Improving Sample Efficiency In Model-Free Reinforcement Learning From Images 论文翻译
文章目录
- 论文原文链接
- 摘要
- INTRODUCTION
- 相关工作
- 背景
- 剖析利用 β \beta β-变分自编码器进行状态表示学习的方法
-
- 实验环境设置
- 没有辅助任务的model-free off-policy RL
- 应用 β \beta β-自编码器进行交替式的表示学习
- β \beta β-自编码器端到端学习的尝试
- 我们的方法
-
- 在像素上的性能
- 简化实验
-
- 编码器产生的表示的能力
- 泛化到没有见过的任务
- 讨论
- 最后——自己的话
论文原文链接
“Improving Sample Efficiency In Model-Free Reinforcement Learning From Images”(2019 arxiv)
摘要
利用Model-Free的强化学习方法训练一个直接从高维图像数据到控制策略的智能体已经被证明非常困难。智能体在学习控制策略的同时还需要学习状态的隐表示(latent representation)。利用稀疏的reward来拟合一个高维度的encoder不仅非常地采样低效(sample inefficient),并且可能导致收敛到次优解。有两种方法来提升采样效率,一是提取与任务相关的特征,二是使用异策(off policy)算法。我们剖析了多种优秀的隐特征(latent feature)学习方法后,得出了一个结论:图像的重构误差是基于图像的强化学习非常必要的一个组成部分。基于这个发现,我们开发了一种能够端到端训练的异策AC(off-policy actor critic)算法,包含一个辅助的解码器,并且在state-of-art的model-free和model-based算法中达到了相似的性能。我们开源了代码。
INTRODUCTION
相机是非常方便且廉价的设备,能够获取环境的状态信息,尤其是复杂、非结构化的环境。通常需要得到在这些环境中的底层动力学状态才能进行有效的控制。因此,开发一种有效的利用像素作为输入的强化学习方法,将会为许多的真实世界中的问题提供解决方案。
如何仅适用稀疏的反馈信号来有效地学习一个从像素到适合控制的状态表示成为我们的挑战。虽然深度卷积网络能够学到很好的表示,但是它们需要非常庞大的训练数据。正如现有的强化学习方法已经存在非常严重的采样复杂度问题,直接使用像素输入将会使得训练非常地慢。例如:Atari, DeepMind Control 需要上亿训练步数,这在很多应用中是不切实际的,尤其是在机器人领域。
一种很自然的解决办法是在其中添加无监督的辅助任务,来提高采样效率。最简单的方法就是利用一个用重建误差来训练的自编码器。先前的工作已经尝试利用自编码器来从像素中学习状态的表示,通常是一种两步走的形式,首先训练自编码器,随后利用自编码器提供的状态表示来进行策略的训练。这样的训练方法相比于交替训练更加地稳定,但是会产生次优的策略。其他的一些工作利用额外的重构误差进行了同策的model-free end-to-end的训练。
我们重新来研究在model-free的强化学习中添加自编码器的方法,但是集中研究异策算法。我们进行了一系列细致(careful)的实验来理解为什么之前的算法不能够很好地工作。我们发现像素的重构误差对学习到一个好的表示至关重要,尤其是在端到端训练的情况下。基于这些发现,我们提出了一种简单的,端到端训练的,基于自编码器的异策算法。我们的方法是第一个能够同时,稳定且高效地训练状态表示和策略的model-free off-policy 算法。
