Python网络爬虫实战:爬取携程网酒店评价信息
这个爬虫是在一个小老弟的委托之下写的。
他需要爬取携程网上的酒店的评价数据,来做一些分词和统计方面的分析,然后来找我帮忙。
爬这个网站的时候也遇到了一些有意思的小麻烦,正好整理一下拿出来跟大家分享一下。
这次爬取过程稍微曲折,各种碰壁,最终成功的过程,还是有点意思。
所以本文我会按照自己当时爬取的思路来讲述,希望能给大家一些思路上的启发。
分析部分略长,如果赶时间可以直接拉到最下面,自取代码。
如果是想学习爬虫的话,最好还是跟着文章的思路走一遍吧。
一、明确需求
这位小老弟给我的需求是:
- 爬取携程网(https://hotels.ctrip.com/)酒店的用户评价数据,具体来讲就是要爬取【上海静安香格里拉大酒店】的评价中,出行类型为【家庭亲子】的用户的评价数据。
- 评价数据包括:昵称,房型,入住日期,评价日期,评分,评价内容。
要求很简单不是嘛,数据量也不是很大(我看了一下,也才 910 条评价,后来爬取完成之后发现其实只有 750 条左右),根本不够看的。于是,我自作主张,返了个场,在他需求的基础上添加了几条:
- 酒店不只爬一家了,要爬就爬取【北京市】的所有【四星级以上】的酒店。
- 评价数据也不止爬【家庭亲子】类型了,要爬就爬所有的评价数据。
二、分析目标网站
这里我发现新手在这里一般都有一个共有的误区,就是他们觉得爬虫都是 “通用” 的,一个网站的爬虫拿过来,网址改一下,再随便撺吧撺吧就可以爬另一个网站了。
实际上,每一个网站的爬取都是需要单独进行分析的,你需要找到目标数据是在网页上的什么位置,是通过静态还是动态的方式加载进去的,网站是否有难搞的反爬虫措施,等等,从而来制定自己爬虫的爬取策略。
一般情况下,除非两个网站是极其相似的,或者根本就是用同一个网页模板开发的,这样的话可以套用同一个爬虫来爬,否则,需要针对每个网站的特点去写对应的爬虫。
1. 酒店列表爬取
好了,话不多讲,我们先来分析一下目标网站。
首先打开携程网站,目的地选择【北京】,星级选择【四星级】和【五星级】,点击搜索。

此时网址是:https://hotels.ctrip.com/hotel/beijing1#ctm_ref=hod_hp_sb_lst
可以看到网址中只包含了 【北京】 这个信息,什么四星级五星级的筛选条件,并没有体现在 URL 中。但是从结果来看,它又是确实完成了筛选,所以筛选条件的这些参数肯定是包含在请求的某一个位置的。
继续向下看,翻到页尾,发现网站是用这种方式来实现【翻页】功能的。点击【下一页】,跳转到了第 2 页。

回头看一下 URL,居然没有一丝变化,还是:https://hotels.ctrip.com/hotel/beijing1#ctm_ref=hod_hp_sb_lst
到现在基本可以确定一件事儿了,网页中的酒店信息是通过【动态】方式加载进来的。
好,我们去抓包看一下,按 F12 召唤出【开发者工具】,切换到【Network】选项卡,然后刷新一下页面。
天哪,瞧我发现了什么!!!

在浏览器加载页面时,我抓到了一个叫【AjaxHotelList.aspx】的网络请求,而它的返回结果,恰恰就是我们页面中展示的酒店列表的信息。
果然,携程网的酒店数据,是通过 Ajax 请求动态地加载的。如果没猜错的话,刚才没找到的【四星级、五星级】筛选条件参数,以及页码的参数,应该就藏在这个 Ajax 请求的参数中吧。

