Pytorch-线性回归(一)
一.线性回归
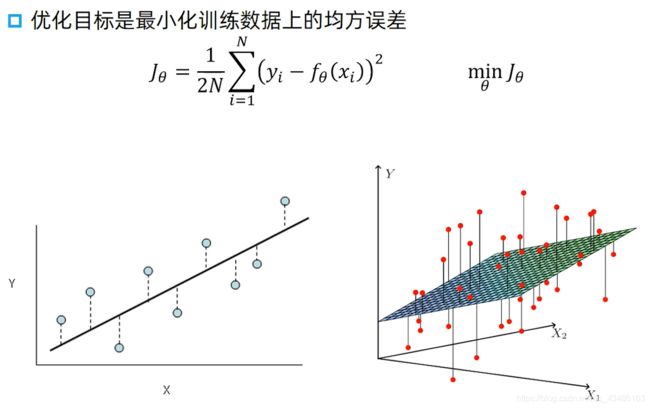
1.数学概念
线性回归是利用数理统计中的回归分析,来确定两种,或两种以上变量关系的一种统计方法。简而言之,对于输入 x x x与输出 y y y有一个映射 f f f, y = f ( x ) y = f(x) y=f(x), f f f的形式为 w x + b wx+b wx+b,其中 w , b w,b w,b为可调参数,训练 w , b w,b w,b
线性模型 y = f w ( x ) = w 0 + ∑ i = 1 n w i x i x = w T x y = f_w(x) = w_0 + \sum_{i = 1}^{n}w_ix_ix = w^Tx y=fw(x)=w0+i=1∑nwixix=wTx
x = ( 1 , x 1 , x 2 ⋅ ⋅ ⋅ ⋅ x n ) x= (1,x_1,x_2 \cdot \cdot \cdot \cdot x_n) x=(1,x1,x2⋅⋅⋅⋅xn)


2 .损失函数 loss function
min w 1 N ∑ i = 1 N L ( y i , f w ( x i ) ) \min_w \frac{1}{N}\sum_{i=1}^N \mathcal{L}(y_i,f_w(x_i)) wminN1i=1∑NL(yi,fw(xi))
M S E : L ( y i , f w ( x i ) ) = 1 2 ( y i − f w ( x i ) ) 2 MSE:\mathcal{L}(y_i,f_w(x_i)) = \frac{1}{2}(y_i - f_w(x_i))^{2} MSE:L(yi,fw(xi))=21(yi−fw(xi))2
3.梯度更新


3.1 批量梯度下降算法Batch Gradient Descent
优化函数
J ( w ) = 1 2 N ∑ i = 1 N ( y i − f w ( x i ) ) 2 m i n w J ( w ) J(w) = \frac{1}{2N} \sum_{i = 1}^N (y_i - f_w(x_i))^2 \quad \underset{w}{min} J(w) J(w)=2N1i=1∑N(yi−fw(xi))2wminJ(w)
根据整个批量数据的梯度更新参数 w n e w = w o l d − η ∂ J ( w ) ∂ w w_{new} = w_{old} - \eta\frac{\partial J(w)} {\partial w} wnew=wold−η∂w∂J(w)
∂ J ( w ) ∂ w = − 1 N ∑ i = 1 N ( ( y i − f w ( x i ) ∂ f w ( x i ) ∂ w ) = − 1 N ∑ i = 1 N ( y i − f w ( x i ) x i \begin{aligned} \frac{\partial J(w)} {\partial w} &= -\frac{1}{N} \sum_{i = 1}^{N}((y_i - f_w(x_i)\frac{\partial f_w(x_i)}{\partial w}) \\ &= -\frac{1}{N} \sum_{i = 1}^{N}(y_i - f_w(x_i) x_i \end{aligned} ∂w∂J(w)=−N1i=1∑N((yi−fw(xi)∂w∂fw(xi))=−N1i=1∑N(yi−fw(xi)xi
