.3964/j.issn.1000-0593(2020)05-1356-06
error occurred: Document is empty
2 of total 3 pdf success
Done.
3.3 回到 Web of Science,提取搜索页的 DOI 列表
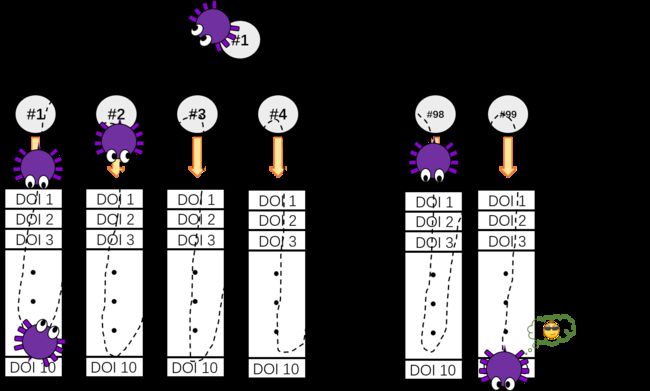
3.3.1 方法一:修改 doc 属性值快速构建 url,然后从中爬取 doi
http://apps.webofknowledge.com/full_record.do?product=UA&search_mode=
GeneralSearch&qid=30&SID=8FZeNUIigweW9fYyFJn&page=1&doc=1
http://apps.webofknowledge.com/ → \rightarrow → Web of Science 主页链接xxx.do → \rightarrow → 是个网页后台程序,刚点搜索弹出的页面便是 Search.do、切换分页时为 Summary.do,打开具体某一文献时为 full_record.do?attr1=value1&attr2=value2&... → \rightarrow → 问号后面接一个或多个用 & 分隔开来的变量,并设定一定值,从而实现动态链接,也就是说对于不同的属性以及属性值,会生成不同的网页。那我们来看看上面那个链接跟了些啥参数吧:
product。这个不用管,所有页面都一样search_mode。 看名字就是知道,指搜索模式,这个也不用管qid、SID。不知道啥意思,但不可少,而且同一个搜索结果下所有文献网站的 qid 和 SID 都一样,所以我们保持原样即可page。分页号码,对应的便是不同分页,可能有用。(但事实上这种分页与结果列表本身没有关系,只是刻意限定了每页的结果数目而已,所以很可能也不用管)doc。文献搜索序号,与分页号无关,当 page 和 doc 共存时 doc “说得算”,你会发现即使没有分页号也能正常打开目标网页,说明分页号page不重要,重要的是文献搜索序列号doc!!!
http://apps.webofknowledge.com/full_record.do?attr1=value1&attr2=...&attrn=valuen&doc=num, 要获取搜索列表中第 i i i 篇文献网页,将 url 末尾参数 doc 改变,使得 &doc=i 即可,此时链接变为:http://apps.webofknowledge.com/full_record.do?attr1=value1&attr2=...&attrn=valuen&doc=i'//span[text()="DOI:"]/following::*[1]')[0].text())<p class="FR_field">
<span class="FR_label">DOI:span>
<value>10.1016/j.electacta.2020.137142value>
p>
from download import download
import re
from lxml.html import fromstring
def url_changer(source_url):
"""获取文献网站url的模式"""
url = re.findall(r'''(.*)&doc''', source_url)[0]
doc = '&doc='
return url + doc
def get_doi(html):
"""根据获取到的html获得其中的doi并返回"""
try:
tree = fromstring(html)
doi = tree.xpath('//span[text()="DOI:"]/following::*[1]')[0].text
return doi
except Exception as e:
print('get_doi() error: ', e)
return None
def doi_crawler(pattern_url, headers=None, number=500):
""" 获得搜索结果中第 [1, number] 的 doi
pass the following parameter
:param pattern_url: 搜索结果内任意一篇文献的url,不是分页或者搜索结果页的!
