探秘Hadoop生态11:使用Sqoop导出Mysql数据至Hive中,反之亦然
sqoop一些语法的使用
参数详细资料 观看这个博客
http://shiyanjun.cn/archives/624.html
Sqoop可以在HDFS/Hive和关系型数据库之间进行数据的导入导出,其中主要使用了import和export这两个工具。这两个工具非常强大,提供了很多选项帮助我们完成数据的迁移和同步。比如,下面两个潜在的需求:
- 业务数据存放在关系数据库中,如果数据量达到一定规模后需要对其进行分析或同统计,单纯使用关系数据库可能会成为瓶颈,这时可以将数据从业务数据库数据导入(import)到Hadoop平台进行离线分析。
- 对大规模的数据在Hadoop平台上进行分析以后,可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库。
这里,我们介绍Sqoop完成上述基本应用场景所使用的import和export工具,通过一些简单的例子来说明这两个工具是如何做到的。
import和export工具有些通用的选项,如下表所示:
| 选项 | 含义说明 |
--connect |
指定JDBC连接字符串 |
--connection-manager |
指定要使用的连接管理器类 |
--driver |
指定要使用的JDBC驱动类 |
--hadoop-mapred-home |
指定$HADOOP_MAPRED_HOME路径 |
--help |
打印用法帮助信息 |
--password-file |
设置用于存放认证的密码信息文件的路径 |
-P |
从控制台读取输入的密码 |
--password |
设置认证密码 |
--username |
设置认证用户名 |
--verbose |
打印详细的运行信息 |
--connection-param-file |
可选,指定存储数据库连接参数的属性文件 |
数据导入工具import
import工具,是将HDFS平台外部的结构化存储系统中的数据导入到Hadoop平台,便于后续分析。我们先看一下import工具的基本选项及其含义,如下表所示:
| 选项 | 含义说明 |
--append |
将数据追加到HDFS上一个已存在的数据集上 |
--as-avrodatafile |
将数据导入到Avro数据文件 |
--as-sequencefile |
将数据导入到SequenceFile |
--as-textfile |
将数据导入到普通文本文件(默认) |
--boundary-query |
边界查询,用于创建分片(InputSplit) |
--columns |
从表中导出指定的一组列的数据 |
--delete-target-dir |
如果指定目录存在,则先删除掉 |
--direct |
使用直接导入模式(优化导入速度) |
--direct-split-size |
分割输入stream的字节大小(在直接导入模式下) |
--fetch-size |
从数据库中批量读取记录数 |
--inline-lob-limit |
设置内联的LOB对象的大小 |
-m,--num-mappers |
使用n个map任务并行导入数据 |
-e,--query |
导入的查询语句 |
--split-by |
指定按照哪个列去分割数据 |
--table |
导入的源表表名 |
--target-dir |
导入HDFS的目标路径 |
--warehouse-dir |
HDFS存放表的根路径 |
--where |
指定导出时所使用的查询条件 |
-z,--compress |
启用压缩 |
--compression-codec |
指定Hadoop的codec方式(默认gzip) |
--null-string |
果指定列为字符串类型,使用指定字符串替换值为null的该类列的值 |
--null-non-string |
如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值 |
bin/sqoop help 可以查看出帮助文档 英文的 看不懂
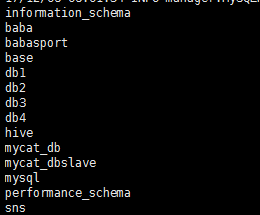
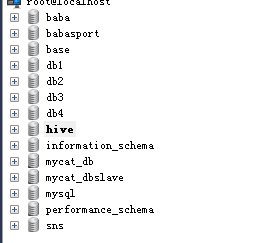
1:sqoop查看mysql有多少个数据库
bin/sqoop list-databases \
--connect jdbc:mysql://172.16.71.27:3306 \
--username root \
--password root

