入门级中文分词项目 【关键词计算,文本摘要生成】,还不来收藏学习!

目录
-
-
- 前言
- 项目演示
- 中文分词
- 近义词合并
- 关键词计算
-
- 1.tf-idf算法
- 2. 计算步骤
- 3.代码实现
- 摘要生成
-
- textrank算法
- 计算步骤
- 代码实现
- 尾言
-
前言
大家好,我是Ericam_
希望本篇分享可以给大家带来帮助~
愿我们都在代码世界的道路上渐行渐远。
当然啦,也希望一键三连,拜托啦拜托啦。
(你们会心疼gie gie嘛(●ˇ∀ˇ●))
好久没写文章了,真是懒癌上身,借着今天的闲暇来分享一下经验吧。最近完成了一个小项目,采用中文分词,然后完成同义词合并、计算TF-IDF值来提取关键词、最后通过textrank算法生成文本摘要!个人觉得挺适合入门学习的,如果你想锻炼自己的code水平,那就快来看看吧~
项目演示
中文分词
中文分词这里直接使用jieba库进行分词。
import jieba
'''
读取要进行中文分词的文本
'''
def readData(name):
dataPath = "{}".format(name)
with open(dataPath,'r',encoding='utf8')as f:
comments = f.readlines()
return comments
'''
向jieba词库添加用户自定义词典
'''
def loadDict(name):
userfile = "./settings/{}".format(name)
jieba.load_userdict(userfile)
'''
对文本进行中文分词
'''
def wordSeg(name,rname,dictname):
txts = readData(name)
loadDict(dictname)
wsrPath = "./result/{}".format(rname)
results = ""
for txt in txts:
seg_list = jieba.cut(txt, cut_all=False)
r = "/ ".join(seg_list)
results += "{}\n".format(r)
with open(wsrPath,'w+',encoding='utf8') as f:
f.write(results)
return results
近义词合并
由于在上一步中我们已经完成了中文分词,所以只需要来比较每个词汇是否存在于同义词字典中,如果存在则都替换成同一值即可。
'''
合并同义词
'''
def mergeSyn(name,rname,dictname):
comments = readData(name)
loadDict(dictname)
synname = "synonym_list.txt"
d = makeSynDict(synname)
stop_file = "stopwordlist.txt"
stop_words = get_stop_dict(stop_file)
wsrPath = "./result/{}".format(rname)
results = ""
for comment in comments:
seg_list = jieba.cut(comment,cut_all=False)
for seg in seg_list:
if seg in d.keys() and seg not in stop_words:
results += d[seg]
else:
results += seg
with open(wsrPath,'w+',encoding='utf8') as f:
f.write(results)
return results
关键词计算
在本次项目中,我们采用tf-idf算法进行关键词计算,提取文本中的关键词。
1.tf-idf算法
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
详细介绍:TF-IDF算法介绍及实现
2. 计算步骤
- (1) 整合功能:文本分词并完成同义词替换,提取出总词频
- (2) 计算词汇IDF值(通过词汇自身所在的语料库)
- (3) 根据IDF值进行排序,挑选关键词
- (3) 计算关键词汇的TF-IDF值
3.代码实现
'''
为了更加贴合关键词含义,按照以下词性来挑选关键词
'''
flag_list = ['n','nr','ns','nt','nz','vn'] #名词,人名,地名,机构团体,其他专名,名动词
'''
(1)整合功能
params:
- filename : 要提取文本的路径
'''
def txtInit(filename):
savename = "txtresult.txt"
dictname = "add_word_list.txt"
wordSeg(filename,savename,dictname) #文本分词
mergeSyn("./result/{}".format(savename),savename,dictname) #同义词合并
txtseg_list = wordSegByPart("./result/{}".format(savename),dictname) #按照词性再次文本分词
stop_file = "stopwordlist.txt"
stop_words = get_stop_dict(stop_file) #加载停用词
word_frequency = defaultdict(int)
for ts in txtseg_list:
for wordseg in ts:
if wordseg.flag in flag_list and wordseg.word not in stop_words and wordseg.word != '':
word_frequency[wordseg.word] += 1
return word_frequency
'''
(2)计算词汇IDF值
params:
- word_frequency : 总词频
- filedir : 语料库路径
'''
def getIDF(word_frequency,filedir):
doc = glob.glob(filedir+"/*")
doc_num = len(doc)
word_doc = defaultdict(int)
word_idf = {
}
result = ""
for name in doc:
with open(name,'r',encoding='utf8') as f:
data = f.read()
for word in word_frequency.keys():
if word in data:
word_doc[word] += 1
for word in word_frequency.keys():
word_idf[word] = math.log(doc_num/(word_doc[word]+1))
