前言
本文主要介绍直播所需要的编解码基础,后续文章将继续介绍实际的运用。
什么是码?
这里的码指码流(Data Rate),是指视频文件在单位时间内使用的数据流量,也叫码率或码流率,通俗一点的理解就是取样率,是视频编码中画面质量控制中最重要的部分,一般我们用的单位是kb/s或者Mb/s。一般来说同样分辨率下,视频文件的码流越大,压缩比就越小,画面质量就越高。码流越大,说明单位时间内取样率越大,数据流,精度就越高,处理出来的文件就越接近原始文件,图像质量越好,画质越清晰,要求播放设备的解码能力也越高。
编码
编码又分为硬编码和软编码,下面会着重介绍。
整个视频直播分为以下几个步骤:
采集—>处理—>编码和封装—>推流到服务器—>服务器流分发—>播放器流播放
如下图所示:
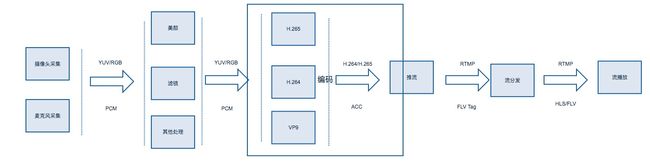
如果把整个流媒体比喻成一个物流系统,那么编解码就是其中配货和装货的过程,这个过程非常重要,它的速度和压缩比对物流系统的意义非常大,影响物流系统的整体速度和成本。同样,对流媒体传输来说,编码也非常重要,它的编码性能、编码速度和编码压缩比会直接影响整个流媒体传输的用户体验和传输成本。
为什么要编码?
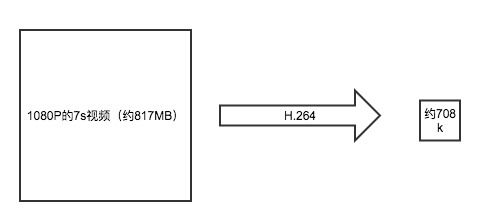
如上所示,10Mbps的带宽传输上述7s视频需要11分钟,而经过H.264编码之后,传输只需要500ms,时间上前后差距达1000多倍,可以满足实时传输的需求,所以从视频采集传感器采集来的原始视频势必要经过视频编码。
基本原理
为什么巨大的原始视频可以编码成很小的视频呢?这其中的技术是什么呢?核心思想就是去除冗余信息
- 空间冗余:图像相邻像素之间有较强的相关性
- 时间冗余:视频序列的相邻图像之间内容相似
- 编码冗余:不同像素值出现的概率不同
- 视觉冗余:人的视觉系统对某些细节不敏感
- 知识冗余:规律性的结构可由先验知识和背景知识得到
编码标准的选择
经过数十年的发展,从开始的只支持帧内编码演进到现如今的H.265和VP9为代表的新一代编码标准,下面是一些常见的视频编码标准:
- H.264/AVC
- HEVC/H.265
- VP8
- VP9
- FFmpeg
- ...
下面是一些常见的音频编码标准
- MP3
- AAC
- WMA
- PCM
- ...
封装
封装就是媒体的容器,而容器就是把编码器生成的多媒体内容(视频,音频,字幕,章节信息等)混合封装在一起的标准。容器使得不同多媒体内容同步播放变得很简单,而容器的另一个作用就是为多媒体内容提供索引,也就是说如果没有容器存在的话一部影片你只能从一开始看到最后,不能拖动进度条,而且打开的视频也没有声音。下面是几种常见的封装格式:
- AVI 格式(后缀为 .avi)
- DV-AVI 格式(后缀为 .avi)
- QuickTime File Format 格式(后缀为 .mov)
- MPEG 格式(文件后缀可以是 .mpg .mpeg .mpe .dat .vob .asf .3gp .mp4等)
- WMV 格式(后缀为.wmv .asf)
- Real Video 格式(后缀为 .rm .rmvb)
- Flash Video 格式(后缀为 .flv)
- Matroska 格式(后缀为 .mkv)
- MPEG2-TS 格式 (后缀为 .ts)
目前,我们在流媒体传输,尤其是直播中主要采用的就是 FLV 和 MPEG2-TS 格式,分别用于 RTMP/HTTP-FLV 和 HLS 协议。
硬件编码
在Android 4.1 之前,Android是没有提供硬件编码的API,所以之前都是采用FFMPEG来进行软编码的,而FFMPEG都是用C语言开发的,对于阅读源码及学习都有一定的门槛。对于同一平台,同一硬件环境,硬件编码速度快于软件编码,CPU占有率更低,所以能用硬件编码的条件下,我们尽量用硬件编码。
MediaCodec
MediaCodec类可用于访问Android底层的多媒体编解码器,例如,编码器/解码器组件。它是Android底层多媒体支持基础架构的一部分(通常与MediaExtractor, MediaSync, MediaMuxer, MediaCrypto, MediaDrm, Image, Surface, 以及AudioTrack一起使用)。
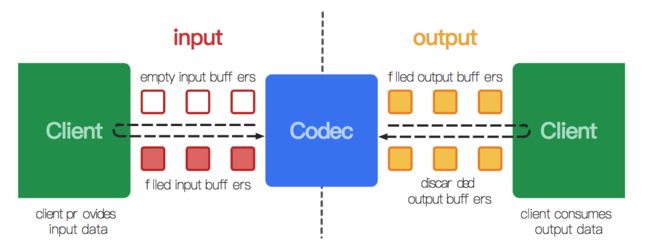
从广义上讲,编解码器就是处理输入数据来产生输出数据。MediaCodec采用异步方式处理数据,并且使用了一组输入输出缓存(input and output buffers)。简单来讲,你请求或接收到一个空的输入缓存(input buffer),向其中填充满数据并将它传递给编解码器处理。编解码器处理完这些数据并将处理结果输出至一个空的输出缓存(output buffer)中。最终,你请求或接收到一个填充了结果数据的输出缓存(output buffer),使用完其中的数据,并将其释放给编解码器再次使用。
数据类型
编解码器可以处理三种类型的数据:
- 压缩数据(即为经过H254. H265. 等编码的视频数据或AAC等编码的音频数据)
- 原始音频数据
- 原始视频数据。
