Java应用调优实战-实战案例与高频面试点
缓冲区如何让代码加速
文件读写流
接下来,我会以文件读取和写入字符流为例进行讲解。
Java 的 I/O 流设计,采用的是装饰器模式,当需要给类添加新的功能时,就可以将被装饰者通过参数传递到装饰者,封装成新的功能方法。下图是装饰器模式的典型示意图,就增加功能来说,装饰模式比生成子类更为灵活。

在读取和写入流的 API 中,BufferedInputStream 和 BufferedReader 可以加快读取字符的速度,BufferedOutputStream 和 BufferedWriter 可以加快写入的速度。
下面是直接读取文件的代码实现:
int result = 0;
try (Reader reader = new FileReader(FILE_PATH)) {
int value;
while ((value = reader.read()) != -1) {
result += value;
}
}
return result;
要使用缓冲方式读取,只需要将 FileReader 装饰一下即可:
int result = 0;
try (Reader reader = new BufferedReader(new FileReader(FILE_PATH))) {
int value;
while ((value = reader.read()) != -1) {
result += value;
}
}
return result;
我们先看一下与之类似的,BufferedInputStream 类的具体实现方法:
//代码来自JDK
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
当缓冲区的内容读取完毕,将尝试使用 fill 函数把输入流读入缓冲区:
//代码来自JDK
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0; /* no mark: throw away the buffer */
else if (pos >= buffer.length) /* no room left in buffer */
if (markpos > 0) {
/* can throw away early part of the buffer */
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else if (buffer.length >= MAX_BUFFER_SIZE) {
throw new OutOfMemoryError("Required array size too large");
} else {
/* grow buffer */
int nsz = (pos <= MAX_BUFFER_SIZE - pos) ?
pos * 2 : MAX_BUFFER_SIZE;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
程序会调整一些读取的位置,并对缓冲区进行位置更新,然后使用被装饰的 InputStream 进行数据读取:
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
那么为什么要这么做呢?直接读写不行吗?
这是因为:字符流操作的对象,一般是文件或者 Socket,要从这些缓慢的设备中,通过频繁的交互获取数据,效率非常慢;而缓冲区的数据是保存在内存中的,能够显著地提升读写速度。
既然好处那么多,为什么不把所有的数据全部读到缓冲区呢?
这就是一个权衡的问题,缓冲区开得太大,会增加单次读写的时间,同时内存价格很高,不能无限制使用,缓冲流的默认缓冲区大小是 8192 字节,也就是 8KB,算是一个比较折中的值。
这好比搬砖,如果一块一块搬,时间便都耗费在往返路上了;但若给你一个小推车,往返的次数便会大大降低,效率自然会有所提升。
下图是使用 FileReader 和 BufferedReader 读取文件的 JMH 对比(相关代码见仓库),可以看到,使用了缓冲,读取效率有了很大的提升(暂未考虑系统文件缓存)。

日志缓冲
日志是程序员们最常打交道的地方。在高并发应用中,即使对日志进行了采样,日志数量依旧惊人,所以选择高速的日志组件至关重要。
SLF4J 是 Java 里标准的日志记录库,它是一个允许你使用任何 Java 日志记录库的抽象适配层,最常用的实现是 Logback,支持修改后自动 reload,它比 Java 自带的 JUL 还要流行。
Logback 性能也很高,其中一个原因就是异步日志,它在记录日志时,使用了一个缓冲队列,当缓冲的内容达到一定的阈值时,才会把缓冲区的内容写到文件里。使用异步日志有两个考虑:
- 同步日志的写入,会阻塞业务,导致服务接口的耗时增加;
- 日志写入磁盘的代价是昂贵的,如果每产生一条日志就写入一次,CPU 会花很多时间在磁盘 I/O 上。
Logback 的异步日志也比较好配置,我们需要在正常配置的基础上,包装一层异步输出的逻辑(详见仓库)。
<appender name ="ASYNC" class= "ch.qos.logback.classic.AsyncAppender">
<discardingThreshold >0</discardingThreshold>
<queueSize>512</queueSize>
<!--这里指定了一个已有的Appender-->
<appender-ref ref ="FILE"/>
</appender>
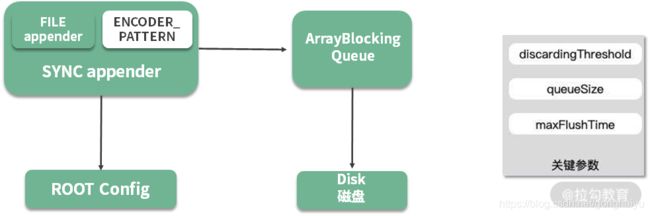
如上图,异步日志输出之后,日志信息将暂存在 ArrayBlockingQueue 列表中,后台会有一个 Worker 线程不断地获取缓冲区内容,然后写入磁盘中。
上图中有三个关键参数:
- queueSize,代表了队列的大小,默认是256。如果这个值设置的太大,大日志量下突然断电,会丢掉缓冲区的内容;
- maxFlushTime,关闭日志上下文后,继续执行写任务的时间,这是通过调用 Thread 类的 join 方法来实现的(worker.join(maxFlushTime));
- discardingThreshold,当 queueSize 快达到上限时,可以通过配置,丢弃一些级别比较低的日志,这个值默认是队列长度的 80%;但若你担心可能会丢失业务日志,则可以将这个值设置成 0,表示所有的日志都要打印。
缓冲区优化思路
毫无疑问缓冲区是可以提高性能的,但它通常会引入一个异步的问题,使得编程模型变复杂。
通过文件读写流和 Logback 两个例子,我们来看一下对于缓冲区设计的一些常规操作。
如下图所示,资源 A 读取或写入一些操作到资源 B,这本是一个正常的操作流程,但由于中间插入了一个额外的存储层,所以这个流程被生生截断了,这时就需要你手动处理被截断两方的资源协调问题。
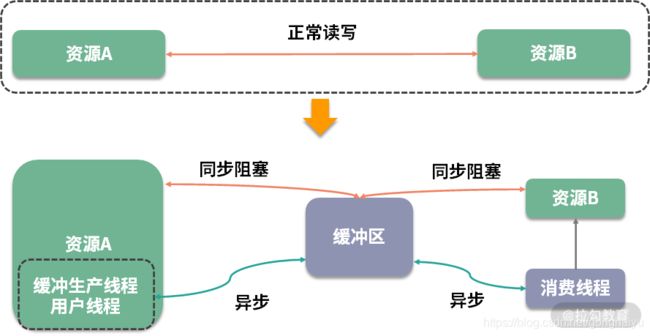
根据资源的不同,对正常业务进行截断后的操作,分为同步操作和异步操作。
同步操作
同步操作的编程模型相对简单,在一个线程中就可完成,你只需要控制缓冲区的大小,并把握处理的时机。比如,缓冲区大小达到阈值,或者缓冲区的元素在缓冲区的停留时间超时,这时就会触发批量操作。
由于所有的操作又都在单线程,或者同步方法块中完成,再加上资源 B 的处理能力有限,那么很多操作就会阻塞并等待在调用线程上。比如写文件时,需要等待前面的数据写入完毕,才能处理后面的请求。
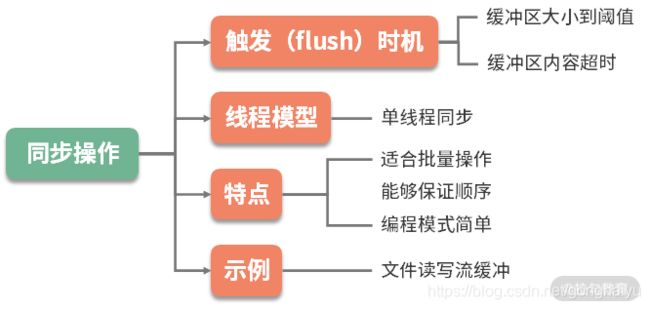
异步操作
异步操作就复杂很多。
缓冲区的生产者一般是同步调用,但也可以采用异步方式进行填充,一旦采用异步操作,就涉及缓冲区满了以后,生产者的一些响应策略。
此时,应该将这些策略抽象出来,根据业务的属性选择,比如直接抛弃、抛出异常,或者直接在用户的线程进行等待。你会发现它与线程池的饱和策略是类似的,这部分的详细概念将在 12 课时讲解。
许多应用系统还会有更复杂的策略,比如在用户线程等待,设置一个超时时间,以及成功进入缓冲区之后的回调函数等。
对缓冲区的消费,一般采用开启线程的方式,如果有多个线程消费缓冲区,还会存在信息同步和顺序问题。

Kafka缓冲区示例
- Kafka 的生产者,有可能会丢数据吗?

如图,要想解答这个问题,需要先了解 Kafka 对生产者的一些封装,其中有一个对性能影响非常大的点,就是缓冲。
生产者会把发送到同一个 partition 的多条消息,封装在一个 batch(缓冲区)中。当 batch 满了(参数 batch.size),或者消息达到了超时时间(参数 linger.ms),缓冲区中的消息就会被发送到 broker 上。
这个缓冲区默认是 16KB,如果生产者的业务突然断电,这 16KB 数据是没有机会发送出去的。此时,就造成了消息丢失。
解决的办法有两种:
(1). 把缓冲区设置得非常小,此时消息会退化成单条发送,这会严重影响性能;
(2). 消息发送前记录一条日志,消息发送成功后,通过回调再记录一条日志,通过扫描生成的日志,就可以判断哪些消息丢失了。
- Kafka 生产者会影响业务的高可用吗?
这同样和生产者的缓冲区有关。缓冲区大小毕竟是有限制的,如果消息产生得过快,或者生产者与 broker 节点之间有网络问题,缓冲区就会一直处于 full 的状态。此时,有新的消息到达,会如何处理呢?
通过配置生产者的超时参数和重试次数,可以让新的消息一直阻塞在业务方。一般来说,这个超时值设置成 1 秒就已经够大了,有的应用在线上把超时参数配置得非常大,比如 1 分钟,就造成了用户的线程迅速占满,整个业务不能再接受新的请求。
- 其他做法
使用缓冲区来提升性能的做法非常多,下面再举几个例子:
(1)StringBuilder 和 StringBuffer,通过将要处理的字符串缓冲起来,最后完成拼接,提高字符串拼接的性能;
(2)操作系统在写入磁盘,或者网络 I/O 时,会开启特定的缓冲区,来提升信息流转的效率。通常可使用 flush 函数强制刷新数据,比如通过调整 Socket 的参数 SO_SNDBUF 和 SO_RCVBUF 提高网络传输性能;
(3)在一些比较底层的工具中,也会变相地用到缓冲。比如常见的 ID 生成器,使用方通过缓冲一部分 ID 段,就可以避免频繁、耗时的交互。
- 注意事项
虽然缓冲区可以帮我们大大地提高应用程序的性能,但同时它也有不少问题,在我们设计时,要注意这些异常情况。
其中,比较严重就是缓冲区内容的丢失。即使你使用 addShutdownHook 做了优雅关闭,有些情形依旧难以防范避免,比如机器突然间断电,应用程序进程突然死亡等。这时,缓冲区内未处理完的信息便会丢失,尤其金融信息,电商订单信息的丢失都是比较严重的。
所以,内容写入缓冲区之前,需要先预写日志,故障后重启时,就会根据这些日志进行数据恢复。在数据库领域,文件缓冲的场景非常多,一般都是采用 WAL 日志(Write-Ahead Logging)解决。对数据完整性比较严格的系统,甚至会通过电池或者 UPS 来保证缓冲区的落地。这就是性能优化带来的新问题,必须要解决。
无处不在的缓存,高并发系统的法宝
在我们平常的应用开发中,根据缓存所处的物理位置,一般分为进程内缓存和进程外缓存。
本课时我们主要聚焦在进程内缓存上,在 Java 中,进程内缓存,就是我们常说的堆内缓存。Spring 的默认实现里,就包含 Ehcache、JCache、Caffeine、Guava Cache 等。
Guava 的 LoadingCache
Guava 是一个常用的工具包,其中的 LoadingCache(下面简称 LC),是非常好用的堆内缓存工具。通过学习 LC 的结构,即可了解堆内缓存设计的一般思路。
缓存一般是比较昂贵的组件,容量是有限制的,设置得过小,或者过大,都会影响缓存性能:
- 缓存空间过小,就会造成高命中率的元素被频繁移出,失去了缓存的意义;
- 缓存空间过大,不仅浪费宝贵的缓存资源,还会对垃圾回收产生一定的压力。
通过 Maven,即可引入 guava 的 jar 包:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
下面介绍一下 LC 的常用操作:

缓存初始化
首先,我们可以通过下面的参数设置一下 LC 的大小。一般,我们只需给缓存提供一个上限。
- maximumSize 这个参数用来设置缓存池的最大容量,达到此容量将会清理其他元素;
- initialCapacity 默认值是 16,表示初始化大小;
- concurrencyLevel 默认值是 4,和初始化大小配合使用,表示会将缓存的内存划分成 4 个 segment,用来支持高并发的存取。
缓存操作
那么缓存数据是怎么放进去的呢?有两种模式:
- 使用 put 方法手动处理,比如,我从数据库里查询出一个 User 对象,然后手动调用代码进去;
- 主动触发( 这也是 Loading 这个词的由来),通过提供一个 CacheLoader 的实现,就可以在用到这个对象的时候,进行延迟加载。
public static void main(String[] args) {
LoadingCache<String, String> lc = CacheBuilder
.newBuilder()
.build(new CacheLoader<String, String>() {
@Override
public String load(String key) throws Exception {
return slowMethod(key);
}
});
}
static String slowMethod(String key) throws Exception {
Thread.sleep(1000);
return key + ".result";
}
上面是主动触发的示例代码,你可以使用 get 方法获取缓存的值。比如,当我们执行 lc.get(“a”) 时,第一次会比较缓慢,因为它需要到数据源进行获取;第二次就瞬间返回了,也就是缓存命中了。具体时序可以参见下面这张图。

除了靠 LC 自带的回收策略,我们也可以手动删除某一个元素,这就是 invalidate 方法。当然,数据的这些删除操作,也是可以监听到的,只需要设置一个监听器就可以了,代码如下:
.removalListener(notification -> System.out.println(notification))
回收策略
缓存的大小是有限的,满了以后怎么办?这就需要回收策略进行处理,接下来我会向你介绍三种回收策略。
(1)第一种回收策略基于容量
这个比较好理解,也就是说如果缓存满了,就会按照 LRU 算法来移除其他元素。
(2)第二种回收策略基于时间
一种方式是,通过 expireAfterWrite 方法设置数据写入以后在某个时间失效;
另一种是,通过 expireAfterAccess 方法设置最早访问的元素,并优先将其删除。
(3)第三种回收策略基于 JVM 的垃圾回收
我们都知道对象的引用有强、软、弱、虚等四个级别,通过 weakKeys 等函数即可设置相应的引用级别。当 JVM 垃圾回收的时候,会主动清理这些数据。
关于第三种回收策略,有一个高频面试题:如果你同时设置了 weakKeys 和 weakValues函数,LC 会有什么反应?
答案:如果同时设置了这两个函数,它代表的意思是,当没有任何强引用,与 key 或者 value 有关系时,就删掉整个缓存项。这两个函数经常被误解。
缓存造成内存故障
LC 可以通过 recordStats 函数,对缓存加载和命中率等情况进行监控。
值得注意的是:LC 是基于数据条数而不是基于缓存物理大小的,所以如果你缓存的对象特别大,就会造成不可预料的内存占用。
围绕这点,我分享一个由于不正确使用缓存导致的常见内存故障。
大多数堆内缓存,都会将对象的引用设置成弱引用或软引用,这样内存不足时,可以优先释放缓存占用的空间,给其他对象腾出地方。这种做法的初衷是好的,但容易出现问题。
当你的缓存使用非常频繁,数据量又比较大的情况下,缓存会占用大量内存,如果此时发生了垃圾回收(GC),缓存空间会被释放掉,但又被迅速占满,从而会再次触发垃圾回收。如此往返,GC 线程会耗费大量的 CPU 资源,缓存也就失去了它的意义。
所以在这种情况下,把缓存设置的小一些,减轻 JVM 的负担,是一个很好的方法。
缓存算法
算法介绍
堆内缓存最常用的有 FIFO、LRU、LFU 这三种算法。
- FIFO
这是一种先进先出的模式。如果缓存容量满了,将会移除最先加入的元素。这种缓存实现方式简单,但符合先进先出的队列模式场景的功能不多,应用场景较少。 - LRU
LRU 是最近最少使用的意思,当缓存容量达到上限,它会优先移除那些最久未被使用的数据,LRU是目前最常用的缓存算法,稍后我们会使用 Java 的 API 简单实现一个。 - LFU
LFU 是最近最不常用的意思。相对于 LRU 的时间维度,LFU 增加了访问次数的维度。如果缓存满的时候,将优先移除访问次数最少的元素;而当有多个访问次数相同的元素时,则优先移除最久未被使用的元素。
实现一个 LRU 算法
Java 里面实现 LRU 算法可以有多种方式,其中最常用的就是 LinkedHashMap,这也是一个需要你注意的面试高频考点。
首先,我们来看一下 LinkedHashMap 的构造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder)
accessOrder 参数是实现 LRU 的关键。当 accessOrder 的值为 true 时,将按照对象的访问顺序排序;当 accessOrder 的值为 false 时,将按照对象的插入顺序排序。我们上面提到过,按照访问顺序排序,其实就是 LRU。
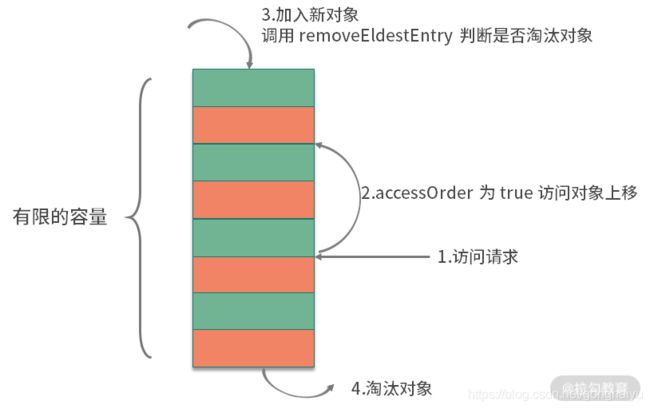
如上图,按照缓存的一般设计方式,和 LC 类似,当你向 LinkedHashMap 中添加新对象的时候,就会调用 removeEldestEntry 方法。这个方法默认返回 false,表示永不过期。我们只需要覆盖这个方法,当超出容量的时候返回 true,触发移除动作就可以了。关键代码如下:
public class LRU extends LinkedHashMap {
int capacity;
public LRU(int capacity) {
super(16, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
}
相比较 LC,这段代码实现的功能是比较简陋的,它甚至不是线程安全的,但它体现了缓存设计的一般思路,是 Java 中最简单的 LRU 实现方式。
进一步加速
在 Linux 系统中,通过 free 命令,能够看到系统内存的使用状态。其中,有一块叫作 cached 的区域,占用了大量的内存空间。

如图所示,这个区域,其实就是存放了操作系统的文件缓存,当应用再次用到它的时候,就不用再到磁盘里走一圈,能够从内存里快速载入。
在文件读取的缓存方面,操作系统做得更多。由于磁盘擅长顺序读写,在随机读写的时候,效率很低,所以,操作系统使用了智能的预读算法(readahead),将数据从硬盘中加载到缓存中。
预读算法有三个关键点:
- 预测性,能够根据应用的使用数据,提前预测应用后续的操作目标;
- 提前,能够将这些数据提前加载到缓存中,保证命中率;
- 批量,将小块的、频繁的读取操作,合并成顺序的批量读取,提高性能。
预读技术一般都是比较智能的,能够覆盖大多数后续的读取操作。举个极端的例子,如果我们的数据集合比较小,访问频率又非常高,就可以使用完全载入的方式,来替换懒加载的方式。在系统启动的时候,将数据加载到缓存中。
缓存优化的一般思路
一般,缓存针对的主要是读操作。当你的功能遇到下面的场景时,就可以选择使用缓存组件进行性能优化:
- 存在数据热点,缓存的数据能够被频繁使用;
- 读操作明显比写操作要多;
- 下游功能存在着比较悬殊的性能差异,下游服务能力有限;
- 加入缓存以后,不会影响程序的正确性,或者引入不可预料的复杂性。
缓存组件和缓冲类似,也是在两个组件速度严重不匹配的时候,引入的一个中间层,但它们服务的目标是不同的:
- 缓冲,数据一般只使用一次,等待缓冲区满了,就执行 flush 操作;
- 缓存,数据被载入之后,可以多次使用,数据将会共享多次。
缓存最重要的指标就是命中率,有以下几个因素会影响命中率。
(1)缓存容量
缓存的容量总是有限制的,所以就存在一些冷数据的逐出问题。但缓存也不是越大越好,它不能明显挤占业务的内存。
(2)数据集类型
如果缓存的数据是非热点数据,或者是操作几次就不再使用的冷数据,那命中率肯定会低,缓存也会失去了它的作用。
(3)缓存失效策略
缓存算法也会影响命中率和性能,目前效率最高的算法是 Caffeine 使用的 W-TinyLFU 算法,它的命中率非常高,内存占用也更小。新版本的 spring-cache,已经默认支持 Caffeine。
推荐使用 Guava Cache 或者 Caffeine 作为堆内缓存解决方案,然后通过它们提供的一系列监控指标,来调整缓存的大小和内容,一般来说:
- 缓存命中率达到 50% 以上,作用就开始变得显著;
- 缓存命中率低于 10%,那就需要考虑缓存组件的必要性了。
引入缓存组件,能够显著提升系统性能,但也会引入新的问题。其中,最典型的也是面试高频问题:如何保证缓存与源数据的同步?关于这点,我们会在下一课时进行讲解。
接下来,我再简单举两个缓存应用的例子。
第一个是 HTTP 304 状态码,它是 Not Modified 的意思。
浏览器客户端会发送一个条件性的请求,服务端可以通过 If-Modified-Since 头信息判断缓冲的文件是否是最新的。如果是,那么客户端就直接使用缓存,不用进行再读取了。
另一个是关于 CDN,这是一种变相的缓存。
用户会从离它最近最快的节点,读取文件内容。如果这个节点没有缓存这个文件,那么 CDN 节点就会从源站拉取一份,下次有相同的读取请求时,就可以快速返回。
Redis 如何助力秒杀业务
说到 Redis,就不得不提一下另外一个分布式缓存 Memcached(以下简称 MC)。MC 现在已经很少用了,但面试的时候经常会问到它们之间的区别,这里简单罗列一下:

SpringBoot 如何使用 Redis
使用 SpringBoot 可以很容易地对 Redis 进行操作(完整代码见仓库)。Java 的 Redis的客户端,常用的有三个:jedis、redisson 和 lettuce,Spring 默认使用的是 lettuce。
lettuce 是使用 netty 开发的,操作是异步的,性能比常用的 jedis 要高;redisson 也是异步的,但它对常用的业务操作进行了封装,适合书写有业务含义的代码。
通过加入下面的 jar 包即可方便地使用 Redis。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
上面这种方式,我们主要是使用 RedisTemplate 这个类。它针对不同的数据类型,抽象了相应的方法组。
另外一种方式,就是使用 Spring 抽象的缓存包 spring-cache。它使用注解,采用 AOP的方式,对 Cache 层进行了抽象,可以在各种堆内缓存框架和分布式框架之间进行切换。这是它的 maven 坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
与 spring-cache 类似的,还有阿里的 jetcache,都是比较好用的。
使用 spring-cache 有三个步骤:
- 在启动类上加入 @EnableCaching 注解;
- 使用 CacheManager 初始化要使用的缓存框架,使用 @CacheConfig 注解注入要使用的资源;
- 使用 @Cacheable 等注解对资源进行缓存。
我们这里使用的是 RedisCacheManager,由于现在只有这一个初始化实例,第二个步骤是可以省略的。
针对缓存操作的注解,有三个:
@Cacheable 表示如果缓存系统里没有这个数值,就将方法的返回值缓存起来;
@CachePut 表示每次执行该方法,都把返回值缓存起来;
@CacheEvict 表示执行方法的时候,清除某些缓存值。
对于秒杀系统来说,仅仅使用这三个注解是有局限性的,需要使用更加底层的 API,比如 RedisTemplate,来完成逻辑开发,下面就来介绍一些比较重要的功能。
秒杀业务介绍
处理秒杀业务有三个绝招:
- 第一,选择速度最快的内存作为数据写入;
- 第二,使用异步处理代替同步请求;
- 第三,使用分布式横向扩展。
下面,我们就来看一下 Redis 是如何助力秒杀的。
Lua 脚本完成秒杀
一个秒杀系统是非常复杂的,一般来说,秒杀可以分为一下三个阶段:
- 准备阶段,会提前载入一些必需的数据到缓存中,并提前预热业务数据,用户会不断刷新页面,来查看秒杀是否开始;
- 抢购阶段,就是我们通常说的秒杀,会产生瞬时的高并发流量,对资源进行集中操作;
- 结束清算,主要完成数据的一致性,处理一些异常情况和回仓操作。

下面,我将介绍一下最重要的秒杀阶段。我们可以设计一个 Hash 数据结构,来支持库存的扣减。
seckill:goods:${
goodsId}{
total: 100,
start: 0,
alloc:0
}
在这个 Hash 数据结构中,有以下三个重要部分:
- total 是一个静态值,表示要秒杀商品的数量,在秒杀开始前,会将这个数值载入到缓存中。
- start 是一个布尔值。秒杀开始前的值为 0;通过后台或者定时,将这个值改为 1,则表示秒杀开始。
- 此时,alloc 将会记录已经被秒杀的商品数量,直到它的值达到 total 的上限。
static final String goodsId = "seckill:goods:%s";
String getKey(String id) {
return String.format(goodsId, id);
}
public void prepare(String id, int total) {
String key = getKey(id);
Map<String, Integer> goods = new HashMap<>();
goods.put("total", total);
goods.put("start", 0);
goods.put("alloc", 0);
redisTemplate.opsForHash().putAll(key, goods);
}
秒杀的时候,首先需要判断库存,才能够对库存进行锁定。这两步动作并不是原子的,在分布式环境下,多台机器同时对 Redis 进行操作,就会发生同步问题。
为了解决同步问题,一种方式就是使用 Lua 脚本,把这些操作封装起来,这样就能保证原子性;另外一种方式就是使用分布式锁。
缓存穿透、击穿和雪崩
抛开秒杀场景,我们再来看一下分布式缓存系统会存在的三大问题: 缓存穿透、缓存击穿和缓存雪崩 。
1.缓存穿透
本次请求,在缓存和持久层都没有命中,这种情况就叫缓存的穿透。
举个例子,如上图,在一个登录系统中,有外部攻击,一直尝试使用不存在的用户进行登录,这些用户都是虚拟的,不能有效地被缓存起来,每次都会到数据库中查询一次,最后就会造成服务的性能故障。
解决这个问题有多种方案,我们来简单介绍一下。
第一种就是把空对象缓存起来。不是持久层查不到数据吗?那么我们就可以把本次请求的结果设置为 null,然后放入到缓存中。通过设置合理的过期时间,就可以保证后端数据库的安全。
缓存空对象会占用额外的缓存空间,还会有数据不一致的时间窗口,所以第二种方法就是针对大数据量的、有规律的键值,使用布隆过滤器进行处理。
一条记录存在与不存在,是一个 Bool 值,只需要使用 1 比特就可存储。布隆过滤器就可以把这种是、否操作,压缩到一个数据结构中。比如手机号,用户性别这种数据,就非常适合使用布隆过滤器。

2.缓存击穿
缓存击穿,指的也是用户请求落在数据库上的情况,大多数情况,是由于缓存时间批量过期引起的。
我们一般会对缓存中的数据,设置一个过期时间。如果在某个时刻从数据库获取了大量数据,并设置了同样的过期时间,它们将会在同一时刻失效,造成和缓存的击穿。
对于比较热点的数据,我们就可以设置它不过期;或者在访问的时候,更新它的过期时间;批量入库的缓存项,也尽量分配一个比较平均的过期时间,避免同一时间失效。
3.缓存雪崩
雪崩这个词看着可怕,实际情况也确实比较严重。缓存是用来对系统加速的,后端的数据库只是数据的备份,而不是作为高可用的备选方案。
当缓存系统出现故障,流量会瞬间转移到后端的数据库。过不了多久,数据库将会被大流量压垮挂掉,这种级联式的服务故障,可以形象地称为雪崩。

缓存的高可用建设是非常重要的。Redis 提供了主从和 Cluster 的模式,其中 Cluster 模式使用简单,每个分片也能单独做主从,可以保证极高的可用性。
另外,我们对数据库的性能瓶颈有一个大体的评估。如果缓存系统当掉,那么流向数据库的请求,就可以使用限流组件,将请求拦截在外面。
缓存一致性
引入缓存组件后,另外一个老大难的问题,就是缓存的一致性。
我们首先来看问题是怎么发生的。对于一个缓存项来说,常用的操作有四个:写入、更新、读取、删除。
写入:缓存和数据库是两个不同的组件,只要涉及双写,就存在只有一个写成功的可能性,造成数据不一致。
更新:更新的情况类似,需要更新两个不同的组件。
读取:读取要保证从缓存中读到的信息是最新的,是和数据库中的是一致的。
删除:当删除数据库记录的时候,如何把缓存中的数据也删掉?
由于业务逻辑大多数情况下,是比较复杂的。其中的更新操作,就非常昂贵,比如一个用户的余额,就是通过计算一系列的资产算出来的一个数。如果这些关联的资产,每个地方改动的时候,都去刷新缓存,那代码结构就会非常混乱,以至于无法维护。
我推荐使用触发式的缓存一致性方式,使用懒加载的方式,可以让缓存的同步变得非常简单:
当读取缓存的时候,如果缓存里没有相关数据,则执行相关的业务逻辑,构造缓存数据存入到缓存系统;
当与缓存项相关的资源有变动,则先删除相应的缓存项,然后再对资源进行更新,这个时候,即使是资源更新失败,也是没有问题的。
这种操作,除了编程模型简单,有一个明显的好处。我只有在用到这个缓存的时候,才把它加载到缓存系统中。如果每次修改 都创建、更新资源,那缓存系统中就会存在非常多的冷数据。
但这样还是有问题。
我们上面提到的缓存删除动作,和数据库的更新动作,明显是不在一个事务里的。如果一个请求删除了缓存,同时有另外一个请求到来,此时发现没有相关的缓存项,就从数据库里加载了一份到缓存系统。接下来,数据库的更新操作也完成了,此时数据库的内容和缓存里的内容,就产生了不一致。
下面这张图,直观地解释了这种不一致的情况,此时,缓存读取 B 操作以及之后的读取操作,都会读到错误的缓存值。

