爬取猫眼票房数并数据可视化
我发现猫眼有个移动端某页接口,获取的json的,获取数据也是更新的,链接:http://piaofang.maoyan.com/getBoxList?date=1&isSplit=true,去掉接口后你会发现就是字体加密反爬的猫眼专业版,数据就是json格式
我们就利用json模块进行抓取这个网页数据存入csv做数据可视化
我们先发送请求获取数据
class Maoyan(object):
# 初始化数据
def __init__(self):
self.url = 'http://piaofang.maoyan.com/getBoxList?date=1&isSplit=true'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 '
}
# 获取数据
def get_data(self):
response = requests.get(url=self.url, headers=self.header)
return response.content
我们直接返回content,接下来就是解析数据,我们就把这个content,用json模块解析,loads一个字典方便取值:
# 解析数据
def parse_data(self, response):
data = json.loads(response)
data_list = data['boxOffice']["data"]["list"]
datas = list()
for main_data in data_list:
temp = {
}
temp["电影ID"] = main_data['movieInfo']["movieId"]
temp["电影名称"] = main_data['movieInfo']["movieName"]
temp["综合票房"] = main_data['sumBoxDesc']
temp["综合票房占比"] = main_data['boxRate']
temp["排片占比"] = main_data['showCountRate']
temp["排坐占比"] = main_data['seatCountRate']
datas.append(temp)
return datas
最后我们保存csv,后续我们进行数据可视化,先保存,代码如下:
def save_data(self, datas):
for data in datas:
csv_writer.writerow([data["电影ID"], data["电影名称"], data["综合票房"], data["综合票房占比"], data["排片占比"], data["排坐占比"]])
整体代码如下:
import requests
import json
import csv
class Maoyan(object):
# 初始化数据
def __init__(self):
self.url = 'http://piaofang.maoyan.com/getBoxList?date=1&isSplit=true'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 '
}
# 获取数据
def get_data(self):
response = requests.get(url=self.url, headers=self.header)
return response.content
# 解析数据
def parse_data(self, response):
data = json.loads(response)
data_list = data['boxOffice']["data"]["list"]
datas = list()
for main_data in data_list:
temp = {
}
temp["电影ID"] = main_data['movieInfo']["movieId"]
temp["电影名称"] = main_data['movieInfo']["movieName"]
temp["综合票房"] = main_data['sumBoxDesc']
temp["综合票房占比"] = main_data['boxRate']
temp["排片占比"] = main_data['showCountRate']
temp["排坐占比"] = main_data['seatCountRate']
datas.append(temp)
return datas
# 保存数据
def save_data(self, datas):
for data in datas:
csv_writer.writerow([data["电影ID"], data["电影名称"], data["综合票房"], data["综合票房占比"], data["排片占比"], data["排坐占比"]])
def run(self):
response = self.get_data()
datas = self.parse_data(response)
self.save_data(datas)
if __name__ == '__main__':
head = ["电影ID", "电影名称", "综合票房", "综合票房占比", "排片占比", "排坐占比"]
with open('猫眼.csv', 'a', newline='', encoding="gb18030") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(head)