三种类型的数据均可以利用ByteBuffers进行处理,但是对于原始视频数据应提供一个Surface以提高编解码器的性能。Surface直接使用本地视频数据缓存(native video buffers),而没有映射或复制数据到ByteBuffers,因此,这种方式会更加高效。在使用Surface的时候,通常不能直接访问原始视频数据,但是可以使用ImageReader类来访问非安全的解码(原始)视频帧。这仍然比使用ByteBuffers更加高效,因为一些本地缓存(native buffer)可以被映射到 direct ByteBuffers。当使用ByteBuffer模式,你可以利用Image类和getInput/OutputImage(int)方法来访问到原始视频数据帧。
压缩缓存
输入缓存(对于解码器)和输出缓存(对于编码器)中包含由多媒体格式类型决定的压缩数据。对于视频类型是单个压缩的视频帧。对于音频数据通常是单个可访问单元(一个编码的音频片段,通常包含几毫秒的遵循特定格式类型的音频数据),但这种要求也不是十分严格,一个缓存内可能包含多个可访问的音频单元。在这两种情况下,缓存不会在任意的字节边界上开始或结束,而是在帧或可访问单元的边界上开始或结束。
原始音频缓存(Raw Audio Buffers)
原始的音频数据缓存包含完整的PCM(脉冲编码调制)音频数据帧,这是每一个通道按照通道顺序的一个样本。每一个样本是一个按照本机字节顺序的16位带符号整数(16-bit signed integer in native byte order)。
short[] getSamplesForChannel(MediaCodec codec, int bufferId, int channelIx) {
ByteBuffer outputBuffer = codec.getOutputBuffer(bufferId);
MediaFormat format = codec.getOutputFormat(bufferId);
ShortBuffer samples = outputBuffer.order(ByteOrder.nativeOrder()).asShortBuffer();
int numChannels = formet.getInteger(MediaFormat.KEY_CHANNEL_COUNT);
if (channelIx < 0 || channelIx >= numChannels) {
return null;
}
short[] res = new short[samples.remaining() / numChannels];
for (int i = 0; i < res.length; ++i) {
res[i] = samples.get(i * numChannels + channelIx);
}
return res;
}
原始视频缓存(Raw Video Buffers)
在ByteBuffer模式下,视频缓存(video buffers)根据它们的颜色格式(color format)进行展现。你可以通过调用getCodecInfo().getCapabilitiesForType(…).colorFormats方法获得编解码器支持的颜色格式数组。视频编解码器可以支持三种类型的颜色格式:
- 本地原始视频格式(native raw video format):这种格式通过COLOR_FormatSurface标记,并可以与输入或输出Surface一起使用。
- 灵活的YUV缓存(flexible YUV buffers)(例如:COLOR_FormatYUV420Flexible):利用一个输入或输出Surface,或在在ByteBuffer模式下,可以通过调用getInput/OutputImage(int)方法使用这些格式。
- 其他,特定的格式(other, specific formats):通常只在ByteBuffer模式下被支持。有些颜色格式是特定供应商指定的。其他的一些被定义在 MediaCodecInfo.CodecCapabilities中。这些颜色格式同 flexible format相似,你仍然可以使用 getInput/OutputImage(int)方法。
从Android 5.1(LOLLIPOP_MR1)开始,所有的视频编解码器都支持灵活的YUV4:2:0缓存(flexible YUV 4:2:0 buffers)。
状态(state)
在编解码器的生命周期内有三种理论状态:停止态-Stopped、执行态-Executing、释放态-Released,停止状态(Stopped)包括了三种子状态:未初始化(Uninitialized)、配置(Configured)、错误(Error)。执行状态(Executing)在概念上会经历三种子状态:刷新(Flushed)、运行(Running)、流结束(End-of-Stream)。

- 当你使用任意一种工厂方法(factory methods)创建了一个编解码器,此时编解码器处于未初始化状态(Uninitialized)。首先,你需要使用configure(…)方法对编解码器进行配置,这将使编解码器转为配置状态(Configured)。然后调用start()方法使其转入执行状态(Executing)。在这种状态下你可以通过上述的缓存队列操作处理数据。
