Scrapy 爬取伯乐在线
项目介绍
使用Scrapy框架进行爬取伯乐在线的所有技术文章
所用知识点
- Scrapy项目的创建
- Scrapy框架Shell命令的使用
- Scrapy自带的图片下载管道
- Scrapy自定义图片下载管道(继承自带的管道)
- Scrapy框架ItemLoader的使用
- Scrapy自定义ItemLoader
- Scrapy中同步将Item保存入Mysq数据库
- Scrapy中异步将Item保存入Mysq数据库
项目初始
创建新项目
scrapy startproject bole
创建爬虫
scrapy
genspider
jobbole
blog
.jobbole.com
爬虫调试
为了方便对爬虫进行调试,在项目目录中创建一个main.py文件
from
scrapy.cmdline
import
execute
import
sys,os
# 将项目目录动态设置到环境变量中
# os.path.abspath(__file__) 获取main.py的路径
# os.path.dirname(os.path.abspath(__file__) 获取main.py所处目录的上一级目录
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute([
'scrapy'
,
'crawl'
,
'jobbole'
])
在爬虫开始运行时,建议修改项目中的配置文件,找到
ROBOTSTXT_OBEY
将其改为False,如果不修改的话,Scrapy会自动的查找网站的ROBOTS协议,会过滤不符合协议的URL
在windows环境下可能会出现
No moudle named 'win32api'
,因此需要执行
pip install pypiwin32
如果下载速度过慢可使用豆瓣源进行安装
pip install -i
https://pypi.douban.com/simple
pypiwin32
前置知识
XPath语法简介
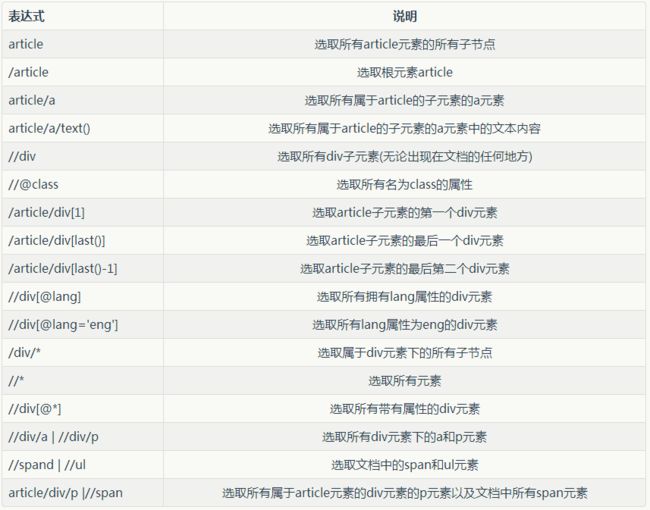
CSS常用选择器
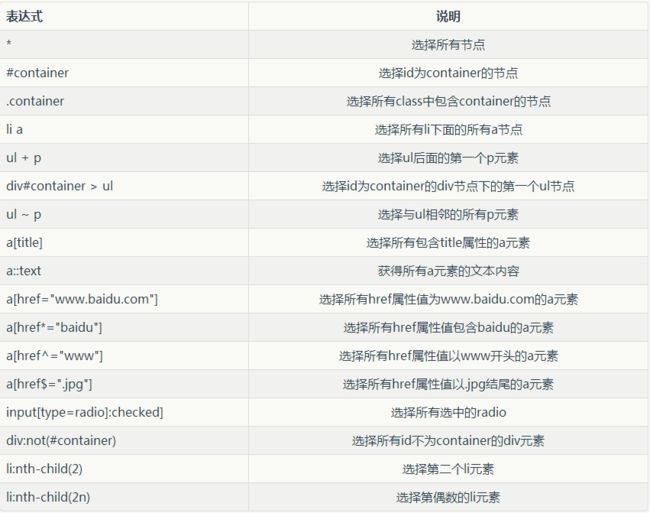
Scrapy shell模式
在解析页面的时候如果要查看运行结果则必须要运行Scrapy爬虫发起一个请求,而Scrapy提供了一种方便的调试方法可以只请求一次。
scrpay shell http:
//blog.jobbole.com/111144/
文章解析
文章详情页
Xpath的解析方式
def
parse_detail
(self, response):
# xpath方式进行解析
# 文章标题
title = response.xpath(
'//div[@class="entry-header"]/h1/text()'
).extract_first()
# 发布时间
create_time = response.xpath(
'//p[@class="entry-meta-hide-on-mobile"]/text()'
).extract_first().replace(
'·'
,
''
).strip()
# 点赞数
# contains函数是找到class中存在vote-post-up这个类
up_num = response.xpath(
'//span[contains(@class,"vote-post-up")]/h10/text()'
).extract_first()
# 收藏数
fav_num = response.xpath(
'//span[contains(@class,"bookmark-btn")]/text()'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
,fav_num)
if
match_re:
fav_num = match_re.group(
1
)
else
:
fav_num =
0
# 评论数
comment_num = response.xpath(
'//a[@href="#article-comment"]/span/text()'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
, comment_num)
if
match_re:
comment_num = match_re.group(
1
)
else
:
comment_num =
0
# 文章正文
content = response.xpath(
'//div[@class="entry"]'
).extract_first()
# 获取标签
tags_list = response.xpath(
'//p[@class="entry-meta-hide-on-mobile"]/a/text()'
).extract()
tags_list = [element
for
element
in
tags_list
if
not
element.strip().endswith(
'评论'
)]
tags =
","
.join(tags_list)
CSS解析方式
def
parse_detail
(self, response):
# CSS方式进行解析
# 文章标题
title = response.css(
'div.entry-header h1::text'
).extract_first()
# 发布时间
create_time = response.css(
'p.entry-meta-hide-on-mobile::text'
).extract_first().replace(
'·'
,
''
).strip()
# 点赞数
up_num = response.css(
'span.vote-post-up h10::text'
).extract_first()
# 收藏数
fav_num = response.css(
'span.bookmark-btn::text'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
,fav_num)
if
match_re:
fav_num = match_re.group(
1
)
else
:
fav_num =
0
# 评论数
comment_num = response.css(
'a[href="#article-comment"] span::text'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
, comment_num)
if
match_re:
comment_num = match_re.group(
1
)
else
:
comment_num =
0
# 文章正文
content = response.css(
'div.entry'
).extract_first()
# 获取标签
tags_list = response.css(
'p.entry-meta-hide-on-mobile a::text'
).extract()
tags_list = [element
for
element
in
tags_list
if
not
element.strip().endswith(
'评论'
)]
tags =
","
.join(tags_list)
列表页
def
parse
(self, response):
# 获取文章列表中的每一篇文章的url交给Scrapy下载并解析
article_nodes = response.css(
'div#archive .floated-thumb .post-thumb a'
)
for
article_node
in
article_nodes:
# 解析每个文章的封面图
font_image_url = article_node.css(
'img::attr(src)'
).extract_first(
""
)
# 解析每个文章的url
article_url = article_node.css(
'::attr(href)'
).extract_first(
""
)
# 智能对url进行拼接,如果url中不带有域名则会自动添加域名
# 通过在Request中设置meta信息来进行数据的传递
yield
Request(url=parse.urljoin(response.url, article_url),meta={
'font_image_url'
:parse.urljoin(response.url, font_image_url)}, callback=self.parse_detail)
# 获取文章的下一页url地址,并交给自身解析
next_url = response.css(
'a.next.page-numbers::attr(href)'
).extract_first(
''
)
if
next_url:
yield
Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def
parse_detail
(self, response):
article_item = JobBoleArticleItem()
# 从response中获取数据
# 文章封面图
font_image_url = response.meta.get(
'font_image_url'
,
''
)
# CSS方式进行解析
# 文章标题
title = response.css(
'div.entry-header h1::text'
).extract_first()
# 发布时间
create_time = response.css(
'p.entry-meta-hide-on-mobile::text'
).extract_first().replace(
'·'
,
''
).strip()
# 点赞数
up_num = response.css(
'span.vote-post-up h10::text'
).extract_first()
# 收藏数
fav_num = response.css(
'span.bookmark-btn::text'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
,fav_num)
if
match_re:
fav_num = match_re.group(
1
)
else
:
fav_num =
0
# 评论数
comment_num = response.css(
'a[href="#article-comment"] span::text'
).extract_first()
match_re = re.match(
'.*?(\d+).*'
, comment_num)
if
match_re:
comment_num = match_re.group(
1
)
else
:
comment_num =
0
# 文章正文
content = response.css(
'div.entry'
).extract_first()
# 获取标签
tags_list = response.css(
'p.entry-meta-hide-on-mobile a::text'
).extract()
tags_list = [element
for
element
in
tags_list
if
not
element.strip().endswith(
'评论'
)]
tags =
","
.join(tags_list)
article_item[
"title"
] = title
article_item[
"create_time"
] = create_time
article_item[
"url"
] = response.url
article_item[
"font_image_url"
] = [font_image_url]
article_item[
"up_num"
] = up_num
article_item[
"fav_num"
] = fav_num
article_item[
"comment_num"
] = comment_num
article_item[
"content"
] = content
article_item[
"tags"
] = tags
