小编在深圳申请了公租房,虽然可以通过深圳市住房和建设局网站查询到排位信息,却无法直观看出同样资格人群里自己的排名。 于是决定用python爬取轮候库数据,解决这个问题。
爬取说明
爬取网址:http://www.szjs.gov.cn/bsfw/zdyw_1/zfbz/gxfgs/

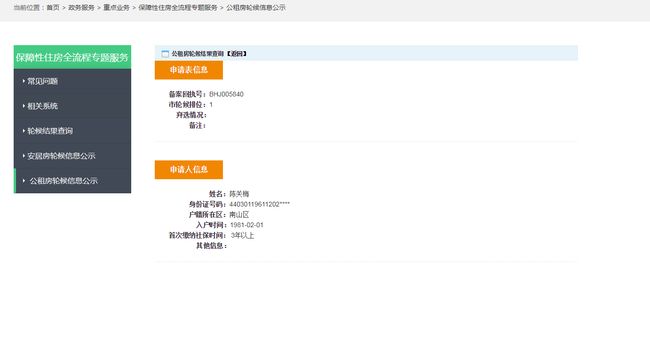
2018年9月30日爬取结果data.txt
3955877,1,BHJ005840,1,南山区
3955878,2,BHJ005866,1,南山区
3955879,3,BHJ021327,2,南山区
3955880,4,BHJ005848,1,南山区
3955881,5,BHJ006961,4,南山区
3955882,6,BHJ016656,1,南山区
3955883,7,BHJ002199,1,南山区
3955884,8,BHJ029628,3,罗湖区
3955885,9,BHJ016179,3,盐田区
3955886,10,BHJ022242,1,罗湖区
数据分为5列,依次为:用户唯一标识(可以忽略)、排位、备案号、申请人数、户籍所在区。
此次先简单手工将数据文件导入mysql数据库,再用sql检索结果。
后续学习计划:
使用python将文本数据导入mysql;
使用ELK,将数据导入elasticsearch,通过kibana展示分析;
做成在线功能放在的公众号(id:jintianbufaban),让非IT人员使用;
scrapy爬取公租房数据
安装scrapy不再赘述,开始爬取功能开发。
第一步:创建爬虫项目,命名为sz_security_housing
scrapy startproject sz_security_housing
下面是运行后的scrapy工程结构:

第二步:配置items文件items.py
# -*- coding: utf-8 -*-
import scrapy
class SzSecurityHousingItem(scrapy.Item):
#用户唯一id
userid = scrapy.Field()
#轮候排位
seqno = scrapy.Field()
#备案回执好
applyNo = scrapy.Field()
#申请人数
num = scrapy.Field()
#户籍所在地
place = scrapy.Field()
第三步:在spiders文件夹中新建sz_security_housing.py
# -*- coding: utf-8 -*-
import scrapy
from sz_security_housing.items import SzSecurityHousingItem
from scrapy.http import FormRequest
import json
import time
class SzSecurityHousingSpider(scrapy.Spider):
#爬虫名,启动爬虫使用
name = 'szsh'
#爬虫域
allowed_domains = ['szjs.gov.cn']
def start_requests(self):
url = 'http://bzflh.szjs.gov.cn/TylhW/lhmcAction.do?method=queryYgbLhmcList'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'bzflh.szjs.gov.cn',
'Origin': 'http://bzflh.szjs.gov.cn',
'Referer': 'http://bzflh.szjs.gov.cn/TylhW/lhmcAction.do?method=queryYgbLhmcInfo&waittype=2',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
yield scrapy.FormRequest(
url = url,
headers = headers,
formdata = {"pageNumber" : "1", "pageSize" : "10","waittype":"2","num":"0","shoulbahzh":"","xingm":"","idcard":""},
meta={'pageNum':1,'pageSize':10,"headers":headers},
callback = self.parse
)
def parse(self,response):
item=SzSecurityHousingItem()
data = json.loads(response.body_as_unicode())
# print(data)
total = data["total"]
# print(total)
list = data["rows"]
for value in list:
item['userid']=value['LHMC_ID']
item['seqno']=value['PAIX']
item['applyNo']=value['SHOULHZH']
yield item
url = 'http://bzflh.szjs.gov.cn/TylhW/lhmcAction.do?method=queryYgbLhmcList'
meta=response.meta
prepageNumber=meta["pageNum"]
pageSize=meta["pageSize"]
headers=meta["headers"]
print('finsh scrapy pageNumber:%s'%prepageNumber)
print(len(list))
time.sleep( 2 )
pageNumber=prepageNumber+1
if len(list) == pageSize:
requestdata={"pageNumber" : "1", "pageSize" : "1000","waittype":"2","num":"0","shoulbahzh":"","xingm":"","idcard":""}
requestdata['pageNumber']=str(pageNumber)
requestdata['pageSize']=str(pageSize)
meta['pageNum']=pageNumber
# print(requestdata)
yield scrapy.FormRequest(
url = url,
headers = headers,
formdata =requestdata,
meta=meta,
callback = self.parse
)
第四步:配置管道文件pipelines.py
# -*- coding: utf-8 -*-
from urllib import request
from lxml import etree
import re
class SzSecurityHousingPipeline(object):
def process_item(self, item, spider):
print(item)
url='http://bzflh.szjs.gov.cn/TylhW/lhmcAction.do?method=queryDetailLhc&lhmcId=%s&waittype=2'%(item['userid'])
print(url)
try:
response = request.urlopen(url,timeout=5)
page = response.read()
page = page.decode('utf-8')
selector = etree.HTML(page)
content=selector.xpath('//div[@class="leader_intro1"]')[1].xpath('string(.)')
place = re.search('户籍所在区.*区',content).group().replace('户籍所在区:','')
item['place']=place
num=len(selector.xpath('//div[@class="leader_intro1"]'))-1
item['num']=num
except Exception:
print ("Error:%s"%(item['seqno']))
else:
print ("Success:%s"%(item['seqno']))
ret=str(item['userid'])+','+str(item['seqno'])+","+str(item['applyNo'])+","+str(item['num'])+","+str(item['place'])+"\n"
saveFile = open('data.txt','a')
saveFile.write(ret)
saveFile.close()
# print(item)
第五步:配置settings.py
BOT_NAME = 'sz_security_housing'
SPIDER_MODULES = ['sz_security_housing.spiders']
NEWSPIDER_MODULE = 'sz_security_housing.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'sz_security_housing (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'sz_security_housing.pipelines.SzSecurityHousingPipeline': 300,
}
第六步:在项目根目录运行程序,运行结果保存在data.txt
scrapy crawl szsh