可以使用分布式锁来解决这个问题,将缓存操作和数据库删除操作,与其他的缓存读操作,使用锁进行资源隔离即可。一般来说,读操作是不需要加锁的,它会在遇到锁的时候,重试等待,直到超时。
本人觉得上面的内容没有说清楚,
建议参考:https://www.cnblogs.com/lzghyh/p/13276514.html
https://blog.csdn.net/qq_20597727/article/details/88652045
https://blog.csdn.net/koli6678/article/details/88202245
池化对象的应用场景
带有evcit 字样的参数,主要是处理对象逐出的。池化对象除了初始化和销毁的时候比较昂贵,在运行时也会占用系统资源。比如,连接池会占用多条连接,线程池会增加调度开销等。业务在突发流量下,会申请到超出正常情况的对象资源,放在池子中。等这些对象不再被使用,我们就需要把它清理掉。
超出 minEvictableIdleTimeMillis 参数指定值的对象,就会被强制回收掉,这个值默认是 30 分钟;softMinEvictableIdleTimeMillis 参数类似,但它只有在当前对象数量大于 minIdle 的时候才会执行移除,所以前者的动作要更暴力一些。
还有 4 个 test 参数:testOnCreate、testOnBorrow、testOnReturn、testWhileIdle,分别指定了在创建、获取、归还、空闲检测的时候,是否对池化对象进行有效性检测。
开启这些检测,能保证资源的有效性,但它会耗费性能,所以默认为 false。生产环境上,建议只将 testWhileIdle 设置为 true,并通过调整空闲检测时间间隔(timeBetweenEvictionRunsMillis),比如 1 分钟,来保证资源的可用性,同时也保证效率。
HikariCP 为什么快呢
- 它使用 FastList 替代 ArrayList,通过初始化的默认值,减少了越界检查的操作;
- 优化并精简了字节码,通过使用 Javassist,减少了动态代理的性能损耗,比如使用 invokestatic 指令代替 invokevirtual 指令;
- 实现了无锁的 ConcurrentBag,减少了并发场景下的锁竞争。
数据库连接池同样面临一个最大值(maximumPoolSize)和最小值(minimumIdle)的问题。这里同样有一个非常高频的面试题:你平常会把连接池设置成多大呢?
很多同学认为,连接池的大小设置得越大越好,有的同学甚至把这个值设置成 1000 以上,这是一种误解。根据经验,数据库连接,只需要 20~50 个就够用了。具体的大小,要根据业务属性进行调整,但大得离谱肯定是不合适的。
HikariCP 官方是不推荐设置 minimumIdle 这个值的,它将被默认设置成和 maximumPoolSize 一样的大小。如果你的数据库Server端连接资源空闲较大,不妨也可以去掉连接池的动态调整功能。
另外,根据数据库查询和事务类型,一个应用中是可以配置多个数据库连接池的,这个优化技巧很少有人知道,在此简要描述一下。
业务类型通常有两种:一种需要快速的响应时间,把数据尽快返回给用户;另外一种是可以在后台慢慢执行,耗时比较长,对时效性要求不高。如果这两种业务类型,共用一个数据库连接池,就容易发生资源争抢,进而影响接口响应速度。虽然微服务能够解决这种情况,但大多数服务是没有这种条件的,这时就可以对连接池进行拆分。
如图,在同一个业务中,根据业务的属性,我们分了两个连接池,就是来处理这种情况的。

HikariCP 还提到了另外一个知识点,在 JDBC4 的协议中,通过 Connection.isValid() 就可以检测连接的有效性。这样,我们就不用设置一大堆的 test 参数了,HikariCP 也没有提供这样的参数。
总体来说,当你遇到下面的场景,就可以考虑使用池化来增加系统性能:
- 对象的创建或者销毁,需要耗费较多的系统资源;
- 对象的创建或者销毁,耗时长,需要繁杂的操作和较长时间的等待;
- 对象创建后,通过一些状态重置,可被反复使用。
大对象复用的目标和注意点
那么为什么大对象会影响我们的应用性能呢?
第一,大对象占用的资源多,垃圾回收器要花一部分精力去对它进行回收;
第二,大对象在不同的设备之间交换,会耗费网络流量,以及昂贵的 I/O;
第三,对大对象的解析和处理操作是耗时的,对象职责不聚焦,就会承担额外的性能开销。
结合我们前面提到的缓存,以及对象的池化操作,加上对一些中间结果的保存,我们能够对大对象进行初步的提速。
但这还远远不够,我们仅仅减少了对象的创建频率,但并没有改变对象“大”这个事实。下面从几个知识点将大对象变小。
substring 生成了一个新的字符串,这个字符串通过构造函数的 Arrays.copyOfRange 函数进行构造。这个函数在 JDK7 之后是没有问题的,但在 JDK6 中,却有着内存泄漏的风险。
String 的 substring 方法
我们都知道,String 在 Java 中是不可变的,如果你改动了其中的内容,它就会生成一个新的字符串。如果我们想要用到字符串中的一部分数据,就可以使用 substring 方法。
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
这个是jdk1.7中的写法,但是在jdk1.6中确有内存泄漏的风险。下面看下源代码。
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ? this : //如果开始位置等于且结束为止等于count字符个数。那么就返回本身
new String(offset + beginIndex, endIndex - beginIndex, value); //否则创建一个新的字符串对象
}
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
可以看到,它在创建子字符串的时候,并不只拷贝所需要的对象,而是把整个 value 引用了起来。如果原字符串比较大,即使不再使用,内存也不会释放。

集合大对象扩容
- StringBuilder,容量不够的时候,会将内存翻倍,并使用 Arrays.copyOf 复制源数据。
- HashMap 的扩容代码,扩容后大小也是翻倍。但是要注意,HashMap 有负载因子的集合(0.75),初始化大小 = 需要的个数/负载因子+1
- List 的代码大家可自行查看,也是阻塞性的,扩容策略是原长度的 1.5 倍。
由于集合在代码中使用的频率非常高,如果你知道具体的数据项上限,那么不妨设置一个合理的初始化大小。比如,HashMap 需要 1024 个元素,需要 7 次扩容,会影响应用的性能。面试中会频繁出现这个问题,你需要了解这些扩容操作对性能的影响。
数据的冷热分离
冷热分离是把数据分成两份,如下图,一般都会保持一份全量数据,用来做一些耗时的统计操作。

由于冷热分离在工作中经常遇到,所以面试官会频繁问到数据冷热分离的方案。下面简单介绍三种:
1.数据双写
把对冷热库的插入、更新、删除操作,全部放在一个统一的事务里面。由于热库(比如 MySQL)和冷库(比如 Hbase)的类型不同,这个事务大概率会是分布式事务。在项目初期,这种方式是可行的,但如果是改造一些遗留系统,分布式事务基本上是改不动的,我通常会把这种方案直接废弃掉。
2.写入 MQ 分发
通过 MQ 的发布订阅功能,在进行数据操作的时候,先不落库,而是发送到 MQ 中。单独启动消费进程,将 MQ 中的数据分别落到冷库、热库中。使用这种方式改造的业务,逻辑非常清晰,结构也比较优雅。像订单这种结构比较清晰、对顺序性要求较低的系统,就可以采用 MQ 分发的方式。但如果你的数据库实体量非常大,用这种方式就要考虑程序的复杂性了。
3.使用 Binlog 同步
针对 MySQL,就可以采用 Binlog 的方式进行同步,使用 Canal 组件,可持续获取最新的 Binlog 数据,结合 MQ,可以将数据同步到其他的数据源中。
大家应该都听过 google 的 protobuf,由于它是二进制协议,而且对数据进行了压缩,性能是非常优越的。protobuf 对数据压缩后,大小只有 json 的 1/10,xml 的 1/20,但是性能却提高了 5-100 倍。
protobuf 的设计是值得借鉴的,它通过 tag|leng|value 三段对数据进行了非常紧凑的处理,解析和传输速度都特别快。
如何用设计模式优化性能
代理模式
代理模式(Proxy)可以通过一个代理类,来控制对一个对象的访问。
Java 中实现动态代理主要有两种模式:一种是使用 JDK,另外一种是使用 CGLib。
其中,JDK 方式是面向接口的,主 要的相关类是 InvocationHandler 和 Proxy;
CGLib 可以代理普通类,主要的相关类是 MethodInterceptor 和 Enhancer。
这个知识点面试频率非常高,仓库中有这两个实现的完整代码,这里就不贴出来了。
我现在用的 JDK 版本是 1.8,可以看到,CGLib 的速度并没有传得那么快(有传言高出10 倍),相比较而言,它的速度甚至略有下降。
我们再来看下代理的创建速度,结果如下所示。可以看到,在代理类初始化方面,JDK 的吞吐量要高出 CGLib 一倍。
Benchmark Mode Cnt Score Error Units
ProxyCreateBenchmark.cglib thrpt 10 7281.487 ± 1339.779 ops/ms
ProxyCreateBenchmark.jdk thrpt 10 15612.467 ± 268.362 ops/ms
综上所述,JDK 动态代理和 CGLib 代理的创建速度和执行速度,在新版本的 Java 中差别并不是很大,Spring 选用了 CGLib,主要是因为它能够代理普通类的缘故。
单例模式
Spring 在创建组件的时候,可以通过 scope 注解指定它的作用域,用来标示这是一个prototype(多例)还是 singleton(单例)。
当指定为单例时(默认行为),在 Spring 容器中,组件有且只有一份,当你注入相关组件的时候,获取的组件实例也是同一份。
如果是普通的单例类,我们通常将单例的构造方法设置成私有的,单例有懒汉加载和饿汉加载模式。
了解 JVM 类加载机制的同学都知道,一个类从加载到初始化,要经历 5 个步骤:加载、验证、准备、解析、初始化。

