概述
这篇文章讨论生产环境中 Express 应用程序的性能和可靠性最佳实践。
很显然,本主题已跨入“devops”领域,涵盖传统开发和运维。相应地,内容分为两部分:
- 代码要做的事(开发部分):
- 开启 gzip 压缩
- 不要使用同步函数
- 正确使用日志
- 合理处理异常
- 环境配置要做的事(运维部分):
- 设置 NODE_ENV 为 “production”
- 确保应用自动重启
- 用 cluster 模式运行应用
- 缓存请求结果
- 使用负载均衡
- 使用反向代理
代码要做的事
为了提升应用性能,你可以做这些事:
- 开启 gzip 压缩
- 不要使用同步函数
- 正确使用日志
- 合理处理异常
开启 gzip 压缩
Gzip 压缩能大幅减少响应体积,从而加快 web 应用速度。可以在 Express 应用中使用 compression中间件做 gzip。例如:
var compression = require('compression')
var express = require('express')
var app = express()
app.use(compression())
对于线上的高流量网站,处理压缩最好的方式是在反向代理层实现(见使用反向代理)。这种情况你不需要使用 compression 中间件。关于 Nginx 开启 gzip 压缩的详细内容,请看 Nginx 文档 。
不要使用同步函数
同步函数和方法独占了执行进程,直到它们返回结果。对同步函数的一次调用可能只需要几微秒或几毫秒,但是对于大流量网站,这些调用耗时积少成多,会降低应用性能。在生产环境要避免使用。
尽管 Node 和 许多模块同时提供了函数的同步和异步版本,在生产环境要用异步版本。同步函数唯一能用的地方就是在应用启动的时候。
如果你使用的是 Node.js 4.0+ 或者 io.js 2.1.0+,你可以用--trace-sync-io命令行参数打印一条警告和堆栈跟踪信息,一旦应用中使用了同步 API。当然,在生产环境你不应该这么做,而是应该确保代码已做好上线准备。更多信息,请看 node 命令行选项文档 。
正确地写日志
通常,在应用中写日志有两个原因:为了调试和记录应用动态(实质上还包括所有其他的内容)。使用 console.log() 或 console.error() 向终端打印日志信息是开发过程中的常见做法。但是当输出目标是终端或者文件时, 这些函数是同步的,因此不适合生产环境,除非你把输出对接到另一个程序上去。
为了调试
如果你是为了调试,那么可以使用像 debug这样的特殊调试模块,而不是使用console.log()。这个模块可以让你通过 DEBUG 环境变量控制哪些调试信息被发送到console.err(),如果有的话。为了让你的应用保持完全异步,你还是需要把console.err() 对接到另一个程序上。但这样的话,你不会真的在生产环境调试,对吧?
为了记录应用活动
如果你为了记录应用动态(例如跟踪网络通信或 API 调用),请使用日志工具库如 Winston 或 Bunyan,而不是用 console.log() 。至于这两个库的详细比较,查看 StrongLoop 的博客 比较 Node.js 日志工具 Winston 和 Bunyan。
正确地处理异常
Node 应用程序在碰到未捕获的异常时会崩溃。如果不处理异常并采取适当的措施,你的 Express 应用将会崩溃下线。如果你采纳下面的 确保应用自动重启 里的建议,你的应用将会从崩溃中恢复。幸运的是,Express 启动时间通常很短。尽管如此,如果你想一开始就避免崩溃,还是需要恰当地处理异常。
为了保证处理所有异常,请使用以下技术:
- 使用 try-catch
- 使用 promise
在深入这些主题之前,你应该对 Node/Express 的错误处理有基本的了解:使用 error 对象为首参的回调函数,并在中间件中传递 error 对象。Node 采用 “回调函数首参为 error 对象”的约定,在异步函数中返回 error 对象,函数的第一个参数是 error 对象,接下来的参数是结果数据。要表示没有错误,第一个参数传 null。回调函数必须遵循首参为 error 对象的约定,以显式地处理错误。Express 的最佳做法是使用 next() 函数在中间件链上传递 error 对象。
更多错误处理相关的基础知识,见:
- Node.js 错误处理
- 构建鲁棒的 Node 应用程序:错误处理 (StrongLoop 博客)
不该做的
你不该做的一件事是监听 uncaughtException 事件,这会导致异常一直向上冒泡,回到事件循环。给 uncaughtException 添加事件监听器会改变出现异常的进程的默认行为,该进程会继续运行,尽管出现了异常。这听起来像是避免应用崩溃的一个好办法,但是出现未捕获的异常后继续运行应用是很危险的做法,不推荐这么做,因为进程的状态变得不可靠,无法预知。
另外,官方认为使用 uncaughtException 是粗暴的。因此监听 uncaughtException 是个坏主意。这就是为什么我们推荐多进程和监控的原因:从错误中恢复,最可靠的方式就是崩溃并重启。
我们也不推荐使用 domains。通常它解决不了问题,并且是个被废弃的模块。
使用 try-catch
Try-catch 是 JavaScript 语言的构成部分,你可以在同步代码里用它捕获异常。比如下面的例子,使用 try-catch 处理 JSON 解析错误。
可以使用JSHint 或 JSLint 这样的工具帮助你发现明显的异常,如未定义的变量上的引用错误。
这里是一个使用 try-catch 处理可能的进程崩溃异常的例子。该中间件函数接受一个叫做“params” 的查询字段参数,该参数是一个 JSON 对象。
app.get('/search', function (req, res) {
// Simulating async operation
setImmediate(function () {
var jsonStr = req.query.params
try {
var jsonObj = JSON.parse(jsonStr)
res.send('Success')
} catch (e) {
res.status(400).send('Invalid JSON string')
}
})
})
但是,try-catch 只对同步代码起作用。由于 Node 平台主要是异步的(特别是生产环境),try-catch 也捕获不到很多异常。
使用 promise
Promise 会处理使用了 then()的异步代码块中的任何异常(同时包括显式的和隐式的)。只要在 promise 链末尾加上 .catch(next) 就行了。例如:
app.get('/', function (req, res, next) {
// do some sync stuff
queryDb()
.then(function (data) {
// handle data
return makeCsv(data)
})
.then(function (csv) {
// handle csv
})
.catch(next)
})
app.use(function (err, req, res, next) {
// handle error
})
现在,异步和同步的所有错误都能传递到这个 error 中间件了。
但是,这里有两个坑:
- 你的所有异步代码必须返回 promise(事件触发器除外)。如果特定的库没有返回 promise,使用一个帮助函数比如Bluebird.promisifyAll() 来转换它的基础对象。
- 事件触发器(比如流)仍然会导致未捕获的异常。因此要确保你已经正确处理了错误事件。比如:
const wrap = fn => (...args) => fn(...args).catch(args[2])
app.get('/', wrap(async (req, res, next) => {
let company = await getCompanyById(req.query.id)
let stream = getLogoStreamById(company.id)
stream.on('error', next).pipe(res)
}))
wrap() 函数封装了捕获被拒绝的 promise 的代码,并用 error 对象作为第一个参数调用 next() 。更多细节,请查看 在Express 中使用 Promises, Generators 和 ES7 处理异步错误。
更多关于使用 promise 处理错误的信息,请查看 用 Q 实现Node.js promise——回调函数的替代方案。
环境配置需要做的事
为了提高应用程序性能,你可以在系统环境里做这些事:
- 设置 NODE_ENV 为 “production”
- 确保应用自动重启
- 用 cluster 模式运行应用
- 缓存请求结果
- 使用负载均衡
- 使用反向代理
设置 NODE_ENV 为 “production”
NODE_ENV 环境变量指定了应用的运行环境(通常是 development 或 production)。提高性能最简单的方式就是设置 NODE_ENV 为 “production”。
设置 NODE_ENV 为 “production” 可以让 Express:
- 缓存视图模板。
- 缓存 CSS 扩展生成的 CSS 文件。
- 生成不那么冗长的错误信息。
测试表明 这么做能让应用性能提高三倍!
如果你需要写针对环境的代码,可以用process.env.NODE_ENV判断NODE_ENV的值。要注意,检查任何环境变量的值都有性能上的代价,所以尽量少用。
在开发环境,通常在 shell 命令行里设置环境变量,比如用 export 或者 .bash_profile 文件。但是通常在生产环境上不该这么做,而要使用操作系统的初始化系统(systemd 或 Upstart)。下一部分会讲关于初始化系统的更多细节,但是设置NODE_ENV对性能如此重要(做起来也简单),所以先在这重点提一下。
对于Upstart,在 job 文件中使用“env”关键字,例如:
# /etc/init/env.conf
env NODE_ENV=production
更多信息,请查看 Upstart 介绍,手册及最佳实践.
对于 systemd,在 unit 文件里使用 Environment 指令。例如:
# /etc/systemd/system/myservice.service
Environment=NODE_ENV=production
更多信息,请查看 Using Environment Variables In systemd Units.
确保应用自动重启
在生产环境,你一定不想让应用下线。这就是说,你要保证当应用崩溃或者服务器宕机时能自动重启。尽管你希望这些事都不发生,但实际上你要为这些可能性负责,要做到:
- 崩溃后使用进程管理器重启应用(和 Node)。
- 当操作系统崩溃时,使用系统提供的初始化系统重启进程管理器。也可以在没有进程管理器的情况下使用init系统。
Node 应用程序碰到未捕获的异常时会崩溃。你需要做的最重要的事情是保证应用经过良好的测试,并处理了所有异常(详情请看合理处理异常)。但是作为一种自动防故障装置,它能保证当你的应用崩溃时自动重启。
使用进程管理器
在开发环境,你可以通过简单的命令如node server.js 或类似的命令启动应用。但是在生产环境也这样做的话就麻烦大了。如果崩溃了,应用将不可用,直到你重启它。为了保证应用在崩溃后重启,要使用进程管理器。进程管理器是应用程序的“容器”, 它让部署变得更容易,提供高可用性,并且允许你在运行时管理应用程序。
除了在应用崩溃后重启,进程管理器还允许你:
- 了解运行时性能和资源消耗。
- 动态地修改设置以提高性能。
- 控制集群(StrongLoop PM和pm2支持)
Node最流行的进程管理器有这些:
- StrongLoop Process Manager
- PM2
- Forever
对这三个进程管理器进行逐个特性的比较,请看 http://strong-pm.io/compare/。三者的详细介绍,请看Express 应用程序管理器。
使用这些进程管理器足以使你的应用程序保持稳定,即使它有时会崩溃。
然而,StrongLoop PM有很多专门针对生产部署的特性。你可以使用它和相关的StrongLoop工具:
- 在本地构建和打包应用程序,然后将其安全地部署到生产环境中。
- 如果因为任何原因崩溃,自动重启你的应用。
- 远程管理你的集群。
- 查看CPU情况和内存堆快照,以优化性能并诊断内存泄漏。
- 查看应用程序的性能指标。
- 通过对Nginx负载均衡的集成控制,轻松地扩展到多台主机。
如下所述,当您使用init系统安装StrongLoop PM作为操作系统服务时,它将在系统重启时自动重启。这样,它将使你的应用程序进程和集群长久持续运行。
使用init系统
下一层的可靠性是确保当服务器重新启动时,应用程序重新启动。系统仍然会因为各种原因而宕机。为了确保在服务器崩溃时,应用程序重新启动,请使用操作系统内置的 init 系统。目前使用的两个主要的init系统是 systemd 和 Upstart。
有两种方法在你的 Express 应用中使用 init 系统:
- 在进程管理器中运行你的应用程序,并通过 init 系统将进程管理器安装为系统服务。当应用程序崩溃时,进程管理器将重新启动应用程序,当操作系统重新启动时,init系统将重启进程管理器。这是推荐的方法。
- 使用 init 系统直接运行你的应用程序(和 Node)。 这稍微简单一些,但是你没有获得使用进程管理器带来的额外优势。
Systemd
Systemd是一个Linux系统和服务管理器。大多数主要的Linux发行版都采用了systemd作为默认的init系统。
systemd 服务配置文件称为单元文件,文件名以.service结尾。下面是一个直接管理节点应用程序的示例单元文件(将粗体文本替换为系统和应用程序的值)。
[Unit]
Description=Awesome Express App
[Service]
Type=simple
ExecStart=/usr/local/bin/node /projects/myapp/index.js
WorkingDirectory=/projects/myapp
User=nobody
Group=nogroup
# Environment variables:
Environment=NODE_ENV=production
# Allow many incoming connections
LimitNOFILE=infinity
# Allow core dumps for debugging
LimitCORE=infinity
StandardInput=null
StandardOutput=syslog
StandardError=syslog
Restart=always
[Install]
WantedBy=multi-user.target
有关systemd的更多信息,请参阅 systemd参考(手册).
作为系统服务的 StrongLoop PM
你可以轻松地将StrongLoop进程管理器安装为systemd服务。在你完成之后,当服务器重新启动时,它将自动重启StrongLoop PM,它将重新启动它所管理的所有应用程序。
将StrongLoop PM作为一个系统服务安装:
$ sudo sl-pm-install --systemd
然后启动服务:
$ sudo /usr/bin/systemctl start strong-pm
更多相关信息,请参阅 建立一个生产主机(StrongLoop文档).
Upstart
Upstart是一个在许多Linux发行版上可用的系统工具,用于在系统启动时启动任务和服务,在关机期间停止它们,并对它们进行监控。你可以将Express应用程序或进程管理器配置为服务,然后Upstart会在崩溃时自动重启它。
一个Upstart服务是在 job 配置文件(也称为“job”)中定义的,文件名以“.conf”结尾。下面的例子展示了如何为一个名为“myapp”的应用创建一个名为myapp的 job,它的主文件位于“/projects/myapp/index.js”中。
创建一个名为“myapp”的文件。在“/etc/init/”中包含以下内容(将粗体文本替换为你的系统和应用程序的值):
# 什么时候启动进程
start on runlevel [2345]
# 什么时候停止进程
stop on runlevel [016]
# 增加文件描述符限制,以便能够处理更多的请求
limit nofile 50000 50000
# 使用生产模式
env NODE_ENV=production
# 作为 www-data 运行
setuid www-data
setgid www-data
# 从 app 目录里运行
chdir /projects/myapp
# 启动的进程
exec /usr/local/bin/node /projects/myapp/index.js
# 如果进程关闭了,重新启动
respawn
# 限制10秒内重启尝试次数为10次
respawn limit 10 10
注意:这个脚本需要在Ubuntu 12.04-14.10中支持的1.4或更新版本。
由于该作业被配置为在系统启动时运行,所以您的应用程序将与操作系统一起启动,如果应用程序崩溃或系统崩溃,则自动重启。
除了自动重启应用程序之外,Upstart还允许你使用以下命令:
-
start myapp– 启动应用程序 -
restart myapp– 重新启动应用程序 -
stop myapp– 停止应用程序
想了解更多关于Upstart的信息,请参阅 Upstart 介绍、手册与最佳实践.
作为 Upstart 服务的StrongLoop PM
您可以轻松地将StrongLoop进程管理器安装为一个 Upstart 服务。在你完成之后,当服务器重新启动时,它将自动重启StrongLoop PM,它将重新启动它所管理的所有应用程序。
将StrongLoop作为一个Upstart 1.4服务安装:
$ sudo sl-pm-install
然后运行服务:
$ sudo /sbin/initctl start strong-pm
注意:在不支持Upstart 1.4的系统上,命令略有不同。更多信息,参阅 建立一个生产主机(StrongLoop文档) 。
在 cluster 中运行应用程序
在多核系统中,通过启动进程 cluster,你可以成倍提高 Node 应用程序的性能。cluster 运行应用程序的多个实例,最好情况下是每个CPU核心一个实例,从而在实例之间分配负载和任务。
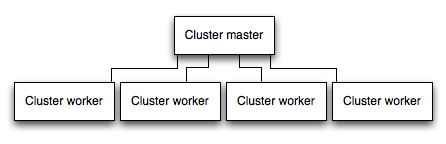
重要:由于应用程序实例作为单独的进程运行,所以它们不共享相同的内存空间。也就是说,对象是应用程序的每个实例的局部对象。因此,你不能在应用程序代码中维护状态。但是,你可以使用像Redis 这样的内存数据存储来存储与会话相关的数据和状态。这个警告适用于所有形式的水平扩展,无论是 cluster 多进程还是多个物理服务器。