- 执行状态(Executing)包含三个子状态: 刷新(Flushed)、运行( Running) 以及流结束(End-of-Stream)。在调用start()方法后编解码器立即进入刷新子状态(Flushed),此时编解码器会拥有所有的缓存。一旦第一个输入缓存(input buffer)被移出队列,编解码器就转入运行子状态(Running),编解码器的大部分生命周期会在此状态下度过。当你将一个带有end-of-stream 标记的输入缓存入队列时,编解码器将转入流结束子状态(End-of-Stream)。在这种状态下,编解码器不再接收新的输入缓存,但它仍然产生输出缓存(output buffers)直到end-of- stream标记到达输出端。你可以在执行状态(Executing)下的任何时候通过调用flush()方法使编解码器重新返回到刷新子状态(Flushed)。
- 通过调用stop()方法使编解码器返回到未初始化状态(Uninitialized),此时这个编解码器可以再次重新配置 。当你使用完编解码器后,你必须调用release()方法释放其资源。
- 在极少情况下编解码器会遇到错误并进入错误状态(Error)。这个错误可能是在队列操作时返回一个错误的值或者有时候产生了一个异常导致的。通过调用 reset()方法使编解码器再次可用。你可以在任何状态调用reset()方法使编解码器返回到未初始化状态(Uninitialized)。否则,调用 release()方法进入最终的Released状态。
数据处理(Data Processing)
每一个编解码器都包含一组输入和输出缓存(input and output buffers),这些缓存在API调用中通过buffer-id进行引用。当成功调用start()方法后客户端将不会“拥有”输入或输出buffers。在同步模式下,通过调用dequeue Input/OutputBuffer(…) 方法从编解码器获得一个输入或输出buffer的所有权。在异步模式下,你可以通过MediaCodec.Callback.onInput/OutputBufferAvailable(…)的回调方法自动地获得可用的buffers。
在获得一个输入buffer后,向其中填充数据,并利用queueInputBuffer方法将其提交给编解码器,若使用解密,则利用queueSecureInputBuffer方法提交。不要提交多个具有相同时间戳的输入buffers(除非它是也被同样标记的codec-specific data)。
在异步模式下通过onOutputBufferAvailable方法的回调或者在同步模式下响应dequeueOutputBuffer的调用,编解码器返回一个只读的output buffer。在这个output buffer被处理后,调用一个releaseOutputBuffer方法将这个buffer返回给编解码器。
当你不需要立即向编解码器重新提交或释放buffers时,保持对输入或输出buffers的所有权可使编解码器停止工作,当然这些行为依赖于设备情况。特别地,编解码器可能延迟产生输出buffers直到输出的buffers被释放或重新提交。因此,尽可能短时间地持有可用的buffers。根据API版本情况,你有三种处理相关数据的方式:
- Synchronous API using buffer arrays(Android 5.0之前,之后弃用)
- Synchronous API using buffers(适用于Android 5.0之后)
- Asynchronous API using buffers(适用于Android 5.0之后)
使用缓存的异步处理方式(Asynchronous Processing using Buffers)
从Android 5.0(LOLLIPOP)开始,首选的方法是调用configure之前通过设置回调异步地处理数据。异步模式稍微改变了状态转换方式,因为你必须在调用flush()方法后再调用start()方法才能使编解码器的状态转换为Running子状态并开始接收输入buffers。同样,初始调用start方法将编解码器的状态直接变化为Running 子状态并通过回调方法开始传递可用的输入buffers。
异步模式下,典型的使用示例如下:
MediaCodec codec = MediaCodec.createByCodecName(name);
MediaFormat mOutputFormat; // member variable
codec.setCallback(new MediaCodec.Callback() {
@Override
void onInputBufferAvailable(MediaCodec mc, int inputBufferId) {
ByteBuffer inputBuffer = codec.getInputBuffer(inputBufferId);
// fill inputBuffer with valid data
…
codec.queueInputBuffer(inputBufferId, …);
}
@Override
void onOutputBufferAvailable(MediaCodec mc, int outputBufferId, …) {
ByteBuffer outputBuffer = codec.getOutputBuffer(outputBufferId);
MediaFormat bufferFormat = codec.getOutputFormat(outputBufferId); // option A
// bufferFormat is equivalent to mOutputFormat
// outputBuffer is ready to be processed or rendered.
