1.1. 字符编码
1.1.1. 字符编码的作用
计算机只认识0和1组成的二进制序列,因此任何文件中的内容(比如"hello neuedu","你好,东软睿道"这些字符串)要想被计算机识别或者想存储在计算机上都需要转换为二进制序列。那么字符与二进制序列怎么进行相互转换呢?于是人们尝试建立一个表格来存储一个字符与一个二进制序列的对应关系。
- 编码 将字符转换为对应的二进制序列的过程叫做字符编码
- 解码 将二进制序列转换为对应的字符的过程叫做字符解码
1.2. 字符编码的简单发展历史
1.2.1. ASCII码诞生
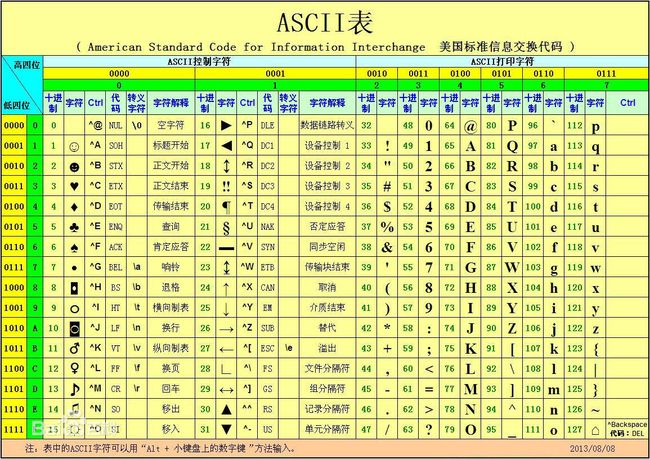
最早建立这个字符与十进制数字对应的关系的是美国,这张表被称为ASCII码(American Standard Code for Information Interface, 美国标准信息交换代码)。ASCII码是基于拉丁字母的一套电脑编程系统,主要用于显示现代英语和其他西欧语言。它被设计为用1个字节来表示一个字符,所以ASCII码表最多只能表示2**8=256个字符。实际上ASCII码表中只有128个字符,剩余的128个字符是预留扩展用的。
1.2.2. GBK等各国编码诞生
随着计算机的普及和发展,很过国家都开始使用计算机。大家发现ASCII码预留的128个位置根本无法存储自己国家的文字和字符,因此各个国家开始制定各自的字符编码表,其中中国的的字符编码表有GB2312和GBK。
1.2.3. Unicode诞生(万国码)
后来随着世界互联网的形成和发展,各国的人们开始有了互相交流的需要。但是这个时候就存在一个问题,每个国家所使用的字符编码表都是不同的。这个时候,人们希望有一个世界统一的字符编码表来存放所有国家所使用的文字和符号,这就是Unicode。Unicode又被称为 统一码、万国码、单一码,它是为了解决传统的字符编码方案的局限性而产生的,它为每种语言中的每个字符设定了统一并且为之一的二进制编码。Unicode规定所有的字符和符号最少由2个字节(16位)来表示,所以Unicode码可以表示的最少字符个数为2**16=65536。
1.2.4. UTF-8诞生
为什么已经有了Unicode还要UTF-8呢?因为美国人不乐意了,由于当时存储设备是非常昂贵的,而Unicode中规定所有字符最少要由2个字节表示。美国人认为像原来ASCII码中的字符用1个字节就可以了,因此决定创建一个新的字符编码来节省存储空间。UTF-8是对Unicode编码的压缩和优化,它不在要求最少使用2个字节,而是将所有字符和符号进行分类:
- ascii码中的内容用1个字节保存
- 欧洲的字符用2个字节保存
- 东亚的字符用3个字节保存
- ...
