ElasticSearch-suggest-问题分析之 too_complex_to_determinize_exception
现象
POST index_name/_search
{
"suggest": {
"my-suggestion": {
"text": "菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇咕叫好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好菇咕叫好菇凉咕咕咕咕叫你好菇凉咕咕咕咕叫你好",
"term": {
"analyzer": "keyword",
"field": "filedName",
"size": 3,
"suggest_mode": "MISSING",
"accuracy": 0.5,
"sort": "SCORE",
"string_distance": "INTERNAL",
"max_edits": 2,
"max_inspections": 5,
"max_term_freq": 0.01,
"prefix_length": 0,
"min_word_length": 2,
"min_doc_freq": 0.0
}
}
}
}
{
"error": {
"root_cause": [{
"type": "too_complex_to_determinize_exception",
"reason": "too_complex_to_determinize_exception: Determinizing automaton with 28269 states and 42632 transitions would result in more than 10000 states."
},
{
"type": "too_complex_to_determinize_exception",
"reason": "Determinizing automaton with 28269 states and 42632 transitions would result in more than 10000 states."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [{
"shard": 0,
"index": "index_name",
"node": "sBN2qHjRQMWPzYuTmP4K4w",
"reason": {
"type": "too_complex_to_determinize_exception",
"reason": "too_complex_to_determinize_exception: Determinizing automaton with 28269 states and 42632 transitions would result in more than 10000 states."
}
},
{
"shard": 4,
"index": "index_name",
"node": "KPd9xkrYTF2-9Pwl9H6dYw",
"reason": {
"type": "too_complex_to_determinize_exception",
"reason": "Determinizing automaton with 28269 states and 42632 transitions would result in more than 10000 states."
}
}
]
},
"status": 500
}
原因
suggest 使用的算法Levenstein edit distance,通过计算一个词通过更改多少个单词可以与另一个词相同的算法来计算得分
fuzzy query也是使用该算法
而报错则是因为查询所携带的text文本过长,导致自动机模型过多,超过10000个
为了加速通配符和正则表达式的匹配速度,Lucene4.0开始会将输入的字符串模式构建成一个DFA (Deterministic Finite Automaton),带有通配符的pattern构造出来的DFA可能会很复杂,开销很大
比如a*bc构造出来的DFA就像下面这个图一样:
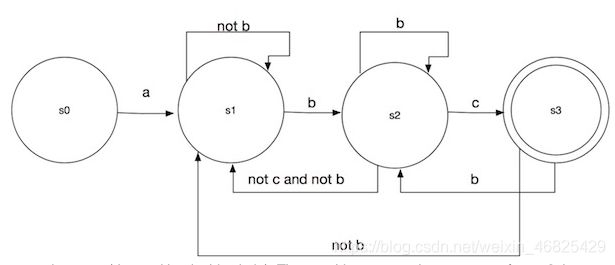
- org.apache.lucene.search.WildcardQuery里的toAutomaton方法,遍历输入的通配符pattern,将每个字符变成一个自动机(automaton),然后将每个字符的自动机链接起来生成一个新的自动机
/**
* Convert Lucene wildcard syntax into an automaton.
* @lucene.internal
*/
@SuppressWarnings("fallthrough")
public static Automaton toAutomaton(Term wildcardquery) {
List<Automaton> automata = new ArrayList<>();
String wildcardText = wildcardquery.text();
for (int i = 0; i < wildcardText.length();) {
final int c = wildcardText.codePointAt(i);
int length = Character.charCount(c);
switch(c) {
// *
case WILDCARD_STRING:
automata.add(Automata.makeAnyString());
break;
// ?
