以下对于神经网络的理解,大都来自知乎作者王小龙和YJango的回答:如何简单形象又有趣地讲解神经网络是什么?
神经网络,深度学习,都是机器学习的一个分支,最终目标还是为了实现正确分类数据的目的。
传统的机器学习方法有时需要人工的构造数据特征,来提高训练算法的效率。
比如只有一个数据X只有x1和x2两个特征时,往往会构造出x12和x22等作为数据特征一起输入。
神经网络往往不需要人为的构造数据特征,因为一个神经元就可以看做是原始数据的不同特征的组合,在神经元数目足够大,层数足够多的情况下,是很容易准确的进行分类的。
两个帮助理解神经网络的网站: ConvnetJS和A Neural Network Playground
以下从神经元的作用,一层神经元的作用,来慢慢理解神经网络。
一、神经元
1、一个神经元的作用
神经元:一个神经元,就是一个分类器。
如上公式,其中x是输入向量,y是输出向量,w是权重,b是偏移量,a()是激活函数。
训练神经元的过程,就是学习参数w和b的过程,使得通过学习的神经元能够正确分类样本点。
对于下图来说,一个神经元就可以找到最好的分开正负例的那一条线,而训练神经元的过程,就是不断调整这条线的过程。
比如下图中希望分开红绿两类点(只有一个神经元)。一开始是这种状态。
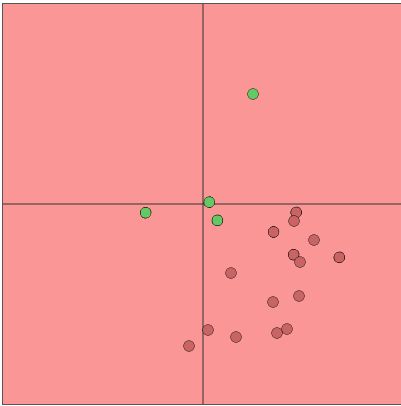
再然后开始训练,不断调整找到最佳分类要求的那条线
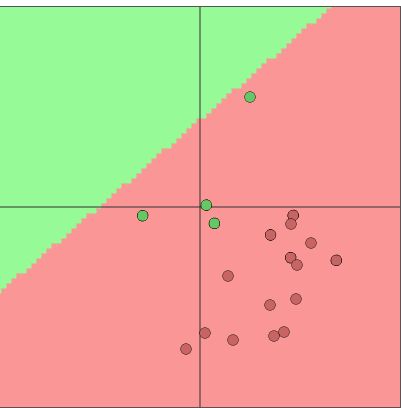
最后,达到这样的效果

最后将其通过线性变换,使得输出结果线性可分,即可以直接判断正负例。如下图所示。
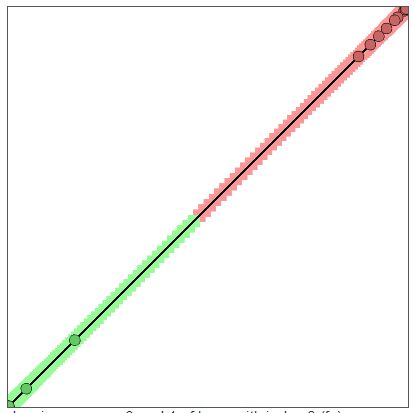
2、多个神经元的作用
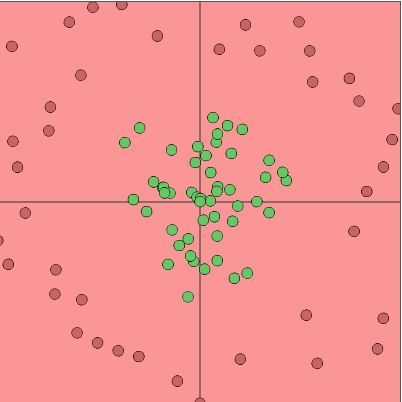
可以简单的理解为,一个神经元的作用,就是希望找到合适的下刀的地方,能够一刀分开两类样本点。如下图,一刀明显不能分开红绿点,那么就找相对比较好的地方下刀。

从上能够看出,对于不能一刀分开的情况,就需要多个神经元进行合作,把切下来的不同的平面做交、并运算。
最终再经过神经元中的激活函数的非线性变换,使得数据不再是一个平面,然后再经过线性变化,使得输出结果可以直接判断正负例。
比如这种情况。
同样是二维平面,最少需要“三刀”的组合,才能够把绿点和红点隔开。所以最简单的情况,也得是一层隐藏层,三个神经元才行。如下图所示

但是最终找到了最好的三刀也是不够的,如下左图,还需要将其分类才行。而这就是神经元的强大之处了。通过线性变换(W和b)与 非线性变换(激活函数)交替进行,使得数据最终能够线性可分,右图。