UTF-8是目前最常用,也是被推荐使用的字符编码。
1.3. 字符串和字节序列的转换
1.3.1. 字符串转字节序列
bytes = '张三'.encode()
print(bytes)
print(type(bytes))
bytes = '张三'.encode('utf-8')
print(bytes)
print(type(bytes))
bytes = '张三'.encode('gbk')
print(bytes)
print(type(bytes))
输出
b'\xe5\xbc\xa0\xe4\xb8\x89'
b'\xe5\xbc\xa0\xe4\xb8\x89'
b'\xd5\xc5\xc8\xfd'
encode默认按utf-8编码
1.3.2. 字节序列转字符串
bytes = b'\xe5\xbc\xa0\xe4\xb8\x89'
msg1 = bytes.decode()
print(msg1)
print(type(msg1))
msg1 = bytes.decode('utf-8')
print(msg1)
print(type(msg1))
msg1 = bytes.decode('gbk')
print(msg1)
print(type(msg1))
输出
张三
张三
寮犱笁
1.4. 文件的概念和作用
- 计算机的 文件,就是存储在硬盘上的 数据
1.5. 文件的存储方式
- 在计算机中,文件是以 二进制 的方式保存在磁盘上的
1.5.1. 文本文件和二进制文件
-
文本文件(字符串)
- 可以使用 文本编辑软件 查看
- 本质上还是二进制文件
- 例如:python 的源程序
-
二进制文件
- 保存的内容 不是给人直接阅读的,而是 提供给其他软件使用的
- 例如:图片文件、音频文件、视频文件等等
- 二进制文件不能使用 文本编辑软件 查看
1.6. 文件的基本操作
1.6.1. 操作文件的套路
在 计算机 中要操作文件的套路非常固定,一共包含三个步骤:
- 打开文件
- 读、写文件
- 读 将文件内容读入内存
- 写 将内存内容写入文件
- 关闭文件
1.6.2. 操作文件的函数/方法
- 在
Python中要操作文件需要记住 1 个函数和 3 个方法
| 序号 | 函数/方法 | 说明 |
|---|---|---|
| 01 | open | 打开文件,并且返回文件操作对象 |
| 02 | read | 将文件内容读取到内存 |
| 03 | write | 将指定内容写入文件 |
| 04 | close | 关闭文件 |
-
open函数负责打开文件,并且返回文件对象 -
read/write/close三个方法都需要通过 文件对象 来调用
1.6.3. read 方法 —— 读取文件
-
open函数的第一个参数是要打开的文件名(文件名区分大小写)- 如果文件 存在,返回 文件操作对象
- 如果文件 不存在,会 抛出异常
-
read方法可以一次性 读入 并 返回 文件的 所有内容 -
close方法负责 关闭文件- 如果 忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问 新建一个demo.txt文件,输入neuedu,放到和readfile.py同级目录下
readfile.py
# 1\. 打开 - 文件名需要注意大小写
file = open("demo.txt")
print(file)
# 2\. 读取
text = file.read()
print(text)
# 3\. 关闭
file.close()
输出
<_io.TextIOWrapper name='demo.txt' mode='r' encoding='cp936'>
neuedu
新建一个demo2.txt文件,输入东软睿道,保存为utf-8模式,放到和readfile.py同级目录下 readfile.py
# 1\. 打开 - 文件名需要注意大小写
file = open("demo2.txt")
print(file)
# 2\. 读取
text = file.read()
print(text)
# 3\. 关闭
file.close()
输出
<_io.TextIOWrapper name='demo2.txt' mode='r' encoding='cp936'>
涓滆蒋鐫块亾
可见发生了中文乱码问题。
上面代码发生的过程是将存储在文件中的字符串,读取到变量中(内存中),这里涉及的事情的先后顺序是这样的,理解这些非常重要:
1.最开始,我们用某个编辑软件(记事本程序),编辑了"东软睿道"四个字符,按utf-8编码方式保存到磁盘上,此处放生了编码过程(字符串--->字节)。 2.接下来我们通过上面的python代码,打开(open)文件,此时将存储在文件中的字符串(字节,二进制),读取到变量中(内存中),转换成字符串。这会发生一个解码过程(字节--->字符串)。Python默认是按照什么编码方式解码的呢,输出信息给出了答案
<_io.TextIOWrapper name='demo2.txt' mode='r' encoding='cp936'>
open函数返回的是TextIOWrapper类型的文件对象,cp936是默认的文本编码格式(gb2312) 说明文件打开时默认按gb2312编码方式进行解码。编码和解码的方式不同,故而发生乱码。
解决办法有2个: 1.记事本编辑完保存时,按'gb2312'方式保存到磁盘(ANSI)
2.文件打开时指定编码方式为utf-8:
# 1\. 打开 - 文件名需要注意大小写
file = open("demo2.txt",encoding='utf-8')
print(file)
# 2\. 读取
text = file.read()
print(text)
# 3\. 关闭
file.close()
输出
<_io.TextIOWrapper name='demo2.txt' mode='r' encoding='utf-8'>
东软睿道
1.6.4. write 方法 —— 写入文件
写入文件示例
# 打开文件
f = open("abc.txt", "w")
print(f)
f.write("hello neuedu!\n")
f.write("今天天气真好")
# 关闭文件
f.close()
查看abc.txt
hello neuedu!