w n e w = w o l d + η 1 N ∑ i = 1 N ( y i − f w ( x i ) x i w_{new} = w_{old} +\eta\frac{1}{N} \sum_{i = 1}^{N}(y_i - f_w(x_i) x_i wnew=wold+ηN1i=1∑N(yi−fw(xi)xi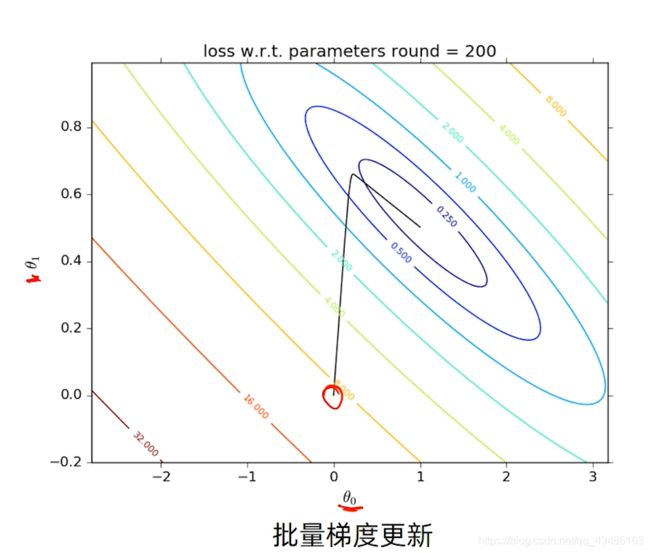
3.2 随机梯度下降Stochastic Gradient Descent
优化函数
J ( i ) ( w ) = 1 2 ( y i − f w ( x i ) ) 2 m i n w 1 N ∑ i J ( i ) ( w ) J^{(i)}(w) = \frac{1}{2}(y_i - f_w(x_i))^2 \quad \underset{w}{min} \frac{1}{N} \sum_iJ^{(i)}(w) J(i)(w)=21(yi−fw(xi))2wminN1i∑J(i)(w)
根据整个批量数据的梯度更新参数 w n e w = w o l d − η ∂ J ( w ) ∂ w w_{new} = w_{old} - \eta\frac{\partial J(w)} {\partial w} wnew=wold−η∂w∂J(w)
∂ J ( i ) ( w ) ∂ w = − ( y i − f w ( x i ) ∂ f w ( x i ) ∂ w ) = − ( y i − f w ( x i ) ) x i \begin{aligned} \frac{\partial J^{(i)}(w)} {\partial w} &= -(y_i - f_w(x_i)\frac{\partial f_w(x_i)}{\partial w}) \\ &= - (y_i - f_w(x_i) )x_i \end{aligned} ∂w∂J(i)(w)=−(yi−fw(xi)∂w∂fw(xi))=−(yi−fw(xi))xi
w n e w = w o l d + η ( y i − f w ( x i ) ) x i w_{new} = w_{old} +\eta(y_i - f_w(x_i)) x_i wnew=wold+η(yi−fw(xi))xi
3.3 小批量梯度下降Mini-Batch Gradient Descent
批量梯度下降和随机梯度下降的结合
1.将整个训练集分成K个小批量(mini-batches)
{ 1 , 2 , 3 , ⋯ , k } \left\{1,2,3,\cdots,k \right\} { 1,2,3,⋯,k}
2.对每一个小批量 k k k,做一个批量下降来降低
J ( k ) ( w ) = 1 2 N k ∑ i = 1 N k ( y i − f w ( x i ) ) 2 J^{(k)}(w) = \frac{1}{2N_k} \sum_{i = 1}^{N_k}(y_i - f_w(x_i))^2 J(k)(w)=2Nk1i=1∑Nk(yi−fw(xi))2
3.对于每一个小批量,更新参数
w n e w = w o l d − η ∂ J ( k ) ( w ) ∂ w w_{new} = w_{old} -\eta \frac{\partial J^{(k)}(w)}{\partial w} wnew=wold−η∂w∂J(k)(w)
未完待续----------------------------------------------------------------------------------------------------------
后期比较优化算法
