基于Kaldi的语音识别
cnblog: https://www.cnblogs.com/ye-buaascse/
第二十九届“冯如杯”学生学术科技作
品竞赛项目论文
基于Kaldi的语音识别
摘要
近年来随着社会的发展,人们的生活水平获得了极大的提高,各种科学技术也为了更好的服务人类而飞速发展,语音识别技术便是这股浪潮之一。语音识别技术,是一门与机器进行语音交流,让机器通过识别和理解过程把语音信号转化成相应的文本或命令的高新技术。不同领域的研究成果均对语音识别的发展做出了贡献,因此它也是一门交叉学科。
现在,语音识别已经被广泛地应用到了生活的方方面面,极大地影响并改变了人类的生活,使进入信息时代的人类社会更加便捷。例如,对于残疾的、或者手不方便的人来说,使用手机会成为他们比较大的障碍,但是有了语音识别,我们可以将人类语言转化为命令,对手机进行操作;又比如,医院失语症治疗室,每天的患者都要一个专职的治疗师进行指导和教学,我国的失语症患者人数达2000多万, 而语音识别技术恰好能代替言语治疗师,为患者进行智能诊疗。
现如今已经较为成熟的语音识别大致可分为三个部分,提取特征,建立模型和模式匹配,以及语言模型和处理。
本项目旨在利用Kaldi中当今流行的语音识别模型进行研究,并针对具体的项目需求不断改进,力图打造自己的语音识别技术。
关键字:语音,模型,卡尔迪
Abstract
In recent years, with the development of society, people's living standards have been greatly improved, and all kinds of science and technology have developed rapidly in order to better serve human beings. Speech recognition technology is one of the waves. Speech recognition technology is a high and new technology to communicate with the machine, and let the machine transform the speech signal into the corresponding text or command through the recognition and understanding process. The research results in different fields all contribute to the development of speech recognition, so it is also an interdisciplinary subject.
Now, speech recognition has been widely used in all aspects of life, greatly affecting and changing human life, making the human society more convenient in the information age. For example, for people with disabilities or inconvenient hands, using mobile phones will become a big obstacle for them. But with speech recognition, we can translate human language into commands and operate mobile phones. Another example is the aphasia treatment room in the hospital. Every day, patients need a full-time therapist for guidance and teaching. The number of aphasia patients in China is more than 20 million, and speech recognition technology can just replace speech therapists to perform intelligent diagnosis and treatment for patients.
At present, the relatively mature speech recognition can be roughly divided into three parts: feature extraction, modeling and pattern matching, and language modeling and processing.
This project aims to make use of the current popular speech recognition model in Kaldi for research, and continuously improve according to the specific project needs, trying to create their own speech recognition technology.
Keywords
Voice,Model,Kaldi
目录
第一章引言 1
第二章研究背景与现状 1
第三章语音识别概率算法 2
3.1语音的度量以及建模 2
3.2隐马尔科夫概率模型 3
3.3 MFCC提取过程 4
第四章模型训练及分析解读 6
总结 8
参考文献 9
第一章 引言
本项目结合kaldi中当今流行的语音识别模型进行研究,并针对具体的项目需求不断改进,力图打造自己的语音识别技术。
本文主要从语音识别背景介绍,模型训练关键点的分析改进,以及识别概率的生成算法的分析入手,详细阐释语音识别的技术原理以及本项目的改进思路。
第二章 研究背景与现状
为了更清晰地认识到语音识别技术究竟是什么,我将在下文给出粗略地介绍。
语音识别技术是一种时下流行的高科技技术,它与机器进行自然语言的通信,在通信过程中机器将语言转化为指令或结果。 不同领域的研究成果有助于语音识别的发展,因此它也是一门跨学科的学科。而且,其研究纪录,早在半个世纪以前,就有明确的记录,可以称得上是一门新兴技术。 大致经历了单一模式匹配、模式和特征分析、统计方法(声学模型)和自2010年起沿用至今的深度学习网络四段时期, 而发展至今的语音识别已经能够完成大部分的预期工作并成功地进行了商业化,被广泛地运用在诸如移动设备、查询系统、自动服务等领域。
现如今已经较为成熟的语音识别大致可分为三个部分,提取特征,建立模型和模式匹配,以及语言模型和处理。具体过程可以大致描述为,从连续或不连续的自然音频中提取语音特征的时变序列。 然后利用声学模型描述不同声音之间的不同特征,再利用模式匹配在声学和语言之间建立了一个映射关系,然后,建立一个特殊的语言模型,它具有一定的概率算法,能“预测”下一个单词的出现。 语音识别在以上建模的基础上在一个庞大的网络上搜索寻找可能正确的结果,从而完成这一整个语音识别的认知过程。
虽然语音识别技术现在已经被广泛运用,但是它仍然有巨大的改进空间,其缺陷依然显而易见。最容易被看出来的就是任何一种模型的正确识别率均低于公布出来识别概率,其具体表现也没有发布会上的优秀,其原因是多方面的,接下来大致介绍几点。第一,杂音的干扰;发布会上使用的是专业级别的耳麦,说话是标准的语言,这大大降低了语音识别的鲁棒性,不可能要求任何一个用户在使用设备的时候说标准的语言和带着高水平的设备,同时,也不可能要求设备的使用场合具备优秀的无杂音的环境,所以现阶段语音识别的正确率其实并没有想象的那么高;第二,口音;语音识别的训练单从结果来看很奇妙,如果只针对一个人的语音进行深度学习训练,那么最终得到的模型对这个人将具有极高的正确度,而相对的对其他人正确度就会很低,而口音正是这个问题的放大化,本地人尚且不能一次性听懂外地人的话,更何况机器;第三,多音字;同音多字,或者说复音词,是个很有趣的问题,如何得到最正确,用户最想要的结果,需要更强大的语言分析能力。以上这些都是仍需解决的问题,仍需技术人员努力。
接下来简要介绍一下,我们小组在本次探究性研究学习中运用的语音识别工具包Kaldi。Kaldi是一款基于加权有限状态及理论的,完全由C++编写的,语音识别开源软件,它具有详细的说明文档,完全公开的说明教程,使得我们选择了它作为入门的对象。而大量的模块化和高度可扩展性设计,使得它具备兼容时下最新技术发展的能力,当下阿里最新推出的DFSMN也具有完整的补丁包。
第三章 语音识别概率算法
3.1语音的度量以及建模
若要用计算机对人类的语音有读取、识别、处理、合成等功能需求,就必须要研究人类语音的产生过程,分析其原因,从而建立模型。
首先,我们了解到声音具有波形,可以通过产生的波形绘制频谱图,分析其频谱图特征,获取声音特征值,总结规律。声音信号波形可以通过傅立叶变换而分解为DC分量(即,常数)和很多个(一般是无限多个)正弦信号的和。每个正弦分量都有自己的频率和高峰值,因此,把频率值作为水平轴,峰值作为垂直轴,将上述提到的个正弦信号的峰值绘制在对应的频率上,这样绘制的分布图就是信号的幅频分布图,也称为频谱图。
声音的状态是由声带震动而发生改变的,声带完全放松时没有产生声音,如果声带一张一合(振动)就会形成周期性的脉冲气流。由于每个字的发声不同,我们能通过理解区别来辨别发声所对应的是哪个字。同样,发声不同,则形成的脉冲也会不同,那么声音的波形就会随着时间轴改变,这个波形,就是以后分析所需要的数据。
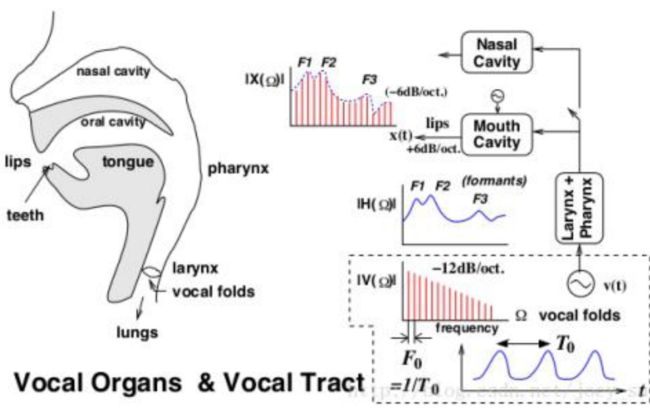
图1声音的产生
3.2隐马尔科夫概率模型
研究声学波形,我们会寻找波形图可能的概率模型,即寻找下一个状态所产生的波形图是怎样的,这就会涉及到概率模型。马尔科夫概率模型常用在统计学、概率学等领域,而我们对语音信号研究的初步就是对相应的马尔科夫链进行研究。我们所说的隐马尔科夫模型是一种由马尔可夫链导出的时间序列与状态转换的概率模型,与原本的马尔科夫模型不同的是,它是隐式的,其被解释为隐藏的序列链随机生成得到的不可推断的随机状态序列,又由每个状态得到观察,推测而产生观察序列的过程。由上述所说方法根据概率随机生成的一系列不知道且暂时不能推断的状态序列,简称为状态序列。每个状态经过一系列变换会得到对应的观察值和状态值,由此可以得到观察序列。
我们都知道马尔科夫链的组成部分,有三个部分:初始概率矩阵、转移概率矩阵、观察得到的概率分布。假设我们研究的项目状态仅与当时的状态有关,即在任何当前时间t的状态q只与其前一段时间t-1的状态相关,即:
于是该过程就是马尔科夫模型的算法过程,算法中转移概率需要满足半正定性质和归一性质[1]。
在上面所说的模型中,我们把每个状态都看做一个可观察的值,也就是可视(非隐式)的模型。但是,在许多实际应用中,我们并不知道模型所通过的状态序列。我们通常希望得到某一种较为良好的状态,但往往是不可推测的观测状态。因为状态转移概率函数我们是已知的,因此这个不可推测的过程变为双重随机过程,其中模型变换的状态被隐藏了,我们可以间接通过状态转化概率而推测其被隐藏的状态。
例如,今天是晴天,那么我们可以推断明天天气应该怎么样的概率,接着后天又可以根据明天的天气推断其概率。但是,假设现在不知道今天天气如何,而我们可以知道动植物的状态,因为动植物的状态会因为天气变化而发生改变,所以我们可以通过动植物的状态来推断今、明、后天的天气情况。
图2 天气状态转换图
而我们如何确定该概率算法呢?在隐马尔可夫模型算法中,我们设置三个参数,这几个参数对应初始概率(设置为π)、转换概率(可设置为矩阵A)以及相应的概率矩阵(设置为矩阵B),可视的观察状态与隐藏的状态间的对应关系就是对应概率矩阵,那么写成表达式,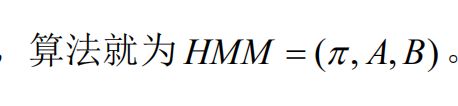
上述问题中,植物状态与天气状态就是对应关系。
3.3 MFCC提取过程
声音转换后的声音波形是模拟信号,因此,我们必须首先将声音波形转换为声学特征向量,以便很好地识别语音。也就是说,需要先分析输入的语音信号,并提取相应的特征,然后将其转化为用于描述的频谱图。我们在本文用MFCC作为识别提取。
学习模电、数电的知识后会知道模拟信号转换为数字信号主要包括两个步骤:采样和量化,即将连续的波形转换为有特定采样率和样本数量的离散数据点。下面看一下转化过程:
首先,任何信号都必须先经过预处理,才能进行识别,排除杂音,并且提高信号的强度是一些常有的步骤。Mel倒谱系数MFCC特征提取的第一步是增加声音高频部分的能量,也称预加重。我们通过阶高通滤波器来实现这个步骤,我们观察声音信号的频谱图得知,绝大多数低频率部分的能量会比高频部分的能量更高,所以必须要使得它们的能量幅值相差不会太大,尽量让两个部分互相补充[2]。总而言之,这个步骤的实现能提高识别准确率。
