【大数据开发】Presto——Presto安装部署、核心数据结构、Java集成Presto、自定义UDF、UDAF函数
Presto快速入门点我点我点我!
Presto只支持Java操作,不能使用Scala
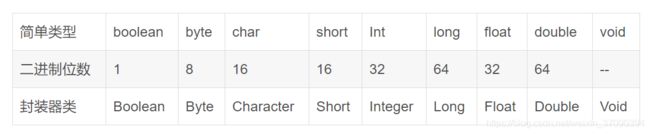
必备知识:一个字节是8位,一个中文汉字占用3个字节的长度,byte类型数据是1个字节(presto需要自己手动计算字节数和存储位置)
Presto目录
- 一、安装部署
- 二、Presto核心数据结构
-
- 2.1 Slice
- 2.2 Block
- 2.3 Page
- 2.4 总结
- 三、Java集成Presto
- 四、Presto编写UDF函数
-
- 4.1 导入依赖
- 4.2 代码
- 五、Presto编写UDAF函数
一、安装部署
# 创建目录
mkdir -p /opt/soft/presto
# 下载presto-server
wget -P /opt/soft/presto http://doc.yihongyeyan.com/qf/project/soft/presto/presto-server-0.236.tar.gz
# 创建软连
ln -s /opt/soft/presto/presto-server-0.236 /opt/soft/presto/presto-server
# 安装目录下创建etc目录
cd /opt/soft/presto/presto-server/ && mkdir etc
# 创建节点数据目录
mkdir -p /data1/presto/data
# 接下来创建配置文件
cd /opt/soft/presto/presto-server/etc/
# config.properties persto server的配置
cat << EOF > config.properties
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
# 单个查询在整个集群上够使用的最大用户内存
query.max-memory=3GB
# 单个查询在每个节点上可以使用的最大用户内存
query.max-memory-per-node=1GB
# 单个查询在每个节点上可以使用的最大用户内存+系统内存(user memory: hash join,agg等,system memory:input/output/exchange buffers等)
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://0.0.0.0:8080
EOF
# node.properties 节点配置
cat << EOF > node.properties
node.environment=production
node.id=node01
node.data-dir=/data1/presto/data
EOF
#jvm.config 配置,注意-DHADOOP_USER_NAME配置,替换为你需要访问hdfs的用户
cat << EOF > jvm.config
-server
-Xmx3G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-DHADOOP_USER_NAME=root
EOF
#log.properties
#default level is INFO. `ERROR`,`WARN`,`DEBUG`
cat << EOF > log.properties
com.facebook.presto=INFO
EOF
# catalog配置,就是各种数据源的配置,我们使用hive,注意替换为你自己的thrift地址
mkdir /opt/soft/presto/presto-server/etc/catalog
cat <<EOF > catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.10.99:9083
hive.parquet.use-column-names=true
hive.allow-rename-column=true
hive.allow-rename-table=true
EOF
# 添加hudi支持
wget -P /opt/soft/presto/presto-server/plugin/hive-hadoop2 http://doc.yihongyeyan.com/qf/project/soft/hudi/hudi-presto-bundle-0.5.2-incubating.jar