yield
article_item
定义Items
class
JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_time = scrapy.Field()
url = scrapy.Field()
url_object_id = scrapy.Field()
font_image_url = scrapy.Field()
font_image_path = scrapy.Field()
up_num = scrapy.Field()
fav_num = scrapy.Field()
comment_num = scrapy.Field()
tags = scrapy.Field()
content = scrapy.Field()
pipeline管道的使用
Scrapy自带的图片下载管道
在settings.py中的pipeline处添加 scrapy.pipeline.images.ImagesPipeline
ITEM_PIPELINES = {
'bole.pipelines.BolePipeline'
:
300
,
'scrapy.pipeline.images.ImagesPipeline'
:
200
}
# 设置图片url的字段,scraoy将从item中找出此字段进行图片下载
IMAGES_URLS_FIELD =
"font_image_url"
# 设置图片下载保存的目录
project_path = os.path.abspath(os.path.dirname(
__file__
))
IMAGES_STORE = os.path.join(project_path,
"images"
)
# 表示只下载大于100x100的图片
IMAGES_MIN_HEIGHT =
100
IMAGES_MIN_WIDTH =
100
之后运行项目可能包PIL未找到,因此需要
pip install pillow
此外scrapy的图片下载默认是接受一个数组,因此在赋值的时候需要
article_item["font_image_url"] = [font_image_url]
自定义图片下载管道
虽然Scrapy自带的下载中间件很好用,但是如果我要获取图片下载后保存的路径则官方自带就不能满足需求,因此需要我们自定义管道
# 自定义图片下载处理的中间件
class
ArticleImagePipeline(ImagesPipeline):
# 重载函数,改写item处理完成的函数
def
item_completed
(self, results, item, info):
for
key, value
in
results:
font_image_path = value[
"path"
]
item[
"font_image_path"
] = font_image_path
return
item
使用Scrapy自带的管道将Item导出成Json文件
from scrapy.exporters import JsonItemExporter
# 使用Scrapy自带的JsonExporter将item导出为json
class JsonExportPipeline(object):
# 调用scrapy提供的JsonExporter导出json文件
def __init__(self):
self.file = open('article_export.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
# 重写Item处理
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def spider_closed(self, spider):
self.exporter.finish_exporting()
self.file.close()
自定义管道将Item保存为Json文件
import
codecs,json
# 自定义将Item导出为Json的管道
class
ArticleWithJsonPipeline(object):
# 爬虫初始化时调用
def
__init__
(self):
# 打开json文件
# 使用codecs能够解决编码方面的问题
self.file = codecs.open(
'article.json'
,
'w'
,encoding=
"utf-8"
)
# 重写Item处理
def
process_item
(self, item, spider):
# 需要关闭ensure_ascii,不然中文字符会显示不正确
lines = json.dump(dict(item), ensure_ascii=
False
)+
'\n'
# 将一行数据写入
self.file.write(lines)
return
item
# 爬虫结束时调用
def
spider_closed
(self, spider):
# 关闭文件句柄
self.file.close()
同步化将Item保存入数据库
pip install mysqlclient 安装Mysql客户端库
import
MySQLdb
# 同步机制写入数据库
class
ArticleWithMysqlPipeline(object):
def
__init__
(self):
self.conn = MySQLdb.connect(
'127.0.0.1'
,
'root'
,
'root'
,
'scrapy'
, charset=
"utf8"
, use_unicode=
True
)
self.cursor = self.conn.cursor()
def
process_item
(self, item, spider):
insert_sql =
'''
INSERT INTO
jobbole_article (title, create_time, url, url_object_id, font_image_url, comment_num, up_num, fav_num, tags, content)
VALUES
(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