当然,一些当前state-of-art的model-based方法在像素任务上相比model-free方法已经展现出了超人的采样效率。但是我们发现我们的model-free,off-policy,autoencoder-based方法尽管更加简单并且不需要一个环境模型,也能够达到同样的性能,这缩小了model-free和model-based算法性能在基于图像的强化学习任务上的距离。
本文共有三个主要的贡献:1、说明了在model-free off-policy的强化学习算法中添加额外的重构误差能够使其在一系列连续控制任务上获得与state-of-art model-based 算法相匹敌的性能;2、理解将自编码器添加到model-free off-policy算法中的关键问题;3、一个开源的Pytorch实现。
相关工作
略
背景
第一段马尔科夫过程 略。
第二段 略,主要说明本文方法基于Soft Actor-Critic(SAC, RAIL实验室18年提出)算法,是一种DRL中的最大熵框架,在最大化reward的同时,也最大化策略的熵,以鼓励策略去探索。
第三、四段 略,主要说明自编码器、变分自编码器、β-变分自编码器的原理,及其与RL算法的结合
剖析利用 β \beta β-变分自编码器进行状态表示学习的方法
在本章中我们将系统地探索model-free off-policy RL算法是如何直接从像素完成训练的。首先我们先说明了SAC算法在像素输入时极大的性能损失(Section 4.2)。这一结果驱动我们去寻找不同的额外监督信息来加速表示学习(representation learning)。当然,有很多辅助的目标函数能够用来加速表示学习,从简单的角度考虑,我们专注于自编码器的研究。我们根据先前工作的方法(Section 4.3),尝试了一种交替式的无监督预训练β-自编码器来重建像素。对先前工作的训练过程的探索,说明了他们将导致次优策略的产生,并指出了β-自编码器与策略网络进行端到端训练的必要性。然而,在Section 4.4中我们发现这样的端到端训练将产生严重的训练不稳定性,尤其是在β较大时。我们重新来面对这个问题,并使用了确定性的变分自编码器和细致的学习过程。这引出了我们自己的算法。
实验环境设置
我们在此简要地说明我们的环境设置,详细的内容参阅附录B。在本文中,我们在6个基于图像的富有挑战性的连续控制任务评估各个算法。出于简单的目的,在正文中我们仅绘制3个主要的任务结果。对于一个任务来说,一个回合(episode)持续1000步,最大反馈1000。图像渲染为38484的RGB,并限制在[0, 1]范围内。为了从图像中推断出速度和加速度信息,我们堆叠3帧连续图像,就像DQN中所用的一样。在各个任务中我们保持所有超参数一致,出了重复动作数(action repeat)。参考先前的工作,我们仅在像素学习时才进行重复动作,这意味着部分训练数据将会被丢弃,例如在1000步的回合中,对每个动作重复4步,则仅有250个观察数据被用于训练。我们在每一万次训练后评估一次策略性能,每次评估持续10个回合,取平均。为了可靠的比较,每个回合我们都使用了不同的随机种子。
没有辅助任务的model-free off-policy RL
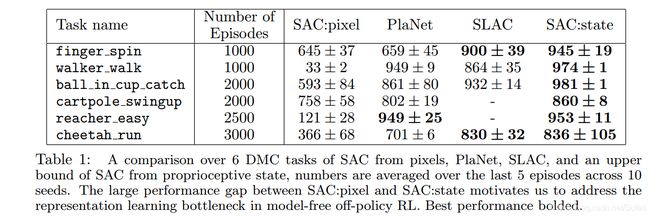
我们首先将SAC直接应用在像素学习上,与两个state-of-the-art model-based算法,PlaNet和SLAC。结果如下表。从结果可以看出,在像素上执行SAC的性能与利用额外辅助学习任务的model-based算法有很大的差距。Model-based算法能够达到非常接近于性能上界(使用state的SAC算法)的表现。故此,在像素上的SAC算法将作为性能的下界,我们将逐渐地引入额外的重建误差来缩小上下界之间的差距。
