程序是如何跑起来的
内存和磁盘的亲密关系
- 磁盘缓存是指:从磁盘中读出的数据在内存中,当该数据再次被读取时,不是从磁盘而是直接从内存中高速读出,借助虚拟内存,哪怕是内存容量不足的计算机,也可以运行很大的程序
从都具有存储程序命令和数据这点来看,内存和磁盘的功能是相同的,在计算机的5大部件(输入装置,输出装置,存储器,运算器,控制器)中,内存和磁盘都被归类为存储设备。内存使用电流实现存储,磁盘使用磁效应存储,内存主要是是指主内存(负责存储 CPU 中运行的程序指令和数据内存),磁盘主要是指硬盘
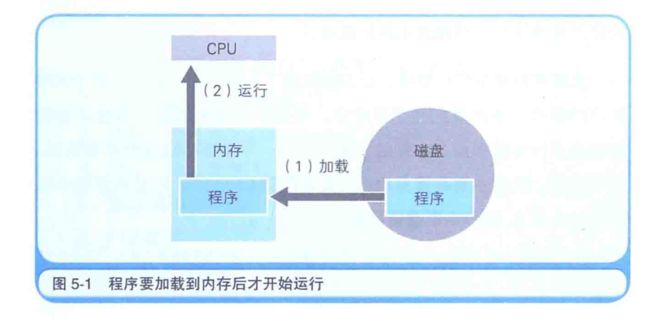
不读入内存就无法运行
程序保存在存储设备中,通过有序地读出来实现运行,这一机制称为存储程序方式,计算机中主要的存储部件是内存和磁盘,磁盘中存储的程序,必须要加载到内存中才能运行,在磁盘中保存的原始程序是无法直接运行的,这是因为,负责解析和运行程序内容的 CPU, 需要通过内部程序计数器来指定内存地址,然后才能读出程序,
磁盘缓存加快了磁盘当文速度
磁盘缓存 指的是把从磁盘中读出的数据存储到内存空间中的方式,这样一来,当接下来需要读取同一数据时,就不用通过实际的磁盘,而是从磁盘缓存中把内容读出来,使用磁盘缓存可以大大改善磁盘数据的访问数据。
虚拟内存把磁盘作为部分内存来使用
虚拟内存是指把磁盘的一部分作为假想的内存来来使用,借助虚拟内存,在内存不足时也可以运行程序,例如在只剩下 5MB 内存空间的情况下也能运行 10MB 大小的程序,cpu 只能执行加载到内存中的程序,虚拟内存虽说是把磁盘作为内存的一部分来使用,但实际上正在运行的程序部分,在这个时间点上必须存在在内存中,也就是说,为了实现虚拟内存,就必须把实际内存的内容和磁盘上的虚拟内存的内容进行部分置换(swap),并同时运行程序。
为了实现虚拟内存功能, Windows 在磁盘上提供了虚拟内存用的文件(page file, 页文件),该文件由 Windows 自动做成和管理,文件的大小也就是虚拟内存的大小,通常是实际内存的相同程度至两倍程度,通过 windows 的控制面板,可以查看或变更当前虚拟内存的设定。

节约内存的编程方法
为了从根本上解决内存不足的问题,需要增加内存的容量,或者尽量把运行的应用文件变小。
通过 DLL 文件实现函数共有
DLL(Dynamic Link Library) 文件,顾命思义是在程序运行时可以动态加载 Library(函数和数据的集合),多个应用可以共有同一个 DLL 文件,通过一个 DLL 文件则可以达到节约内存的效果。
通过调用 _stdcall 来减小程序文件的大小
_Stdcall是standard call的略称, windows 提供的 DLL 文件内的函数,基本上都是_stdcall的方式调用的,另一方面,用 C 语言编写的程序内的函数,默认设置都不是_StdCall, c 语言特有的调用方式是 C 调用,因为 C 所对应的函数的传入参数是可变的,只有函数调用方才能知道到底有多少个参数,在这种情况下,栈的清理作业便无法进行
c 语言函数调用后,需要执行栈清理处理指令,栈清理处理是指:把不需要的数据从接收和传递函数的参数时使用的的内存上的栈区域中清理出去,该命令不是程序记述的,而是在程序编译时由编译器自动附加到程序中,编译器默认将该处理附加在函数调用方。
实例:
// 函数调用方
void main()
{
int a;
a = MyFunc(123, 456);
}
// 被调用方
int MyFunc(int a,int b)
{
return a+b;
}
从函数 main() 中调用了函数 MyFunc(). 按照默认设定,栈的清理处理会附加在函数 main() 这一方,在同一个程序中,同样的函数可能会被多次反复调用,儿如果是同样的函数,栈清理的内容也是一样的,由于该处理是在调用函数的一方,因此就会导致同一处理被反复进行,造成了内存的浪费

C 语言通过栈来传递函数的参数,push 是往栈中存入数据的指令, 32 位 cpu 中, 1次 push 指令可以存储 4 个字节的数据,由于使用了两次 push 指令把两个参数存入到栈中,因此总的来说就是存储了8字节的数据,通过 call 指令调用函数 MyFunc() 后,栈中存储的数据就不再需要了,于是这时就通过 add esp, 8 这个指令存储这个栈数据的 esp 寄存器前进8位,来进行数据清理。c 语言中,函数的返回值是通过寄存器而非栈来返回的。
栈清理处理,比起在函数调用方进行,在反复被调用的函数一方进行,程序整体要小一些,这时所使用的就是 _stdcall, 在函数前面加上 stdcall,就可以把栈清理处理变为在被调用函数一方进行。
磁盘的物理结构
磁盘是通过把其物理表面划分成多个空间来使用的,划分的方式有扇区方式和可变长方式,前者指将磁盘划分为固定长度的空间,后者则是把磁盘划分为长度可变的空间,扇区方式中,把磁盘的表面划分成若干个同心圆空间的就是磁道,把磁道按照固定大小(能存储的数据长度相同)划分而成的空间就是扇面。

程序是在何种环境中运行的
运行环境
运行环境 = 操作系统 + 硬件
