Erasure coding in HDFS
EC可以通俗的这样理解(并不准确,只是方便理解):传统的 HDFS Replication像RAID 0,数据被简单的复制多份;而EC像RAID5,采用数据+校验码的方式来确保可靠性。
EC的优点
1.更节省存储空间:RS(6+3)只需要1.5倍的磁盘空间就可以获得相同的可靠性,相比传统的Replication 3节省50%存储空间,;
2.并发读写多个DataNode,尤其对小文件的访问更快;
3.数据直接一次性写入(Replication是先写入一个DataNode,再异步复制到其它DataNode中);
EC缺点
1.数据恢复需要耗费更多的CPU、内存和IO,也更耗时(想象一下RAID5磁盘坏掉后的恢复过程……);
2.不(Wu)再(Fa)支持就近读取的策略了(Hadoop:现在动不动就万兆网,就近没那么重要了吧?)
总结
小于1 block(默认128M)的小文件多,磁盘空间紧张,适合用EC;大文件多适合用Replication。由于EC和Replication都是基于HDFS block的,所以它们并不冲突。Hadoop支持在同一个HDFS Cluster中对不同的文件或目录指定不同的存储策略。
EC是如何解决数据可靠性的问题呢?
EC本身就是纠偏码的缩写,纠删码技术主要将原始的数据进行编码得到校验,并将数据和校验一并存储起来,以达到容错的目的。其基本思想是将k块原始的数据元素通过一定的编码计算,得到m块校验元素。对于这k+m块元素,当其中任意的m块元素出错(包括数据和校验出错),均可以通过对应的重构算法恢复出原来的k块数据。Hadoop EC采用一种叫做RS(Reed-Solomon encoding)的纠偏码,这种编码方式之前广泛用于通信数据传输中。一般采用6个数据单元+3个校验单元,记为RS(6,3)。
EC数据存储方式:
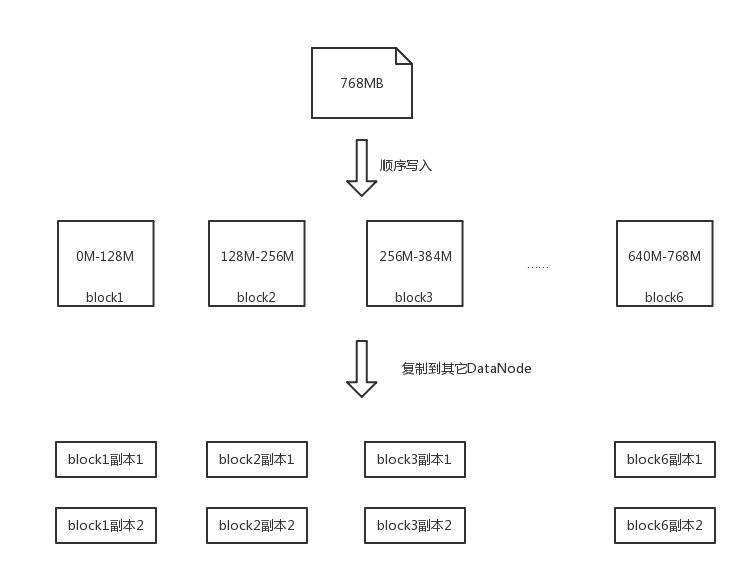
HDFS存储数据的最小物理单元是block,默认的block size是128M。传统的顺序存储方式是:将文件顺序写入多个block中。
例如,一个768M的文件,将被顺序写入6个128M的block中,然后每个block再被异步复制2个副本到其它DataNode中:
EC采用叫做文件存储的最小物理单元依然是block,但是在block基础上增加了strip和cell的逻辑单元,其中cell就是RS码中的"单元"。6个数据单元(也就是6个cell)+3个校验单元构成一个条(strip)。
例如,同样一个768M的文件将被分为768个1M大小的逻辑单元cell,每6个cell做RS encoding,生成3个校验cell,这样9个cell构成一个逻辑条(strip),然后依次循环将这些条写入到block中。

需要注意的是
1.client会直接并发读写这9个block所在的DataNode;
2.每个条(strip)中的cell必须分配到不同的block中。也就意味着,在RS(6,3)中即使文件再小,也至少占用9个block;
参考
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html
https://blog.cloudera.com/blog/2015/09/introduction-to-hdfs-erasure-coding-in-apache-hadoop/
最低支持Java8,不再支持Java7
YARN Timeline Service v.2(early preview,并不能用)
相比v.1改进:
1.扩展性增强:读写存储从单实例变为分布式并且将读写分开;
2.增加Flow的概念:我理解类似DAG(有向无环图);
其他改进
重写shell script;
Shaded client jars:屏蔽client jar包,避免client jar与Application classpath中的jar冲突(怎么做到的?);
增加Opportunistic Containers:低优先的container,即使没有资源也可以提交,等待资源空闲下来执行,主要目的是提高yarn集群利用率。
mapreduce性能优化:增加了一个map output collector的本地实现,对于shuffle-intensive jobs可以提升30%以上的性能;
默认端口变更:为了避免和linux临时端口范围 (32768-61000)冲突,修改了部分默认端口号;
增加Microsoft Azure Data Lake和阿里云OSS支持;
Intra-datanode balancer:解决DataNode内部增减磁盘导致的数据倾斜问题,我理解DataNode内部rebalance不用整个集群rebalance了。
YARN 支持自定义扩展Resource Types,比如你可以定义GPU、软件licenses等资源;
HDFS Router-Based Federation增加了a RPC routing layer,多个子集群的超大型集群才用得上,有时间再研究。
Capacity Scheduler queue增加读写Configuration的API;
S3Guard:用不到,懒得看了。