爬取结果data.txt
3955877,1,BHJ005840,1,南山区
3955878,2,BHJ005866,1,南山区
3955879,3,BHJ021327,2,南山区
3955880,4,BHJ005848,1,南山区
3955881,5,BHJ006961,4,南山区
3955882,6,BHJ016656,1,南山区
3955883,7,BHJ002199,1,南山区
3955884,8,BHJ029628,3,罗湖区
3955885,9,BHJ016179,3,盐田区
3955886,10,BHJ022242,1,罗湖区
爬虫结果分析
第一步:数据导入mysql
在mysql中建表T_PRH_DATA
CREATE TABLE `T_PRH_DATA` (
`USER_ID` int(20) unsigned NOT NULL COMMENT '用户ID',
`SEQ_NO` int(20) NOT NULL COMMENT '轮候排位',
`APPLY_NO` varchar(20) NOT NULL DEFAULT '' COMMENT '备案号',
`NUM` tinyint(4) NOT NULL DEFAULT 0 COMMENT '申请人数',
`PLACE` varchar(20) NOT NULL DEFAULT '' COMMENT '户籍所在区',
PRIMARY KEY (`USER_ID`),
KEY `INDEX_APPLY_NO` (`APPLY_NO`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='轮候信息'
导入mysql,这里我以Navicat为例:




剩余的直接下一步,至此数据导入到mysql。
第二步:查询户籍区排名
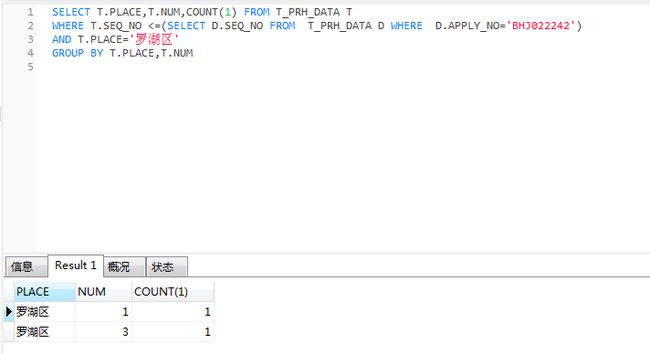
SELECT T.PLACE,T.NUM,COUNT(1) FROM T_PRH_DATA T
WHERE T.SEQ_NO <=(SELECT D.SEQ_NO FROM T_PRH_DATA D WHERE D.APPLY_NO='备案号')
AND T.PLACE='户籍所在区'
GROUP BY T.PLACE,T.NUM
这里排序第10个为例,他(她)属于罗湖区、备案号:BHJ022242
以上这是这次的所有内容,源码地址:https://github.com/tianduo4/sz_security_housing
这是学习python的第一个练手项目,做的不好的请多多包涵。 使用过程中遇到问题,或者有更好建议欢迎留言。