…
codec.releaseOutputBuffer(outputBufferId, …);
}
@Override
void onOutputFormatChanged(MediaCodec mc, MediaFormat format) {
// Subsequent data will conform to new format.
// Can ignore if using getOutputFormat(outputBufferId)
mOutputFormat = format; // option B
}
@Override
void onError(…) {
…
}
});
codec.configure(format, …);
mOutputFormat = codec.getOutputFormat(); // option B
codec.start();
// wait for processing to complete
codec.stop();
codec.release();
使用缓存的同步处理方式(Synchronous Processing using Buffers)
从Android5.0(LOLLIPOP)开始,即使在同步模式下使用编解码器你应该通过getInput/OutputBuffer(int) 或 getInput/OutputImage(int) 方法检索输入和输出buffers。这允许通过框架进行某些优化,例如,在处理动态内容过程中。如果你调用getInput/OutputBuffers()方法这种优化方式是不可用的。
注意,不要同时混淆使用缓存和缓存数组的方法。特别地,仅仅在调用start()方法后或取出一个值为INFO_OUTPUT_FORMAT_CHANGED的输出buffer ID后你才可以直接调用getInput/OutputBuffers方法。
同步模式下MediaCodec的典型应用如下:
MediaCodec codec = MediaCodec.createByCodecName(name);
codec.configure(format, …);
MediaFormat outputFormat = codec.getOutputFormat(); // option B
codec.start();
for (;;) {
int inputBufferId = codec.dequeueInputBuffer(timeoutUs);
if (inputBufferId >= 0) {
ByteBuffer inputBuffer = codec.getInputBuffer(…);
// 通过有效数据来装填inputBuffer
…
codec.queueInputBuffer(inputBufferId, …);
}
int outputBufferId = codec.dequeueOutputBuffer(…);
if (outputBufferId >= 0) {
ByteBuffer outputBuffer = codec.getOutputBuffer(outputBufferId);
MediaFormat bufferFormat = codec.getOutputFormat(outputBufferId); // option A
// 缓存格式等同于输出格式
// 输出格式已经准备好了执行和渲染
…
codec.releaseOutputBuffer(outputBufferId, …);
} else if (outputBufferId == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED) {
//数据流会遵循新的格式
//如果使用getOutputFormat(outputBufferId),则会被忽略
outputFormat = codec.getOutputFormat(); // option B
}
}
codec.stop();
codec.release();
使用缓存数组的同步处理方式(Synchronous Processing using Buffer Arrays)-- (deprecated)
MediaCodec codec = MediaCodec.createByCodecName(name);
codec.configure(format, …);
codec.start();
ByteBuffer[] inputBuffers = codec.getInputBuffers();
ByteBuffer[] outputBuffers = codec.getOutputBuffers();
for (;;) {
int inputBufferId = codec.dequeueInputBuffer(…);
if (inputBufferId >= 0) {
// 通过有效数据来装填InputBuffers[inputBufferId]
…
codec.queueInputBuffer(inputBufferId, …);
}
int outputBufferId = codec.dequeueOutputBuffer(…);
if (outputBufferId >= 0) {
// outputBuffers[outputBufferId]已经准备好了被执行或渲染
…
codec.releaseOutputBuffer(outputBufferId, …);
} else if (outputBufferId == MediaCodec.INFO_OUTPUT_BUFFERS_CHANGED) {
outputBuffers = codec.getOutputBuffers();
} else if (outputBufferId == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED) {
// 数据流会遵循新的格式
MediaFormat format = codec.getOutputFormat();
}
}
codec.stop();
codec.release();
引用
- Android API