其中,static 字段和 static 代码块,是属于类的,在类加载的初始化阶段就已经被执行。它在字节码中对应的是 方法,属于类的(构造方法)。因为类的初始化只有一次,所以它就能够保证这个加载动作是线程安全的。
根据以上原理,只要把单例的初始化动作,放在方法里,就能够实现饿汉模式。
private static Singleton instace = new Singleton();
饿汉模式在代码里用的很少,它会造成资源的浪费,生成很多可能永远不会用到的对象。
而对象初始化就不一样了。通常,我们在 new 一个新对象的时候,都会调用它的构造方法,就是,用来初始化对象的属性。由于在同一时刻,多个线程可以同时调用函数,我们就需要使用 synchronized 关键字对生成过程进行同步。
目前,公认的兼顾线程安全和效率的单例模式,就是 double check。很多面试官,会要求你手写,并分析 double check 的原理。
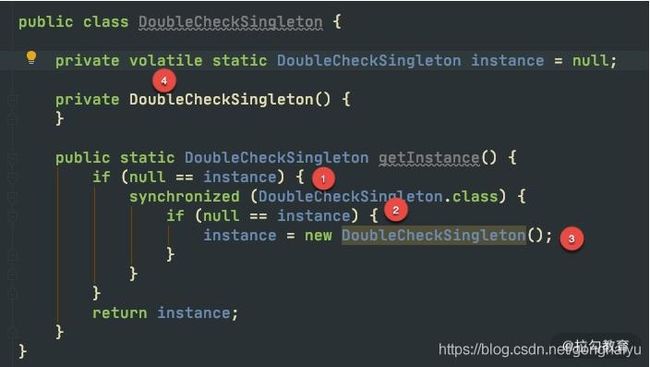
如上图,是 double check 的关键代码,我们介绍一下四个关键点:
第一次检查,当 instance 为 null 的时候,进入对象实例化逻辑,否则直接返回。
加同步锁,这里是类锁。
第二次检查才是关键。如果不加这次判空动作,可能会有多个线程进入同步代码块,进而生成多个实例。
最后一个关键点是 volatile 关键字。在一些低版本的 Java 里,由于指令重排的缘故,可能会导致单例被 new 出来后,还没来得及执行构造函数,就被其他线程使用。 这个关键字,可以阻止字节码指令的重排序,在写 double check 代码时,习惯性会加上 volatile。
可以看到,double check 的写法繁杂,注意点很多,它现在其实是一种反模式,已经不推荐使用了,我也不推荐你用在自己的代码里。但它能够考察面试者对并发的理解,所以这个问题经常被问到。
推荐使用 enum 实现懒加载的单例。这是《Effective Java》推荐的方法。
public class EnumSingleton {
private EnumSingleton() {
}
public static EnumSingleton getInstance() {
return Holder.HOLDER.instance;
}
private enum Holder {
HOLDER;
private final EnumSingleton instance;
Holder() {
instance = new EnumSingleton();
}
}
}
并行计算让代码“飞”起来
在我们的平常的业务中,有计算密集型任务和 I/O 密集型任务之分。
I/O 密集型任务
对于我们常见的互联网服务来说,大多数是属于 I/O 密集型的,比如等待数据库的 I/O,等待网络 I/O 等。在这种情况下,当线程数量等于 I/O 任务的数量时,效果是最好的。虽然线程上下文切换会有一定的性能损耗,但相对于缓慢的 I/O 来说,这点损失是可以接受的。
我们上面说的这种情况,是针对同步 I/O 来说的,基本上是一个任务对应一个线程。异步 NIO 会加速这个过程,《15 | 案例分析:从 BIO 到 NIO,再到 AIO》将对其进行详细讲解。
计算密集型任务
计算密集型的任务却正好相反,比如一些耗时的算法逻辑。CPU 要想达到最高的利用率,提高吞吐量,最好的方式就是:让它尽量少地在任务之间切换,此时,线程数等于 CPU 数量,是效率最高的。
了解了任务的这些特点,就可以通过调整线程数量增加服务性能。比如,高性能的网络工具包 Netty,EventLoop 默认的线程数量,就是处理器的 2 倍。如果我们的业务 I/O 比较耗时,此时就容易造成任务的阻塞,解决方式有两种:一是提高 worker 线程池的大小,另外一种方式是让耗时的操作在另外的线程池里运行。
在 SpringBoot 中如何使用异步?
SpringBoot 中可以非常容易地实现异步任务。
首先,我们需要在启动类上加上 @EnableAsync 注解,然后在需要异步执行的方法上加上 @Async 注解。一般情况下,我们的任务直接在后台运行就可以,但有些任务需要返回一些数据,这个时候,就可以使用 Future 返回一个代理,供其他的代码使用。
关键代码如下:

默认情况下,Spring 将启动一个默认的线程池供异步任务使用。这个线程池也是无限大的,资源使用不可控,所以强烈建议你使用代码设置一个适合自己的。
@Bean
public ThreadPoolTaskExecutor getThreadPoolTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(100);
taskExecutor.setMaxPoolSize(200);
taskExecutor.setQueueCapacity(100);
taskExecutor.setKeepAliveSeconds(60);
taskExecutor.setThreadNamePrefix("test-");
taskExecutor.initialize();
return taskExecutor;
}
多线程资源盘点
1.线程安全的类
我们在上面谈到了 HashMap 和 ConcurrentHashMap,后者相对于前者,是线程安全的。多线程的细节非常多,下面我们就来盘点一下,一些常见的线程安全的类。
注意,下面的每一个对比,都是面试中的知识点,想要更加深入地理解,你需要阅读 JDK 的源码。
StringBuilder 对应着 StringBuffer。后者主要是通过 synchronized 关键字实现了线程的同步。值得注意的是,在单个方法区域里,这两者是没有区别的,JIT 的编译优化会去掉 synchronized 关键字的影响。
HashMap 对应着 ConcurrentHashMap。ConcurrentHashMap 的话题很大,这里提醒一下 JDK1.7 和 1.8 之间的实现已经不一样了。1.8 已经去掉了分段锁的概念(锁分离技术),并且使用 synchronized 来代替了 ReentrantLock。
ArrayList 对应着 CopyOnWriteList。后者是写时复制的概念,适合读多写少的场景。
LinkedList 对应着 ArrayBlockingQueue。ArrayBlockingQueue 对默认是不公平锁,可以修改构造参数,将其改成公平阻塞队列,它在 concurrent 包里使用得非常频繁。
HashSet 对应着 CopyOnWriteArraySet。
下面以一个经常发生问题的案例,来说一下线程安全的重要性。
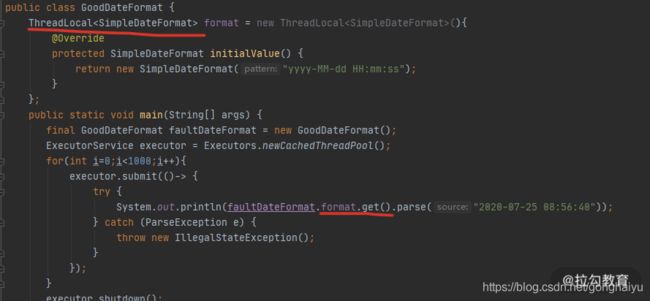
SimpleDateFormat 是我们经常用到的日期处理类,但它本身不是线程安全的,在多线程运行环境下,会产生很多问题,在以往的工作中,通过 sonar 扫描,我发现这种误用的情况特别的多。在面试中,我也会专门问到 SimpleDateFormat,用来判断面试者是否具有基本的多线程编程意识。

解决方式就是使用 ThreadLocal 局部变量,代码如下图所示,可以有效地解决线程安全问题。
2.线程的同步方式
Java 中实现线程同步的方式有很多,大体可以分为以下 8 类。
使用 Object 类中的 wait、notify、notifyAll 等函数。由于这种编程模型非常复杂,现在已经很少用了。这里有一个关键点,那就是对于这些函数的调用,必须放在同步代码块里才能正常运行。
使用 ThreadLocal 线程局部变量的方式,每个线程一个变量,本课时会详细讲解。
使用 synchronized 关键字修饰方法或者代码块。这是 Java 中最常见的方式,有锁升级的概念。
使用 Concurrent 包里的可重入锁 ReentrantLock。使用 CAS 方式实现的可重入锁。
使用 volatile 关键字控制变量的可见性,这个关键字保证了变量的可见性,但不能保证它的原子性。
使用线程安全的阻塞队列完成线程同步。比如,使用 LinkedBlockingQueue 实现一个简单的生产者消费者。
使用原子变量。Atomic* 系列方法,也是使用 CAS 实现的,关于 CAS,我们将在下一课时介绍。
使用 Thread 类的 join 方法,可以让多线程按照指定的顺序执行。
下面的截图,是使用 LinkedBlockingQueue 实现的一个简单生产者和消费者实例,在很多互联网的笔试环节,这个题目会经常出现。 可以看到,我们还使用了一个 volatile 修饰的变量,来决定程序是否继续运行,这也是 volatile 变量的常用场景。

