任何数据库都离不开日常的备份与恢复,这二者是数据库安全的前提,MongoDB的备份与恢复方法一般而言都采用自带的工具来进行。
在开始讲述备份之前,需要首先了解两个概念,一个是恢复点目标、一个叫恢复时间目标,下面我们分别来看:
- 恢复点目标:
(也叫RPO,recovery point objective)
也就是数据可以恢复到哪个时间点,可以承受多少损失。
- 恢复时间目标:
(也叫RTO,recover time objective),在发生故障的时候,数据库可以承受多长时间宕机。
有了这两个概念,就可以理解不同备份恢复方法可以满足的RPO和RTO是多少了。
来看备份工具:
Mongodump工具
在MongoDB中,mongodump工具通常用来做备份使用。它有如下特点:
1、可以对mongos和mongod进行操作
2、备份的是数据和数据结构,会以bson数据格式存储
3、不会备份索引,只会备份索引的元数据,只有在恢复的时候才会重建索引。
4、备份的过程中,mongodump会批量的将数据加载到内存中,该方法在数据量比较大的时候,会持续占用内存资源,会增加IO负载压力。
5、可以备份整个数据库、整个集合、部分集合内容
该工具的缺点:
1、仅仅适合备份小型的、或者单一数据库的备份
2、数据量大的时候,备份时间较长
关于Mongodump的命令使用方法,大家可以mongodump --help去查看,常用选项如下:
-p,--port:端口
-h,--host:IP地址
-d,--db:数据库
-c,--collection:备份的集合名称
-q,--query:备份数据的条件表达式
-o,--out:备份文件的存放位置
-u,--username:用户名
-p,--password:密码
--authenticationDataBase:认证数据库
具体的使用方法,下面有例子。
Mongorestore工具
数据备份和数据恢复二者是不可分割的,因为数据的备份,本质上还是为了恢复准备的,如果备份的数据不能恢复,那么备份也就失去了意义。
在MongoDB中,Mongorestore这个工具是用来做数据恢复的,数据恢复命令的常用参数如下:
与mongodump重复的部分不再赘述
-p,--port
-h,--host
-d,--db
-c,--collection
--dir:恢复文件存放的位置,如果指定了数据库文件夹或者集合文件,则只恢复当前数据库或者当前集合,如果没有指定,则恢复当前目录下所有备份数据。
--drop:恢复前会删除已有的数据库
-u,--user
-p,--password
--authenticationDatabase
下面来看样例:
数据备份举例
备份所有数据库
mongodump --port=27017 -h 127.0.0.1 -o /data/mongodb_backup -u root -p 123456
2020-11-23T23:40:41.599+0800 writing admin.system.users to
2020-11-23T23:40:41.626+0800 done dumping admin.system.users (3 documents)
2020-11-23T23:40:41.626+0800 writing admin.system.roles to
2020-11-23T23:40:41.651+0800 done dumping admin.system.roles (1 document)
2020-11-23T23:40:41.651+0800 writing admin.system.version to
2020-11-23T23:40:41.680+0800 done dumping admin.system.version (2 documents)
2020-11-23T23:40:41.680+0800 writing test.yeyz to
2020-11-23T23:40:41.680+0800 writing yeyz.test to
2020-11-23T23:40:41.726+0800 done dumping yeyz.test (2 documents)
2020-11-23T23:40:41.727+0800 done dumping test.yeyz (3 documents)
备份yeyz这一个数据库
[root@VM-0-14-centos ~]# mongodump -d yeyz --port=27017 -h 127.0.0.1 -o /data/mongodb_backup -u root -p 123456 --authenticationDatabase admin
2020-11-23T23:41:58.991+0800 writing yeyz.test to
2020-11-23T23:41:59.050+0800 done dumping yeyz.test (2 documents)
备份yeyz数据库中的test集合中的name=ccc的记录
[root@VM-0-14-centos ~]# mongodump -d yeyz -c test -q '{name:{$eq:"ccc"}}' --port=27017 -h 127.0.0.1 -o /data/mongodb_backup -u root -p 123456 --authenticationDatabase admin
2020-11-23T23:43:24.473+0800 writing yeyz.test to
2020-11-23T23:43:24.501+0800 done dumping yeyz.test (1 document)
数据恢复举例
恢复前
> use yeyz
switched to db yeyz
> show tables;
test
> db.test.find()
{ "_id" : ObjectId("5fa7eae2515b814f18f2d474"), "name" : "ccc" }
{ "_id" : ObjectId("5fa7f00e523d80402cdfa326"), "name" : "bbb" }
恢复后
> show tables;
test
test_recover
> db.test_recover.find()
{ "_id" : ObjectId("5fa7eae2515b814f18f2d474"), "name" : "ccc" }
我们成功的将上面的yeyz数据库中的test集合中的name=ccc的记录恢复到了test_recover这个集合当中。
物理备份
物理备份的概念大家应该都理解,常用的方法是复制物理硬盘上的数据库文件。
想要保证复制的物理文件和真实的数据库文件一致,需要保证当前数据库没有写入。如果数据库有写入,则复制的数据是不准确的。所以,物理复制必须在MongoDB实例停机状态或者锁定状态下进行。一般来讲,在MongoDB集群中,我们会使用锁定从库的办法来进行备份。
通常情况下,使用:
db.fsyncLock() 锁定从数据库。
db.fsyncUnlock() 解锁数据库
锁定从节点的数据库之后,在从节点上使用物理文件拷贝的方式进行备份即可。
备份完成即可解锁数据库。
最后,数据备份的时候,如果有写入,那么备份的数据是否会不准确?例如下面这样:
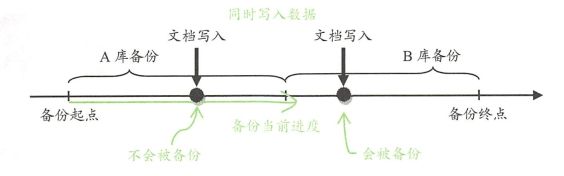
如果我们的备份进度处在中间位置,即:
A库备份完成的时候,B库没有开始备份
此时分别写入A库和B库两个文档,则最终的备份结果中,A库的数据没有新增的数据,B库的数据有新增的数据,就会产生数据的不一致。为了解决这个问题,备份一般都使用锁定数据库或者停止实例的方法来解决。
在MongoDB中,可以在从库上进行锁定或者停止实例的备份操作,不建议在线上环境使用MongoDB单库,因为这种情况,备份恢复将会成为一个瓶颈问题。
以上就是MongoDB的备份与恢复的详细内容,更多关于MongoDB 备份与恢复的资料请关注脚本之家其它相关文章!