在 cluster 应用中,工作进程可以单独崩溃,而不会影响其他进程。除了性能优势之外,故障隔离是运行 cluster 应用进程的另一个原因。每当一个工作程崩溃时,一定要确保记录事件,并使用 cluster.fork() 生成一个新进程。
使用 Node 中的 cluster 模块
集群是通过 Node 的 cluster 模块 实现的。这使主进程能够产生工作进程并在工作之间分配进入的连接。但是,与其直接使用这个模块,不如使用其中的一个工具来自动为你做这件事。例如 node-pm or cluster-service。
使用 StrongLoop PM
如果你将应用程序部署到StrongLoop Process Manager(PM),那么你可以利用集群的优势而不需要修改应用程序代码。当StrongLoop Process Manager(PM)运行一个应用程序时,它会自动地在 cluster 中运行它,它的数量相当于系统上的CPU核心数。你可以使用slc命令行工具手动改变 cluster 的工作进程数量,而无需停止应用程序。
例如,假设你已经将应用程序部署到 prod.foo.com 和 StrongLoop PM,它正在监听端口8701(默认值),然后使用slc将集群大小设置为8:
$ slc ctl -C http://prod.foo.com:8701 set-size my-app 8
要获得关于 StrongLoop PM 集群的更多信息,请参阅 StrongLoop 文档的集群 。
使用 PM2
如果你使用PM2部署应用程序,那么你可以利用集群的优势而不需要修改应用程序代码。你首先应该确保 应用程序是无状态的 ,也就是说进程中没有保存本地数据(例如会话、websocket 连接之类)。
当使用PM2运行一个应用程序时,你可以启用** cluster 模式**在集群中运行它,并且可以选择多个实例,例如匹配机器上可用cpu的数量。你可以使用“pm2”命令行工具手动更改集群中的进程数量,而无需停止应用程序。
要启用 cluster 模式,请像这样启动应用程序:
# 启动 4 个工作进程
$ pm2 start app.js -i 4
# 自动检测可用cpu的数量,并启动多个工作进程
$ pm2 start app.js -i max
这也可以在PM2进程文件中配置(ecosystem.config.js 或类似文件),将 exec_mode 设置为cluster,将instances设置为进程数量。
一旦运行,一个名为app的应用程序可以像这样缩放:
# 增加 3 个工作进程
$ pm2 scale app +3
# 增加到指定工作进程数
$ pm2 scale app 2
有关PM2集群的更多信息,请参阅 PM2 文档的Cluster 模式 。
缓存请求结果
另一种提高生产性能的策略是缓存请求的结果,这样你的应用程序就不会重复操作来重复相同的请求。
使用 Varnish 或 Nginx 这样的缓存服务器(另请参阅 Nginx 缓存) 以大幅提高你的应用的速度和性能。
使用负载均衡
无论一个应用程序优化得多好,一个实例只能处理有限的负载和流量。扩展应用程序的一种方法是运行多个实例,并通过负载均衡器分配流量。设置负载均衡可以提高应用程序的性能和速度,并使其能够在单个实例中扩展超出可能的范围。
负载均衡器通常是一个反向代理,它可以协调多个应用程序实例和服务器之间的流量。通过使用Nginx 或 HAProxy 你可以轻松地为应用设置负载均衡。
有了负载均衡,你可能需要确保与特定会话ID相关联的请求与产生它们的进程相关联。这就是所谓的“会话粘滞”,并且可以通过上面的建议来解决,使用诸如Redis这样的数据存储来处理会话数据(取决于你的应用程序)。要进行讨论,请参阅使用多 node。
使用反向代理
反向代理位于web应用程序的前面,除了将请求定向到应用程序之外,还对请求执行支撑操作。它可以处理错误页面、压缩、缓存、服务文件和负载均衡等。
把不需要应用程序状态的任务移交给反向代理,可以释放Express以执行专门的应用程序任务。出于这个原因,生产环境建议在反向代理后面运行Express,比如Nginx 或 HAProxy。