如图,切换到 Headers 选项,拉到最底下(Form Data 里的参数有点多,代表了各种各样的筛选条件,不过我们不关心那些),看到了 star 和 page 两个参数。
果然如我所料!
不过不能高兴太早,为了防止网站有什么比较坑爹的反爬机制,最好先写段代码验证一下,看能否按照预期爬到数据。
这里我网络请求用的是 requests 库,数据解析用的是 json 库。
照着浏览器中开发者工具里的 Ajax 请求,把里面的 url,headers,以及 form data 搬过来填这里,发起请求,打印返回结果。
(无关的参数实在太多了,这里简化了一下,只保留了关键的三个参数,cityId,star,和 page)
-
import requests
-
import json
-
-
def fetchHotel(city, star, page):
-
-
url =
"https://hotels.ctrip.com/Domestic/Tool/AjaxHotelList.aspx"
-
headers = {
-
'Content-type':
'application/x-www-form-urlencoded; charset=UTF-8',
-
'Origin':
'https://hotels.ctrip.com',
-
'Referer':
'https://hotels.ctrip.com/hotel/beijing1',
-
'accept':
'*/*',
-
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
-
}
-
-
formData = {
-
'cityId': city,
-
'star': star,
-
'page': page,
-
}
-
-
# 发起网络请求
-
r = requests.post(url, data=formData,headers=headers)
-
r.raise_for_status()
-
r.encoding = r.apparent_encoding
-
-
# 打印 r.text 来看看是否获取到了酒店数据
-
print(r.text)
-
-
fetchHotel(
'1',
'4,5',
1)
运行一下,确实出来结果了(虽然输出一堆 “乱七八糟” 的东西,但是从中文字里还是能够看出来,数据取到了)

OK,这条路走通了,不过既然都写到这儿了,顺手把 json 给解析一下,把数据提取了吧。(免得有的小伙伴不相信)
这里我们提取 酒店名称,酒店ID 打印出来看看。
-
import requests
-
import json
-
-
def fetchHotel(city, star, page):
-
-
url =
"https://hotels.ctrip.com/Domestic/Tool/AjaxHotelList.aspx"
-
headers = {
-
'Content-type':
'application/x-www-form-urlencoded; charset=UTF-8',
-
'Origin':
'https://hotels.ctrip.com',
-
'Referer':
'https://hotels.ctrip.com/hotel/beijing1',
-
'accept':
'*/*',
-
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
-
}
-
-
formData = {
-
'cityId': city,
-
'star': star,
-
'page': page,
-
}
-
-
# 发起网络请求
-
r = requests.post(url, data=formData,headers=headers)
-
r.raise_for_status()
-
r.encoding = r.apparent_encoding
-
-
# 打印 r.text 来看看是否获取到了酒店数据
-
#print(r.text)
-
-
# 解析 json 文件,提取酒店数据
-
json_data = json.loads(r.text)[
'hotelPositionJSON']
-
-
hotelList = []
-
for item
in json_data:
-
hotelId = item[
'id']
-
hotelList.append(hotelId)
-
print(item[
'name'], hotelId)
-
-
return hotelList
-
-
fetchHotel(
'1',
'4,5',
1)
运行代码,你看!没错吧,是我们要的酒店列表。

到这里,酒店列表爬取工作,基本就跑通了。
2. 酒店评论爬取
接下来该研究研究酒店评论该怎么爬取吧。
随便打开一个酒店,进入详情页之后,找到了【酒店点评】部分。

在这里,我们可以找到需要的评论的数据,用户昵称,评分,出游类型,入住时间,评价时间,房型,评价内容等等。
继续往下翻,评论页数同样的方式翻页,而且翻页时候 URL 不变,不用说,又是 Ajax 动态加载咯。
直接 F12 召唤 开发者工具,流程很熟悉了,就讲快一点啦。于是我就抓到了评价数据的包了。
(其实很好找的啦,AjaxHotelCommentList,懂点英语的都能猜到是这个了)

不过它返回的内容格式不是 json 了,而是 html,而且没有排版,格式有点乱。
这个不要紧,去随便找一个在线代码格式化网站(http://tool.oschina.net/codeformat/html),排个版就好了。

解析 json 文件可以用 json 库,解析 HTML 文件用什么呢?我一般用 BeautifulSoup 库,贼拉好用。
这里先不急解析,先写代码验证一下,看看有没有什么坑爹的反爬机制。
同样的方法,讲 Ajax 请求中的 Url,headers 还有 formdata 里的参数都扣过来,跑一下。
-
import requests
-
-
def fetchCmts(hotel, page):
-
-
url =
"https://hotels.ctrip.com/Domestic/tool/AjaxHotelCommentList.aspx?MasterHotelID=469055&hotel=469055&NewOpenCount=0&AutoExpiredCount=0&RecordCount=5420&OpenDate=2013-12-01&card=-1&property=-1&userType=-1&productcode=&keyword=&roomName=&orderBy=2&viewVersion=c&contyped=0&eleven=12488c2f039b057861112f7bc2f1322271c415a3618cba855bcc85b09795189e&callback=CASOmTvWnCuMJeETo&_=1572277191008"
-
headers = {
-
'Content-type':
'application/x-www-form-urlencoded; charset=UTF-8',
-
'referer':
'https://hotels.ctrip.com/hotel/469055.html?isFull=F&masterhotelid=469055&hcityid=2',
-
'accept':
'*/*',
-
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
-
}
-
formData = {
-
'hotel': str(hotel),
-
'currentPage': str(page),
-
'eleven':
'12488c2f039b057861112f7bc2f1322271c415a3618cba855bcc85b09795189e',
-
'callback':
'CASOmTvWnCuMJeETo',
-
'_':
'1572277191008',
-
}
-
-
r = requests.post(url, headers=headers)
-
r.raise_for_status()
-
r.encoding =
"utf-8"
-
print(r.text)
-
-
fetchCmts(
'469055',
1)
运行代码,果然,可以获取到数据。