2:将mysql表中数据导入到hdfs中 imports
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--table test_tb
ps:如果没有指定hdfs的目录 默认会将数据存到系统当前登录用户下 以表名称命名的文件夹下

ps : 复制的时候一定要注意下 \ 的位置 少个空格都会报错。。。 默认会有4个MapReduce在执行 这里测试数据只有2条 so。。。
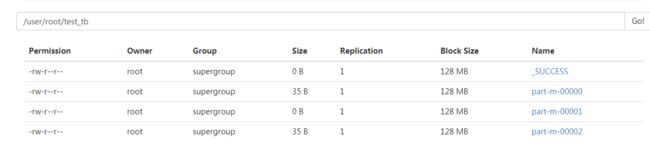
数据默认以逗号隔开 可以根据需求进行指定
![]()
导入数据至指定hdfs目录
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_user \
--num-mappers 1
ps: num-mappers 1 指定执行MapReduce的个数为1
target-dir 指定hdfs的目录
sqoop 底层的实现就是MapReduce,import来说,仅仅运行Map Task
数据存储文件
* textfile
* orcfile
* parquet
将数据按照parquet文件格式导出到hdfs指定目录
bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--table test_tb \
--target-dir /user/xuyou/sqoop/imp_my_user_parquet \
--fields-terminated-by '@' \
--num-mappers 1 \
--as-parquetfile
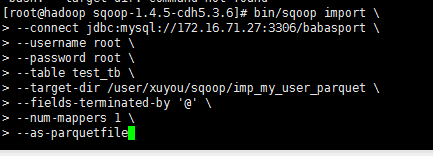
ps fields-terminated-by '@' 数据已@隔开
as-parquetfile 数据按照parquet文件格式存储
columns id,name 这个属性 可以只导入id已经name 这两个列的值

* 在实际的项目中,要处理的数据,需要进行初步清洗和过滤
* 某些字段过滤
* 条件
* join
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--query 'select id, account from my_user where $CONDITIONS' \
--target-dir /user/beifeng/sqoop/imp_my_user_query \
--num-mappers 1
ps: query 这个属性代替了 table 可以通过用sql 语句来导出数据
(where $CONDITIONS' 是固定写法 如果需要条件查询可以 select id, account from my_user where $CONDITIONS' and id > 1)
压缩导入至hdfs的数据 可以指定格式
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/beifeng/sqoop/imp_my_sannpy \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
ps:compress 这个属性 是 开启压缩功能
compression-codec 这个属性是 指定压缩的压缩码 本次是SnappyCodec
用java代码调用shell脚本执行sqoop将hive表中数据导出到mysql
1:创建shell脚本
1 touch sqoop_options.sh
2 chmod 777 sqoop_options.sh![]()
编辑文件 特地将执行map的个数设置为变量 测试 可以java代码传参数 同时也验证sqoop的 options 属性支持这种写法

1 #!/bin/bash
2 /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/bin/sqoop --options-file /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/sqoop-import-mysql.txt --num-mappers $1
3 if [ $? -eq 0 ];then
4 echo "success"
5 else
6 echo "error"
7 fi2:创建 sqoop-import-mysql.txt 文件并编辑
|
1
|
touch sqoop-
import
-mysql.txt
|
1 export
2 --connect
3 jdbc:mysql://172.16.71.27:3306/babasport
4 --username
5 root
6 --password
7 root
8 --table
9 test_hive
10 --export-dir
11 /user/hive/warehouse/hive_bbs_product_snappy
12 --input-fields-terminated-by
13 '\t'
hive数据存在hdfs位置