FastThreadLocal
在我们平常的编程中,使用最多的就是 ThreadLocal 类了。拿最常用的 Spring 来说,它事务管理的传播机制,就是使用 ThreadLocal 实现的。因为 ThreadLocal 是线程私有的,所以 Spring 的事务传播机制是不能够跨线程的。在问到 Spring 事务管理是否包含子线程时,要能够想到面试官的真实意图。
既然 Java 中有了 ThreadLocal 类了,为什么 Netty 还自己创建了一个叫作 FastThreadLocal 的结构?
我们首先来看一下 ThreadLocal 的实现。
Thread 类中,有一个成员变量 ThreadLocals,存放了与本线程相关的所有自定义信息。对这个变量的定义在 Thread 类,而操作却在 ThreadLocal 类中。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
...
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
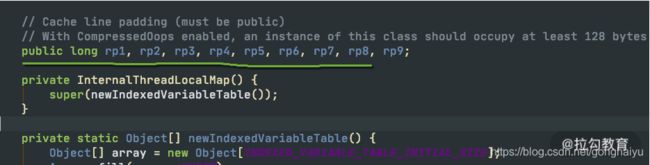
问题就出在 ThreadLocalMap 类上,它虽然叫 Map,但却没有实现 Map 的接口。如下图,ThreadLocalMap 在 rehash 的时候,并没有采用类似 HashMap 的数组+链表+红黑树的做法,它只使用了一个数组,使用开放寻址(遇到冲突,依次查找,直到空闲位置)的方法,这种方式是非常低效的。
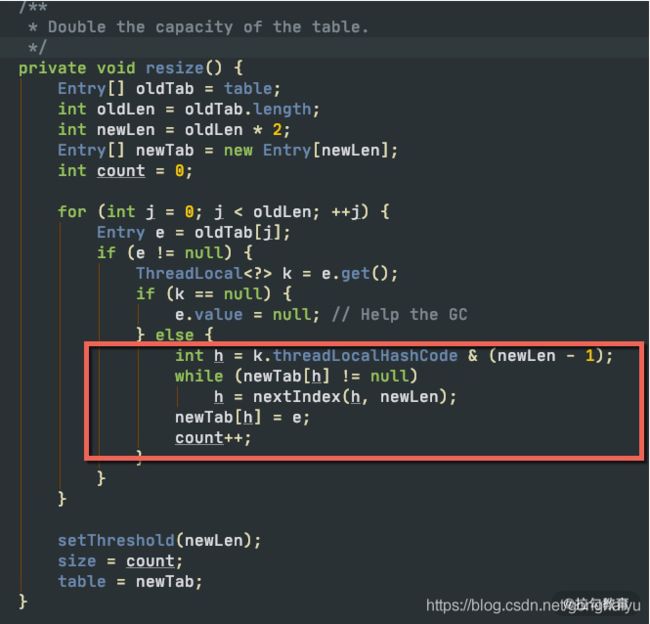
由于 Netty 对 ThreadLocal 的使用非常频繁,Netty 对它进行了专项的优化。它之所以快,是因为在底层数据结构上做了文章,使用常量下标对元素进行定位,而不是使用JDK 默认的探测性算法。
还记得《03 | 深入剖析:哪些资源,容易成为瓶颈?》提到的伪共享问题吗?底层的 InternalThreadLocalMap对cacheline 也做了相应的优化。
你在多线程使用中都遇到过哪些问题?
通过上面的知识总结,可以看到多线程相关的编程,是属于比较高阶的技能。面试中,面试官会经常问你在多线程使用中遇到的一些问题,以此来判断你实际的应用情况。
我们先总结一下文中已经给出的示例:
- 线程池的不正确使用,造成了资源分配的不可控;
- I/O 密集型场景下,线程池开得过小,造成了请求的频繁失败;
- 线程池使用了 CallerRunsPolicy 饱和策略,造成了业务线程的阻塞;
- SimpleDateFormat 造成的时间错乱。
另外,我想要着重提到的一点是,在处理循环的任务时,一定不要忘了捕捉异常。尤其需要说明的是,像 NPE 这样的异常,由于是非捕获型的,IDE 的代码提示往往不起作用。我见过很多案例,就是由于忘了处理异常,造成了任务中断,这种问题发生的机率小,是比较难定位的,一定要保持良好的编码习惯。
while(!isInterrupted()){
try{
……
}catch(Exception ex){
……
}
}
多线程环境中,异常日志是非常重要的,但线程池的默认行为并不是特别切合实际。参见如下代码,任务执行时,抛出了一个异常,但我们的终端什么都没输出,异常信息丢失了,这对问题排查非常不友好。
ExecutorService executor = Executors.newCachedThreadPool();
executor.submit( ()-> {
String s = null; s.substring(0);
});
executor.shutdown();
我们跟踪任务的执行,在 ThreadPoolExecutor 类中可以找到任务发生异常时的方法,它是抛给了 afterExecute 方法进行处理。
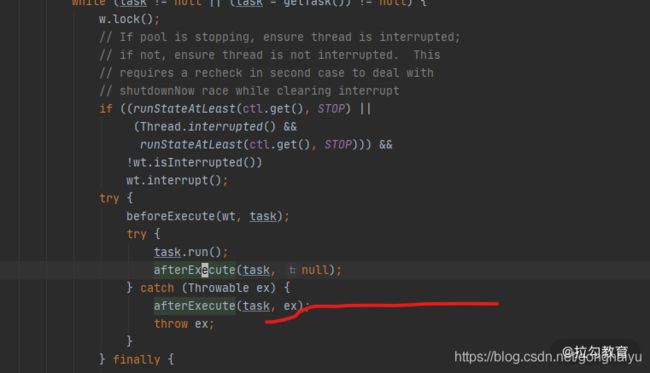
可惜的是,ThreadPoolExecutor 中的 afterExecute 方法是没有任何实现的,它是个空方法。
protected void afterExecute(Runnable r, Throwable t) {
}
如果你通过重写 afterExecute 来改变这个默认行为,但这代价点大。其实,使用 submit 方法提交的任务,会返回一个 Future 对象,只有调用了它的 get 方法,这个异常才会打印。使用 submit 方法提交的任务,代码永远不会走到上图标红的一行,获取异常的方式有且只有这一种。
只有使用 execute 方法提交的任务才会走到这行异常处理代码。如果你想要默认打印异常,推荐使用 execute 方法提交任务,它和 submit 方法的区别,也不仅仅是返回值不一样那么简单。
关于异步
异步是一种编程模型,它通过将耗时的操作转移到后台线程运行,从而减少对主业务的堵塞,所以我们说异步让速度变快了。但如果你的系统资源使用已经到了极限,异步就不能产生任何效果了,它主要优化的是那些阻塞性的等待。
多线程锁的优化
Java 中有两种加锁的方式:一种就是常见的synchronized 关键字,另外一种,就是使用 concurrent 包里面的 Lock。针对这两种锁,JDK 自身做了很多的优化,它们的实现方式也是不同的。
synchronized 关键字给代码或者方法上锁时,都有显示或者隐藏的上锁对象。当一个线程试图访问同步代码块时,它首先必须得到锁,而退出或抛出异常时必须释放锁。
- 给普通方法加锁时,上锁的对象是 this;
- 给静态方法加锁时,锁的是 class 对象;
- 给代码块加锁,可以指定一个具体的对象作为锁。
1.monitor 原理
参照下面的代码,在命令行执行 javac,然后再执行 javap -v -p,就可以看到它具体的字节码。可以看到,同步方法中在字节码的体现上,它只给方法加了一个 flag:ACC_SYNCHRONIZED。但在同步代码块的字节码中,可以看到,字节码是通过 monitorenter 和monitorexit 两个指令进行控制的。有monitorenter就必须有个monitorexit出口。
注意了,下面是面试题目高发地。比如,你能描述一下 monitor 锁的实现原理吗?
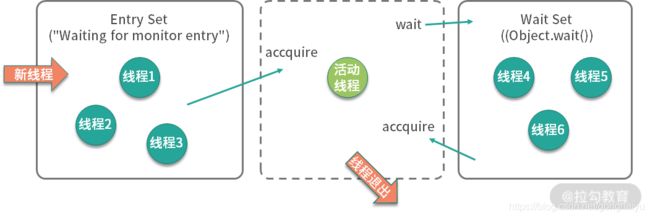
如上图所示,我们可以把运行时的对象锁抽象地分成三部分。其中,EntrySet 和 WaitSet 是两个队列,中间虚线部分是当前持有锁的线程,我们可以想象一下线程的执行过程。
当第一个线程到来时,发现并没有线程持有对象锁,它会直接成为活动线程,进入 RUNNING 状态。
接着又来了三个线程,要争抢对象锁。此时,这三个线程发现锁已经被占用了,就先进入 EntrySet 缓存起来,进入 BLOCKED 状态。此时,从 jstack 命令,可以看到他们展示的信息都是 waiting for monitor entry。
"http-nio-8084-exec-120" #143 daemon prio=5 os_prio=31 cpu=122.86ms elapsed=317.88s tid=0x00007fedd8381000 nid=0x1af03 waiting for monitor entry [0x00007000150e1000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.io.BufferedInputStream.read(java.base@13.0.1/BufferedInputStream.java:263)
- waiting to lock <0x0000000782e1b590> (a java.io.BufferedInputStream)
at org.apache.commons.httpclient.HttpParser.readRawLine(HttpParser.java:78)
at org.apache.commons.httpclient.HttpParser.readLine(HttpParser.java:106)
at org.apache.commons.httpclient.HttpConnection.readLine(HttpConnection.java:1116)
at org.apache.commons.httpclient.HttpMethodBase.readStatusLine(HttpMethodBase.java:1973)
at org.apache.commons.httpclient.HttpMethodBase.readResponse(HttpMethodBase.java:1735)
处于活动状态的线程,执行完毕退出了;或者由于某种原因执行了 wait 方法,释放了对象锁,进入了 WaitSet 队列,这就是在调用 wait 之前,需要先获得对象锁的原因。
synchronized (lock){
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
此时,jstack 显示的线程状态是 WAITING 状态,而原因是 in Object.wait()。
发生了这两种情况,都会造成对象锁的释放,进而导致 EntrySet 里的线程重新争抢对象锁,成功抢到锁的线程成为活动线程,这是一个循环的过程。
那 WaitSet 中的线程是如何再次被激活的呢?接下来,在某个地方,执行了锁的 notify 或者 notifyAll 命令,会造成 WaitSet 中的线程,转移到 EntrySet 中,重新进行锁的争夺。
如此周而复始,线程就可按顺序排队执行。
2.分级锁
在 JDK 1.8 中,synchronized 的速度已经有了显著的提升,类似于AQS中维护一个valitale类型的变量state来做一个可重入锁的重入次数。在C语言层面实现了偏向锁->轻量级锁->重量级锁。
锁只能升级,不能降级。一旦升级为重量级锁,就只能依靠操作系统进行调度。在JDK1.6中,我们一直把sychronized当做重量级锁。重量级锁,即我们对 synchronized 的直观认识,这种情况下,线程会挂起,进入到操作系统内核态,等待操作系统的调度,然后再映射回用户态。系统调用是昂贵的,所以重量级锁的名称由此而来。如果并发非常严重,可以通过参数 -XX:-UseBiasedLocking 禁用偏向锁,理论上会有一些性能提升,但实际上并不确定。
要想了解锁升级的过程,需要先看一下对象在内存里的结构。具体锁升级的内容可以参考JVM相关章节。