case WILDCARD_CHAR:
automata.add(Automata.makeAnyChar());
break;
// \\
case WILDCARD_ESCAPE:
// add the next codepoint instead, if it exists
if (i + length < wildcardText.length()) {
final int nextChar = wildcardText.codePointAt(i + length);
length += Character.charCount(nextChar);
automata.add(Automata.makeChar(nextChar));
break;
} // else fallthru, lenient parsing with a trailing \
default:
automata.add(Automata.makeChar(c));
}
i += length;
}
return Operations.concatenate(automata);
}
-
此时生成的状态机是不确定状态机,也就是Non-deterministic Finite Automaton(NFA)
-
org.apache.lucene.util.automaton.Operations类里的determinize方法则会将NFA转换为DFA
时间复杂度最差情况下是状态数量的指数级别,一般是指数级别
/**
* Returns a (deterministic) automaton that accepts the complement of the
* language of the given automaton.
*
* Complexity: linear in number of states if already deterministic and
* exponential otherwise.
* @param maxDeterminizedStates maximum number of states determinizing the
* automaton can result in. Set higher to allow more complex queries and
* lower to prevent memory exhaustion.
*/
static public Automaton complement(Automaton a, int maxDeterminizedStates) {
a = totalize(determinize(a, maxDeterminizedStates));
int numStates = a.getNumStates();
for (int p=0;p<numStates;p++) {
a.setAccept(p, !a.isAccept(p));
}
return removeDeadStates(a);
}
- DFA虽然搜索的时候快,但是构造方面的时间复杂度可能比较高,特别是带有首部通配符+长字符串的时候。
回想Elasticsearch官方文档里对于Wildcard query有特别说明,要避免使用通配符开头的term
- regex, fuzzy query是也有同样的情况,在于他们底层和wildcard一样,都是通过将pattern构造成DFA来加速字符串匹配速度的
疑点
为什么suggest也会出现这种现象?以下是es自己报错
Caused by: org.elasticsearch.common.io.stream.NotSerializableExceptionWrapper: too_complex_to_determinize_exception: Determinizing automaton with 14431 states and 21763 transitions would result in more than 10000 states.
at org.apache.lucene.util.automaton.Operations.determinize(Operations.java:746) ~[lucene-core-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:05:56]
at org.apache.lucene.util.automaton.RunAutomaton.(RunAutomaton.java:74) ~[lucene-core-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:05:56]
at org.apache.lucene.util.automaton.ByteRunAutomaton.(ByteRunAutomaton.java:32) ~[lucene-core-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:05:56]
at org.apache.lucene.util.automaton.CompiledAutomaton.(CompiledAutomaton.java:251) ~[lucene-core-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:05:56]
at org.apache.lucene.util.automaton.CompiledAutomaton.(CompiledAutomaton.java:137) ~[lucene-core-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:05:56]
at org.apache.lucene.search.FuzzyTermsEnum.(FuzzyTermsEnum.java:134) ~[lucene-core-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:05:56]
at org.apache.lucene.search.spell.DirectSpellChecker.suggestSimilar(DirectSpellChecker.java:409) ~[lucene-suggest-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:06:45]
at org.apache.lucene.search.spell.DirectSpellChecker.suggestSimilar(DirectSpellChecker.java:357) ~[lucene-suggest-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:06:45]
at org.apache.lucene.search.spell.DirectSpellChecker.suggestSimilar(DirectSpellChecker.java:298) ~[lucene-suggest-8.2.0.jar:8.2.0 31d7ec7bbfdcd2c4cc61d9d35e962165410b65fe - ivera - 2019-07-19 15:06:45]