今天天气真好
如果看到的的中文是乱码,确认是否是以记事本程序打开,如果是用pycharm打开,看到的是乱码,和读文件是同样的道理,python默认是以gb2312的方式将中文编码,写入到文件中,pycharm默认以utf-8格式解码打开,故而看到是乱码,要想以utf-8方式将中文编码,写入到文件中,需要:
f = open("abc.txt", "w",encoding='utf-8')
注意,要想向文件中写入数据,open方法必须写上第二个参数w。
f = open("abc.txt", "w")
open方法默认以读的方式打开,以下2行代码是等价的。
f = open("abc.txt")
f = open("abc.txt","r")
所以,读文件的时候我们可以省略第二个参数r,写文件不可以省略。
1.7. read(),readline(),readlines()区别与用法
0.准备 假设a.txt的内容如下所示:
Hello
Welcome
What is the luck...
-
read([size])方法 read([size])方法从文件当前位置起读取size个字节,若无参数size,则表示读取至文件结束为止,它的返回值为字符串对象
f = open("a.txt") lines = f.read() print(lines) print(type(lines)) f.close()输出结果:
Hello Welcome What is the luck...#字符串类型 2.readline()方法 从字面意思可以看出,该方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
f = open("a.txt") line = f.readline() print(type(line)) while line: print(line) line = f.readline() f.close()输出结果:
Hello Welcome What is the luck... 3.readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存。
f = open("a.txt") lines = f.readlines() print(type(lines)) for line in lines: print(lines) f.close()输出结果:
Hello Welcome What is the luck... 4.最简单、最快速的逐行处理文本的方法:直接for循环文件对象
f = open("a.txt") for line in f: print(line) f.close()1.8. 使用 with open() as 读写文件
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
try:
f = open('a.txt', 'r')
print(f.read())
finally:
if f:
f.close()
每次都这么写实在太繁琐,所以,Python引入了with语句来自动帮我们调用close()方法:
with open('a.txt', 'r') as f:
print(f.read())
这和前面的try ... finally是一样的,但是代码更加简洁,并且不必调用f.close()方法。
1.9. 文件指针
文件指针 标记 从哪个位置开始读取数据
- 第一次打开 文件时,通常 文件指针会指向文件的开始位置
- 当执行了 read 方法后,文件指针 会移动到 读取内容的末尾
思考 如果执行了一次 read 方法,读取了所有内容,那么再次调用 read 方法,还能够获得到内容吗?
