本文是 WWDC 2018 Session 704 的读后感,其视频及配套 PDF 文稿链接如下:
Core ML 3 Framework。本文会首先回顾 Core ML 的发展历史,其后着重介绍 Core ML 本次的更新和使用场景。
查阅全部 WWDC 2019 专栏内容,点击此处前往小专栏。
Core ML 发展史
Core ML 是苹果在2017年推出的机器学习框架。旨在为 App 开发提供一套完整的机器学习方案,包括模型获取、模型部署、使用模型三个部分。
其中模型获取在 Create ML 章节中已有深入探讨和介绍,感兴趣的朋友可以查阅 WWDC 2018:初探 Create ML。
而模型部署和使用方面,则完全是由 Core ML 负责。Core ML 1.0 的模型可以直接在 Xcode 中导入 App 中,然后自动生成 API 接口。Core ML 2.0 在此基础上,进行了 API 的扩展和改进;对输入量化了权重,对输出增加了定制化精度的功能;模型的神经网络层也可以定制化替换。这一系列的改进使得 Core ML 的灵活性大幅提成、性能更是提高了30%。可以说 Core ML 2.0 做到了更小、更快、定制化的目标。
至此,苹果已经在移动端机器学习领域完成了从0到1的计划。今年 Core ML 3.0 的发展,在笔者看来,则是从1到N的第一步。
Core ML 新功能和使用场景
今年的更新主要有三个:本地模型个性化、神经网络的优化和支持、性能优化和更多种类的数据支持。
本地模型个性化
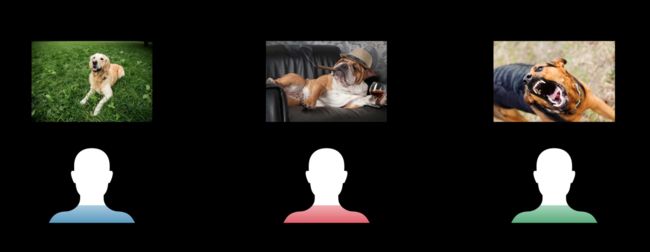
之前的 Core ML 模型,只能处理普遍的、共性的数据。例如,它可以判断一张照片中的动物是不是狗,但无法针对不同的狗主人,判断照片中的狗是否属于当前使用模型的主人。要解决这个问题,有以下几个方案:
针对不同的狗主人训练不同的模型。这样做的问题是扩展性太差:如果有10000个狗主人,那这个识别主人的 App 就要发布10000个版本,每个版本有不同的模型,每个用户要去下载各自的版本。这样做显然不现实。
将照片上传至云端处理。服务器端的模型可以提取相应的特征,然后根据大数据确定狗主人的信息,再将信息返回至移动端。这样做的问题首先是有延时,网络情况会直接影响 App 性能;其次是有隐私泄露的可能,毕竟照片和狗主人的信息会在上传和下载的同时被窃取。
在本地更新模型,适配不同的用户。所有用户一开始拿到的都是同一个模型,之后模型会根据用户输入的图片,自动更新参数,生成新的本地模型。新的模型会根据当前用户的照片,判断该狗是否属于主人。
Core ML 3.0 目前采取的就是方案3。这样做的唯一疑虑就是性能问题:只能快捷得处理简单任务,复杂的就捉襟见肘。这是由于手机硬件性能和优化不足导致的瓶颈。
具体的实现原理是,苹果在原来的 Core ML 模型中加入了更新接口,用于接收新的输入数据,并更新对应的模型参数,这样就可以生成新的本地化模型。就上文的小狗(狗主人)识别模型为例,现在的 Core ML 3.0 模型有以下4个接口:
// 模型类
class DogClassifier
// 输入类,用于接收带分类数据
class DogClassifierInput
// 输出类,用于输出分类结果
class DogClassifierOutput
// 相比于 Core ML 2.0 新增的输入类,用于接收新的训练数据,用以改变模型参数
class DogClassifierTrainingInput
根据新提供的接口,我们可以根据以下步骤更新原来的模型:
// 1. 提供原模型的信息
let bundle = Bundle(for: DogClassifier.self)
let updatableModelURL = bundle.url(forResource: "DogClassifier",
withExtension: "mlmodelc")!
// 2. 提供新的训练数据
let trainingData = prepareTrainingData(from: trainingSamples)
// 3. 开始更新模型
let updateTask = try MLUpdateTask(forModelAt: updatableModelURL,
trainingData: trainingData,
configuration: configuration,
completionHandler: { context in
// 使用新的模型
self.dogClassifier.model = context.model
})
updateTask.resume()
实际模型中更新的只是部分层级:它们必须是全连接的卷积神经网络层,其更新损失经过均方差和交叉熵计算后通过 Adam 和 SGD 方法优化,使得参数变化在一个固定范围,变化比较平稳。
神经网络的优化和支持
苹果的神经网络模型主要是由两部分组成:
- 卷积层。负责加权叠加输入数据。简单的讲,就是对于一个数据不同的特征,你要计算出一个结果,就得将这些特征拉到一个维度。卷积层的工作就是把特征一个个提取出来,放在一个向量中。
- 激活函数。负责将神卷积层输出的结果(向量)加上一个非线性变换。可以这样理解,这时候所有的特征被揉在一起,最后输出的是一个全局特征值。
Core ML 的模型,原来只能一层层的定向传输数据。现在 Core ML 3.0 增加了动态的神经网络层,可以根据不同条件,进行不同层之间选择性的传输、在固定层之间数据循环传输。目前,Core ML 3.0 可以支持多达100多种神经网络。
苹果现场展示了一款集合声音识别、自然语言处理、声音合成三大模型的应用。首先模型接受一篇长文,然后根据用户的提问,在长文中提取关键信息回答提问。这里 Core ML 3.0 可以将多个神经网络层动态结合形成一个综合性能的模型,可以接收不同类型的数据进行处理并输出精准的结果。

性能优化和更多种类数据支持
如往常一样,苹果在 Core ML 3.0 中优化了使用性能,例如用在不同图片分类器中,底层的逻辑被提取出来,做成了引用——这样多个模型就不用每次拷贝同一份底层逻辑,这也使得每个模型的大小缩小了一半左右。

基于 Core ML 为自然语言处理定制的 NLP 框架和为图像定制的 Vision 框架也进行了不小的更新。NLP 中,苹果增加了单词的上下文语义理解;Vision中,苹果引入了图片内文字检索和预测图片关注度的显著性预测功能。iOS 13 的图片 App 中,苹果还将 Vision 框架用于图片搜索功能,以提高搜索的准确性和相关度。
最后,本次 Core ML 新增了两种新的数据类型:声音和活动。声音方面,既可以文字转声音、也可以声音转文字,配合 NLP 框架效果更好。使用实例即是苹果自己的 Siri 和 Accessbility 语音功能(用户可以通过语音操控各种 App)。活动方面的应用主要集中在 Apple Watch,通过相关模型可以更好地帮助运动员判断姿势是否正确、是否需要调整训练计划等。
总结
Core ML 3.0 如期而至,WWDC 相关的 Session 由去年的8个增加到了10个。可以说苹果在此稳步投资,其功能的增加和性能的优化使得其使用场景进一步扩大,采用 Core ML 的 App 数量目前也已经增加到了300个以上。相信下一步 Core ML 将会继续专注于多种输入数据和模型之间的联系,例如增加多语种的支持;同时,移动端性能的优化也是其一个重要的方向。可以料想到,Core ML 将会在2年左右成为所有主流 App 的标配。