# 客户端安装
wget -P /opt/soft/presto/ http://doc.yihongyeyan.com/qf/project/soft/presto/presto-cli-0.236-executable.jar
cd /opt/soft/presto/
mv presto-cli-0.236-executable.jar presto
chmod u+x presto
ln -s /opt/soft/presto/presto /usr/bin/presto
# 至此presto 安装完毕
数据查询
需要先启动Hive的metastore服务,否则会报错hive --service hiveserver2 &

# 启动persto-server, 注意下方命令是在后台启动,日志文件在node.properties中配置的 /data1/presto/data/var/log/ 目录下
/opt/soft/presto/presto-server/bin/launcher start
# presot 连接hive metastore
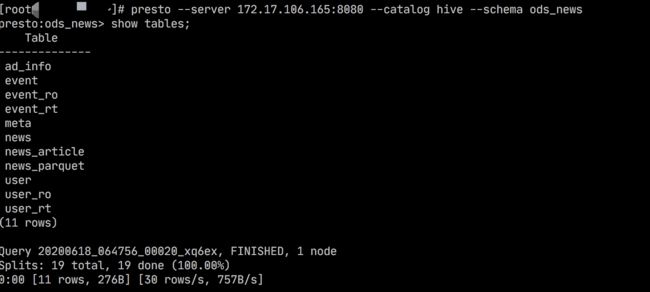
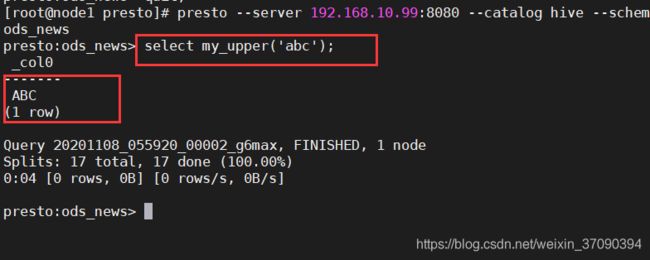
presto --server 192.168.10.99:8080 --catalog hive --schema ods_news
# 执行查询你会看到我们hive中的表
show tables;
-- 查询user表
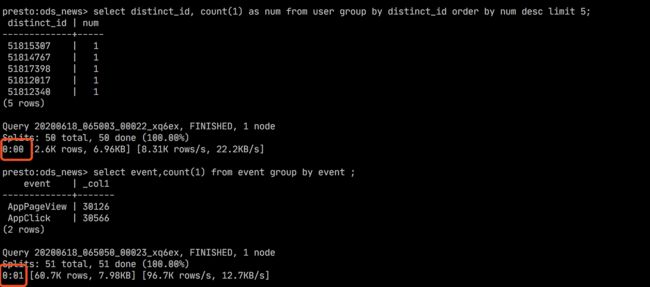
select distinct_id, count(1) as num from user group by distinct_id order by num desc limit 5;
-- 查询event表
select event,count(1) from event group by event ;
-- 你可以关注一下查询时间
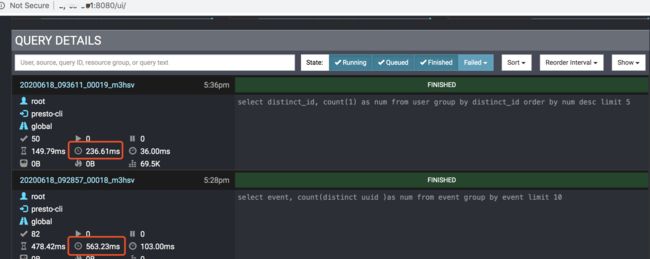
Presto 也给我提供了一个UI界面,可以让我们能够看到查询相关执行和统计信息
可以访问
http://172.17.106.165:8080注意替换为你自己的IP地址从下面第一张图你可以更清晰看到查询的执行时间,同数据量级下,速度相比SparkSQL还是要快一些的,大家可以自己去测试一下。

二、Presto核心数据结构
在 Presto 中,我们需要了解一些非常重要的数据结构,例如,Slice,Block 以及 Page,下面将介绍这些数据结构。

presto采取三层表结构:
- catalog 对应某一类数据源,例如hive的数据,或mysql的数据
- schema 对应mysql中的数据库
- table 对应mysql中的表
2.1 Slice
从用户的角度来看,Slice 是一个对开发人员更友好的虚拟内存,它定义了一组 getter 和 setter 方法,因此我们可以像使用结构化数据一样使用内存:
Slice 常用来表示一个字符串:
// use it as utf8 encoded string
Slice slice = Slices.utf8Slice("hello");
Slice subSlice = SliceUtf8.substring(slice, 1, 2);
我们可以像使用字符串一样使用 Slice,Presto 为什么选择 Slice 而不是 String:
字符串创建代价昂贵(字符串拼接,StringBuilder等)。
Slice 是可变的,而 String 是不可变的,因此当我们需要进行字符串计算时,效率更高。
字符串在内存中编码为 UTF16,而 Slice 使用 UTF8,这样可以提高内存效率。UTF16 最少使用两个字节来表示一个字符,而 UTF8 最少使用一个字节,因此,如果 String 内容主要是 ASCII 字符,则 UTF8 可以节省大量内存。
Slice(在 Presto 中)的另一种用法是表示原始字节(SQL中的 VARBINARY 类型):
// use it as raw bytes
block.getSlice().getBytes()
2.2 Block
由于 Page 由 Block 组成,因此我们首先介绍 Block。Block 可以认为是同一类数据(int,long,Slice等)的数组。每个数据项都有一个 position ,总位置个数代表 Block 中数据的总行数(Block 仅保存这些行中的一列)。
Block 定义了好几套 API,其中一个是 getXXX 方法,让我们以 getInt 为例:
/**
* Gets a little endian int at {@code offset} in the value at {@code position}.
*/
default int getInt(int position, int offset) {
throw new UnsupportedOperationException(getClass().getName());
}
通常,一个 Block 仅支持一种 getXxx 方法,因为一个 Block 中的数据都来自同一列,并且具有相同的类型。
Block 定义的另一个方法是 copyPositions,来代替从 Block 中获取某个值,通过返回一个新的 Block 来从指定的位置列表获取一组值:
/**
* Returns a block containing the specified positions.
* All specified positions must be valid for this block.
*
* The returned block must be a compact representation of the original block.
*/
Block copyPositions(List<Integer> positions);
Presto 还定义了 BlockEncoding,定义了如何对 Block 进行序列化和反序列化:
public interface BlockEncoding {
/**
* Read a block from the specified input. The returned
* block should begin at the specified position.
*/
Block readBlock(SliceInput input);
/**
* Write the specified block to the specified output
*/
void writeBlock(SliceOutput sliceOutput, Block block);
}
我们以最简单的 BlockEncoding:IntArrayBlockEncoding 为例,其 readBlock 如下所示:
int positionCount = block.getPositionCount();
sliceOutput.appendInt(positionCount);
encodeNullsAsBits(sliceOutput, block);
for (int position = 0; position < positionCount; position++) {
if (!block.isNull(position)) {
sliceOutput.writeInt(block.getInt(position, 0));
}
}
2.3 Page
Page 由不同的 Block 组成:
public class Page {
private final Block[] blocks;
private final int positionCount;
...
}
除 Block 外,Page 还有另一个称为 Channel 的概念:每个 Block 都是该 Page 的 Channel,Block 的总数就是 Channel 数。因此,让我们在这里总结一下数据是如何结构化的,当要发送一些行时,Presto 将:
将每一列放入单独的 Block 中。
将这些 Block 放入一个 Page 中。
发送 Page。
Page 是保存数据并在 Presto 物理执行算子之间传输的数据结构:上游算子通过 getOutput() 产生输出:
/**
* Gets an output page from the operator. If no output data is currently
* available, return null.
*/
Page getOutput();
下游算子通过 addInput() 方法获取输入:
/**
* Adds an input page to the operator. This method will only be called if
* {@code needsInput()} returns true.
*/
void addInput(Page page);
就像 Block 一样,Page 也需要序列化和反序列化,序列化发生在工作进程之间传输数据时。 Page 进行序列化时,首先使用相应的 BlockEncoding 对 Block 进行编码。 如果有压缩器,将尝试对编码的块数据进行压缩,如果压缩效果良好(编码率低于0.8),将使用压缩数据,否则使用未压缩的数据。 编码后的块数据将与一些统计信息(压缩前后页面的字节大小)一起放入名为 SerializedPage 的类中。
2.4 总结
我们介绍了 Presto 中三个核心数据结构:Slice,Block 和 Page。简而言之,Slice 是对开发人员更友好的虚拟内存,Block 代表列,Page 代表行组。
三、Java集成Presto
import io.airlift.slice.Slice;
import io.airlift.slice.Slices;
import org.junit.Test;
/**
* Presto用法
*/
public class test {
@Test
public void test1(){
// 创建一个内存区域 10个字节大小
Slice slice = Slices.allocate(20);
// 使用内存区域,添加数据
// 一个字节等于8bit (8个二进制 256),如果超出内存限定,就会数据溢出,字节设置不要超出限定
// 长度,不然你的数据就不准了
slice.setByte(0,100);
// 获取第0个字节的数据
System.out.println(slice.getByte(0));
// 设置一个int类型 int =4个字节
slice.setInt(1,1024*1024*1024*2-1);
// 获取Int数据
System.out.println(slice.getInt(1));
// 接下来存入一个汉字,一般在UTF8下面的汉字都差不多占3个字节
slice.setBytes(5,"张三".getBytes());
// 获取汉字
System.out.println(new String(slice.getBytes(5, 6)));
// 内存复写 数据覆盖,写入相同位置的数据
slice.setBytes(8,Slices.utf8Slice("六"));
System.out.println(new String(slice.getBytes(5, 6)));
slice.setBytes(8,Slices.utf8Slice("七六"),0,3);
System.out.println(new String(slice.getBytes(5, 4)));
// 可以将内存地址合并使用
Slice slice1 = Slices.allocate(10);
// 将之前的空间大小进行内存拼接,并使用,然后形成一个新的数据内存空间
slice.setBytes(5,slice1);
System.out.println(slice1.toStringUtf8());
}
}
四、Presto编写UDF函数
参考资料1
参考资料2
4.1 导入依赖
<properties>
<jdk-version>1.8jdk-version>
<presto.version>0.236presto.version>
<scope.type>providedscope.type>
properties>
<dependencies>
<dependency>
<groupId>io.airliftgroupId>
<artifactId>sliceartifactId>
<version>0.38version>
dependency>
<dependency>
<groupId>com.google.guavagroupId>
<artifactId>guavaartifactId>
<version>26.0-jreversion>
dependency>
<dependency>
<groupId>com.facebook.prestogroupId>
<artifactId>presto-spiartifactId>
<version>${presto.version}version>
<scope>${scope.type}scope>
dependency>
<dependency>
<groupId>com.facebook.prestogroupId>
<artifactId>presto-mainartifactId>
<version>${presto.version}version>
<scope>${scope.type}scope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>RELEASEversion>
<scope>testscope>
dependency>
dependencies>
<repositories>
<repository>
<id>ali-mavenid>
<url>http://maven.aliyun.com/nexus/content/groups/publicurl>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>trueenabled>
<updatePolicy>alwaysupdatePolicy>
<checksumPolicy>failchecksumPolicy>
snapshots>
repository>
repositories>
<pluginRepositories>
<pluginRepository>
<id>ali-mavenid>
<url>http://maven.aliyun.com/nexus/content/groups/publicurl>
pluginRepository>
pluginRepositories>
<build>
<sourceDirectory>src/main/javasourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>2.5.3version>
<configuration>
<finalName>presto-udffinalName>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<source>${jdk-version}source>
<target>${jdk-version}target>
<encoding>UTF-8encoding>
<showWarnings>trueshowWarnings>
configuration>
plugin>
plugins>
build>
4.2 代码
package com.mgs.bigdata.udf;
import com.facebook.presto.common.type.StandardTypes;
import com.facebook.presto.spi.function.Description;
import com.facebook.presto.spi.function.ScalarFunction;
import com.facebook.presto.spi.function.SqlType;
import io.airlift.slice.Slice;
import io.airlift.slice.Slices;
public class MyFunction {
@ScalarFunction("my_upper")
@Description("大小写转换")
@SqlType(StandardTypes.VARCHAR)
public static Slice toUpperCase(@SqlType(StandardTypes.VARCHAR) Slice input) {
return Slices.utf8Slice(input.toStringUtf8().toUpperCase());
}
}
package com.mgs.bigdata.udf;
import com.facebook.presto.spi.Plugin;
import com.google.common.collect.ImmutableSet;
import java.util.Set;
public class UpperCasePlugin implements Plugin {
@Override
public Set<Class<?>> getFunctions() {
return ImmutableSet.<?>>builder()
.add(MyFunction.class)
.build();
}
}
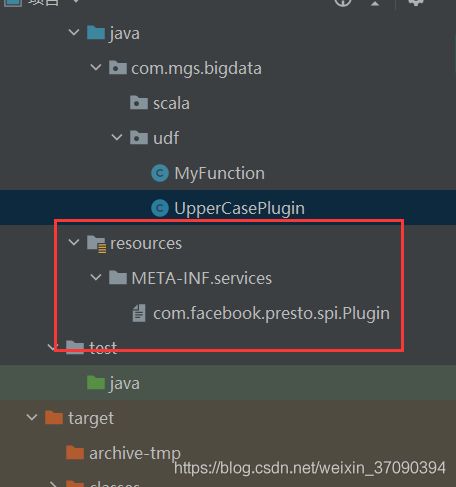
services
在项目自己的META-INF文件夹中建立一个名为services的文件夹,如WAR包,则为{$Context}WebContent META-INFservices。
在该文件夹中创建一个名为org.apache.commons.logging.LogFactory的文件,在该文件中只加入一句话:org.apache.commons.logging.impl.Log4jFactory。
意思很简单,那就是为 org.apache.commons.logging.LogFactory类指定了在当前项目中的实现类:org.apache.commons.logging.impl.Log4jFactory。
这个文件要点一下可以跳转到指定的类
com.mgs.bigdata.udf.UpperCasePlugin
打包,这个插件打包可以将依赖打进去

将含有依赖的包拖到这里,udf文件夹是自己创建的

重启presto
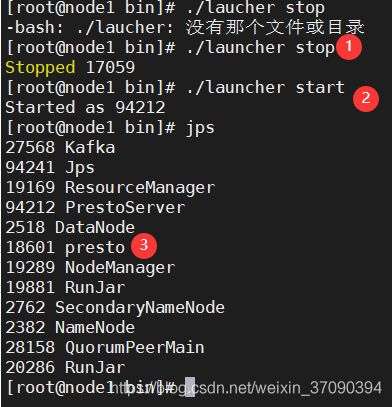
五、Presto编写UDAF函数
参考资料1
参考资料2