CPU 只能解释其自身固有的机器语言,不同的 CPU 能解释的机器语言种类也不同,机器语言的程序称为本地代码,程序员使用 C 语言等编写的程序,在编写阶段仅仅是文本文件,文本文件在任何环境下都能显示和编辑,我们称之为源代码,通过对源代码进行编译就可以得到本地代码。
之所以需要根据不同的操作系统类型来专门开发应用软件,是因为操作系统的类型不同,应用程序向操作系统传递指令的途径也不是相同的。
FreeBSD
unix 系列操作系统 FreeBSD 中,存在一种名为 Ports 的机制,该机制能够结合当前运行的硬件环境来编译应用的源代码,进而得到可以运行的本地代码系统。
BIOS 和引导
BIOS 存储在 ROM 中,是预先内置在计算机主机内部的程序,BIOS 除了键盘,磁盘,显卡等基本控制程序外,还有启动“引导程序”的功能,引导程序是存储在启动驱动器其实区域的小程序,操作系统的启动驱动器一般是硬盘。
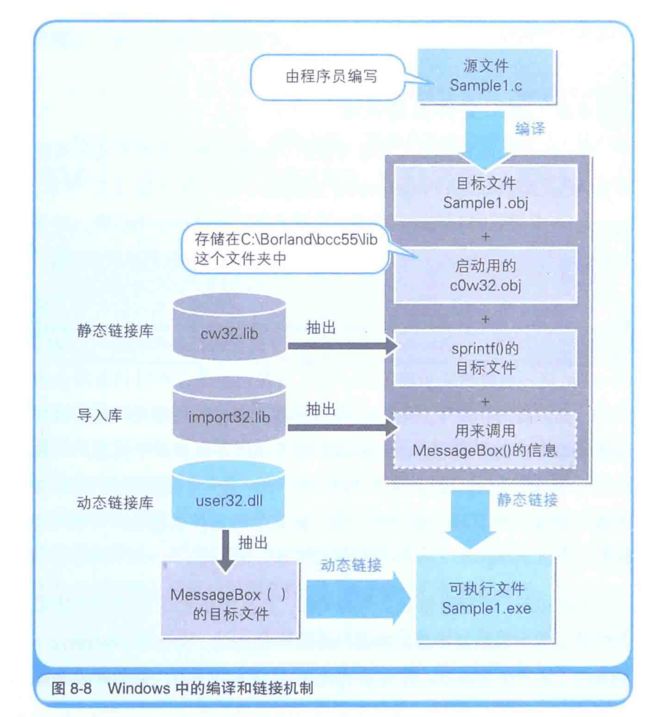
从源文件到可执行文件
通过编译源代码得到本地代码,通过编译和链接,得到 exe 文件,链接器会从库文件中抽取出必要的目标文件并将其结合到 Exe 文件中,把导入库信息结合到 exe 文件中,这样程序在运行时就可以利用DLL 内的函数了。堆的内存空间会根据程序的命令进行申请和释放
源代码完成后,就可以编译生成可执行文件了,负责实现该功能的是编译器
编译器负责转换源代码
能够把 C 语言等高级编程语言编写的源代码转换成本地代码的程序称为编译器,每个编写源代码的编程语言都需要器专用的编译器,将 C 语言编写的源代码转换成本地代码的编译器称为 C 编译器
编译器首先读入代码的内容,然后再把源代码转换成本地代码,编译器中就好像有一个源代码同本地代码的对应表,读入的源代码还需要经过语法解析,语句解析,语义解析等,才能生成本地代码
仅靠编译是无法得到可执行文件的
编译器转换源代码后,就会生成本地文件,不过,本地文件是无法直接运行的,为了得到可以运行的 EXE 文件,编译之后还需要进行“链接”处理。'
把多个目标文件结合,生成1个 exe 文件的处理就是链接,运行链接的程序就成为链接器
可执行文件运行时的必要条件
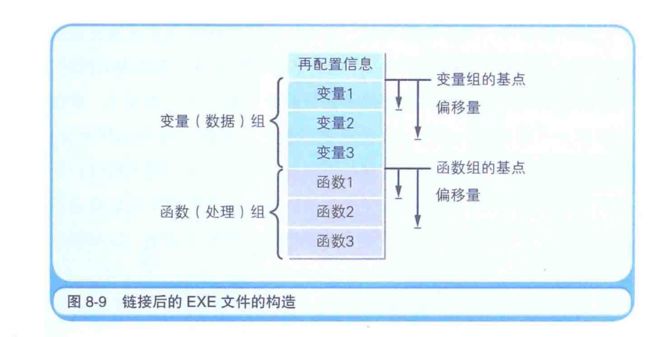
本地代码在对曾许中记述的变量进行读写时,是参照数据存储的地址来运行命令的,在调用函数时,程序的处理流程就会跳转至存储着函数处理内容的内存地址上, exe 文件作为本地代码的程序,并没有指定变量及函数的实际内存地址。那么在 exe 文件中,变量和函数的内存地址的值,是如何来的呢?
