Flink SQL和Table编程和案例
声明:本系列博客为原创,最先发表在拉勾教育,其中一部分为免费阅读部分。被读者各种搬运至各大网站。所有其他的来源均为抄袭。
《2021年最新版大数据面试题全面开启更新》
一、概述
1、背景
Flink自身提供了不同级别的抽象来支持开发者进行流式或者批量处理程序,Flink支持4种不同级别的抽象。
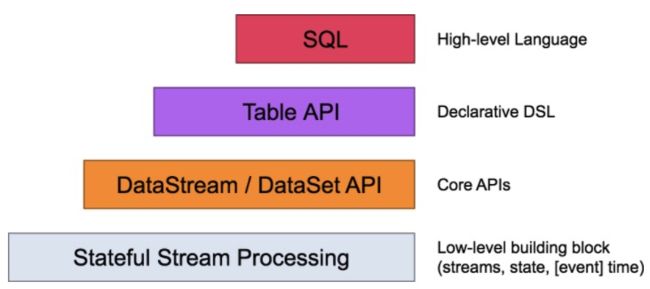
Table API 和SQL处于最顶端,是Flink提供的高级API操作。Flink SQL是Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准SQL语义的开发语言。
Flink在编程模型上提供了DataSet 和 DataStream两套API,并没有做到事实上的批流一体。
2、原理
在离线计算领域Hive几行扛起了半壁江山,它的底层对SQL的解析用到了Apache Calcite,Flink同样把SQL的解析、优化和执行交给了Calcite。
下图是一张经典的Flink Table & SQL 实现原理图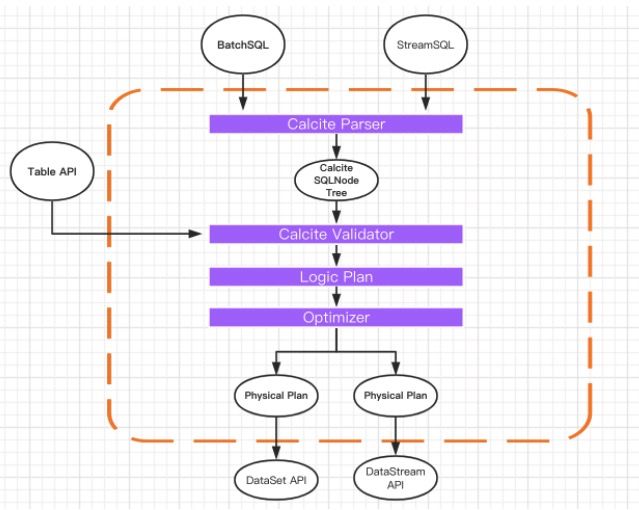
无论是批查询SQL还是流式查询SQL,都会经过对应的转换器Parser转换成节点数SQLNode tree,然后生成逻辑执行计划Logical Plan,逻辑执行计划在经过优化后生成真正可以执行的物理执行计划,交给DataSet或者DataStream的API去执行。
一个完成的Flink Table & SQL Job也是由Source、Transformations、Sink构成:
- source:来源于外部数据,常用的有Kafka、Mysql等
- Transformations:是Flink Table & SQL 支持的常用SQL算子,比如简单的Select、GroupBy等,然后在这里也有更为复杂的多流Join、流与维表的Join等。
3、动态表
与传统的表SQL查询相比,Flink Table & SQL 在处理流数据时会时时刻刻处于动态的数据变化中,所以便又了一个动态表的概念。 动态表的查询和静态表一样,在查询动态表的时候,SQL会连续查询,不会终止。举个简单的例子,Kafka流作为输入:
Kafka消息会源源不断的解析成一张不断增长的动态表,我们在动态表上执行的SQL会不断生成新的动态表作为结果表。
4、Flink Table & SQL算子和内置函数
Flink Table & SQL的开发一直在进行中,并没有支持所有场景下的计算逻辑。
常用算子
目前Flink SQL支持的语法主要如下:
query:
values
| {
select
| selectWithoutFrom
| query UNION [ ALL ] query
| query EXCEPT query
| query INTERSECT query
}
[ ORDER BY orderItem [, orderItem ]* ]
[ LIMIT { count | ALL } ]
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY]
orderItem:
expression [ ASC | DESC ]
select:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
FROM tableExpression
[ WHERE booleanExpression ]
[ GROUP BY { groupItem [, groupItem ]* } ]
[ HAVING booleanExpression ]
[ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ]
selectWithoutFrom:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
projectItem:
expression [ [ AS ] columnAlias ]
| tableAlias . *
tableExpression:
tableReference [, tableReference ]*
| tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ]
joinCondition:
ON booleanExpression
| USING '(' column [, column ]* ')'
tableReference:
tablePrimary
[ matchRecognize ]
[ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ]
tablePrimary:
[ TABLE ] [ [ catalogName . ] schemaName . ] tableName
| LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')'
| UNNEST '(' expression ')'
values:
VALUES expression [, expression ]*
groupItem:
expression
| '(' ')'
| '(' expression [, expression ]* ')'