应用 β \beta β-自编码器进行交替式的表示学习
参考先前的工作,我们实验了利用自编码器的无监督表示学习方法。我们首先使用随机的策略(random policy)来进行自编码器的预训练,并在策略训练时固定自编码器的参数。我们通过微调超参数 β \beta β,发现数值较大的 β \beta β效果更差,非常小的 β ∈ [ 1 0 − 8 , 1 0 − 6 ] \beta \in [10^{-8}, 10^{-6}] β∈[10−8,10−6] 表现最好。同时,我们探索了在策略训练的同时更新自编码器的方法。在下图中展示了更新频率N对策略性能的影响,N表示每N步策略更新一次自编码器。N为无穷说明不再更新,N=1说明每步都更新。结果显示更新越频繁,性能越好。需要强调的是,自编码器的更新所使用的梯度不是从策略中来的,而是仅仅从重建误差而来。这一结果说明,将自编码器和策略训练结合在一起,通过稳定的端到端学习方式,能够提升性能。然而,在先前的工作中,研究人员并不能够成功地重现这一结果。我们需要更好地了解其中到底那部分出了问题。

β \beta β-自编码器端到端学习的尝试
我们以上的发现以及先前工作,都启发我们应该允许策略学习的梯度传递到自编码器上来。我们构建了一个端到端的训练模式,令自编码器的训练不仅仅根据于重构误差,还根据于Actor-Critic的目标函数产生的梯度。然而,下图的结果表明端到端的训练方式并不稳定,容易产生发散的情况而降低性能。这一结果和先前的工作是一致的,先前的解决办法是交替地训练自编码器和策略网络,而不是通过端到端的方式。下面我们尝试使得端到端的训练变得稳定,并提出我们的方法。

我们的方法
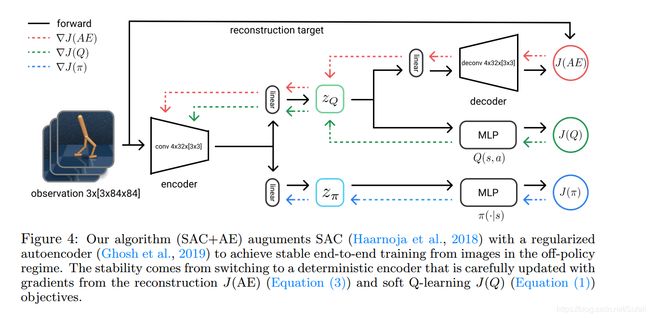
我们现在来设计一种稳定的训练方式,使得像素自编码器能够和策略学习同时进行。我们基于SAC算法进行开发。基于我们在第四章中的发现,我们提出一个新的、简单的、端到端训练的算法,SAC+AE。我们发现使用确定的隐表示方法,而不是具有随机性的隐表示(如 β \beta β-VAE),更能够使端到端的训练变得稳定。因此我们使用确定性的自编码器:正则自编码器(regularized autoencoder, RAE)。同时我们也发现,令卷积层的参数在target critic网络训练时更新地更快很重要。这一手段使得在保证训练稳定性的同时加快训练速度。最后,我们在actor和critic之间共享卷积层参数,但是卷积层不从actor处获得传播梯度。结构如下图所示。
在像素上的性能
我们现在来看看我们这一简单的方法能否稳定地进行端到端训练。(此处省略一些实现细节,如网络结构等)。
我们将我们的算法与目前最先进的model-free和model-based算法进行比较,包括D4PG(model-free)、PlaNet(model-based)、SLAC(model-based)。同时,我们将SAC算法在低维状态下的学习结果作为性能的上界来作比较。结果如下图所示,SAC+AE方法(本文提出的)能够达到持平基于图像的最优性能。

简化实验
为了进一步说明我们的算法在隐表示空间学习方面的一些属性,我们进行了一些模型简化实验。我们想要回答这样两个问题:1、我们的方法是否从原始像素中获取了足够多的信息,这些信息是否足够从中能否恢复出相应的状态信息?2、学习到的隐表示能否泛化到一些有相似像素观察但没有见过的任务?