答案是:给 exe 文件中的变量及函数分配了虚拟的内存地址,在程序运行时,虚拟的内存地址会转换成实际的内存地址,连接器会在 exe 文件的开头,追加转换内存地址所需的必要信息,这个信息被称为再配置信息,exe 文件的再配置信息,就成了变量和函数的相对地址,相对地址表示的是相对于基点地址的偏移量,也就是相对距离,实现相对地址,也是需要花费一番心思的,在源代码中,虽然变量及函数是在不同位置分散记述的,但在链接后的 exe 文件中,变量及函数就会变成一个连续排列的组,这样一来,各变量的内存地址就可以用相对变量组起始位置这一基点的偏移量来表示,同样,各函数的内存地址也可以相对于函数组起始位置这一基点的偏移量来表示,而各组基点的内存地址是在程序运行时被分配的。
/Users/qianbaofeng/Desktop/屏幕快照 2017-07-08 下午3.06.08.png
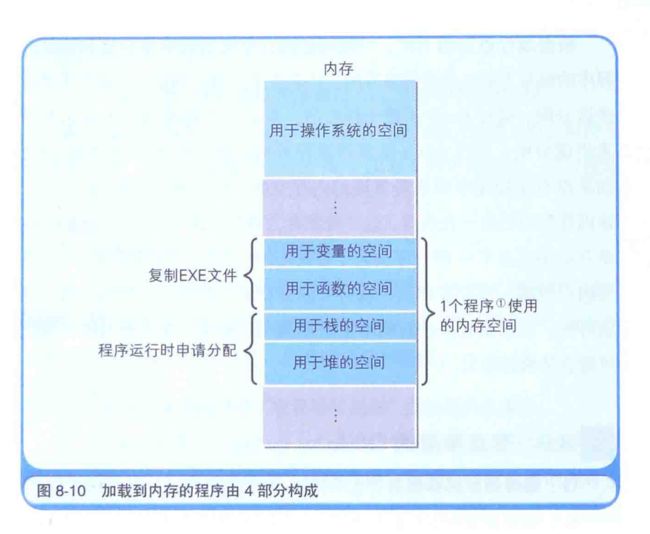
加载程序时会生成栈和堆
EXE 文件的内容分为再配置信息,变量组和函数组,不过当程序加载到内存后,初次之外还会额外生成两个组,那就是堆和栈,栈是用来存储函数内部临时使用的变量(局部变量)以及函数调用时所用的参数的内存区域,堆是用来存储程序运行时的任意数据及对象的内存领域
个人理解,所谓的 c++ 面向对象编程,最终都将会被转换成c 语言的函数,只不过再调用的时候调用的是获取和设置函数,每个对象的属性栈及时一堆函数???
exe 文件中并不存在栈及堆的组,堆和栈需要在内存空间是在 exe 文件加载到内存后开始运行时得到分配的,因而,内存中的程序,就是由用于变量的内存空间,用于函数的内存空间,用于栈的内存空间,用于堆的内存空间这四个部分构成。
堆和栈的相似之处在于,他们的内存空间都是在程序运行时得到申请分配的。不同点在于: 栈中对数据进行存储和舍弃(清理处理)的代码,由编译器自动生成,使用栈的数据内存空间,每当函数被调用时都会得到申请分配,并在函数处理完毕后自动释放,与此相对,堆的内存空间,则要根据程序员编写的程序,来明确进行申请分配或释放。
不管什么程序,程序的内容都是有处理和数据构成的,大多数编程语言都是由函数来表示处理,变量来表示数据。
一些有难度的 Q&A
- Q: 编译器和解释器有什么不同
A: 编译器是在运行前对所有源代码进行解释处理的,而解释器则是在运行时对源代码的内容一行一行的进行解释处理的 - Q: 分割编译是什么
A: 将整个程序分为多个源代码编写,然后分别进行编写,最后链接成一个 EXE 文件,这样每个源代码都相对变短,便于程序管理 - Q: "build" 指的是什么
A: build 指的是连续执行编译和链接 - Q: DLL 的好处?
A: DLL 文件中的函数可以被多个程序共用,可以节约内存和磁盘
汇编语言
汇编语言和本地代码一一对应
计算机 CPU 能直接解释运行的只有本地代码程序,用 C 语言等编写的代码,需要通过各自的编译器编译后,转换成本地代码,
对栈进行 push 和 pop
程序运行时,会在内存上申请分配一个称为栈的数据空间,数据在存储时是从内存的下层(大号地址)逐渐网上层累加的,读出时是按照从上往下的顺序进行的。

栈是存储临时数据的区域,它的特点是通过 push 指令和 pop 指令进行数据的存储和读出,往栈中存储数据称为 "入栈",从"栈"中读出数据称为 "出栈"。对栈尽享读写的内存地址是由 esp 寄存器(栈指针)进行管理的, push 指令和 pop 指令运行后,esp 寄存器值回自动进行更新.