3:开始写java后台代码 目前只支持 window写法 后期加上linux调用shell脚本的写法
1 package com.liveyc.common.utils;
2
3 import java.util.Properties;
4
5 import org.apache.commons.logging.Log;
6 import org.apache.commons.logging.LogFactory;
7
8 public class FileToHbase {
9 /**
10 * shell脚本执行成功标识
11 */
12 public static int SHELL_EXIT_OK = 0;
13 public static Log log = LogFactory.getLog(FileToHbase.class);
14 public static String connIp = "172.16.71.120";
15 public static String connUser = "root";
16 public static String connPwd = "123456";
17
18 public static void main(String[] args) throws Exception {
19 boolean result = export();
20 System.out.println(result);
21 }
22
23 public static boolean export() throws Exception {
24 boolean result = false;
25 // 如果当前系统是window系统需要远程ssh连接系统
26 if (isWinSystem()) {
27 ConnectShell connectShell = new ConnectShell(connIp, connUser, connPwd, "utf-8");
28 String url = "/opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/sqoop_options.sh" + " " +1;
29 result = connectShell.excuteShellCommand(url);
30 }
31 return result;
32 }
33
34 /**
35 * 当前操作系统类型
36 *
37 * @return true 为windos系统,false为linux系统
38 */
39 public static boolean isWinSystem() {
40 // 获取当前操作系统类型
41 Properties prop = System.getProperties();
42 String os = prop.getProperty("os.name");
43 if (os.startsWith("win") || os.startsWith("Win")) {
44 return true;
45 } else {
46 return false;
47 }
48 }
49 }
1 package com.liveyc.common.utils;
2
3 import java.io.BufferedReader;
4 import java.io.IOException;
5 import java.io.InputStream;
6 import java.io.InputStreamReader;
7 import java.io.UnsupportedEncodingException;
8 import java.nio.charset.Charset;
9
10 import org.apache.commons.logging.Log;
11 import org.apache.commons.logging.LogFactory;
12
13 import ch.ethz.ssh2.ChannelCondition;
14 import ch.ethz.ssh2.Connection;
15 import ch.ethz.ssh2.Session;
16 import ch.ethz.ssh2.StreamGobbler;
17
18 /**
19 *
20 * ConnectShell
21 *
22 * @Description:连接Shell脚本所在服务器
23 * @author:aitf
24 * @date: 2016年3月31日
25 *
26 */
27 public class ConnectShell {
28 private Connection conn;
29 private String ipAddr;
30 private String userName;
31 private String password;
32 private String charset = Charset.defaultCharset().toString();
33 private static final int TIME_OUT = 1000 * 5 * 60;
34 public static Log log = LogFactory.getLog(ConnectShell.class);
35
36 public ConnectShell(String ipAddr, String userName, String password, String charset) {
37 this.ipAddr = ipAddr;
38 this.userName = userName;
39 this.password = password;
40 if (charset != null) {
41 this.charset = charset;
42 }
43 }
44
45 public boolean login() throws IOException {
46 conn = new Connection(ipAddr);
47 conn.connect();
48 return conn.authenticateWithPassword(userName, password); // 认证
49 }
50
51 /**
52 *
53 * @Title: excuteShellCommand
54 * @Description: 执行shell脚本命令
55 * @param shellpath
56 * @return
57 */
58 public boolean excuteShellCommand(String shellpath) {
59 InputStream in = null;
60 boolean result = false;
61 String str = "";
62 try {
63 if (this.login()) {
64 Session session = conn.openSession();
65 //session.execCommand("cd /root");
66 session.execCommand(shellpath);
67 in = new StreamGobbler(session.getStdout());
68 // in = session.getStdout();
69 str = this.processStdout(in, charset);
70 session.waitForCondition(ChannelCondition.EXIT_STATUS, TIME_OUT);
71 session.close();
72 conn.close();
73 if (str.contains("success")) {
74 result = true;
75 }else{
76 result = false;
77 }
78 }
79 } catch (IOException e1) {
80 e1.printStackTrace();
81 }
82 return result;
83 }
84
85 public String excuteShellCommand2(String shellpath) throws Exception {
86 InputStream in = null;
87 String result = "";
88 try {
89 if (this.login()) {
90 Process exec = Runtime.getRuntime().exec(shellpath);// ipconfig
91 in = exec.getInputStream();
92 result = this.processStdout(in, this.charset);
93 }
94 } catch (IOException e1) {
95 e1.printStackTrace();
96 }
97 return result;
98 }
99
100 /**
101 * 转化结果
102 *
103 * @param in
104 * @param charset
105 * @return
106 * @throws UnsupportedEncodingException
107 */
108 public String processStdout(InputStream in, String charset) throws UnsupportedEncodingException {
109 String line = null;
110 BufferedReader brs = new BufferedReader(new InputStreamReader(in, charset));
111 StringBuffer sb = new StringBuffer();
112 try {
113 while ((line = brs.readLine()) != null) {
114 sb.append(line + "\n");
115 }
116 } catch (IOException e) {
117 log.error("---转化出现异常---");
118 }
119 return sb.toString();
120 }
121
122 }
4:开始测试
在mysql创建一个表 hive中数据格式 是 int int String
1 CREATE TABLE test_hive(
2 id INT,
3 brand_id INT,
4 NAME VARCHAR(200)
5 )
执行java main方法 开始测试
观看8088端口 查看MapReduce的运行状况 发现正在运行(开心)

