pytorch识别minist数据集
import torch
from torchvision import transforms #针对图像做原始处理的工具
from torchvision import datasets
from torch.utils.data import DataLoader #以上三行用于构建DataLoader
import torch.nn.functional as F #使用relu激活函数
import torch.optim as optim #使用优化器,用来简写
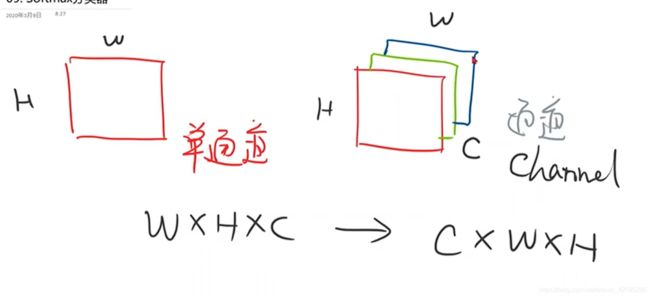
在回归问题和一些机器学习算法中,以及训练神经网络的过程中,通常需要对原始数据进行标准化和归一化
- 目的:通过标准化处理,得到均值为0,标准差为1的服从标准正态分布的数据(改变了正太分布数据的均值和方差(原始数据要是正态分布));归一化则是将数据转换到[0,1]之间
- 标准化计算过程由下式表示: x ′ = x − u σ x'=\frac{x-u}{\sigma} x′=σx−u
- 下面解释一下为什么需要使用这些数据预处理步骤。
在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表征的。比如在预测房价的问题中,影响房价的因素有房子面积、卧室数量等,我们得到的样本数据就是这样一些样本点,这里的、又被称为特征。很显然,这些特征的量纲和数值得量级都是不一样的,在预测房价时,如果直接使用原始的数据值,那么他们对房价的影响程度将是不一样的,而通过标准化处理,可以使得不同的特征具有相同的尺度(Scale)。这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了。 - 简言之,当原始数据不同维度上的特征的尺度(单位)不一致时,需要标准化步骤对数据进行预处理。
https://www.zhihu.com/question/37069477
batch_size = 64
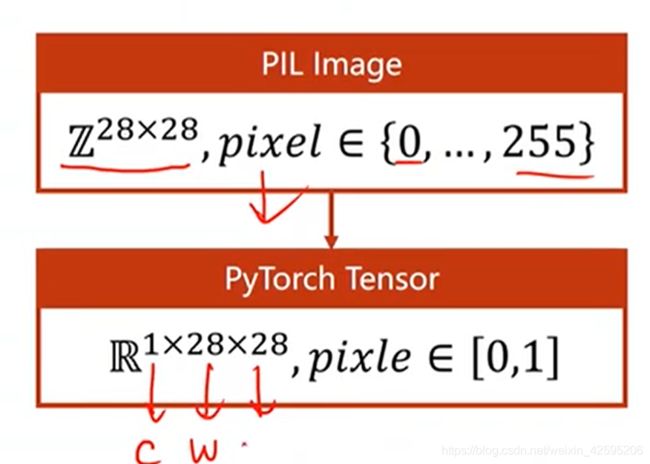
# 由于神经网络更容易训练更小的数据,最好满足正态分布的数据,我们把0-255的图像数据转为0-1的数据
# 在神经网络中,要把图像数据转为张量,使神经网络更高效
transform = transforms.Compose([ #将输入的图片进行“[]”中的一系列的处理
transforms.ToTensor(), #将输入图片进行转成3通道的张量,并将像素值压缩到0-1
transforms.Normalize((0.1307,),(0.3081,)) # 这两个值使均值和方差,将图像数据进行标准化
#(这里使数据形成正态分布)
]
)
train_dataset =datasets.MNIST(root='D:\\software\\conda\\Lib\\site-packages\\torchvision\\datasets\\mnist',
train=True,
download=True,
transform=transform,
) # 这里用本地的MNIST数据集需要改变mnist.py文件,并进行编译,
#(重新打开项目,再重新导入包)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset =datasets.MNIST(root='D:\\software\\conda\\Lib\\site-packages\\torchvision\\datasets\\mnist',
train=False,
download=True,
transform=transform,
)
test_loader = DataLoader(train_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784) # 将每张28*28的图片转为 784的一维的张量,
#-1的意思是自动计算有多少个图片(一维张张量)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 这里用CrossEntropyLoss()函数不用激活输出,因为这个函数中带有激活函数
model = Net()

criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)#由于模型比较复杂,所以用带冲量的优化器
def train(epoch): #因为有模型训练和模型测试,所以对训练和测试进行封装
running_loss = 0
for batch_idx ,data in enumerate(train_loader,0): # 第二个是列表中的元素索引
inputs, target =data # 获取数据和标签
optimizer.zero_grad()
# forward +backward+updata
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 每个batch会更新一次权重和得到一次损失,
#但是没有必要每个batch都要输出一次损失
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f'%(epoch + 1,batch_idx + 1,running_loss/300))
running_loss =0
def test():
correct = 0
total = 0
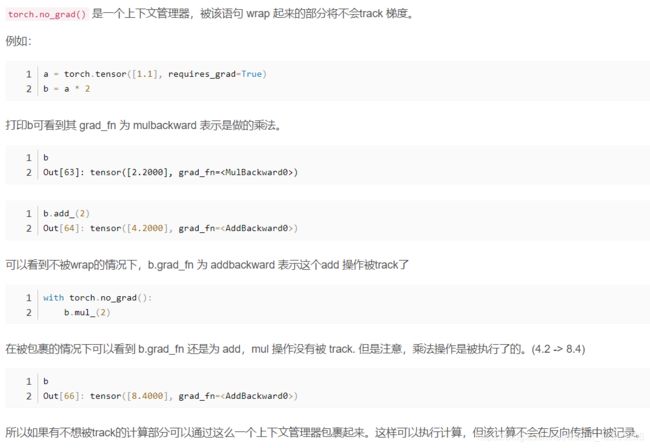
with torch.no_grad(): # 在这里面就不用计算梯度(应该是Tensor不用管)
for data in test_loader: # 将数据从test_loader中加载出来
images,labels = data
outputs = model(images) # 用训练的模型进行预测
_, predicted = torch.max(outputs.data,dim=1) # 因为网络的输出有10个神经元,
# dim=1是沿着行(第一个维度)找最大的,
# 这个最大的坐标就是预测值
total += labels.size(0) #size()就是用来返回labels矩阵(N,1)的尺寸 size(0)就是返回行数
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%'% (100 * correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
https://www.bilibili.com/video/BV1Y7411d7Ys