3.优化技巧
锁的优化理论其实很简单,那就是减少锁的冲突。无论是锁的读写分离,还是分段锁,本质上都是为了避免多个线程同时获取同一把锁。
所以我们可以总结一下优化的一般思路:减少锁的粒度、减少锁持有的时间、锁分级、锁分离 、锁消除、乐观锁、无锁等。
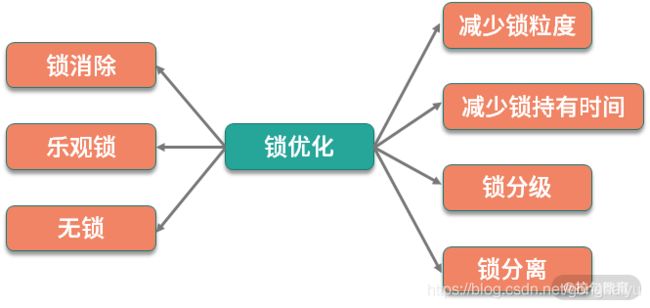
- 减少锁粒度
通过减小锁的粒度,可以将冲突分散,减少冲突的可能,从而提高并发量。简单来说,就是把资源进行抽象,针对每类资源使用单独的锁进行保护。 - 减少锁持有时间
通过让锁资源尽快地释放,减少锁持有的时间,其他线程可更迅速地获取锁资源,进行其他业务的处理。 - 锁分级
锁分级,指的是我们文章开始讲解的 Synchronied 锁的锁升级,属于 JVM 的内部优化,它从偏向锁开始,逐渐升级为轻量级锁、重量级锁,这个过程是不可逆的。 - 锁分离
我们在上面提到的读写锁,就是锁分离技术。这是因为,读操作一般是不会对资源产生影响的,可以并发执行;写操作和其他操作是互斥的,只能排队执行。所以读写锁适合读多写少的场景。 - 锁消除
通过 JIT 编译器,JVM 可以消除某些对象的加锁操作。举个例子,大家都知道StringBuffer 和 StringBuilder 都是做字符串拼接的,而且前者是线程安全的。
JDK1.8 加了一个StampedLock,具体的不同在于提供了乐观锁1.获取乐观读锁(会获取一个校验码)2.读取一些值3.根据步骤1的校验码再次校验,看看是否有被动过4.如果没有被动过就结束了4.如果被动过,转为读锁(接下来就和readwritelock一致了)
乐观锁和无锁
Lock 是基于 AQS(AbstractQueuedSynchronizer)实现的,AQS 是用来构建 Lock 或其他同步组件的基础,它使用了一个 int 成员变量来表示state(同步状态),通过内置的 FIFO 队列,来完成资源获取线程的排队。
CAS
CAS 是 Compare And Swap 的缩写,意思是比较并替换。追踪到 JVM 内部,在 linux 机器上参照 os_cpu/linux_x86/atomic_linux_x86.hpp。可以看到,最底层的调用,是汇编语言,而最重要的,就是cmpxchgl指令。到这里没法再往下找代码了,因为 CAS 的原子性实际上是硬件 CPU 直接保证的。
template<>
template<typename T>
inline T Atomic::PlatformCmpxchg<4>::operator()(T exchange_value,
T volatile* dest,
T compare_value,
atomic_memory_order /* order */) const {
STATIC_ASSERT(4 == sizeof(T));
__asm__ volatile ("lock cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest)
: "cc", "memory");
return exchange_value;
}
乐观锁
乐观锁严格来说,并不是一种锁,它提供了一种检测冲突的机制,并在有冲突的时候,采取重试的方法完成某项操作。假如没有重试操作,乐观锁就仅仅是一个判断逻辑而已。
为什么读多写少的情况,就适合使用乐观锁呢?悲观锁在读多写少的情况下,不也是有很少的冲突吗?
其实,问题不在于冲突的频繁性,而在于加锁这个动作上。
- 悲观锁需要遵循下面三种模式:一锁、二读、三更新,即使在没有冲突的情况下,执行也会非常慢;
- 如之前所说,乐观锁本质上不是锁,它只是一个判断逻辑,资源冲突少的情况下,它不会产生任何开销。
我们上面谈的 CAS 操作,就是一种典型的乐观锁实现方式,我们顺便看一下 CAS 的缺点,也就是乐观锁的一些缺点。
在并发量比较高的情况下,有些线程可能会一直尝试修改某个资源,但由于冲突比较严重,一直更新不成功,这时候,就会给 CPU 带来很大的压力。JDK 1.8 中新增的 LongAdder,通过把原值进行拆分,最后再以 sum 的方式,减少 CAS 操作冲突的概率,性能要比 AtomicLong 高出 10 倍左右。
CAS 操作的对象,只能是单个资源,如果想要保证多个资源的原子性,最好使用synchronized 等经典加锁方式
ABA 问题,意思是指在 CAS 操作时,有其他的线程现将变量的值由 A 变成了 B,然后又改成了 A,当前线程在操作时,发现值仍然是 A,于是进行了交换操作。这种情况在某些场景下可不用过度关注,比如 AtomicInteger,因为没什么影响;但在一些其他操作,比如链表中,会出现问题,必须要避免。可以使用 AtomicStampedReference 给引用标记上一个整型的版本戳,来保证原子性。
使用 select for update 这么一句简单的 SQL,其实在底层就加了三把锁,非常昂贵。
- 默认对主键索引加锁,不过这里直接忽略;
- 二级索引 userid={id} 的 next key lock(记录+间隙锁);
- 二级索引 userid={id} 的下一条记录的间隙锁。
所以,在现实场景中,这种悲观锁都已经不再采用,第一是因为它不够通用,第二是因为它非常昂贵。
一种比较好的办法,就是使用乐观锁。根据上面我们对于乐观锁的定义,就可以抽象两个概念: - 检测冲突的机制:先查出本次操作的余额E,在更新时判断是否与当前数据库的值相同,如果相同则执行更新动作
- 重试策略:有冲突直接失败,或者重试5次后失败
伪代码如下,可以看到这其实就是 CAS。
# old_balance获取
select balance from user where userid={
id}
# 更新动作
update user set balance = balance - 20
where userid={
id}
and balance >= 20
and balance = $old_balance
还有一种 CAS 的变种,就是使用版本号机制。通过在表中加一个额外的字段 version,来代替对余额的判断。这种方式不用去关注具体的业务逻辑,可控制多个变量的更新,可扩展性更强,典型的伪代码如下:
version,balance = dao.getBalance(userid)
balance = balance - cost
dao.exec("
update user
set balance = balance - 20
version = version + 1
where userid=id
and balance >= 20
and version = $old_version
")
从 BIO 到 NIO,再到 AIO
非阻塞 I/O 模型
Java 的 NIO,在 Linux 上底层是使用 epoll 实现的。epoll 是一个高性能的多路复用 I/O 工具,改进了 select 和 poll 等工具的一些功能。在网络编程中,对 epoll 概念的一些理解,几乎是面试中必问的问题。
epoll 的数据结构是直接在内核上进行支持的,通过 epoll_create 和 epoll_ctl 等函数的操作,可以构造描述符(fd)相关的事件组合(event)。
这里有两个比较重要的概念:
- fd 每条连接、每个文件,都对应着一个描述符,比如端口号。内核在定位到这些连接的时候,就是通过 fd 进行寻址的。
- event 当 fd 对应的资源,有状态或者数据变动,就会更新 epoll_item 结构。在没有事件变更的时候,epoll 就阻塞等待,也不会占用系统资源;一旦有新的事件到来,epoll 就会被激活,将事件通知到应用方。
关于 epoll 还会有一个面试题,相对于 select,epoll 有哪些改进?
你可以这样回答:
- epoll 不再需要像 select 一样对 fd 集合进行轮询,也不需要在调用时将 fd 集合在用户态和内核态进行交换;
- 应用程序获得就绪 fd 的事件复杂度,epoll 是 O(1),select 是 O(n);
- select 最大支持约 1024 个 fd,epoll 支持 65535个;
- select 使用轮询模式检测就绪事件,epoll 采用通知方式,更加高效。
我们还是以 Java 中的 NIO 代码为例,来看一下 NIO 的具体概念。
public class NIO {
static boolean stop = false;
public static void main(String[] args) throws Exception {
int connectionNum = 0;
int port = 8888;
ExecutorService service = Executors.newCachedThreadPool();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.socket().bind(new InetSocketAddress("localhost", port));
Selector selector = Selector.open();
ssc.register(selector, ssc.validOps());
while (!stop) {
if (10 == connectionNum) {
stop = true;
}
int num = selector.select();
if (num == 0) {
continue;
}
Iterator<SelectionKey> events = selector.selectedKeys().iterator();
while (events.hasNext()) {
SelectionKey event = events.next();
if (event.isAcceptable()) {
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
connectionNum++;
} else if (event.isReadable()) {
try {
SocketChannel sc = (SocketChannel) event.channel();
ByteBuffer buf = ByteBuffer.allocate(1024);
int size = sc.read(buf);
if(-1==size){
sc.close();
}
String result = new String(buf.array()).trim();
ByteBuffer wrap = ByteBuffer.wrap(("PONG:" + result).getBytes());
sc.write(wrap);
} catch (Exception ex) {
ex.printStackTrace();
}
} else if (event.isWritable()) {
SocketChannel sc = (SocketChannel) event.channel();
}
events.remove();
}
}
service.shutdown();
ssc.close();
}
}
上面这段代码比较长,是使用 NIO 实现的和 BIO 相同的功能。从它的 API 设计上,我们就能够看到 epoll 的一些影子。首先,我们创建了一个服务端 ssc,并开启一个新的事件选择器,监听它的 OP_ACCEPT 事件。
ServerSocketChannel ssc = ServerSocketChannel.open();
Selector selector = Selector.open();
ssc.register(selector, ssc.validOps());
共有 4 种事件类型,分别是:
- 新连接事件(OP_ACCEPT);
- 连接就绪事件(OP_CONNECT);
- 读就绪事件(OP_READ);
- 写就绪事件(OP_WRITE)。
任何网络和文件操作,都可以抽象成这四个事件。