神经元的工作过程,是先对数据进行线性变换,再通过激活函数进行非线性变换。但是并不能理解成,找到了最好的“三刀”组合以后,再进行非线性变换。而是通过不断最优化损失函数,不停地调整神经元的参数(线性变换和非线性变换交替着进行的)。如下图所示,
开始调整参数,训练神经元,寻找最佳分割线。
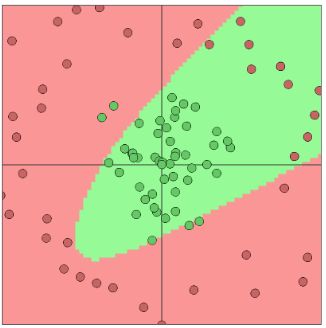
训练过程中,对二维空间进行着线性变换==> Wx+b。
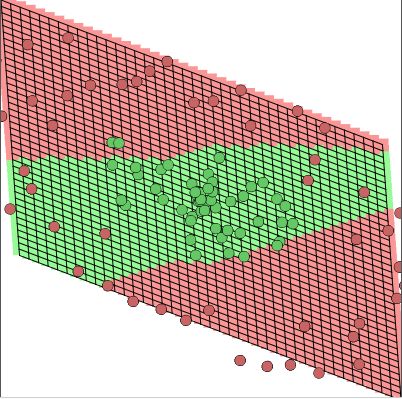
然后进行非线性变换==>a(Wx+b)。
这里的激活函数a()是sigmoid函数。

通过loss函数的反馈以及不断更新调整参数,重新调整着原平面的线性变换以及非线性变换,使得训练好的神经元达到这样的效果。
下图左侧表示此时已经找到了最好的分类边界。(可见是一个三角形,相当于切了三刀。)右侧表示左侧二维平面此时经过神经元作用以后(先线性后非线性变换)的样子。

最终,经过输出层的作用,达到线性可分的目的。

以上是对二维平面内的最简单的分类情况应用神经网络做的描述,对于异或门等更加复杂的分布,需要用到更多的神经元数以及层数。
比如螺旋式的形状进行划分的时候,就需要用多个神经元多个网络了。

二、一层神经元的作用
以下都是引用摘抄YJango的回答。
1、每一层的行为(基本变换)
每层神经网络的数学理解:用线性变换跟随着非线性变化,将输入空间投向另一个空间。
每层神经网络的物理理解:通过现有的不同物质的组合形成新物质。
2、每一层的作用
线性可分视角:神经网络的学习就是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始的输入空间投向线性可分(或稀疏的空间)去分类(或回归)。
增加节点数:增加维度,增加线性转换能力。增加层数:增加激活函数的个数,即增加非线性转换次数。
物质组成视角:神经网络的学习过程就是学习物质组成方式的过程。
增加节点数:增加同一层物质的种类。增加层数:增加更多层级,并通过判断更抽象的概念来识别物体。
比如,图像识别中,第二层网络表示的是“纹理”,增加节点数就是增加“细化的纹理的种类”,比如增加了布纹,刻纹。增加层数,就是增加了一个抽象的概念,比如再加一层,那么第三层网络可能表示的是“光”,比如灯光,等。
三、神经网络的训练
1、收集数据集
2、设计网络结构
设计出合理的网络结构,层数,神经元数,激活函数的设计
3、数据预处理
把收集到的数据,处理成可以直接输入网络中的形式。(一般就是处理成矩阵形式)。
或者处理成再需一步,就是矩阵的形式。(因为有时全部数据都直接做成矩阵比较大,内存不够,所以不能直接处理成矩阵。于是处理成友好的数据形式,在读取一小部分数据的时候,可以一步就变成矩阵,从而直接输入到网络中。)
4、权重初始化
选择初始化时,W矩阵符合的分布,b的初值。
5、训练网络
5.1. 正向传递,算当前网络的预测值
将batch_size个数据(矩阵形式)直接输入到网络中,得到batch_size个输出的预测值。
5.2. 计算loss
通过计算预测值和真实值之间的关系,得到loss。
5.3. 计算梯度
5.4. 更新权重
5.5. 预测新值
比如,在batch_size设置为128的网络中。
- 1 先用前面的第一批数据(batch_size个数据)经过W和b的运算,得到一个预测值X1。
- 2 loss为每个输入数据的预测值与真实值的函数 之和或者平均值。然后用loss更新一次W和b
- 3 再用第二批数据(新的batch_size个数据)与W和b运算,得到一个新的预测值X2。
- 4 利用X2再得到新的loss,再更新得到新的W和b。然后再用第三批数据 。。。如此直到整个数据集遍历完,算是循环了一次。