:param number: doi获取数目,不要超过页面最大结果数
"""
if headers is None:
headers = {
'User-Agent': 'sheng'}
base_url = url_changer(pattern_url)
dois = []
for i in range(1, number + 1):
url = base_url + str(i)
html = download(url, headers)
doi = get_doi(html)
if doi:
dois.append(doi)
return dois
def save_doi_list(dois, filename):
"""将doi列表项以[filename].txt保存到当前文件夹中,"""
filepath = filename[:128] + '.txt'
try:
with open(filepath, 'w') as fp:
for doi in dois:
fp.writelines(doi + '\n')
except Exception as e:
print('save error: ', e)
def read_dois_from_disk(filename):
"""从磁盘文件[filename].txt中
按行读取doi,返回一个doi列表"""
dois = []
try:
filepath = filename + '.txt'
with open(filepath, 'r') as fp:
lines = fp.readlines()
for line in lines:
dois.append(line.strip('\n'))
return dois
except Exception as e:
print('read error: ', e)
return None
if __name__ == '__main__':
import time
source_url = 'http://apps.webofknowledge.com/full_record.do?product=UA&' \
'search_mode=GeneralSearch&qid=2&SID=6F9FiowVadibIcYJShe&page=1&doc=2'
start = time.time()
dois = doi_crawler(source_url, number=10)
save_doi_list(dois, 'dois')
print('time spent: %ds' % (time.time()-start))
print('now read the dois from disk: ')
doi_list = read_dois_from_disk('dois')
for doi in doi_list:
print(doi)
Downloading: http://apps.webofknowledge.com/full_record.do?...&doc=1
...
Downloading: http://apps.webofknowledge.com/full_record.do?...&doc=10
time spent: 9s
now read the dois from disk:
10.1016/j.apcatb.2020.119553
...
10.1016/j.ceramint.2020.08.241
3.3.2 方法二:结合 Web of Science 导出功能的"零封禁几率"方法
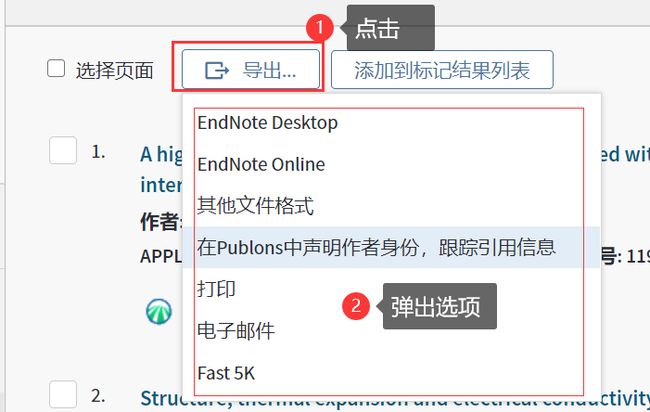

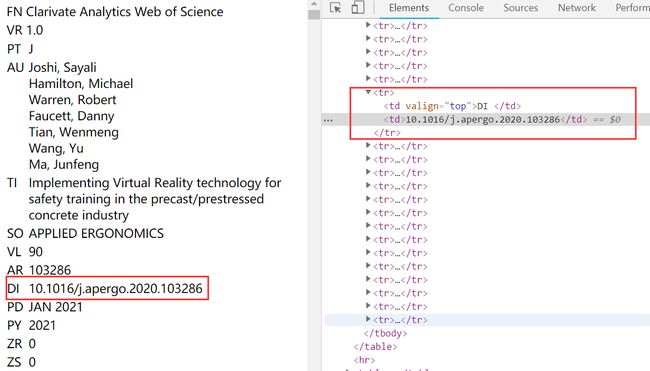
标签的属性 valign 值是一致的,那么我们就只能根据文本 “DI” 来定位并选择其下一个兄弟元素的方式来获取目标 DOI 了。因此,笔者采用 XPath 选择器,使用的选择字符串与 3.3.1 节类似。
from lxml.html import fromstring
def get_doi(html):
"""根据获取到的html获得其中的doi并返回"""
results = []
try:
tree = fromstring(html)
dois = tree.xpath('//td[text()="DI "]/following::*[1]')
for doi in dois:
results.append(doi.text)
return results
except Exception as e:
print('get_doi() error: ', e)
return None
def doi_crawler(filepath):
"""html 导出文件的路径"""
try:
with open(filepath, 'r', encoding='utf-8') as fp:
html = fp.read()
doi_list = get_doi(html)
return doi_list
except Exception as e:
print('doi_crawler() error', e)
return None
if __name__ == '__main__':
import time
start = time.time()
filepath = './data.html'
doi_list = doi_crawler(filepath)
print('time spent: %ds' % (time.time() - start))
print('%d doi records in total: ' % len(doi_list))
for doi in doi_list:
print(doi)
print('Done.')
time spent: 0s
206 doi records in total:
10.1016/j.apergo.2020.103286 #1
10.11607/ijp.6835 #2
...
10.1016/j.proeng.2017.10.509 #206
Done.
STEP4 组装起来,形成终极接口:sci_spider()
def doi_crawler(filepath):
pass # in advanced_doi_crawler.py
def sci_hub_crawler(doi_list, robot_url=None, user_agent='sheng', proxies=None,num_retries=2,
delay=3, start_url='sci-hub.do', useSSL=True, get_link=None, nolimit=False, cache=None):
pass # in download.py
def get_link_xpath(html):
pass # in scraping_using_lxml.py
4.1 流程梳理 ⋆ \star ⋆
filepath (也可以是相对路径)doi_listcache。另外说明的是,cache_dir 是缓存文件的路径,一般用相对路径即可;其余参数根据需要来调整4.2 组装起来,给它取个名字,就叫 “sci_spider” 好了
from download import sci_hub_crawler
from scraping_using_lxml import get_link_xpath
from cache import Cache
from advanced_doi_crawler import doi_crawler
def sci_spider(savedrec_html_filepath, robot_url=None, user_agent='sheng', proxies=None, num_retries=2,
delay=3, start_url='sci-hub.do', useSSL=True, get_link=get_link_xpath,
nolimit=False, cache=None):
"""
给定一个文献索引导出文件 (来自 Web of Science),(按照DOI)下载文献对应的 pdf文件 (来自 sci-hub)
:param savedrec_html_filepath: 搜索结果的导出文件 (.html),其中含有文献记录 (每一条记录可能有doi,也可能没有)
:param robot_url: robots.txt在sci-bub上的url
:param user_agent: 用户代理,不要设为 'Twitterbot'
:param proxies: 代理
:param num_retries: 下载重试次数
:param delay: 下载间隔时间
:param start_url: sci-hub 主页域名
:param useSSL: 是否开启 SSL,开启后HTTP协议名称为 'https'
:param get_link: 抓取下载链接的函数对象,调用方式 get_link(html) -> html -- 请求的网页文本
所使用的函数在 scraping_using_%s.py % (bs4, lxml, regex) 内,默认用xpath选择器
:param nolimit: do not be limited by robots.txt if True
:param cache: 一个缓存类对象,在此代码块中我们完全把它当作字典使用
"""
print('trying to collect the doi list...')
doi_list = doi_crawler(savedrec_html_filepath) # 得到 doi 列表
if not doi_list:
print('doi list is empty, crawl aborted...')
else:
print('doi_crawler process succeed.')
print('now trying to download the pdf files from sci-hub...')
sci_hub_crawler(doi_list, robot_url, user_agent, proxies, num_retries, delay, start_url,
useSSL, get_link, nolimit, cache)
print('Done.')
if __name__ == '__main__':
filepath = './data.html' # doi所在的原始 html
cache_dir = './cache.txt' # 缓存路径
cache = Cache(cache_dir)
sci_spider(filepath, nolimit=True, cache=cache)
4.3 对第一次运行结果的分析与问题处理 ⋆ \star ⋆
4.3.1 运行结果分析
trying to collect the doi list...
doi_crawler process succeed.
now trying to download the pdf files from sci-hub...
... # 下载过程省略
94 of total 206 pdf success
Done.
time spent: 1664s

我们注意到最后一个 url 对应第 95 行,而第一个文件从第 2 行开始,所以一共有 94 个 pdf 文件成功下载,从数量上看这是没有错的。
惊了,明明成功下载了 94 个,却只有 71 个项目,难道被谁吃了吗?确实,看看第一个文件名称 —— 一个下划线,这暗示着有些文献没抓到标题,标题为空字符,然后这个仅有的空字符被替换成了下划线,从数目看,空标题的情况有 24 个,数量占比不小了,所以我们得对这些情况下的 html 文本再度分析一下。在此之前,我们再仔细看看运行窗口中那些下载失败或标题为空的文件对应的输出信息吧:# 第一种类型的错误:找不到合适的代理 (不管了)
Downloading: https://sci-hub.do/10.11607/ijp.6835
error occurred: list index out of range
...
# 第二种类型的错误:文件标题抓取为空 (重点关注)
Downloading: https://sci-hub.do/10.3390/s20205967
Downloading: https://sci-hub.do/downloads/2020-10-31/dc/[email protected]?download=true
_.pdf
...
# 第三种类型的错误:文献网页内容为空 (不管了)
Downloading: https://sci-hub.do/10.3275/j.cnki.lykxyj.2020.03.013
error occurred: Document is empty
...
# 第四种类型的错误:原链接中已有HTTP协议头 (重点关注)
Downloading: https://sci-hub.do/10.1109/TCIAIG.2017.2755699
Downloading: https:https://twin.sci-hub.do/6601/f481261096492fa7c387e58b490c15c6/llobera2017.pdf?download=true
Download error No connection adapters were found for
'https:https://twin.sci-hub.do/6601/f481261096492fa7c387e58b490c15c6/llobera2017.pdf?download=true'
...
# 第五种类型的错误 :IP被 ACM DL(美国计算机学会 数字图书馆) 官网封禁了,
# 但似乎是因为前面加了个 sci-hub 的缘故,去掉后还是可以正常访问 ACM DL (不管了)
Downloading: https://sci-hub.do/10.1145/3337722.3341860
Download error:
504 Gateway Time-out
4.3.2 问题1:标题抓取为空 —— 用 DOI 作为名字

如你所见,我们的目标区域内容为空,那我们得想想别的办法了?即使不能保证有意义,但最起码得给它个不一样的名字,免得造成文件覆盖而丢失,那我们最容易想到的就是用 DOI 作为名字啦。def download_pdf(result, headers, proxies=None, num_retries=2, doi=None):
···
try:
...
if len(result['title']) < 5: # 处理标题为空的情况
filename = get_valid_filename(doi) + '.pdf'
else:
filename = get_valid_filename(result['title']) + '.pdf'
...
def sci_hub_crawler(doi_list, robot_url=None, user_agent='sheng', proxies=None,num_retries=2,
delay=3, start_url='sci-hub.do', useSSL=True, get_link=None, nolimit=False, cache=None):
...
if result and download_pdf(result, headers, proxies, num_retries, doi):
...
...
4.3.3 问题2:HTTP协议头重复 —— 添加判断去重
<a href="#" onclick="location.href=
'https://twin.sci-hub.do/6601/f481261096492fa7c387e58b490c15c6/llobera2017.pdf?download=true'">
⇣ savea>
def download_pdf(result, headers, proxies=None, num_retries=2, doi=None):
url = result['onclick']
components = urlparse(url)
if len(components.scheme) == 0: # HTTP协议头长度为 0,则添加协议头
url = 'https:{}'.format(url)
print('Downloading: ', url)
...
# 小测试
if __name__ == '__main__':
from scraping_using_lxml import get_link_xpath
dois = ['10.1109/TCIAIG.2017.2755699', # HTTP协议头重复
'10.3390/s20205967', # 标题为空
'10.1016/j.apergo.2020.103286' # 没毛病
]
get_link = get_link_xpath
sci_hub_crawler(dois, get_link = get_link, user_agent='sheng', nolimit=True)
print('Done.')
Downloading: https://sci-hub.do/10.1109/TCIAIG.2017.2755699
Downloading: https://twin.sci-hub.do/6601/f481261096492fa7c387e58b490c15c6/llobera2017.pdf?download=true
A_tool_to_design_interactive_characters_based_on_embodied_cognition.
_IEEE_Transactions_on_Computational_Intelligence_and_AI_in_G.pdf
Downloading: https://sci-hub.do/10.3390/s20205967
Downloading: https://sci-hub.do/downloads/2020-10-31/dc/[email protected]?download=true
10.3390_s20205967.pdf
Downloading: https://sci-hub.do/10.1016/j.apergo.2020.103286
Downloading: https://sci-hub.do/downloads/2020-12-01/29/joshi2021.pdf?download=true
Implementing_Virtual_Reality_technology_for_safety_training_in_the_precast__
prestressed_concrete_industry._Applied_Ergonomics,_9.pdf
3 of total 3 pdf success
Done.
4.3.4 最后的调试
trying to collect the doi list...
doi_crawler process succeed.
now trying to download the pdf files from sci-hub...
...
150 of total 206 pdf success
Done.
time spent: 2847s
trying to collect the doi list...
doi_crawler process succeed.
now trying to download the pdf files from sci-hub...
...
already downloaded: https:https://twin.sci-hub.do/
6634/7e804814554806b27952fd2974ae4ba1/radionova2017.pdf?download=true
150 of total 206 pdf success
Done.
time spent: 1367s
爬虫感想
sci_spider() 竟然有如此多的参数,看起来相当复杂;但是,它是笔者实践过程中一步步搭建与优化得到的,就算某个代码细节忘记了,也有办法通过重新回顾此代码而迅速拾起,这或许就是实践与没有实践过的区别。资源 (见GitHub)
References
你可能感兴趣的:(Python3,网络爬虫,开放性实验,网络爬虫,Python3,sci-hub,文献爬取,手把手系列)