at org.elasticsearch.search.suggest.term.TermSuggester.innerExecute(TermSuggester.java:56) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.suggest.term.TermSuggester.innerExecute(TermSuggester.java:39) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.suggest.Suggester.execute(Suggester.java:42) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.suggest.SuggestPhase.execute(SuggestPhase.java:57) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:97) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.SearchService.loadOrExecuteQueryPhase(SearchService.java:335) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:355) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.SearchService.lambda$executeQueryPhase$1(SearchService.java:340) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.action.ActionListener.lambda$map$2(ActionListener.java:145) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.action.ActionListener$1.onResponse(ActionListener.java:62) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.search.SearchService.lambda$rewriteShardRequest$7(SearchService.java:1043) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.action.ActionRunnable$1.doRun(ActionRunnable.java:45) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.common.util.concurrent.TimedRunnable.doRun(TimedRunnable.java:44) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:773) ~[elasticsearch-7.4.0.jar:7.4.0]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) ~[elasticsearch-7.4.0.jar:7.4.0]
上面日志+源码可以发现: **org.elasticsearch.search.suggest.term.TermSuggester.innerExecute()**中针对每个token都生产了DFA
List<Token> tokens = queryTerms(suggestion, spare);
for (Token token : tokens) {
// TODO: Extend DirectSpellChecker in 4.1, to get the raw suggested words as BytesRef
SuggestWord[] suggestedWords = directSpellChecker.suggestSimilar(
token.term, suggestion.getShardSize(), indexReader, suggestion.getDirectSpellCheckerSettings().suggestMode()
);
Text key = new Text(new BytesArray(token.term.bytes()));
TermSuggestion.Entry resultEntry = new TermSuggestion.Entry(key, token.startOffset, token.endOffset - token.startOffset);
// 针对每个词,都做自动机转换
for (SuggestWord suggestWord : suggestedWords) {
Text word = new Text(suggestWord.string);
resultEntry.addOption(new TermSuggestion.Entry.Option(word, suggestWord.freq, suggestWord.score));
}
response.addTerm(resultEntry);
}
而在**org.apache.lucene.search.spell.DirectSpellChecker#suggestSimilar()**方法中,用FuzzyTermsEnum对象来封装查询term
FuzzyTermsEnum e = new FuzzyTermsEnum(terms, atts, term, editDistance, Math.max(minPrefix, editDistance-1), true);
FuzzyTermsEnum初始化时候
prevAutomata = new CompiledAutomaton[maxEdits+1];
// 针对词生成automata 组
Automaton[] automata = buildAutomata(termText, prefixLength, transpositions, maxEdits);
for (int i = 0; i <= maxEdits; i++) {
// 针对每一个词都构建一个/两个(与maxEdits参数有关)prevAutomata
prevAutomata[i] = new CompiledAutomaton(automata[i], true, false);
}
// first segment computes the automata, and we share with subsequent segments via this Attribute:
dfaAtt.setAutomata(prevAutomata);
在CompiledAutomaton方法中
// 会将NFA转换为DFA
automaton = Operations.determinize(automaton, maxDeterminizedStates);
// 在取得转换为UTF-8的自动机
binary = new UTF32ToUTF8().convert(automaton);
// This will determinize the binary automaton for us:
// 获取二进制的自动机
runAutomaton = new ByteRunAutomaton(binary, true, maxDeterminizedStates);
之后在ByteRunAutomaton中还会将NFA转换为DFA
整个流程ES与对每个输入词根据maxEdits(最大编辑距离),调用lucene的DirectSpellChecker.suggestSimilar()方法去构建preAutomaton,若字符过长,产生的自动机状态也会很多,当数量超过1W,则会出现too_complex_to_determinize_exception错误,另外,太长的查询词,会严重影响es的cpu,导致es性能急剧下降
解决方案
- 过滤字符(例: 只取中文,英文,数字参与搜索)
- 限制长度(例: 取前20位参与搜索)
PS
PS1: 百度限制查询长度为38个字符
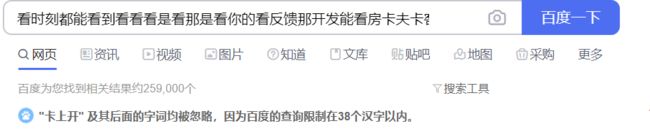
PS2:
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>8.2.0version>
dependency>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>7.4.0version>
dependency>