执行完毕 
可以看到 只有1个 MapReduce任务 (默认的个数是4个 这样看来第一步写的shell脚本 参数是传递过来了 sqoop的 options 也支持这种直接指定参数的写法)
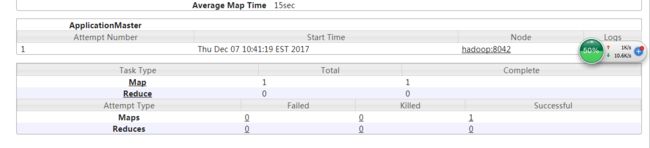
现在转过来看java代码
返回值 :
1 Warning: /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/bin/../../hbase does not exist! HBase imports will fail.
2 Please set $HBASE_HOME to the root of your HBase installation.
3 Warning: /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/bin/../../hcatalog does not exist! HCatalog jobs will fail.
4 Please set $HCAT_HOME to the root of your HCatalog installation.
5 Warning: /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/bin/../../accumulo does not exist! Accumulo imports will fail.
6 Please set $ACCUMULO_HOME to the root of your Accumulo installation.
7 Warning: /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/bin/../../zookeeper does not exist! Accumulo imports will fail.
8 Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
9 success
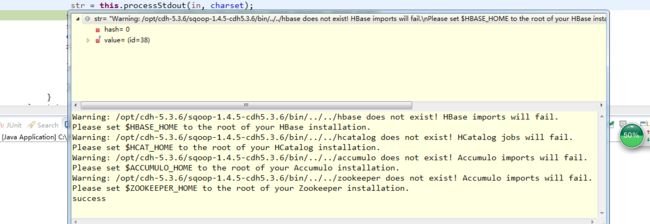
发现返回 success 说明shell脚本执行成功了
一切执行正常 看下mysql 数据库表中有没有数据

OK 一切正常 , 后期把linux执行shell脚本的语句也补充上 。
用sqoop将mysql的数据导入到hive表中
1:先将mysql一张表的数据用sqoop导入到hdfs中
准备一张表

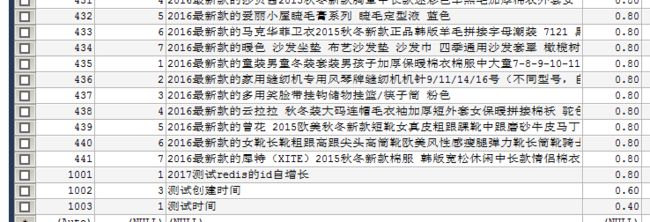
需求 将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
数据存在 hdfs 目录 /user/xuyou/sqoop/imp_bbs_product_sannpy_ 下

bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
--target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'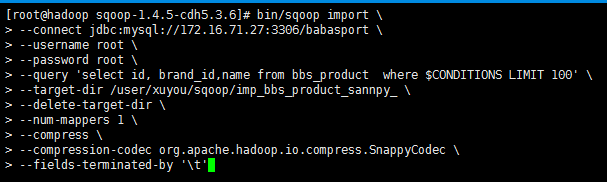
ps: 如果导出的数据库是mysql 则可以添加一个 属性 --direct
1 bin/sqoop import \
2 --connect jdbc:mysql://172.16.71.27:3306/babasport \
3 --username root \
4 --password root \
5 --query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
6 --target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
7 --delete-target-dir \
8 --num-mappers 1 \
9 --compress \
10 --compression-codec org.apache.hadoop.io.compress.SnappyCodec \
11 --direct \
12 --fields-terminated-by '\t'加了 direct 属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
第一次执行所需要的时间

第二次执行所需要的时间 (加了direct属性)

执行成功

2:启动hive 在hive中创建一张表
1 drop table if exists default.hive_bbs_product_snappy ;
2 create table default.hive_bbs_product_snappy(
3 id int,
4 brand_id int,
5 name string
6 )
7 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;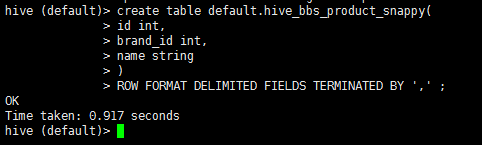
3:将hdfs中的数据导入到hive中
1 load data inpath '/user/xuyou/sqoop/imp_bbs_product_sannpy_' into table default.hive_bbs_product_snappy ;
4:查询 hive_bbs_product_snappy 表
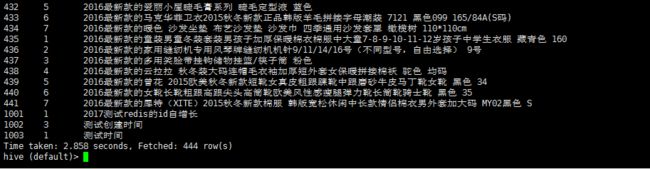
1 select * from hive_bbs_product_snappy; 
此时hdfs 中原数据没有了

然后进入hive的hdfs存储位置发现

注意 :sqoop 提供了 直接将mysql数据 导入 hive的 功能 底层 步骤就是以上步骤
创建一个文件 touch test.sql 编辑文件 vi test.sql
1 use default;
2 drop table if exists default.hive_bbs_product_snappy ;
3 create table default.hive_bbs_product_snappy(
4 id int,
5 brand_id int,
6 name string
7 )
8 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
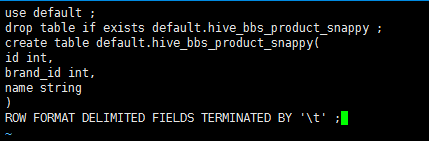
在 启动hive的时候 执行 sql脚本
bin/hive -f /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/test.sql

执行sqoop直接导入hive的功能
1 bin/sqoop import \
2 --connect jdbc:mysql://172.16.71.27:3306/babasport \
3 --username root \
4 --password root \
5 --table bbs_product \
6 --fields-terminated-by '\t' \
7 --delete-target-dir \
8 --num-mappers 1 \
9 --hive-import \
10 --hive-database default \
11 --hive-table hive_bbs_product_snappy
看日志输出可以看出 在执行map任务之后 又执行了load data
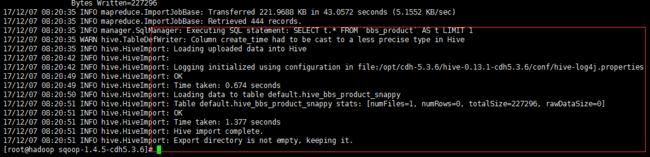
查询 hive 数据
个人公众号:程序员黄小斜
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!专注于分享技术、面试、职场等成长干货,这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术学习、计算机基础和考研等8000G资料合集。

技术公众号:Java技术江湖
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。