因为语音信号在短期时域中是静止信号,也就是说,在较短时间内我们可以把它看作是平稳的。计算分析时,我们首先需要完成整个语音信号的成帧,以便将每个帧视为平滑信号。一般声音是非平稳信号,应该没有固定的统计特性,但收集到的点在相对较短的时间内收集到一帧中后,我们认为该帧中的信号就是平滑的,这是窗口化。然而,按如上述方法加窗后,信号每个帧的开始和结束将存在不连续性。因此,我们要避免过多的划分帧,减小与原始信号的误差。窗口化是为了解决这个问题。
事实上,信号不是规范的波形,由其会出现宽频谱的信号,为了防止时域采样后这一部分所产生的频谱重叠,预滤波器通常用于滤除具有小幅度的高频分量,使得信号的带宽小于折叠频率。此外,对于持续时间很长的信号,过多的采样点会使得分析和计算变得困难。由于语音信号的时域分布很难看出信号特征,那我们应该取得什么分布图更合适呢?结果就是我们通常将它转换为频域中的分布图来以观察相应的能量信息,因为不同的能量分布代表着不同语音信号的特性。在对信号进行加窗之后,对每一帧应用快速傅里叶变换可以获得频谱中的能量分布。
上述快速傅里叶变换的结果包括每个帧带中每个帧信号的能量信息。为了更好地满足人们的听觉特性,这也是因为人类听觉对不同频带的敏感性不同,我们利用它的这个属性,来更好地区分我们研究的信号特征,从而提高识别的性能。
虽然Mel频谱本身可以作为声音的特征,但识别性能仍然需要提高。如果你使用倒谱,有一个更大的优势,你仍然可以提高识别性能。假设不经过上述步骤的转换这些操作,那么倒谱可以看作是频谱对数的频谱,也就是对频谱取对数后可视化为一个看起来像声音波形的频谱。在波形上,倒谱具有与频谱有类似的波形,并且波形通常是单调的,大体上看递增递减区间是相似的。
高斯函数在统计学领域表述为正态分布。同时在信号处理的概率模型中,也用于定义高斯滤波器。
第四章 模型训练及分析解读
我们小组在正式尝试进行语音识别的学习后经历了诸如基础知识薄弱,工程量大无从下手等难题,最终决定从Kaldi自带的thchs30训练模型开始尝试,并在成功后尝试用该模型的脚本训练阿里公布的开源的DFSMN模型,遭遇失败,因此此部分只会介绍有关thchs30的模型训练及分析解读。
Thchs30语料库,记录于2000-2001年间,设计目的为863数据库的补充,命名代表清华大学30小时中文语料库[3],它公开了一些发音词典、语言模型、相关脚本、一部分噪音数据等,接下来我们将从脚本出发解析thchs30的训练流程。
Thchs30的训练,第一步为特征提取阶段。先读取thchs30-openslr下的资料,包括.wav文件和.trn文件,生成wav. scp和txt等,然后进入提取MFCC特征阶段,而为了使每个人有不同的方式提取特征均值,其采用了倒谱均值和方差归一化方法(CMVN),采用了FilterBank分析,来提高语音识别的性能,并对分帧之后的语音,逐帧提取FBank特征。在提取特征之后,开始建立word- graph,程序解压语言模型并检查各种输入文件,然后进行处理单词、添加音素位置标记、插入消歧符等操作完成字典,建立L.. fst文件,然后根据语音模型建立G. fst文件,这两个文件均为有限状态机,可以完成词典的功能。在建立完成word- graph之后,程序开始建立phone- graph,该过程与建立word- graph类似,只是将标记单词换成了标记音素,剩余流程基本一致,也会产生相对应的L. fst和G. fst[4]。
完成初始化后,脚本程序开始训练以单音素为基础的模型。训练的核心为迭代对齐、统计GMM与HMM信息、并更新参数,然后采用刚训练得到的模型对测试数据集进行解码并计算准确度等信息,然后使用训练的模型强制对齐训练数据,并把结果定向到 Aligned Data的一个文件中。方便以后使用。之后进行三音子模型的训练,除模型的训练部分有状态绑定部分以外,其余过程与单音素模型训练一样,有解码测试和强制对齐部分。状态绑定这部分其作用是为决策树构建累积相关的统计量,大致流程为输入声学模型,打开特征文件,对每一句话的特征和对应的对齐状态调用AccumulateTreeStates()累计统计量,然后将统计量写入到文件JOB. treeacc中[5]。
接下来脚本程序采用LDA做特征调整并训练新模型,剩余步骤和之前一致。LDA,线性判别分析,是一种监督学习的降维技术,这个过程大致为估计出LDA变换矩阵,特征经LDA转换,用得到的特征重新训练GMM,计算MLLT的统计量并更新矩阵,然后更新模型的均值和转换矩阵。在得到新的特征后,脚本程序对特征进行FMLLR,训练GMM模型,随后对自适应模型进行解码和测试。然后,根据FMLLR模型,数据被对齐以实现说话人适应的目的,然后进行快速训练,并执行相关的解码测试和数据对齐,然后对齐开发数据集。于此,基于GMM-HMM的训练已经全部完成,脚本之后是关于DNN-HMM的训练,而限于硬件条件不足,关于深度学习的部分我们小组未能完成,此处仅为大致介绍[6]。