接下来,在 while 循环里,使用 select 函数,阻塞在主线程里。所谓阻塞,就是操作系统不再分配 CPU 时间片到当前线程中,所以 select 函数是几乎不占用任何系统资源的。
int num = selector.select();
一旦有新的事件到达,比如有新的连接到来,主线程就能够被调度到,程序就能够向下执行。这时候,就能够根据订阅的事件通知,持续获取订阅的事件。
由于注册到 selector 的连接和事件可能会有多个,所以这些事件也会有多个。我们使用安全的迭代器循环进行处理,在处理完毕之后,将它删除。
这里留一个思考题:如果事件不删除的话,或者漏掉了某个事件的处理,会有什么后果?
Iterator<SelectionKey> events = selector.selectedKeys().iterator();
while (events.hasNext()) {
SelectionKey event = events.next();
...
events.remove();
}
}
有新的连接到达时,我们订阅了更多的事件。对于我们的数据读取来说,对应的事件就是 OP_READ。和 BIO 编程面向流的方式不同,NIO 操作的对象是抽象的概念 Channel,通过缓冲区进行数据交换。
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
值得注意的是:服务端和客户端的实现方式,可以是不同的。比如,服务端是 NIO,客户端可以是 BIO,它们并没有什么强制要求。
另外一个面试时候经常问到的事件就是 OP_WRITE。我们上面提到过,这个事件是表示写就绪的,当底层的缓冲区有空闲,这个事件就会一直发生,浪费占用 CPU 资源。所以,我们一般是不注册 OP_WRITE 的。
这里还有一个细节,在读取数据的时候,并没有像 BIO 的方式一样使用循环来获取数据。
如下面的代码,我们创建了一个 1024 字节的缓冲区,用于数据的读取。如果连接中的数据,大于 1024 字节怎么办?
SocketChannel sc = (SocketChannel) event.channel();
ByteBuffer buf = ByteBuffer.allocate(1024);
int size = sc.read(buf);
这涉及两种事件的通知机制:
- 水平触发(level-triggered) 称作 LT 模式。只要缓冲区有数据,事件就会一直发生
- 边缘触发(edge-triggered) 称作 ET 模式。缓冲区有数据,仅会触发一次。事件想要再次触发,必须先将 fd 中的数据读完才行可以看到,Java 的 NIO 采用的就是水平触发的方式。LT 模式频繁环唤醒线程,效率相比较ET模式低,所以 Netty 使用 JNI 的方式,实现了 ET 模式,效率上更高一些。
AIO
面试官可能会问你:为什么我在使用 NIO 时,使用 Channel 进行读写,socket 的操作依然是阻塞的?NIO 的作用主要体现在哪里?
//这行代码是阻塞的
int size = sc.read(buf);
这时你可以回答:NIO 只负责对发生在 fd 描述符上的事件进行通知。事件的获取和通知部分是非阻塞的,但收到通知之后的操作,却是阻塞的,即使使用多线程去处理这些事件,它依然是阻塞的。
AIO 更近一步,将这些对事件的操作也变成非阻塞的。下面是一段典型的 AIO 代码,它通过注册 CompletionHandler 回调函数进行事件处理。这里的事件是隐藏的,比如 read 函数,它不仅仅代表 Channel 可读了,而且会把数据自动的读取到 ByteBuffer 中。等完成了读取,就会通过回调函数通知你,进行后续的操作。
public class AIO {
public static void main(String[] args) throws Exception {
int port = 8888;
AsynchronousServerSocketChannel ssc = AsynchronousServerSocketChannel.open();
ssc.bind(new InetSocketAddress("localhost", port));
ssc.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() {
void job(final AsynchronousSocketChannel sc) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
sc.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
String str = new String(attachment.array()).trim();
ByteBuffer wrap = ByteBuffer.wrap(("PONG:" + str).getBytes());
sc.write(wrap, null, new CompletionHandler<Integer, Object>() {
@Override
public void completed(Integer result, Object attachment) {
job(sc);
}
@Override
public void failed(Throwable exc, Object attachment) {
System.out.println("error");
}
});
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
System.out.println("error");
}
});
}
@Override
public void completed(AsynchronousSocketChannel sc, Object attachment) {
ssc.accept(null, this);
job(sc);
}
@Override
public void failed(Throwable exc, Object attachment) {
exc.printStackTrace();
System.out.println("error");
}
});
Thread.sleep(Integer.MAX_VALUE);
}
}
AIO 是 Java 1.7 加入的,理论上性能会有提升,但实际测试并不理想。这是因为,AIO主要处理对数据的自动读写操作。这些操作的具体逻辑,假如不放在框架中,也要放在内核中,并没有节省操作步骤,对性能的影响有限。而 Netty 的 NIO 模型加上多线程处理,在这方面已经做得很好,编程模式也比AIO简单。
所以,市面上对 AIO 的实践并不多,在采用技术选型的时候,一定要谨慎。
响应式编程
你可能听说过 Spring 5.0 的 WebFlux,WebFlux 是可以替代 Spring MVC 的一套解决方案。
响应式编程是一种面向数据流和变化传播的编程范式。这意味着可以在编程语言中很方便地表达静态或动态的数据流,而相关的计算模型会自动将变化的值,通过数据流进行传播。
这段话很晦涩,在编程方面,它表达的意思就是:把生产者消费者模式,使用简单的API 表示出来,并自动处理背压(Backpressure)问题。
背压,指的是生产者与消费者之间的流量控制,通过将操作全面异步化,来减少无效的等待和资源消耗。
Java 的 Lambda 表达式可以让编程模型变得非常简单,Java 9 更是引入了响应式流(Reactive Stream),方便了我们的操作。
比如,下面是 Spring Cloud GateWay 的 Fluent API 写法,响应式编程的 API 都是类似的。
public RouteLocator customerRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route(r -> r.path("/market/**")
.filters(f -> f.filter(new RequestTimeFilter())
.addResponseHeader("X-Response-Default-Foo", "Default-Bar"))
.uri("http://localhost:8080/market/list")
.order(0)
.id("customer_filter_router")
)
.build();
}
从传统的开发模式过渡到 Reactor 的开发模式,是有一定成本的,不过它确实能够提高我们应用程序的性能,至于是否采用,这取决于你在编程难度和性能之间的取舍。
常见 Java 代码优化法则
代码优化法则
1.使用局部变量可避免在堆上分配
2.减少变量的作用范围
3.访问静态变量直接使用类名
有的同学习惯使用对象访问静态变量,这种方式多了一步寻址操作,需要先找到变量对应的类,再找到类对应的变量,如下面的代码:
public class StaticCall {
public static final int A = 1;
void test() {
System.out.println(this.A);
System.out.println(StaticCall.A);
}
}
对应的字节码为:
void test();
descriptor: ()V
flags:
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: aload_0
4: pop
5: iconst_1
6: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
9: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
12: iconst_1
13: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
16: return
LineNumberTable:
line 5: 0
line 6: 9
line 7: 16
可以看到使用 this 的方式多了一个步骤。
-
重写对象的 HashCode,不要简单地返回固定值
在代码 review 的时候,我发现有开发重写 HashCode 和 Equals 方法时,会把 HashCode 的值返回固定的 0,而这样做是不恰当的。
当这些对象存入 HashMap 时,性能就会非常低,因为 HashMap 是通过 HashCode 定位到 Hash 槽,有冲突的时候,才会使用链表或者红黑树组织节点。固定地返回 0,相当于把 Hash 寻址功能给废除了。 -
HashMap 等集合初始化的时候,指定初始值大小
这个原则参见 “10 | 案例分析:大对象复用的目标和注意点”,这样的对象有很多,比如 ArrayList,StringBuilder 等,通过指定初始值大小可减少扩容造成的性能损耗。 -
遍历 Map 的时候,使用 EntrySet 方法
使用 EntrySet 方法,可以直接返回 set 对象,直接拿来用即可;而使用 KeySet 方法,获得的是key 的集合,需要再进行一次 get 操作,多了一个操作步骤。所以更推荐使用 EntrySet 方式遍历 Map。 -
不要在多线程下使用同一个 Random
Random 类的 seed 会在并发访问的情况下发生竞争,造成性能降低,建议在多线程环境下使用 ThreadLocalRandom 类。
在 Linux 上,通过加入 JVM 配置 -Djava.security.egd=file:/dev/./urandom,使用 urandom 随机生成器,在进行随机数获取时,速度会更快。
- 自增推荐使用 LongAddr
自增运算可以通过 synchronized 和 volatile 的组合,或者也可以使用原子类(比如 AtomicLong)。
后者的速度比前者要高一些,AtomicLong 使用 CAS 进行比较替换,在线程多的情况下会造成过多无效自旋,所以可以使用 LongAdder 替换 AtomicLong 进行进一步的性能提升。
9.不要使用异常控制程序流程
异常,是用来了解并解决程序中遇到的各种不正常的情况,它的实现方式比较昂贵,比平常的条件判断语句效率要低很多。
这是因为异常在字节码层面,需要生成一个如下所示的异常表(Exception table),多了很多判断步骤。
- 不要在循环中使用 try catch
道理与上面类似,很多文章介绍,不要把异常处理放在循环里,而应该把它放在最外层,但实际测试情况表明这两种方式性能相差并不大。
既然性能没什么差别,那么就推荐根据业务的需求进行编码。比如,循环遇到异常时,不允许中断,也就是允许在发生异常的时候能够继续运行下去,那么异常就只能在 for 循环里进行处理。
- 不要捕捉 RuntimeException
Java 异常分为两种,一种是可以通过预检查机制避免的 RuntimeException;另外一种就是普通异常。
其中,RuntimeException 不应该通过 catch 语句去捕捉,而应该使用编码手段进行规避。
如下面的代码,list 可能会出现数组越界异常。是否越界是可以通过代码提前判断的,而不是等到发生异常时去捕捉。提前判断这种方式,代码会更优雅,效率也更高。
//BAD
public String test1(List<String> list, int index) {
try {
return list.get(index);
} catch (IndexOutOfBoundsException ex) {
return null;
}
}
//GOOD
public String test2(List<String> list, int index) {
if (index >= list.size() || index < 0) {
return null;
}
return list.get(index);
}
- 合理使用 PreparedStatement
PreparedStatement 使用预编译对 SQL 的执行进行提速,大多数数据库都会努力对这些能够复用的查询语句进行预编译优化,并能够将这些编译结果缓存起来。
这样等到下次用到的时候,就可以很快进行执行,也就少了一步对 SQL 的解析动作。
PreparedStatement 还能提高程序的安全性,能够有效防止 SQL 注入。
但如果你的程序每次 SQL 都会变化,不得不手工拼接一些数据,那么 PreparedStatement 就失去了它的作用,反而使用普通的 Statement 速度会更快一些。
- 日志打印的注意事项
我们在“06 | 案例分析:缓冲区如何让代码加速”中了解了 logback 的异步日志,日志打印还有一些其他要注意的事情。
我们平常会使用 debug 输出一些调试信息,然后在线上关掉它。如下代码:
logger.debug("xjjdog:"+ topic + " is awesome" );
程序每次运行到这里,都会构造一个字符串,不管你是否把日志级别调试到 INFO 还是 WARN,这样效率就会很低。可以在每次打印之前都使用 isDebugEnabled 方法判断一下日志级别,代码如下:
if(logger.isDebugEnabled()) {
logger.debug("xjjdog:"+ topic + " is awesome" );
}
使用占位符的方式,也可以达到相同的效果,就不用手动添加 isDebugEnabled 方法了,代码也优雅得多。
logger.debug("xjjdog:{} is awesome" ,topic);
对于业务系统来说,日志对系统的性能影响非常大,不需要的日志,尽量不要打印,避免占用 I/O 资源。
- 减少事务的作用范围
如果的程序使用了事务,那一定要注意事务的作用范围,尽量以最快的速度完成事务操作。这是因为,事务的隔离性是使用锁实现的,可以类比使用 “13 | 案例分析:多线程锁的优化” 中的多线程锁进行优化。
@Transactional
public void test(String id){
String value = rpc.getValue(id); //高耗时
testDao.update(sql,value);
}
如上面的代码,由于 rpc 服务耗时高且不稳定,就应该把它移出到事务之外,改造如下:
public void test(String id){
String value = rpc.getValue(id); //高耗时
testDao(value);
}
@Transactional
public void testDao(String value){
testDao.update(value);
}
- 不要打印大集合或者使用大集合的 toString 方法
有的开发喜欢将集合作为字符串输出到日志文件中,这个习惯是非常不好的。
拿 ArrayList 来说,它需要遍历所有的元素来迭代生成字符串。在集合中元素非常多的情况下,这不仅会占用大量的内存空间,执行效率也非常慢。我曾经就遇到过这种批量打印方式造成系统性能直线下降的实际案例。
- 程序中少用反射
反射的功能很强大,但它是通过解析字节码实现的,性能就不是很理想。
现实中有很多对反射的优化方法,比如把反射执行的过程(比如 Method)缓存起来,使用复用来加快反射速度。
Java 7.0 之后,加入了新的包 java.lang.invoke,同时加入了新的 JVM 字节码指令 invokedynamic,用来支持从 JVM 层面,直接通过字符串对目标方法进行调用。
如果你对性能有非常苛刻的要求,则使用 invoke 包下的 MethodHandle 对代码进行着重优化,但它的编程不如反射方便,在平常的编码中,反射依然是首选。
下面是一个使用 MethodHandle 编写的代码实现类。它可以完成一些动态语言的特性,通过方法名称和传入的对象主体,进行不同的调用,而 Bike 和 Man 类,可以是没有任何关系的。
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
public class MethodHandleDemo {
static class Bike {
String sound() {
return "ding ding";
}
}
static class Animal {
String sound() {
return "wow wow";
}
}
static class Man extends Animal {
@Override
String sound() {
return "hou hou";
}
}
String sound(Object o) throws Throwable {
MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodType methodType = MethodType.methodType(String.class);
MethodHandle methodHandle = lookup.findVirtual(o.getClass(), "sound", methodType);
String obj = (String) methodHandle.invoke(o);
return obj;
}
public static void main(String[] args) throws Throwable {
String str = new MethodHandleDemo().sound(new Bike());
System.out.println(str);
str = new MethodHandleDemo().sound(new Animal());
System.out.println(str);
str = new MethodHandleDemo().sound(new Man());
System.out.println(str);
}
}
- 正则表达式可以预先编译,加快速度
Java 的正则表达式需要先编译再使用。
Pattern pattern = Pattern.compile({
pattern});
Matcher pattern = pattern.matcher({
content});
Pattern 编译非常耗时,它的 Matcher 方法是线程安全的,每次调用方法这个方法都会生成一个新的 Matcher 对象。所以,一般 Pattern 初始化一次即可,可以作为类的静态成员变量。