word_sort = sorted(word_idf.items(),key=lambda x:x[1],reverse=True) #词汇按照IDF值排序(由大到小
#演示
for v in word_sort:
result += "[{} {}]\t".format(v[0],v[1])
#提取关键词(5个
keyWord_idf = {
}
for i in range(5):
keyWord_idf[word_sort[i][0]] = word_idf[word_sort[i][0]]
#演示
result += "\n-----根据IDF值提取关键词-----\n关键词:\n"
for v in keyWord_idf.keys():
result += "{}\n".format(v)
return keyWord_idf,result
'''
(3) 计算关键词的TF-IDF值
'''
def getTFIDF(word_frequency,keyWord_idf):
word_tf = {
}
result = ""
wordsum = sum(word_frequency.values())
for word in keyWord_idf.keys():
word_tf[word] = word_frequency[word] / wordsum
word_tfidf = {
}
for word in word_tf.keys():
word_tfidf[word] = word_tf[word] * keyWord_idf[word]
result += "\n-----关键词TF-IDF值------\n"
for v in word_tfidf.keys():
result += "{} {}\n".format(v,word_tfidf[v])
return result
摘要生成
在本次项目中,我们选择使用textrank算法来生成摘要。
textrank算法
TextRank由Mihalcea与Tarau于EMNLP’04 [1]提出来,其思想非常简单:通过词之间的相邻关系构建网络,然后用PageRank迭代计算每个节点的rank值,排序rank值即可得到关键词。
TextRank生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。考察句子相似度的方法是下面这个公式:
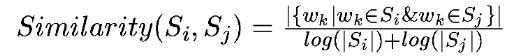
计算步骤
- (1) 文本切割,将文本每句话进行拆分(按照句号)
- (2) 构造相似矩阵
【similarity = a/b a:同属于两个句子的词的数量 , b: 两个句子的词数取对数后求和】 - (3) 构造权值邻接矩阵
【权值的意义是你愿意把自已价值的百分之几传递给箭头指向的那个结点
计算A -> B 的权值的方法是:
先算A 和所有结点相似度的总和(分母)
再算A 和B 的相似度(分子)
两者的比值是A -> B的边的权值
】 - (4) 计算textRank值
- (5) 提取摘要
代码实现
'''
构造相似矩阵(sl:文本切割后返回的list
'''
def makeSimiMatri(sl):
simiMatri = [[0]*len(sl)]*len(sl)
sw_list = [] # 将句子分词后的list
for s in sl:
sentence_word = []
wordseg = jieba.cut(s,cut_all=False)
for word in wordseg:
sentence_word.append(word)
sw_list.append(sentence_word)
for i in range(len(sl)-1):
for j in range(i+1,len(sl)):
swi = sw_list[i]
swj = sw_list[j]
b = math.log(len(swi))+math.log(len(swj))
if b < 1e-12:
b = 0.0
a = 0
for word in swi:
if word in swj:
a += 1
simiMatri[i][j] = simiMatri[j][i] = a/b
return simiMatri
'''
构造权值邻接矩阵
'''
def makeWeightMatri(simiMatri,sl):
weightMatri = [[0]*len(sl)]*len(sl)
for i,m in enumerate(simiMatri):
sumSimi = sum(m)
for j,v in enumerate(m):
weightMatri[i][j] = simiMatri[i][j] / sumSimi
#print(weightMatri)
return weightMatri
'''
计算textRank值
'''
def calTextrank(sl,W):
maxIter = 100 # 设置最大迭代次数
N = len(sl)
WS = np.full(N, 0.15) # TextRank 初始值 list ,1*N 维,初值0.15
for _ in range(maxIter):
last_WS = WS.copy()
for i in range(N):
s = 0
for j in range(N):
if i != j and W[i][j] > 0: #W[i][j]>0 代表存在边(即存在联系
s += W[j][i]*WS[j]
WS[i] = 0.15 + s*0.85
if sum( WS - last_WS ) < 1e-12:
print("textRank值计算完毕")
break
#对textRank值进行归一化处理
WS_SUM = sum(WS)
for i in range(N):
WS[i] /= WS_SUM
return WS
'''
根据textRank值返回摘要
'''
def getSummary(sl,WS):
index = np.argmax(WS)
result = ""
result += "\n-------文章句子textrank值如下:---------\n"
N = len(sl)
for i in range(N):
result += "[{} : {}]\n".format(sl[i],WS[i])
result += "\n------根据textrank生成文章摘要------\n\n"
result += sl[index]
return result
尾言
其实项目主要是对两个算法的实现。【TF-IDF算法 textrank算法】
关于两个算法的介绍网上已经很详细了,大家可以自行去搜索。
本文主要讲了我自己的复现过程,大家可以对照着其他文章来看代码思路。
如果想要获取完整项目,可以私信联系我。
