详解AOC指标
AUC指标
AUC是一个模型评价指标,用于二分类模型的评价。AUC是“Area under Curve(曲线下的面积)”的英文缩写,而这条“Curve(曲线)”就是ROC曲线。
ROC:受试者工作特征曲线
为什么要用AUC作为二分类模型的评价指标呢?为什么不直接通过计算准确率来对模型进行评价呢?答案是这样的:机器学习中的很多模型对于分类问题的预测结果大多是概率,即属于某个类别的概率,如果计算准确率的话,就要把概率转化为类别,这就需要设定一个阈值,概率大于某个阈值的属于一类,概率小于某个阈值的属于另一类,而阈值的设定直接影响了准确率的计算。使用AUC可以解决这个问题,接下来详细介绍AUC的计算。
例如,数据集一共有5个样本,真实类别为(1,0,0,1,0);二分类机器学习模型,得到的预测结果为(0.5,0.6,0.4,0.7,0.3)。将预测结果转化为类别——预测结果降序排列,以每个预测值(概率值)作为阈值,即可得到类别。计算每个阈值下的“True Positive Rate”、“False Positive Rate”。以“True Positive Rate”作为纵轴,以“False Positive Rate”作为横轴,画出ROC曲线,ROC曲线下的面积,即为AUC的值。
那么什么是“True Positive Rate”、“False Positive Rate”?
首先,我们看如下的图示:
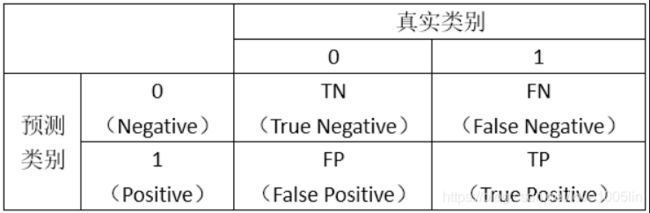
然后,我们计算两个指标的值:
True Positive Rate=TP/(TP+FN),代表将真实正样本划分为正样本的概率
False Positive Rate=FP/(FP+TN),代表将真实负样本划分为正样本的概率
接着,我们以“True Positive Rate”作为纵轴,以“False Positive Rate”作为横轴,画出ROC曲线。类似下图:

实现代码:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#y是类别
y = np.array([1,1,1,1,1,1,0,0,0,1,1,0,0,1,1,0,0,1,1,0,0])
# prob 为得到的预测结果
prob =np.array( [0.42,0.73,0.55,0.37,0.57,0.70,0.25,0.23,0.46,0.62,0.76,0.46,0.55,0.56,0.56,0.38,0.37,0.73,0.77,0.21,0.39])
from sklearn.metrics import roc_curve,auc
#roc_cure()是绘制roc曲线,返回值为fpr,tpr,thredholds
fpr,tpr,thredholds = roc_curve(y,prob)
#auc计算roc曲线下的面积
auc_=auc(fpr,tpr)
plt.plot(fpr,tpr)
plt.legend(['auc:%0.2f'%(auc_)])