编码器产生的表示的能力
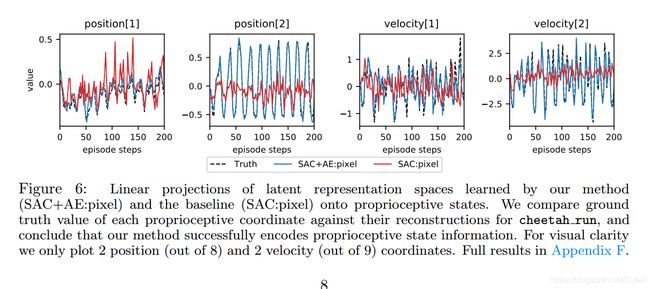
为了说明我们的方法比不带自编码器的方法更优,我们假设从图像中学到的状态表示应该包含足够多的信息,并且从这些信息中能够很简单地提取出真实的状态信息。为了验证这一观点,我们在cheetah_run这一任务中训练了两个策略,SAC+AE和SAC(含自编码器与不含自编码器),训练到收敛为止。随后我们训练两个相同结构的线性映射,将从像素学习到的隐表示映射到真实状态空间。然后我们比较ground truth和这两个映射结果的差异,来说明哪一个学到了更有效的信息。结果如下图所示,结果说明,有自编码器的版本能够很好地从中恢复出真实的状态信息,而不含自编码器的版本则差异十分大。这也解释了为什么直接使用图像作为策略训练将导致严重的性能退化。
泛化到没有见过的任务
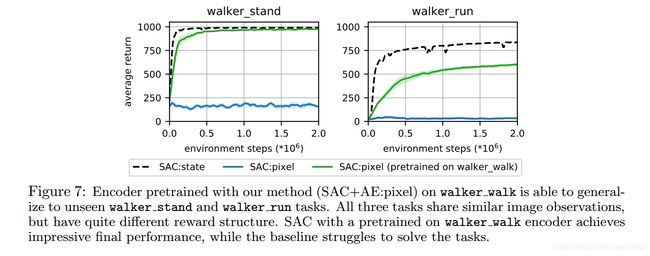
我们从Deep Mind Control中选择了3个像素相似的任务,但是它们有不同的reward结构。我们首先应用SAC+AE方法在其中一个中训练直到收敛,并获得它的编码器部分。随后我们为另外两个任务训练两个版本的agent,1、使用上一个任务训练好的编码器初始化,2、随机初始化编码器。并且在训练过程中不再添加重构误差,只使用critic网络产生的梯度来训练编码器。结果如下图所示,结果表明已训练好的编码器能够帮助SAC算法在其他的任务中很快地获得好的性能。
讨论
我们提出了第一个直接从图像输入并且仅适用重构误差作为额外训练的,端到端的、off-policy model-free的RL算法。它能够达到与目前最先进的model-based算法相媲美的性能,但更加简单、鲁棒,且不需要额外学习一个环境动力学模型。我们通过一些简化实验来说明了端到端训练相比于之前two-step训练方法的优势,说明了像素重建误差在从图像中获取真实状态信息非常必要,也说明了学习到的状态表示有一定的泛化能力和表现能力。
我们发现确定性的模型比β-VAE等具有随机性的模型性能要好,这可能是因为一些来自于其他方面的不确定性,例如bootstrapping、off-policy数据和端到端学习。我们认为即使在随机环境中仍然应该选择确定性的模型,确定性的模型能够有更好的解释性因为它们学习到的是一个更简单的分布。
在附录中我们提供了所有实验的结果以及超参数的设置。我们也将我们的代码开源。
最后——自己的话
读这篇文章的初衷是因为它所提出的问题与一直困扰的我问题一样,到底Image-based DRL是不是不可能/或不现实。很自然的,图像输入将会加大训练的难度,本文给出了相对详尽的研究,说明在图像输入的情况下,一般的方法将会严重退化,同时本文也给出了相应的解决方法,即是包含(确定性)自编码器的端到端训练方法。这一方法在我们实验室后面的实践中会有很大的帮助。本文也有不足之处,可能创新性上不太足,更像是实验性的文章,探究性、实践性更强,研究性不强。