'''
self.cursor.execute(insert_sql, (item[
"title"
], item[
"create_time"
], item[
"url"
], item[
"url_object_id"
], item[
"font_image_url"
][
0
],
item[
"comment_num"
], item[
"up_num"
], item[
"fav_num"
], item[
"tags"
], item[
"content"
]))
self.conn.commit()
def
spider_closed
(self, spider):
self.conn.close()
异步化将Item保存入数据库
因为Scrapy的解析速度非常快,加上文章的内容较大,因此会出现数据库的操作速度赶不上解析速度会产生阻塞,因此采用异步化的方式来进行数据的插入
import
MySQLdb.cursors
from
twisted.enterprise
import
adbapi
# 异步操作写入数据库
class
ArticleTwiterMysqlPipeline(object):
# scrapy会自动执行此方法,将setting文件中的配置读入
@classmethod
def
from_settings
(cls, settings):
param = dict(
host = settings[
"MYSQL_HOST"
],
db = settings[
"MYSQL_DBNAME"
],
user = settings[
"MYSQL_USERNAME"
],
passwd = settings[
"MYSQL_PASSWORD"
],
charset =
"utf8"
,
cursorclass = MySQLdb.cursors.DictCursor,
use_unicode =
True
)
#需要使用连接模块的模块名
dbpool = adbapi.ConnectionPool(
"MySQLdb"
, **param)
return
cls(dbpool)
def
__init__
(self, dbpool):
self.dbpool = dbpool
# 使用twisted异步将数据插入到数据库中
def
process_item
(self, item, spider):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider)
# 自定义错误处理
def
handle_error
(self, failure, item, spider):
print(failure)
print(item)
def
do_insert
(self, cursor, item):
insert_sql =
'''
INSERT INTO
jobbole_article (title, create_time, url, url_object_id, font_image_url, font_image_path, comment_num, up_num, fav_num, tags, content)
VALUES
(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
'''
cursor.execute(insert_sql, (item[
"title"
], item[
"create_time"
], item[
"url"
], item[
"url_object_id"
], item[
"font_image_url"
][
0
],
item[
"font_image_path"
], item[
"comment_num"
], item[
"up_num"
], item[
"fav_num"
], item[
"tags"
], item[
"content"
]))
项目改进
前面使用了最基本的方式来解析的文章详情页,这样使得spider的代码十分长,不容易维护,因此可以采用自定义ItemLoder的方式方便对规则的管理
spider文件的修改
class
JobboleSpider(scrapy.Spider):
# 爬虫的名称 后续启动爬虫是采用此名称
name =
"jobbole"
# 爬取允许的域名
allowed_domains = [
"blog.jobbole.com"
]
# 起始url列表 , 其中的每个URL会进入下面的parse函数进行解析
start_urls = [
'http://blog.jobbole.com/all-posts/'
]
# 列表页面的解析
def
parse
(self, response):
# 获取文章列表中的每一篇文章的url交给Scrapy下载并解析
article_nodes = response.css(
'div#archive .floated-thumb .post-thumb a'
)
for
article_node
in
article_nodes:
# 解析每个文章的封面图
font_image_url = article_node.css(
'img::attr(src)'
).extract_first(
""
)
# 解析每个文章的url
article_url = article_node.css(
'::attr(href)'
).extract_first(
""
)
# 智能对url进行拼接,如果url中不带有域名则会自动添加域名
# 通过在Request中设置meta信息来进行数据的传递
yield
Request(url=parse.urljoin(response.url, article_url),meta={
'font_image_url'
:parse.urljoin(response.url, font_image_url)}, callback=self.parse_detail)
# 获取文章的下一页url地址,并交给自身解析
next_url = response.css(
'a.next.page-numbers::attr(href)'
).extract_first(