| CUBE '(' expression [, expression ]* ')'
| ROLLUP '(' expression [, expression ]* ')'
| GROUPING SETS '(' groupItem [, groupItem ]* ')'
windowRef:
windowName
| windowSpec
windowSpec:
[ windowName ]
'('
[ ORDER BY orderItem [, orderItem ]* ]
[ PARTITION BY expression [, expression ]* ]
[
RANGE numericOrIntervalExpression {PRECEDING}
| ROWS numericExpression {PRECEDING}
]
')'
Flink SQL和传统的SQL一样,支持包含查询、连接、聚合等场景,另外还支持窗口、排序等场景。
SELECT/AS/WHERE
SELECT、WHERE和传统的SQL用法一样,用于筛选和过滤数据,同时适用于DataStream和DataSet。
SELECT * FROM Table;
SELECT name,age FROM Table;
我们也可以在WHERE条件中使用=、<、>、<>、>=、<=,以及 AND、OR 等表达式的组合:
SELECT name,age FROM Table where name LIKE '%小明%';
SELECT * FROM Table WHERE age = 20;
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
GROUP BY / DISTINCT/HAVING
GROUP BY 用于进行分组操作,DISTINCT 用于结果去重。HAVING 和传统 SQL 一样,可以用来在聚合函数之后进行筛选。
SELECT DISTINCT name FROM Table;
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name HAVING
SUM(score) > 300;
JOIN
JOIN 可以用于把来自两个表的数据联合起来形成结果表,目前 Flink 的 Join 只支持等值连接。Flink 支持的 JOIN 类型包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
例如:
SELECT *
FROM User LEFT JOIN Product ON User.name = Product.buyer
SELECT *
FROM User RIGHT JOIN Product ON User.name = Product.buyer
SELECT *
FROM User FULL OUTER JOIN Product ON User.name = Product.buyer
LEFT JOIN、RIGHT JOIN 、FULL JOIN 相与我们传统 SQL 中含义一样。
WINDOW
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种:
- 滚动窗口,窗口数据有固定的大小,窗口中的数据不会叠加;
- 滑动窗口,窗口数据有固定大小,并且有生成间隔;
- 会话窗口,窗口数据没有固定的大小,根据用户传入的参数进行划分,窗口数据无叠加;
滚动窗口:滚动窗口的特点是:有固定大小、窗口中的数据不会重叠,如下图所示:
滚动窗口常用的语法:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
举例说明,我们需要计算每个用户每天的订单数据:
SELECT user, TUMBLE_START(timeLine, INTERVAL '1' DAY) as winStart, SUM(amount) FROM Orders GROUP BY TUMBLE(timeLine, INTERVAL '1' DAY), user;
其中,TUMBLE_START 和 TUMBLE_END 代表窗口的开始时间和窗口的结束时间,TUMBLE (timeLine, INTERVAL '1' DAY) 中的 timeLine 代表时间字段所在的列,INTERVAL '1' DAY 表示时间间隔为一天。
滑动窗口:滑动窗口有固定的大小,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的创建频率。需要注意的是,多个滑动窗口可能会发生数据重叠,具体语义如下: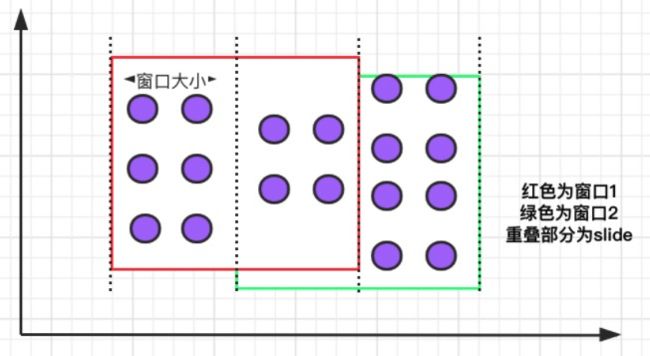
滑动窗口的语法与滚动窗口相比,只多了一个 slide 参数:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
例如,我们要每间隔一小时计算一次过去 24 小时内每个商品的销量:
SELECT product, SUM(amount) FROM Orders GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY), product
上述案例中的 INTERVAL '1' HOUR 代表滑动窗口生成的时间间隔。
会话窗口:会话窗口定义了一个非活动时间,假如在指定的时间间隔内没有出现事件或消息,则会话窗口关闭。