答案 不能 第一次读取之后,文件指针移动到了文件末尾,再次调用不会读取到任何的内容
控制文件指针移动 方法:f.seek(offset,whence) offset代表文件指针的偏移量,单位是字节bytes whence代表参照物,有三个取值 (1)0:参照文件的开头 (2)1:参照当前文件指针所在的位置 (3)2:参照文件末尾
PS:快速移动到文件末尾f.seek(0,2) 强调:其中whence=1和whence=2只能在b 模式下使用 f.tell()函数可以得到当前文件指针的位置
with open(r'rrf.txt','rb')as f:
# f.readlines()
# f.seek(6,0) #从开头移动6个字节
# print(f.readline().decode() )
# print(f.tell() )
# with open(r'rrf.txt', 'rb')as f:
# f.readline()
# f.seek(9,1) #从当前指针位置移动9个字节
# print(f.readline() .decode() )
with open(r'rrf.txt', 'rb')as f:
f.seek(-5,2) #指针在末尾,往前读5个字节
print(f.read() .decode() )
print(f.tell())
rrf.txt
abcdefghijklmnopqrstuvwxyz
1.10. 打开文件的方式总结
-
open函数默认以 只读方式 打开文件,并且返回文件对象
语法如下:
f = open("文件名", "访问方式")
| 访问方式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。如果文件不存在,抛出异常 |
| w | 以只写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a | 以追加方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
| r+ | 以读写方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常 |
| w+ | 以读写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
| a+ | 以读写方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
思考 在使用python的open函数对文件进行打开时,
- 用什么模式打开才最合适?
- 是用r? 还是w? 还是a? ,后面还要不要加个+???
- 读写图片等二进制文件怎么办?
with open('test.txt','打开模式选啥?????') as w:
w.write("要写入的内容")
总结
-
已经确定要打开的文件已存在(如果不存在会报错)。
- 只读文本文件 ? 用r
- 只读非文本文件(图片等)? 用rb
- 要既读又写? 在后边添个+号增加权限, 用r+ 或者 rb+
-
不确定要打开的文件是否存在,如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被替换。如果该文件不存在,创建新文件。
- 只写文本文件 ? 用w
- 只写非文本文件(图片等)? 用wb
- 要既读又写? 在后边添个+号增加权限, 用w+ 或者 wb+
-
不确定要打开的文件是否存在,而且想要追加写入(不替换原有内容,新内容写入到已有内容后)。如果该文件不存在,创建新文件。
- 只写文本文件 ? 用a
- 只写非文本文件(图片等)? 用ab
- 要既读又写? 在后边添个+号增加权限, 用a+ 或者 ab+
1.11. 课上练习
1.11.1. 文件操作
1). 创建文件data.txt, 文件共100000行, 每行存放一个1~100之间的整数. 2). 找出文件中数字出现次数最多的10个数字, 写入文件mostNum.txt;
import random
f = open('data.txt', 'w+')
for i in range(100000):
f.write(str(random.randint(1,100)) + '\n')
print(f.read())
f.close()
from collections import Counter
dict={}
f = open('data.txt', 'r+')
for i in f:
if i not in dict:
dict[i] = 1
else:
dict[i] = dict[i] + 1
d = Counter(dict)
with open('mostNum.txt', 'w+') as k:
for i in d.most_common(10):
k.write(f'{i[0].strip()}--------{i[1]}\n')
k.seek(0, 0)
print(k.read())
f.close()
利用Counter类里的most_common方法来直接比较字典的value值取value值最大的前十个元素。
1.11.2. 添加行号
1). 编写程序, 将a.txt操作生成文件a_num.txt文件, 2). 其中文件内容与a.txt一致, 但是在每行的行首加上行号。
with open('a.txt', 'r+') as f1, open('a_num.txt', 'w+') as f2:
for i, j in enumerate(f1):
f2.write(str(i)+' '+j.strip()+'\n')
f2.seek(0, 0)
print(f2.read())
a.txt
Hello
Welcome
What is the luck...
a_num.txt
0 Hello
1 Welcome
2 What is the luck...
1.11.3. 非文本文件的读取
如果读取图片, 音乐或者视频(非文本文件), 需要通过二进制的方式进行读取与写入;b
- 读取二进制文件 rb:rb+:wb:wb+:ab:ab+:
- 读取文本文件 rt:rt+:wt:wt+:at:at+ 等价于 r:r+:w:w+:a:a+
先读取二进制文件内容, 保存在变量content里面
f1 = open("a.png", mode='rb')
content = f1.read()
f1.close()
# print(content)
f2 = open('b.png', mode='wb')
f2.write(content)
f2.close()