maoyan = Maoyan()
maoyan.run()
由于票房单位不统一,我们存下来的csv,我就手动修改了下,单位不用,有的亿,有的万,这里我就直接用excel进行修改了,把亿全修改成了万单位

我们用matplotlib,pandas, numpy 模块进行数据可视化,先读取数据
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
movie = pd.read_csv("./movie.csv",encoding = "gbk",index_col=0)
获取电影名称
movie_name = movie["电影名称"].values
这里我们获取下电影的个数,因为使用matplotlib绘图的时候,x_ticks,y_ticks不能以文字开头
num = int(len(movie_name))
获取票房那一列
movie_num = movie["综合票房"].values
绘制柱状图
movie_name = movie_name
x = range(len(movie_name))
y = movie_num
plt.figure(figsize=(20,15),dpi=100)
plt.bar(x, y, width=0.8, color=['b','r','g','y','c','m','y','k','c','g','b'],align="center")
plt.xticks(x,movie_name,fontsize=12,rotation=-90)
plt.grid(linestyle="--", alpha=0.5)
plt.title("2020年12月电影票房收入对比",fontsize=25)
plt.xlabel("票房名称",fontsize=28)
plt.ylabel("电影数量",fontsize=25)
plt.savefig('./2.png')
plt.show()

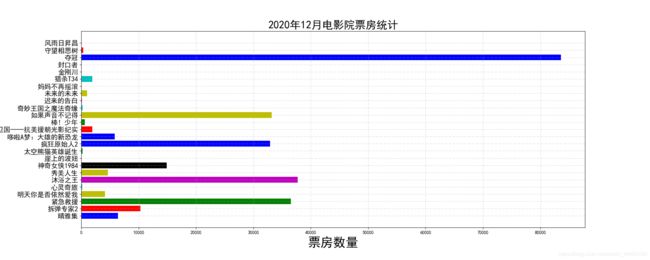
横向柱状图
movie_name = movie_name
x = range(len(movie_name))
y = movie_num
plt.figure(figsize=(20,8),dpi=100)
plt.barh(x, y, color=['b','r','g','y','c','m','y','k','c','g','b'],align="center",height=0.8)
plt.yticks(x,movie_name,fontsize=15)
plt.grid(linestyle="-.", alpha=0.5)
plt.title("2020年12月电影院票房统计",fontsize=24)
plt.xlabel("票房数量",fontsize=28)
plt.ylabel("电影名称",fontsize=25)
plt.savefig("./1.png")
plt.show()
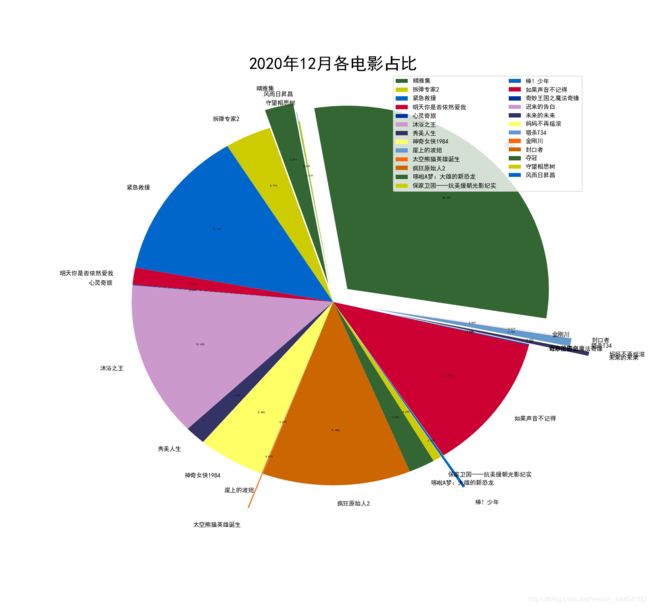
饼状图
movie_name = movie_name
labels = range(len(movie_name))
x = movie_num
color=['#336633','#CCCC00','#0066CC','#CC0033','#003399','#CC99CC','#333366','#FFFF66','#6699CC','#FF6600','#CC6600']
plt.figure(figsize=(15,14),dpi=100)
patches,l_text,p_text = plt.pie(x,labels=movie_name,autopct="%1.2f%%",startangle=100,pctdistance=0.7,radius=1,colors=color,explode=(0.1,0,0,0,0,0,0,0,0,0.2,0,0,0,0.2,0,0,0,0.3,0.3,0.2,0,0.2,0.1,0,0.05))
for l in l_text:
l.set_size(10)
for p in p_text:
p.set_size(5)
plt.grid()
plt.legend(loc=1,ncol=2)
plt.title("2020年12月各电影占比",fontsize=28)
plt.savefig("./3.png")
plt.show()
我把电影名称单独拿出来了,保存到了txt,对电影名称生成词云
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
with open('./词云.txt','r',encoding="utf-8") as f:
data = f.read()
data_list = jieba.cut(data,cut_all=True)
data_text = ','.join(data_list)
wordcloud = WordCloud(
font_path=r'./msyh.ttc',
background_color="white",width=1000,height=1000
).generate(data_text)
plt.imshow(wordcloud,interpolation="bilinear")
plt.axis("off")
plt.savefig('./2.jpg')
plt.show()
生成词云