函数调用机制
代码如下:

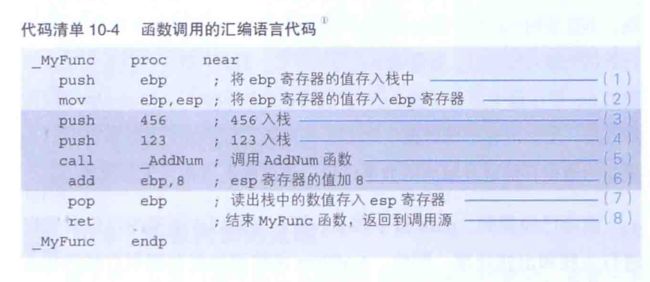
在汇编语言中,函数名表示的是函数所在的内存地址,当call 调用的函数运行后, 程序流程必须返回编号(6)的这一行, call 指令运行后, call 指令的下一行的内存地址(6的这一行)回自动 push 入栈,该值会在 AddNum 函数处理的最后通过 ret 指令 pop 出栈,然后流程回到 6 这一行
函数的内部调用
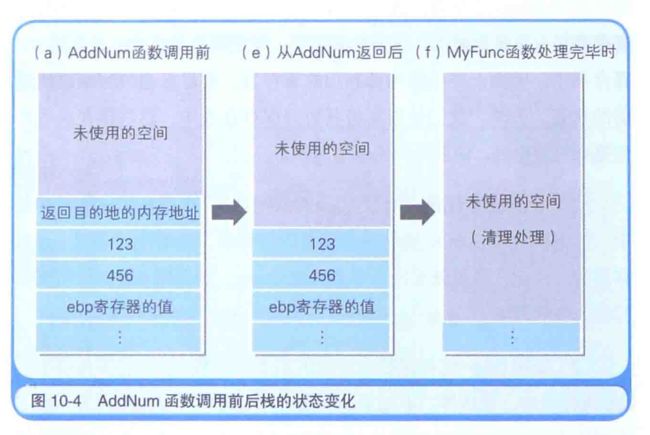

ebp 寄存器的值在 1 中入栈,在 5 中出栈,主要是为了把函数中用到的 ebp 寄存器的内容,恢复到函数调用之前的状态,在进入函数处理之前,无法确定 ebp 寄存器用到了什么地方,但由于函数内部
(2) 中把负责管理地址的 esp 寄存器的值赋到了 ebp 寄存器中,这时因为, mov 指令中方括号的参数,是不允许指令 esp 寄存器的,
函数是的参数是通过栈来传递的,返回值是通过寄存器来返回的。
始终确保全局变量用的内存空间
c 语言中,在函数外部定义的变量称为全局变量,在函数内部定义的变量称为局部变量,
全局变量可以参阅源代码的任意部分,而局部变量只能在定义该变量的函数内进行参阅。
正如之前所说的,编译后的程序,会被归类到名为段定义的组,初始化的全局变量,会被定义到名为 _DATA 的段定义中,没有初始化的全局变量会被汇总到 _BSS 的段定义中,指令会被汇总到名为 _TEXT 的段定义中
临时确保局部部变量用的內存空间
局部变量是临时保存在寄存器和栈中的,导致局部变量只能在定义该函数的内部进行参阅。函数内部利用栈,在函数处理完毕后会恢复到初始状态,因此局部变量的值也就被销毁了,而寄存器也可能会被用于其他目的,因此,局部变量只是在函数处理运行期间临时存储在寄存器和栈上。