''
)
if
next_url:
yield
Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
# 详情页面的解析
def
parse_detail
(self, response):
article_item = JobBoleArticleItem()
# 从response中获取文章封面图
font_image_url = response.meta.get(
'font_image_url'
,
''
)
item_loader = JobBoleArticleItemLoader(item=JobBoleArticleItem(),response=response)
item_loader.add_css(
'title'
,
'div.entry-header h1::text'
)
item_loader.add_css(
'create_time'
,
'p.entry-meta-hide-on-mobile::text'
)
item_loader.add_value(
'url'
, response.url)
item_loader.add_value(
'url_object_id'
, get_md5(response.url))
item_loader.add_value(
'font_image_url'
, [font_image_url])
item_loader.add_css(
'comment_num'
,
'a[href="#article-comment"] span::text'
)
item_loader.add_css(
'content'
,
'div.entry'
)
item_loader.add_css(
'tags'
,
'p.entry-meta-hide-on-mobile a::text'
)
item_loader.add_css(
'up_num'
,
'.vote-post-up h10'
)
item_loader.add_css(
'fav_num'
,
'div.post-adds > span.btn-bluet-bigger.href-style.bookmark-btn.register-user-only::text'
)
article_item = item_loader.load_item()
yield
article_item
自定义的ItemLoader
import
datetime
import
re
import
scrapy
from
scrapy.loader
import
ItemLoader
from
scrapy.loader.processors
import
MapCompose, TakeFirst, Join
# 去除文本中的点
def
remove_dote
(value):
return
value.replace(
'·'
,
''
).strip()
# 时间转换处理
def
date_convert
(value):
try
:
create_time = datetime.datetime.strptime(value,
"%Y/%m/%d"
).date()
except
Exception
as
e:
create_time = datetime.datetime.now().date()
return
create_time
# 获得数字
def
get_num
(value):
match_re = re.match(
'.*?(\d+).*'
, value)
if
match_re:
num = match_re.group(
1
)
else
:
num =
0
return
int(num)
# 获取点赞数
def
get_up_num
(value):
match_re = re.match(
'(\d+) '
, value)
if
match_re:
num = match_re.group(
1
)
else
:
num =
0
return
int(num)
# 去掉tag中的评论
def
remove_comment_tag
(value):
if
"评论"
in
value:
return
""
return
value
# 默认返回
def
return_value
(value):
return
value
# 自定义ITemLoader
class
JobBoleArticleItemLoader(ItemLoader):
# 改写默认的output_processor
default_output_processor = TakeFirst()
# 伯乐在线Item
class
JobBoleArticleItem(scrapy.Item):
title = scrapy.Field()
create_time = scrapy.Field(
# 该传入的字段值要批量处理的函数
input_processor=MapCompose(remove_dote, date_convert),
)
url = scrapy.Field()
url_object_id = scrapy.Field()
font_image_url = scrapy.Field(
output_processor = MapCompose(return_value)
)
font_image_path = scrapy.Field()
up_num = scrapy.Field(
input_processor = MapCompose(get_up_num)
)
fav_num = scrapy.Field(
input_processor=MapCompose(get_num),
)
comment_num = scrapy.Field(
input_processor=MapCompose(get_num),
)
tags = scrapy.Field(
input_processor=MapCompose(remove_comment_tag),
output_processor = Join(
','
)
)
content = scrapy.Field()
```