MapReduce 的核心知识点,你都 get 到了吗 ?(干货文章,建议收藏!)
本文已收录github:https://github.com/BigDataScholar/TheKingOfBigData,里面有大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!
前言
大家好,我是梦想家!
众所周知,Hadoop 中最核心的两大组件就是 HDFS 和 MapReduce。其中 HDFS 提供了承载海量数据存储的能力,而 MapReduce 则提供了海量数据高并行计算的能力。关于 HDFS 的介绍,之前已经写了两篇来分别介绍 HDFS 的架构 和 HDFS实现文件管理和容错的文章 。而本期文章,我将为大家介绍关于 MapReduce 的核心知识点。
MapReduce的原理
Hadoop 中 MapReduce 最核心的思想就是分而治之,通过 MapReduce 这个名字就可以看出,MapReduce 包含有 Map 和 Reduce 两个部分。它将一个大型的计算问题分解成一个个小的,简单的计算任务,交给 MapReduce 中的 Map 部分执行,随后 Reduce 部分会对 Map 部分输出的中间结果进行聚合计算,输出最终的统计结果。
为了方便大家理解,可以看下 MapReduce 的简要模型图:

每个子任务在框架中都是高度并行计算的,然后 MapReduce 框架将各个计算子任务的计算结果进行合并,得出最终的计算结果。
每个子任务在 MapReduce 内部都是高度并行计算的,子任务的高度并行化极大地提高了 Hadoop 处理海量数据的性能。MapReduce 的并行计算模型如图所示:

由图可知,MapReduce 框架将一个大型的计算任务拆分为多个简单的计算任务,交由多个 Map 并行计算,每个 Map 的计算结果经过中间结果处理阶段的处理后输入 Reduce 阶段,Reduce 阶段将输入的数据进行合并处理,输出最终的计算结果 。
同时,用户无须关心 MapReduce 底层各个节点之间的通信机制与通信过程,只需简单地编写 map() 函数和 reduce() 函数即可开发 Hadoop MapReduce 程度。
MapReduce的部署结构
MapReduce 框架由一个主节点(ResourceManager)、多个子节点(NodeManager)和每个执行任务的 MR AppMaster 共同组成 。通常会将 MapReduce 的计算节点和存储节点部署在同一台服务器上,如图所示:
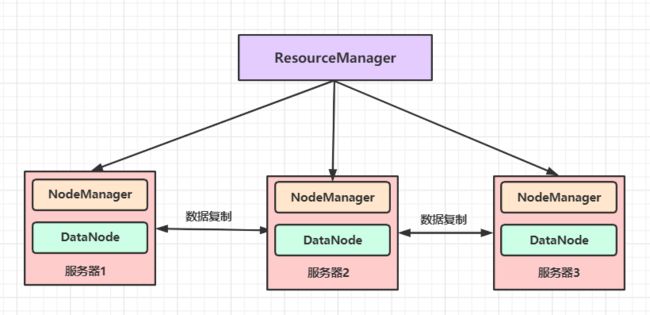
这种部署结构可以使 MapReduce 框架在已经存储好数据的节点上快速、高效地调度任务,尽可能地不用通过 RPC 从其他服务器上获取数据来执行任务,使整个集群的网络带宽被高效利用,极大地提升了处理任务的效率。
MapReduce 的运行流程
MapReduce 编程模型简化了分布式系统中并行计算的复杂度,开发人员能够不必关心 MapReduce 程序的底层实现细节,只专注于解决业务需求。
在 MapReduce 框架内部,整个运行流程可以分为如下四个阶段,其中每个阶段中的数据传输格式也不一样。
简单运行流程如下所示:

大致流程:
(1)原始数据经过 Hadoop 框架的处理,将 “(k,原始数据行)”格式的数据输入 Map 阶段,即 Map 阶段接收到的数据都是 “(k,元素数据行)”的。
(2)数据经过 Map 阶段处理之后,输出 “{(k1,v1),(k2,v2)}”格式的中间结果
(3)Map阶段输出的中间结果经由 Hadoop 的中间结果处理阶段(如聚合、排序等)之后,会形成 “ {(k1,[v1,v2]) …} ”格式的数据
(4)中间结果处理阶段形成的 “{(k1,[v1,v2]) …}”格式的数据会输入 Reduce 阶段进行处理。此时,key相同的数据会被输入进同一个 Reduce 函数进行处理(也可以由用户自定义数据分发规则)
(5)数据经过 Reduce 阶段处理之后,最终会形成“{(k1,v3)}” 格式的数据存入 HDFS 中
另外,如果觉得不够清晰,也可以参考下下面这个版本的 MapReduce 运行流程。
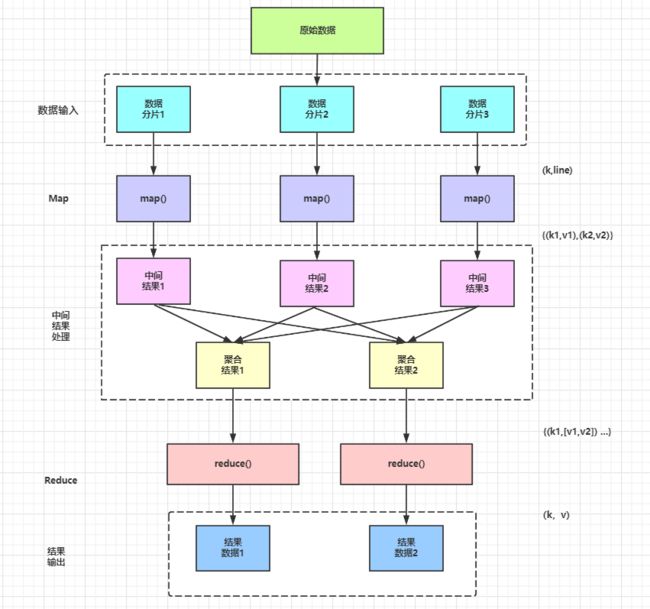
(1)原始数据被切分为多个小的数据分片输入 map() 函数,这些小的数据分片往往是原始数据的数据行,它们以 “(k,line)” 的格式输入 map() 函数,其中 k 表示数据的偏移量,line 表示整行数据。
(2)map() 函数并行处理输入的数据分片,根据具体的业务规则对输入的数据进行相应的处理,输出中间处理结果,这些中间处理结果往往以“{(k1,v1),(k2,v2)}” 的格式存在。
(3)中间处理阶段将 map() 函数输出的中间结果根据 key 进行聚合处理,输出聚合结果,这些聚合结果的格式为:“{(k1,[v1,v2])}”。
(4)中间处理阶段将输出的聚合结果输入 reduce () 函数进行处理( key相同的数据会被输入同一个 reduce()函数中,用户也可以自定义数据分发规则 ),reduce()函数对这些数据进行进一步聚合和计算等。
(5)reduce 函数将最终的结果以 “ (k,v) ”的格式输出到 HDFS 中。
MapReduce的容错机制
MapReduce 容错包括 Task(任务)容错,AppMaster 容错、NodeManager 容错和 ResourceManager 容错。
1、Task 容错
AppMaster 一段时间没有收到任务进度的更新,就会将任务标记为失败,但是不会立刻杀死执行任务的进程,而是等待一定的超时时间。该超时时间可以在mapred-site.xml文件中进行配置,具体的属性为mapreduce.task.timeout:
<properties>
<name>mapreduce.task.timeoutname>
<value>600000value>
property>
超时时间默认值为 10 min,即任务被标记为失败的 10 min 之后才会将任务失败的进程杀死。
MapReduce 提供了重试机制,重试的次数主要由 map-site.xml文件中的 mapreduce.map.maxattempts属性和mapreduce.reduce.maxattempts属性配置,代码如下所示:
<properties>
<name>mapreduce.map.maxattempts</name>
<value>4</value>
</property>
<properties>
<name>mapreduce.reduce.maxattempts</name>
<value>4</value>
</property>
默认重试次数为4,即任务失败后,MapReduce 框架会重试4次,如果任务依然失败,MapReduce才会认为任务彻底失败了。
也可以配置允许任务失败的最大百分比,可以由属性 mapreduce.map.failures.maxpercent 和 mapreduce.reduce.failures.maxprecent 进行配置。
2、AppMaster 容错
AppMaster也提供了重试机制,YARN中的应用程序失败之后,最多尝试次数由mapred-site.xml文件中的mapreduce.am.max-attempts属性配置:
<properties>
<name>mapreduce.am.max-attempts</name>
<value>4</value>
</property>
尝试次数默认值为2,即当 AppMaster 失败2次之后,运行的任务将会失败。
在 MapReduce 内部,YARN 框架对 AppMaster 的最大尝试次数做了限制。其中,每个在 YARN 中运行的应用程序不能超过这个数量限制,具体限制由 yarn-site.xml 文件中的 yarn.resourcemanager.am.max-attempts属性控制,配置信息如下所示:
<properties>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>2</value>
</property>
3、NodeManager 容错
当 NodeManager 发生故障,停止向 ResourceManager 节点发送心跳信息时,ResourceManager 节点并不会立即移除 NodeManager,而是要等待一段时间,该时间可以由 yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms 属性设置,代码如下:
<properties>
<name>yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms</name>
<value>600000</value>
</property>
等待时间默认值为 10 min,即 NodeManager 发生故障之后,ResourceManager 节点接收不到 NodeManager 发生过来的心跳信息,过 10 min 之后才会将 NodeManager 移除 。
当 NodeManager 上运行的失败任务数量达到一定的值时,AppMaster 就会将该节点上的任务调度到其他节点上。任务失败的阈值由 mapred-site.xml 文件中的 mapreduce.job.maxtaskfailures.per.tracker 属性设置,代码如下所示:
<properties>
<name>mapreduce.job.maxtaskfailures.per.trackername>
<value>3value>
property>
此默认值为3,即当一个 NodeManager 上有超过3个任务失败,AppMaster 就会将该节点上的任务调度到其他节点上 。
ResourceManager 容错
新版本的 Hadoop 中提供了 ResourceManager 节点的 HA 机制,如果主 ResourceManager 失败,备 ResouceManager 会迅速接管工作。
Hadoop 中对 ResourceManager节点提供了检查点机制,当所有的 ResourceManager 节点失败后,重启 ResouceManager 节点,可以从上一个失败的 ResourceManager 节点保存的检查点进行状态恢复。
这些检查点的存储是由 yarn-site.xml文件中的 yarn-resourcemanager.store.class属性设置的,代码如下所示:
<properties>
<name>yarn-resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value>
</property>
当然,默认是保存到文件中。
MapReduce的优化
技术面试中,关于 MapReduce 优化的考察频率可能不如 Spark,Flink,但是作为 Hadoop 知识的热门考点,我们对于它的优化还是要有一个清晰的认识 。 这里,我们从以下几个小点逐一展开。
MapReduce跑的慢的原因
MapReduce程序效率的瓶颈在于两点:
- 计算机性能
CPU、内存、磁盘健康、网络
- I/O 操作优化
- 数据倾斜
- Map 和 Reduce 数设置不合理
- Map运行时间太长,导致 Reduce 等待过久
- 小文件过多
- 大量的不可分块的超大文件
- Spill 次数过多
- Merge 次数过多等。
MapReduce优化
关于 MapReduce 优化方法主要从以下6个方面进行考虑,分别是:数据倾斜、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数。
1、数据输入
(1)合并小文件:在执行 MR 任务之前将小文件进行合并,大量的小文件会产生大量的 MR 任务,增大 Map 任务装载次数,而任务的装载比较耗时,从而导致 MR 运行较慢。
(2)采用 CombineText InputFormat 来作为输入,解决输入端大量小文件场景。
2、Map阶段
(1)减少溢写(spill)次数:通过调整 io.sort.mb 及 sort.spill.percent 参数值,增大触发 Spill 的内存上限,减少 Spill 次数,从而减少磁盘 IO 。
(2)减少合并(Merge)次数:通过调整io.sort.factor参数,增大 Merge 的文件数目,减少 Merge 的次数,从而缩短 MR 处理时间。
(3)在 Map 之后,不影响业务逻辑前提下,先进行 Combine 处理,减少 I/O 。
3、Reduce 阶段
(1)合理设置 Map 和 Reduce 数:两个都不能设置的太少,也不能设置的太多。太少,会导致 Task 等待,延长处理时间;太多,会导致 Map,Reduce 任务间竞争资源,造成处理超时等错误 。
(2)设置 Map、Reduce 共存:调整 slowstart.completedmap参数,使 Map 运行到一定程度后,Reduce 也开始运行,减少 Reduce 的等待时间 。
(3)规避使用 Reduce:因为 Reduce 在用于连接数据集的时候将会产生大量的网络消耗。
(4)合理设置 Reduce 端的 Buffer:默认情况下,数据达到一个阈值的时候,Buffer 中的数据就会写入磁盘,然后 Reduce 会从磁盘中获得所有的数据。也就是说,Buffer 和 Reduce 是没有直接关联的,中间多次写磁盘 -> 读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得 Buffer 中的一部分数据可以直接输送到 Reduce,从而减少 IO 开销 : mapreduce.reduce.input.buffer.percent,默认为 0.0 。当值大于 0 的时候,会保留指定比例的内存读 Buffer 中的数据直接拿给 Reduce 使用 。 这样一来,设置 Buffer 需要内存,读取数据需要内存,Reduce 计算也需要内存,所以要根据作业的用运行情况进行调整 。
4、I/O 传输
(1)采用 数据 压缩的方式,减少 网络 IO 的时间 。 安装 Snappy 和 LZO 压缩编码器。
(2)使用 SequenceFile 二进制文件。
5、数据倾斜问题
1. 数据倾斜现象:
- 数据频率倾斜——某一个区域的数据量要远远大于其他的区域。
- 数据大小倾斜——部分记录的大小远远大于平均值
2.减少数据倾斜的方法:
方法1 :抽样和范围分区
可以通过对原始数据进行抽样得到的结果集来预设分区边界值。
方法2:自定义分区
基于输出键的背景知识进行自定义分区。例如,如果 Map 输出键的单词来源于一本书。且其中某几个专业词汇较多,那么就可以自定义分区将这些专业词汇发送给固定的一部分 Reduce 实例。而其他的都发送给剩余的 Reduce 实例。
方法3:Combine
使用 Combine 可以大量的减少数据倾斜。在可能的情况下,Combine 的目的就是聚合并精简数据。
方法4:采用 Map Join,尽量避免 Reduce Join
这个我们上面说过了,Reduce 在用于连接数据集的时候将会产生大量的网络消耗,所以我们采用 MapJoin,尽量避免 Reduce Join 。
6、常用的调优参数
1、资源相关参数
(1)以下参数是在用户自己的MR应用程序中配置就可以生效(mapred-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.memory.mb | 一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.reduce.memory.mb | 一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。 |
| mapreduce.map.cpu.vcores | 每个MapTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.cpu.vcores | 每个ReduceTask可使用的最多cpu core数目,默认值: 1 |
| mapreduce.reduce.shuffle.parallelcopies | 每个Reduce去Map中取数据的并行数。默认值是5 |
| mapreduce.reduce.shuffle.merge.percent | Buffer中的数据达到多少比例开始写入磁盘。默认值0.66 |
| mapreduce.reduce.shuffle.input.buffer.percent | Buffer大小占Reduce可用内存的比例。默认值0.7 |
| mapreduce.reduce.input.buffer.percent | 指定多少比例的内存用来存放Buffer中的数据,默认值是0.0 |
(2)应该在YARN启动之前就配置在服务器的配置文件中才能生效(yarn-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| yarn.scheduler.minimum-allocation-mb | 给应用程序Container分配的最小内存,默认值:1024 |
| yarn.scheduler.maximum-allocation-mb | 给应用程序Container分配的最大内存,默认值:8192 |
| yarn.scheduler.minimum-allocation-vcores | 每个Container申请的最小CPU核数,默认值:1 |
| yarn.scheduler.maximum-allocation-vcores | 每个Container申请的最大CPU核数,默认值:32 |
| yarn.nodemanager.resource.memory-mb | 给Containers分配的最大物理内存,默认值:8192 |
(3)Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.task.io.sort.mb | Shuffle的环形缓冲区大小,默认100m |
| mapreduce.map.sort.spill.percent | 环形缓冲区溢出的阈值,默认80% |
2、容错相关参数(MapReduce性能优化)
| 配置参数 | 参数说明 |
|---|---|
| mapreduce.map.maxattempts | 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.reduce.maxattempts | 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。 |
| mapreduce.task.timeout | Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.” |
巨人的肩膀
1、《海量数据处理与大数据技术实战》
2、《Hadoop权威指南》
小结
实际上,关于 MapReduce的内容还有很多,本期文章只是将比较重要核心的部分介绍了一下。其中,MapReduce的原理,运行流程,优化是面试中比较经常考察的点,而部署结构,容错机制我们仅做学习了解即可。我还想强调一点,一定要学会自发的去学习新的知识和总结学过的内容。否则就容易出现,新学的记不住,学过的忘记了的情况。
好了,本期文章就到这里,我是梦想家,我们下一期见!如果对您有所帮助,请记得一键三连~