然而基于GMM-HMM的语音识别架构,较为基础,建模能力上限较低,对数据之间较为高级的相关性,其捕捉能力差,难满足更高的要求。DNN-HMM系统利用了DNN强大的性能学习能力和HMM的串行建模功能。大多数任务都超出了GMM模型。而在该脚本中不仅使用了DNN训练三音素的语音模型和进行了带有噪音的预料训练[7]。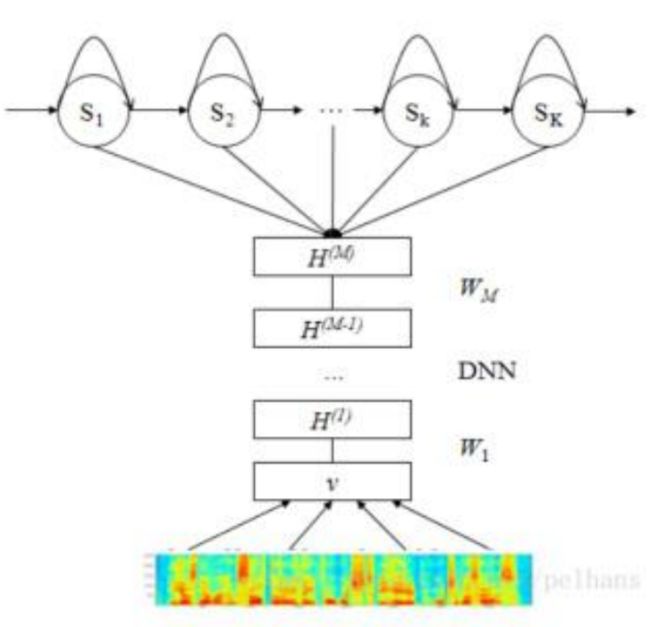
图 3 DNN-HMM系统结构图
关于thchs30的内容深究起来还有很多,但限于能力和硬件条件不足,我们小组对于thchs30的探索只好止步于此,以上便是我们从脚本出发对thchs30语料库训练的理解。
总结
到此次项目完成之时,我们小组了解许多语音识别的技术,知道了计算机是如何将语音信号转化为数学模型进行分析处理,到最后识别出来的。在此过程中,我们研究了各种用于语音识别的概率算法,即隐马尔可夫模型、梅尔倒谱系数、高斯模型和其他算法模型。
目前,语音识别已经被广泛地应用到了生活的方方面面,极大地影响并改变了人类的生活,使进入信息时代的人类社会更加便捷。例如,对于残疾的、或者手不方便的人来说,使用手机会成为他们比较大的障碍,但是有了语音识别,我们可以将人类语言转化为命令,对手机进行操作; 又比如,医院失语症治疗室,每天的患者都要一个专职的治疗师进行指导和教学,我国的失语症患者人数达2000多万, 而语音识别技术恰好能代替言语治疗师,为患者进行智能诊疗。 逐渐地,人工智能会在医疗领域扩展它的用途,语音识别必不可少。
前文所分析的概率算法,是语音识别的基础,也是关键部分,如何提高识别效果、提高识别准确率,就是研究一个好算法。当一个声音波形经过一系列的变换等后,形成一个结构清晰的数学模型,这对于整个识别带来了很大的好处,这也是我们处理信号的一个方法。
在模型训练中,我们运用了Kaldi thchs30训练流程,从简单的“yes”或“no”的识别,到DNN、DFSMN训练。当然这一过程也不是很简单,我们遇到许多问题,该训练模型需要在Linux虚拟机下运行,我们简单学习了Linux命令操作,并且该模型对CPU、GPU的要求比较高,运行起来比较费时,往往我们会遇到内存爆满、或者冲突之类的导致已经跑了一两天的模型直接奔溃掉。而我们小组锲而不舍的精神使得我们最后完成了模型的训练。
在最后,我们希望语音识别技术给人类带来更多的帮助,希望将语音识别更广泛地应用到例如失语症智能诊疗、言语治疗等领域,帮助更多需要帮助的人。
同时感谢指导老师教授以及学长学姐给予我们的指导,还有我们查阅的博客资料的博主,谢谢!
参考文献
[1]CSDN博客:HMM隐马尔可夫模型学习总结
https://blog.csdn.net/u011930705/article/details/81738096
[2]CSDN博客:语音特征MFCC提取过程详解
https://blog.csdn.net/class_brick/article/details/82743741
[3]CSDN博客:Kaldi中文语音识别thchs30模型训练
https://blog.csdn.net/Dreamy_Z/article/details/82983086
[4]Kaldi thchs30手札(一)特征提取阶段(line 0-33)
https://blog.csdn.net/pelhans/article/details/80002009
[5]CSDN博客:Kaldi thchs30手札(三)单音素模型训练(line 62-68)
https://blog.csdn.net/pelhans/article/details/80002252
[6]CSDN博客:Kaldi thchs30手札(五)LDA与MLLT(line 78-85)
https://blog.csdn.net/pelhans/article/details/80003794
[7]Kaldi thchs30手札(七)DNN-HMM模型的训练
https://blog.csdn.net/pelhans/article/details/80003880