不过,这个可不能高兴的太早,为什么呢?
你看 Form Data 的参数中,有三个参数 eleven,callback 和 _ ,这三个的值有点奇怪,一长串看不懂的数字和字母,而且每次的值都不一样。
'_' 的值,1572277191008,这个有点熟悉,好像是时间戳,找在线工具解析一下,没错,果然是。

内心咯噔一下,坏了!
根据经验来讲,参数中带时间戳的,请求一般都是有时效性的。什么意思呢?就是这类请求的参数都是根据一定的规则动态生成的,而且一般几分钟之内就会失效。(再次运行上面的代码,果然啥也获取不到了,失效了)。
也就是说,如果我想通过 Ajax 请求去获取数据的话,我必须搞清楚这三个参数的生成规则。
而这些参数又是经过 JS 加密的,搞这个又涉及到了 JS 逆向的东西。。。
我其实去网上查过携程网酒店爬虫,想看看别人是怎么绕过这个反爬机制的。
结果搜出来的好几个结果,都是用 Selenium webdriver 爬的。那个是什么原理呢。
就是我们正常的思路,是用爬虫直接去访问网站获取数据,爬虫伪装不好的话很容易被发现;
而它们这个,相当于是爬虫操作一个真的浏览器去访问网站,对方网站看到的是真正的浏览器在访问,它怎么也想不到操作浏览器的不是人,而是一只爬虫。所以这个方法几乎可以绕过所有的反爬机制。
不过!!!!
一个爬虫玩家的尊严,不允许我使用这种低效率又无脑的方式(误,手动狗头保命)。
于是我决定硬刚 Ajax 请求!!
不过 JS 逆向哪有这么容易的,一时半会儿也搞不定(记得我第一次做 JS 逆向时,整整调试了一个礼拜的 JS 代码才搞出来),而那边小老弟要的又比较急......
正在我一筹莫展之际,看到了一张帖子,有个老哥的回答让我茅塞顿开。

对呀,网页端的不行,那就模拟手机端的来试试。
网址由 https://hotels.ctrip.com/hotel 变成了 https://m.ctrip.com/webapp/hotel 。

手机版的评论不是点页码翻页的,是划到页面底部时候自动加载下一页内容的,然后我们在 开发者工具中 成功抓到了评论数据的请求包。

再看一下它的参数列表,嗯,还好,没有奇奇怪怪的动态加密的参数了。

这次怎么样呢?写段代码验证一下吧。
-
import requests
-
-
def fetchCmts(hotel, page):
-
url =
"https://m.ctrip.com/restapi/soa2/16765/gethotelcomment?&_fxpcqlniredt=09031074110034723384"
-
headers = {
-
'Content-type':
'application/x-www-form-urlencoded; charset=UTF-8',
-
'Origin':
'https://m.ctrip.com',
-
'accept':
'*/*',
-
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
-
}
-
-
formData = {
-
'groupTypeBitMap':
'2',
-
'hotelId': str(hotel),
-
'pageIndex': str(page),
-
'pageSize':
'10',
-
'travelType':
'-1',
# -1 表示全部,家庭亲子为 30
-
}
-
-
r = requests.post(url, data=formData, headers=headers)
# formData,
-
r.raise_for_status()
-
r.encoding =
"utf-8"
-
-
return r.text
-
-
fetchCmts(
'6410223',
1)
运行程序,可以获取到结果,修改酒店编号,修改页码,再运行都没问题。
返回的结果是 json格式的,回头用 json 库解析一下,把关键数据提取出来就可以了。

事情进行到这儿,对目标网站的分析研究也就基本结束了。
酒店列表,评论数据的爬取,流程也基本跑通了,接下来只需要把代码整理一下,爬就完事儿了。
二、爬虫代码编写
前面将网站的爬取思路已经捋清楚了,而且做了些小测试也基本跑通了,接下来就是撸码环节了。
1. 获取酒店列表
我们其实也发现了,爬取评论数据时,只需要酒店ID和页码两个参数就够了,所以爬酒店列表时,我们只需要提取 酒店ID 即可。
-
import requests
-
import json
-
-
def fetchHotel(city, star, page):
-
-
url =
"https://hotels.ctrip.com/Domestic/Tool/AjaxHotelList.aspx"
-
headers = {
-
'Content-type':
'application/x-www-form-urlencoded; charset=UTF-8',
-
'Origin':
'https://hotels.ctrip.com',
-
'Referer':
'https://hotels.ctrip.com/hotel/beijing1',
-
'accept':
'*/*',
-
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
-
}
-
-
formData = {
-
'cityId': city,
-
'star': star,
-
'page': page,
-
}
-
-
# 发起网络请求
-
r = requests.post(url, data=formData,headers=headers)
-
r.raise_for_status()
-
r.encoding = r.apparent_encoding
-
-
# 解析 json 文件,提取酒店数据
-
json_data = json.loads(r.text)[
'hotelPositionJSON']
-
-
hotelList = []
-
for item
in json_data:
-
hotelId = item[
'id']
-
hotelList.append(hotelId)
-
-
return hotelList
2. 爬取评论数据
-
import requests
-
import json
-
-
def fetchCmts(hotel, page):
-
url =
"https://m.ctrip.com/restapi/soa2/16765/gethotelcomment?&_fxpcqlniredt=09031074110034723384"
-
headers = {
-
'Content-type':
'application/x-www-form-urlencoded; charset=UTF-8',
-
'Referer':
'https://m.ctrip.com/webapp/hotel/hoteldetail/dianping/'+ hotel +
'.html?&fr=detail&atime=20191027&days=1',
-
'Origin':
'https://m.ctrip.com',
-
'accept':
'*/*',
-
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
-
}
-
-
formData = {
-
'groupTypeBitMap':
'3',
-
'auth':
"",
-
'cid':
"09031074110034723384",
-
'ctok':
"",
-
'cver':
"1.0",
-
'extension':
'[]',
-
'lang':
"01",
-
'sid':
"8888",
-
'syscode':
"09",
-
'hotelId': str(hotel),
-
'needStatisticInfo':
'0',
-
'order':
'0',
-
'pageIndex': str(page),
-
'pageSize':
'10',
-
'tagId':
'0',
-
'travelType':
'-1',
-
}
-
-
r = requests.post(url, data=formData, headers=headers)
# formData,
-
r.raise_for_status()
-
r.encoding = r.apparent_encoding
-
-
json_data = json.loads(r.text)
-
-
cmtsList = []
-
hotelName = json_data[
'hotelName']
-
-
for item
in json_data[
'othersCommentList']:
-
cmt = []
-
-
userName = item[
'userNickName']
-
travelType = item[
'travelType']
-
baseRoomName = item[
'baseRoomName']
-
checkInDate = item[
'checkInDate']
-
postDate = item[
'postDate']
-
ratingPoint = item[
'ratingPoint']
-
content = item[
'content']
-
-
cmt.append(userName)
-
cmt.append(hotelName)
-
cmt.append(travelType)
-
cmt.append(baseRoomName)
-
cmt.append(checkInDate)
-
cmt.append(postDate)
-
cmt.append(ratingPoint)
-
cmt.append(content)
-
-
cmtsList.append(cmt)
-
-
return cmtsList
3. 数据保存函数
将数据保存到 csv 文件中。
-
import pandas
as pd
-
import os
-
-
def saveCmts(path, filename, data):
-
# 如果路径不存在,就创建路径
-
if
not os.path.exists(path):
-
os.makedirs(path)
-
-
# 保存文件
-
dataframe = pd.DataFrame(data)
-
dataframe.to_csv(path + filename, encoding=
'utf_8_sig', mode=
'a', index=
False, sep=
',', header=
False )
4. 爬虫调度器
由于小老弟提的要求是: 上海静安香格里拉大酒店,家庭亲子类型的,评论数据。所以,
在 fetchCmts 中,将 travelType 的值设置为 30,
'travelType': '30', # 30 表示 家庭亲子 类型
由于看到评论区内容只有九百多条, 每页显示 10 条,所以我们将页码范围设置为 1 - 100 。
-
import time
-
-
if __name__ ==
'__main__':
-
hotel =
'469055'
# 上海静安香格里拉大酒店
-
startPage =
1
-
endPage =
100
-
path =
'Data/'
-
filename =
'cmtTest.csv'
-
-
for p
in range(startPage, endPage+
1):
-
cmts = fetchCmts(hotel, p)
-
saveCmts(path, filename, cmts)
-
time.sleep(
0.5)
为了保险期间,还加了一个 sleep 函数,每爬一次歇半秒,免得因为爬取太频繁被发现。

几分钟之后,爬取完成,共爬取到 735 条数据。至此,小老弟的忙总算是帮完了。
不过,最开始也说了,我嫌爬的不过瘾,又给自己加了几条需求。
爬取北京市的,所有四星级以上酒店的,所有类型的评价数据。
-
import time
-
-
if __name__ ==
'__main__':
-
city =
'1'
-
star =
'4,5'
-
startPage =
1
-
hotelEndPage =
30
-
cmtsEndPage =
100
-
-
for page
in range(startPage, hotelEndPage +
1):
-
hotelList = fetchHotel(city, star, page)
-
for hotel
in hotelList:
-
for p
in range(startPage, cmtsEndPage +
1):
-
cmts = fetchCmts(hotel, p)
-
saveCmts(
"Data/",
"cmtTest.csv", cmts)
-
time.sleep(
1)
-
-
print(
"爬取完成")
这里偷了个懒,具体有多少酒店,每个酒店有多少评论我们不去管它了,就爬 30 页的酒店,每个酒店爬 100 页的评论,
大概就是爬 300 个酒店,每个酒店 1000 条左右的评论,差不多可以了,如果想爬更多的话,可以自行去修改页码范围。
后记
这个爬虫给了我一个新的启示,就是,遇到问题,我们要有死磕的觉悟,但是也要有灵活变通的思维。
就像这个爬虫,爬取评论信息时,PC 版网页的请求加了密不好整,那就换个途径,从手机端来获取数据。
时间也省了,事儿也办了,岂不快哉。
2019年12月18日 更新
有读者反馈说,在抓取酒店列表信息的部分,使用文章中的代码无法正常获取数据。

运行代码的结果是这样的,也不报错,就是返回的搜索结果是 0 条。
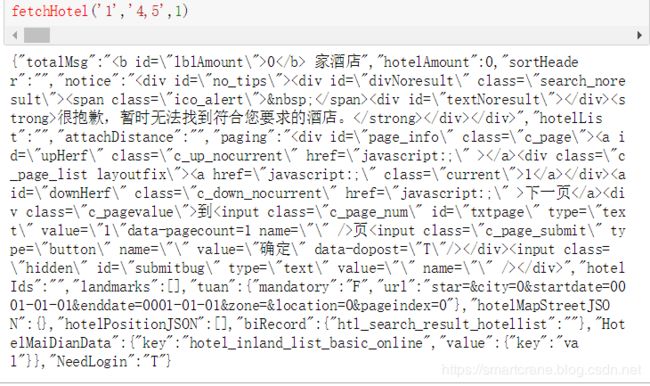
经调试发现,可能是对方服务器做了调整,需要验证 cookies 信息,只需要在 headers 中添加 cookies 参数即可。
2020年6月20日 更新
距离这个爬虫写好已经比较久了,期间对方网站也做过一些反爬机制的调整导致爬虫失效。
很多读者反馈说,前面更新时说的向 headers 中添加 cookies 的方法也失效了。经过测试,确实是,现在网站需要验证 “登陆账号后” 的 cookie 了,注意是登陆账号后的,未登录的cookie爬出来还是0条。
后续网站是否会有调整我不知道,截至本次更新时,添加登陆账号后的 cookie 后,文中的爬虫仍是有效的。(可能有些读者刚刚接触爬虫,不知道 cookie 加在哪儿,下面贴一段测试代码,大家参考)
-
import requests
-
-
def fetchCmts(hotel, page):
-
url =
"https://m.ctrip.com/restapi/soa2/16765/gethotelcomment?&_fxpcqlniredt=09031074110034723384"
-
headers = {
-
'Content-type':
'application/x-www-form-urlencoded; charset=UTF-8',
-
'Origin':
'https://m.ctrip.com',
-
'accept':
'*/*',
-
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36',
-
'cookie':
'这里放登陆账号后登陆账号后登陆账号后的cookie',
-
}
-
-
formData = {
-
'groupTypeBitMap':
'2',
-
'hotelId': str(hotel),
-
'pageIndex': str(page),
-
'pageSize':
'10',
-
'travelType':
'-1',
# -1 表示全部,家庭亲子为 30
-
}
-
-
r = requests.post(url, data=formData, headers=headers)
# formData,
-
r.raise_for_status()
-
r.encoding =
"utf-8"
-
print(r.text)
-
return r.text
-
-
fetchCmts(
'10246623',
2)
对方网站反爬机制升级,也是侧面反映了网站收到各种爬虫爬取的困扰很大。
希望大家在爬取数据时,注意控制爬取节奏,时间允许的范围内,尽量放慢爬取速度。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。