会话窗口的语法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
举例,我们需要计算每个用户过去 1 小时内的订单量:
SELECT user, SESSION_START(rowtime, INTERVAL '1' HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL '1' HOUR) AS sEnd, SUM(amount) FROM Orders GROUP BY SESSION(rowtime, INTERVAL '1' HOUR), user
内置函数
Flink 中还有大量的内置函数,我们可以直接使用,将内置函数分类如下:
- 比较函数
- 逻辑函数
- 算术函数
- 字符串处理函数
- 时间函数
比较函数
逻辑函数
算术函数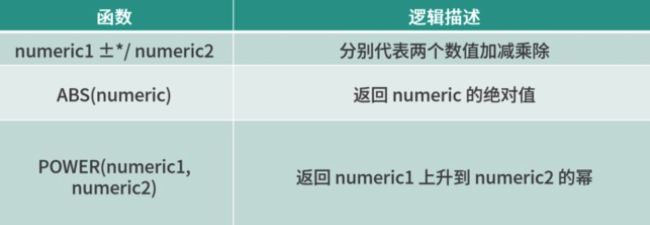
字符串处理函数
时间函数
二、Flink Table & SQL案例
public class MyStreamingSource implements SourceFunction- {
private boolean isRunning = true;
/**
* 重写run方法产生一个源源不断的数据发送源
* @param ctx
* @throws Exception
*/
public void run(SourceContext
- ctx) throws Exception {
while(isRunning){
Item item = generateItem();
ctx.collect(item);
//每秒产生一条数据
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
}
//随机产生一条商品数据
private Item generateItem(){
int i = new Random().nextInt(100);
ArrayList
list = new ArrayList();
list.add("HAT");
list.add("TIE");
list.add("SHOE");
Item item = new Item();
item.setName(list.get(new Random().nextInt(3)));
item.setId(i);
return item;
}
}
我们把实时的商品数据流进行分流,分成 even 和 odd 两个流进行 JOIN,条件是名称相同,最后,把两个流的 JOIN 结果输出。
class StreamingDemo {
public static void main(String[] args) throws Exception {
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
SingleOutputStreamOperator- source = bsEnv.addSource(new MyStreamingSource()).map(new MapFunction
() {
@Override
public Item map(Item item) throws Exception {
return item;
}
});
DataStream- evenSelect = source.split(new OutputSelector
- () {
@Override
public Iterable
select(Item value) {
List output = new ArrayList<>();
if (value.getId() % 2 == 0) {
output.add("even");
} else {
output.add("odd");
}
return output;
}
}).select("even");
DataStream- oddSelect = source.split(new OutputSelector
- () {
@Override
public Iterable
select(Item value) {
List output = new ArrayList<>();
if (value.getId() % 2 == 0) {
output.add("even");
} else {
output.add("odd");
}
return output;
}
}).select("odd");
bsTableEnv.createTemporaryView("evenTable", evenSelect, "name,id");
bsTableEnv.createTemporaryView("oddTable", oddSelect, "name,id");
Table queryTable = bsTableEnv.sqlQuery("select a.id,a.name,b.id,b.name from evenTable as a join oddTable as b on a.name = b.name");
queryTable.printSchema();
bsTableEnv.toRetractStream(queryTable, TypeInformation.of(new TypeHint>(){})).print();
bsEnv.execute("streaming sql job");
}
}
结果如下: