深度学习-自然语言处理(NLP)-知识图谱:知识图谱构建流程【本体构建、知识抽取(实体抽取、 关系抽取、属性抽取)、知识表示、知识融合、知识存储】
逻辑结构上可以把知识图谱分为两层:
- 一个是模式层也叫做 schema 层或者本体层,
- 另一个是数据层。
模式层位于数据层之上。 数据层其实就是存储所有的三元组信息的知识库, 而模式层才是知识图谱的核心, 它是对数据层知识结构的一种提炼, 通常需要借助本体库来存储, 通过在模式层上建立一些约束和规则, 规范实体、 关系、 实体属性、 属性值之间的联系, 以及完成在知识图谱上的一些推理。
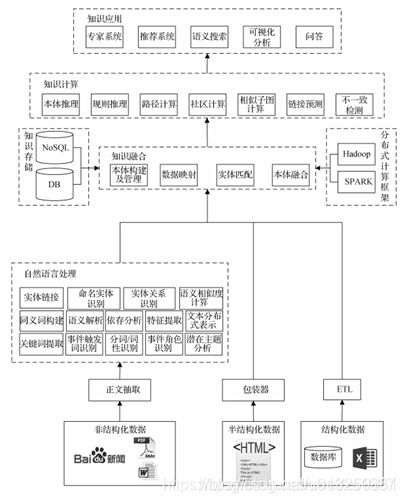
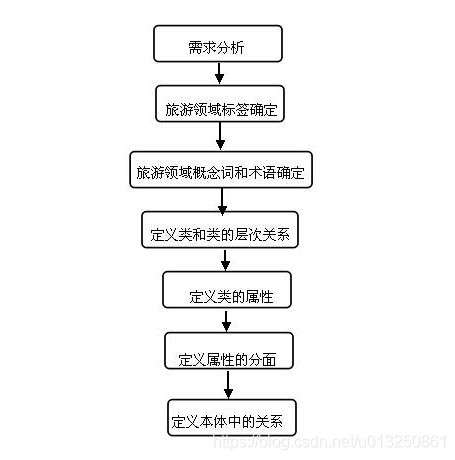
知识图谱的构建主要包括五个过程, 如下图 2-1 所示。 分别是本体构建、 知识获取、知识表示、 知识融合以及知识存储。

一、本体构建【Neo4J图数据库中的标签】
0、本体与实体的区别
- 本体(类的集合):是概念(类)的集合,是大家都公认的概念框架,一般不会改变如“人”、“事”、“物”、“地”、“组织”,在面对对象编程里面,我们把它叫做类,在数据管理里面我们把它叫做元数据;
- 实体(类的对象):是本体、实例及关系的整合,比如“人”是本体框中的一个概念,概念中也规定了相关属性比如“性别”,小明是一个具体的人,叫做实例,所以小明也有性别,小明以及体现小明的本体概念“人”以及相关属性,叫做一个实体(简单的说就是:本体+实例);
1、本体的概念
本体( ontology)最先是被哲学领域研究者提出,其作用主要是为了更好地描述客观事物,在对客观事物描述的过程中,根据描述对象的共性将客观事物抽象为系统化的概念或专业术语。

概括而言,本体是基于自身对客观事物描述的需求,通过对客观事物共性的总结和提炼,形成规范化、系统化的领域概念模型。
1993 年 Gruber 所论述的:本体是对事物所具的概念或类、类的关系、类的属性等要素的明确、清晰地描述,体现了事物内外在的关系。这一描述是目前比较受到学界认可的定义之一。本体的定义体现出了本体的四个重要的特点,即概念化、明确性、形式化和共享性。
- 本体的概念化的内涵意为本体是表示各种客观存在的抽象模型,它并不描绘实体的具体形象而是表达出一个抽象的本质概念;
- 本体的明确性主要体现在在对客观事物进行描述的过程中利用自身严密的概念化表述优势和系统化的思想,准确地展示描述对象的特征;
- 本体的形式化体现在本体使用特定的、严格规范化的、无歧义的语言进行描述,以达到明确清晰的目的,所以体现出形式化的特点;
- 本体的共享性则是指本体所描述和表达的知识信息是具有共享的特性的,它能够被用户普遍的认同并使用。
2、本体的分类
不同的研究方法往往对本体的侧重点有所不同, 其带来的是多样化的本体的分类方法。部分比较有代表性的本体分类如下图:

上述本体分类体现了研究角度对于本体划分有着重要的影响,选择构建本体的领域以及目的或者想要实现的功能等等都对本体有着决定性作用。不同类型的本体适应于不同的构建方法,所以确定本体类别、明确其特征可以在一定程度上帮助选择合适的构建方法。
3、本体的描述语言
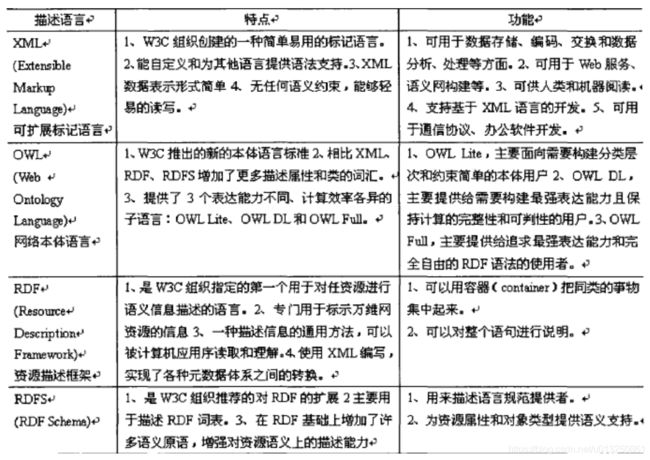
本体构建之前,需要选择合适的本体描述语言。本体描述语言是本体构建环节中的重要工具,客观的信息资源只有经过本体语言的描述转化后才能够在计算机、网络上实现输入、导出、分类、语义关联、逻辑推理等一系列的功能。
比较有代表性的本体描述语言有 XML、 OWL、 RDF 和 RDFS,它们是现今最为常见且应用广泛的四种描述语言。
4、本体建模元语
创建本体需要特定的模型功能实现要素,相关研究者们对此类的研究以及观点也很多。如今,最为大家所接受的是 Perez 等学者归纳出来的 5 个基本建模元语,即概念( Concepts)、关系( Relations)、函数( Functions)、公理( Axioms)以及实例( Instances)。
- 概念( Concepts):概念的主要作用是用来描述具有相似点或共同特征的资源的集合,也被称作“类”。概念是从客观世界具有共同特征的资源集合中归纳出来的集合中资源共有的特性,从更加概括、抽象的角度揭示事物的特征。
- 关系( Relations):关系主要是对概念或术语之间的相互关联性作出定义或描述。通过关系的有效界定和规范将资源归类并区分出不相关的资源,从中体现不同概念资源的性质。
- 函数( Functions):函数的作用是规范集合两个或两个以上类、集合、概念间的对应关系和映射关系[17]。比如函数 Father( )的作用是有效的将生物和他的父亲相关联。
- 公理( Axioms):是用来判断本体推理过程中推理结果和步骤对错的依据和标准。公理具有永真性。
- 实例( Instances):是一种信息资源,是类的成员,是我们要分析的个体,是具体化的事物或者信息资源。与概念不同的是,实例充满了个性化。
5、本体构建方法:七步法
本体构建方法还没有形成统一的规范,主要原因是众多研究者所处的领域和构建目的不同,因此,他们所采取的方法也不尽相同。研究者提出了多种本体构建方法,领域内普遍认可的主要有以下几种:
- METHONTOLOGY 法(主要用于化学领域)、
- TOVE 法
- 骨架法、
- 七步法
七步法是斯坦福大学研究者 Noy 和 McGuinness 在构建领域本体时研究的一种本体构建方法[22]。七步法主要将本体构建过程依次分为七个组成部分。并根据研究的需要对每一部分通过分析,提出相应的详细工作。通过七个步骤完成本体构建工作。七步法体现了本体构建次序的逻辑思路,其步骤主要是:
- 分析研究对象的学科领域。通过研究领域的分析,界定研究领域的范围和领域内的相关知识和专业术语,了解领域内信息用户的需求及特性,保证领域本体的专业性和针对性。
- 研究借用其他领域本体的可行性。如果可以借用,则可以节约时间成本和经济成本。
- 总结、确定本主题领域的重要概念或术语。
- 分析领域内概念和术语,合理描述类之间的层次关系和属性关系。
- 根据领域知识内容描述类的属性。如类“飞机”的属性可以有:“型号”、“价格”、“生产地”等。关系如:继承关系、不相交关系等。
- 定义属性取值的类型。这是对属性的有效限制,使对属性的描述更加准确。
- 构建本体实例。根据以上六步所做的充分的准备工作,进入本体的构建环节,按照本体构建要求构建类、子类、属性等,并为类添加个体、为不同属性添加值。最终本体构建完成。
6、本体构建工具
为了更好的构建本体,各领域纷纷开发适合自己领域的本体构架工具。在众多本体构建工具中存在着六个知名的构建工具,它们分别是: Protege、 Ontolingua、 OntoSaums、 OntoEdit 以及 WebOnto。
Protege是斯坦福大学研究人员根据本体构建需要开发的一款本体开发软件,为实现工具软件对其他语言的兼容性和开放性, Protege 软件的开发采用面向对象语言—Java 语言进行开发。
7、旅游领域本体建模思路
7.1 旅游领域标签确定
标签的搜集对旅游领域本体的构建具有重大影响,因此要选择适当的、高质量的标签来源网站。
具体的标签搜集和确定主要有以下两个步骤:
第一步:标签的收集:以“旅游”、“旅行”为入口词进行标签检索,从新浪博客等网站上检索得到得标签:

第二步:标签的初步整理。原始标签中会有少数不属于旅游领域或者会出现重复、无效标签。对于标签是否属于旅游领域, 可参考《中国分类主题词表》以及中国国家旅游标准和行业标准对其进行分析与确定。
7.2 旅游领域概念词和术语确定
《中国分类主题词表》是本文选择旅游领域重要术语的重要来源。可参考中国旅游国家标准和行业标准;国家标准和行业标准中对旅游景区、旅游服务、旅游资源、旅游饭店等都进行了详细地说明和规范,完全可以作为旅游领域重要术语的重要来源。
经过一系列分析和整理,确定旅游领域的概念词和术语为:旅游、人物、导游、旅游者、历史名人、景区、娱乐、摄影、文学艺术、游记、历史、旅游线路、旅游攻略、国际旅游线、国内旅游线、自助旅游、跟团旅游、食宿、住所、餐馆、美食、酒店、交通方式、景区门票、交通票价、联系方式、行程、组织机构、服务机构、地理位置、国家、省份、城市、民族风情、婚丧习俗、民族歌舞、旅行社、景区管理机构、交通运输企业、旅游局、签证、护照、保险公司、食宿企业、特产企业、自然景观、人文景观、水文景观、生物景观、天象与气候景观、民居、历史古迹、古城古镇、公园、亭台楼阁、建筑与设施等。
7.3 定义类、类的层次结构【本体层次结构图】
旅游领域的类是用来描述旅游的抽象化概念术语,是对众多旅游个体共性的概念化描述。
术语是划分类的基础,根据构建领域本体的目标和具体需要,可以确定哪些术语能作为领域本体的类。在以上抽取的众多旅游领域术语中,有些是能直接作为类的,如:旅游、人物、交通方式、景区等等,而有些则不能作为类,如:票价、景区门票、联系方式等等,它们只是属性。
“旅游”很明显是最顶层的类,是父类。然后,要确定旅游的子类,根据大众标签里体现的共性和《中国分类主题词表》确定了旅游领域的 11 个核心概念,即:人物、交通方式、娱乐、文学艺术、景区、民俗风情、旅游目的、服务机构、旅游线路、地理位置、食宿,它们是“旅游”的子类。
领域本体类的等级体系结构建立方法有三种:自上而下法、自下而上法、综合法。更具其中任意一种方法,来确定旅游领域本体层次结构图:

7.4 定义类(本体)的属性、属性的分面
类的层次结构还只是本体的骨架,不足以全面表现领域知识和提供系统能力问题所需要的答案信息,其血肉就要通过类的关系,即属性来充实了。
7.4.1 定义类(本体)的属性
属性分为外部属性和内部属性:
-
数据属性:内部属性,是类具有的一些固有性质

-
对象属性:外部属性,是指类与类之间的关系
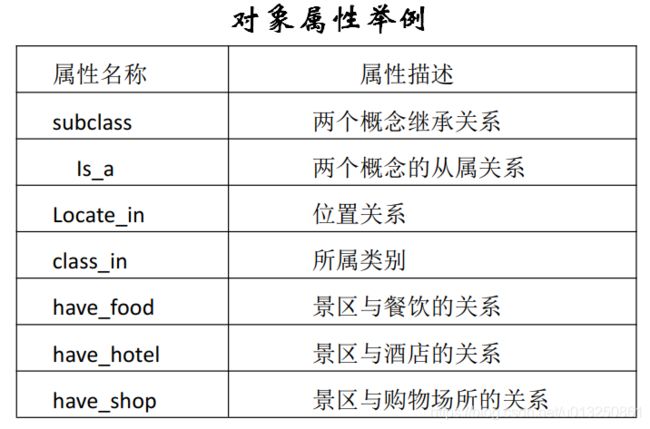
本体的属性主要有两种:对象属性( ObjectProperty)、数据属性(DatatypeProperty):
- 对象属性用于将相关的旅游类的不同个体联系起来;
- 数据属性的功能是对个体赋值,将个体和文字联系起来,准确描述旅游领域个体;
如对类“人物”设置数据属性、对象属性
- 数据属性(固有属性):“姓名”、“性别”等,将人物个体与姓名、性别建立联系,用不同性质的数据描述个体的特性;
- 对象属性(对外关系):“使用”、“选择”等,将人物个体与交通方式和旅游线路等个体联系起来
旅游领域类的诸多属性,主要如下:
- 数据属性(固有属性):旅游线路时间、性别、旅游线路费用、身份证、旅游类别、交通票价、公交线路、客房数量、客房面积、会员价、非会员价、团购价、优惠价、电脑配备、 wifi 配备、会议室配备、停车场配备、卫生间配备、健身房配备、、游泳池配备、接送服务、传真机配备、营业时间、卫生许可证、景区电话、就餐价格、景区名称、景点星级、景点营业时间、门票价格、景点优惠价、景区可容纳人数、旅行社名称、、旅行社地址、旅行社联系方式、旅行社员工数、旅游产品报价、旅游局级别、景区介绍管理机构、旅游局电话、旅游局地址、旅游局员工数、旅游局服务时间、签证机构名称、签证机构地址、签证机构电话、旅游线路名称、景点地址、日期、年龄、姓名
- 对象属性(对外关系):人物使用交通、交通供人物使用、景点所在国家、景点所在省份、景点所在城市、人物所在城市、景区所在城市、住处所在城市、餐馆所在城市、景点具有住处、景点具有餐馆、景点供人物游览、人物游览景点、人物选择住处、人物选择餐馆、住处供人使用、餐馆供人使用、景区具有餐馆、景区具有住处、选择旅行社、可选旅行社、提供旅游线路、所选景点、持有证件、国家具有省份、省份具有城市、城市所属省份、省份所属国家。
7.4.2 定义各个属性的分面
在对类的属性进行定义之后,应该根据类目的层次关系和属性的特征对属性所包含的不同分面分别进行定义,进一步保证属性的完整性。如对属性的取值进行定义,对属性的基数进行定义等:
- 赋值类型,某一属性的确定值,如整数型(int),字符串(string),浮点数(float)等。
- 允许的赋值。允许赋值的主要功能是对属性的赋值特征作进一步的限制,如通过数量、空值等定义属性特征。
- 赋值的基数,也称基数性。它是对一个属性槽(slot)能够拥有的值得数量限制。
- 属性值的领域和范围:规定属性属于哪个类[32]。域是对概念的限制,用一种特定的属性对某一概念进行限制,使其成为某一特定类的成员;范围是指对属性值得限制,以确保概念成为某一特定类的成员。
例如:属性“使用”的定义域是人物,值域就是字符串数据;属性“门票”的定义域是景区,值域是整数型等等
7.4 定义本体中的关系
本体中的关系多种多样,除了基本的语义关系,很多类目关系还需要用户自主归纳总结然后定义。
对于本体的基本语义关系来说,主要有四种,分别是:part-of、 kind-of、 instance-of 和 attribute-of。
- part-of 表达概念之间部分与整体的关系,比如:“车轮”与“汽车”之间的关系;
- kind-of 表达概念之间的继承关系,要求其层次结构中的概念关系必须是同质的、直接父子概念之间具有相同的泛化程度,相当于面向对象思想中的“is a”,比如:“人物”与“旅游者”、“导游”,“旅游者”和“导游”都继承了人物的特性,都具有人的本质,它们都继承了上位类的属性;
- instance-of 描述的是本体中的实例与本体中类的关系,类似于面向对象中对象与类之间的关系,比如:“杨继超”是旅游领域本
体的一个实例,他就是二级类目“人物”的一个具体实例;
attribute-of 描述的是某个概念或类是另外一个概念或类的一个属性,比:“门票”这一术语就是“景区”类目的属性之一。
在以上四种基本关系的基础上,笔者依据旅游领域本体类目的设置和具体特点,还定义了其他一些语义关系类型。具体情况如下:
- 使用和被使用关系。它们是一对互逆关系。表示两个概念或事物之间存在使用与被使用的关系。例如:“交通方式”作为一种出行工具、方式,只能被“人物”所使用,它们之间存在使用和被使用的关系。
- 选择和供选择关系,它们也是一对互逆关系。表示两个概念或事物之间选择与被选择的关系,即概念 a 选择概念 b。例如:“人物”选择“旅游线路”、“景区”供“人物”选择。
- locatedIn 关系,表示两个概念或事物之间“位于” 的关系,即概念 a位于概念 b 那里。例如:类目“景区”、“服务机构”与“地理位置” 之间的关系。
- Has 关系,表示概念 a 与概念 b 之间存在拥有、提供的关系。例如:类目“景区” has“食宿”。
- causes 与 causedBy 关系,表示人物与民俗风情之间引起与被引起的关系。它们是一对互逆关系。如果概念 a 和概念 b 之间存在概念 a概念b 的关系,则概念 b 由概念 a 引起。例如:“民俗风情”由“人物”引起,则它们之间存在关系。
- …的目的:说明了类目“旅游目的”只能是旅游的主体-人物所拥有。
- member 关系和 memberOf 关系,这里定义 member 关系和 memberOf关系是用来说明某事物是另一事物的成员之一。它们是一对互逆关系。例如,旅游局是旅游服务机构的一部分,则它们之间存在 memberOf 关系,表示为“旅游局” “旅游服务机构”。
- 相互对立关系或者互补关系,指两个事物或概念是完全对立的两方面,差异性很大,具有一定的互补性。例如:“自助旅游者”和“跟团旅游者”均属于“人物”的一种,且其内涵相互矛盾,但是人物还包括“导游”、“历史名人”等,所以“自助旅游者”和“跟团旅游者”属于矛盾关系
8、旅游领域本体构建过程
构建本体之前要有详细的规划,包括选择合适的本体描述语言、本体构建的工具以及本体构建的方法,做到统筹兼顾,全面把握本体构建的整个过程。
在大众分类标签的基础上,运用微调后的七步法,采用 protege4.3 软件,展示一下旅游领域本体的构建过程。
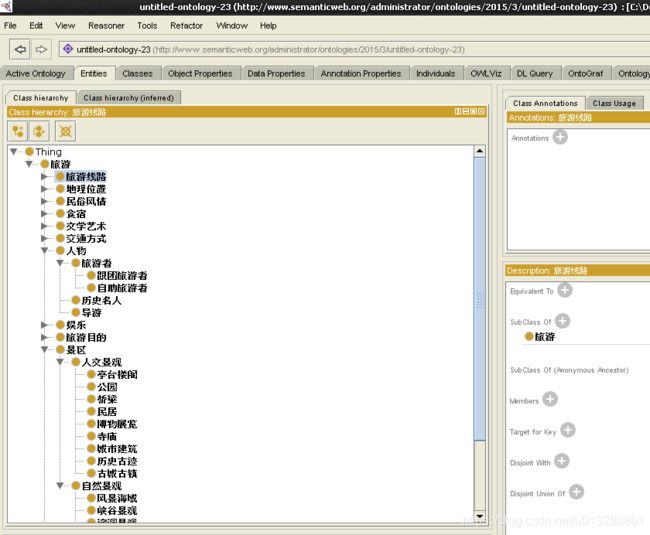
8.1 旅游领域本体类的构建
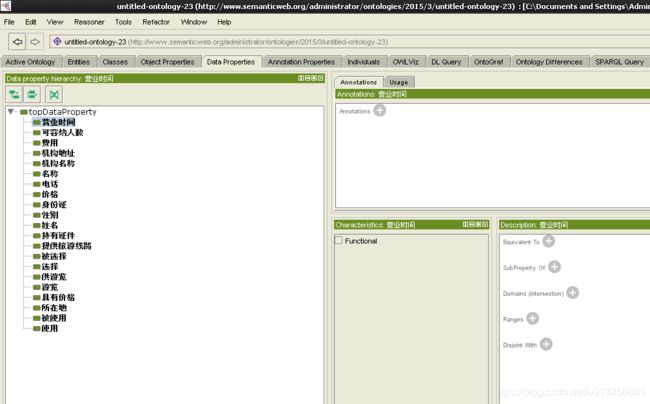
8.2 建立旅游领域本体类属性
8.3 添加旅游领域本体实例
术语是划分类的基础,根据构建领域本体的目标和具体需要,可以确定哪些术语能作为领域本体的类[33]。为本体添加实例时可以用 rdf: type 语言进行描述,以定义、说明该实例所属的类,声明它是某类的成员。如
</owl:Thing rdf:ID=”黄龙景区” >
<rdf:type rdf:resource=” #景区” >
</owl:Ting
这段代码就描述了“黄龙景区”是“景区”的一个个体或实例,阐明了类与个体之间的关系。
8.4 本体关系图显示
本体构建完成后可以通过关系图的形式展示所建本体,本体框架可以一目了然、很美观地体现出来。 Protege4.3 中点击菜单栏“OntoGraf”,它有 7 种本体结构表现形式,比如: Tree-Vertical、 Radial、 Vertical-Directed 等,比如选用“Radial”结构来表现此本体框架。
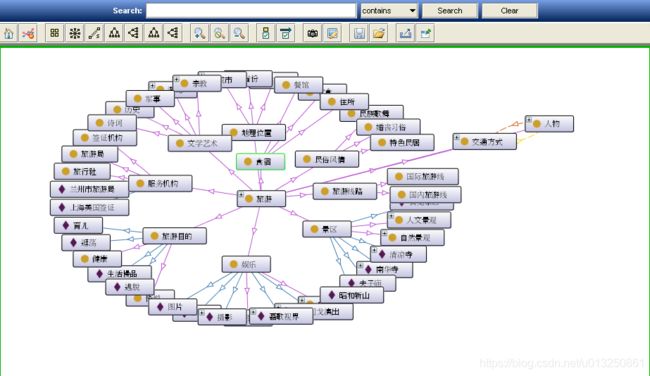
8.5 文档保存
本体构建完成后,需要对形成的本体进行保存。Protege 本体构建软件为本体文档的保存提供了多种形式,如 RDF/XML、 OWL 等保存格式。
8.6 将Protege 本体数据导入Neo4j图数据库
使用各种转换软件即可实现。比如:neosemantics-3.4.0.2 支持3.4.x版本neo4j数据库。
二、知识抽取
知识抽取是构建知识图谱的基础, 因为获取到知识的数量级以及准确度, 直接影响到知识图谱的规模和好坏。
知识抽取的数据来源往往有 3 种,分别是:
- 结构化的数据源
- 半结构化的数据源
- 无结构化的数据源
知识抽取就是从数据源中抽取到我们所需要的内容。
知识抽取包括三个方面的内容: 实体抽取、 关系抽取以及属性抽取。
1、实体抽取(命名实体识别,Named Entity Recognition, 简称 NER)
实体抽取。 主要指的是从自然文本中抽取到我们所需要的命名实体(例如:地名、 人名, 以及各种专有名词) 。 这个过程也叫做命名实体识别( named entity recognition, 简称 NER) 。
最早的命名实体识别过程, 都是基于规则的, 由于所有的规则都是需要人为手工的编写, 因此需要耗费大量的人力, 可扩展性也很差。
1.1 结构化数据源实体抽取:爬虫采集
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。

Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。

以旅游知识图谱为例,爬虫可从以下网址爬取结构化数据:
- 携程网(http://www.ctrip.com/) 是国内领先的、 国内市值最大的综合性旅行服务公司, 全球市值第三的在线旅行服务公司。 已经有超过 4.1 亿的注册会员, 并向超过 2.5 亿的会员提供过包括酒店预定、 机票预定; 向 1.7 亿会员提供过旅游度假、攻略等全方位的旅游服务。
- 驴妈妈旅游网(http://www.lvmama.com/) 创立于 2008年, 是中国新生代旅游服务网站的代表, 主要针对为广大游客提供自助游服务, 为游客出行提供一站式服务便利。
- 途牛网(http://www.tuniu.com/) 拥有中国最全最全的景点信息大全, 可以帮助游客更好的制定行程。大众点评是中国最大点评网站, 评论信息反应了商家最真实的产品质量和服务态度, 大众点评月评论条数超过 20 亿条, 月浏览点击量更是超过 100 亿次。
- 百度百科(https://baike.baidu.com/) 是最大的中文在线百科全书, 至今已拥有超过 1520 万词条, 并且涉及领域和范畴特别广。
- 互动百科(http://www.baike.com/)到 2013 年, 已经拥有超过 1300 万词条、 5 亿个分类、 68 亿文字、 721 万张图片。
- 搜狗百科(http://baike.sogou.com/Home.v) 代表了搜狗“知立方” 最先进的搜索技术, 是新生一代的中文百科大全。
2、关系抽取【中文:LTP工具包;英文:NLTK工具包】
在我们得到实体之后, 就考虑从文本中挖掘出实体与实体之间的语义信息, 也就是它们之间的关联关系。
关系抽取不仅是信息抽取的任务之一, 也是构建和补全知识图谱的关键所在,其研究的主要内容是从文本内容中挖掘出实体与实体之间的语义关系, 从纯文本生成关系数据的过程, 是自然语言处理(NLP) 中的关键任务。 该任务可以描述为:给定一段文本 S, 确定两个目标实体对 < e 1 , e 2 >
最早的关系抽取, 是通过人工编写一系列的规则, 接着采用模式匹配的方式去进行关系挖掘。 现在都是通过神经网络模型抽取到句子的信息, 在根据信息对关系进行分类。
2.1 关系抽取第三方工具包
中文数据集可用成熟的LTP工具包实现关系抽取。
英文数据集可用成熟的NLTK工具包实现关系抽取。
2.2 自定义关系抽取模型
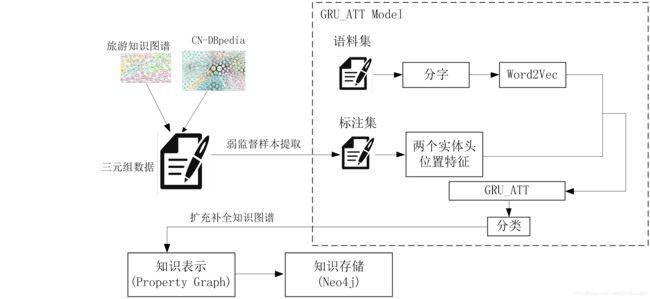
3、属性抽取
属性指的是实体的属性。 百科是实体属性的主要来源。 FMSuchanek等人编写的启发式算法能够从维基百科的信息盒子(inforbox) 中抽取出属值对(属性-属性值) , 准确率超过 96%。 DBpedia 是现在最有影响力的知识库之一, 它从维基百科的 inforbox 中抽取了 45800 个实体、 30 亿个属性。
三、知识表示
知识图谱的本质就是图, 其中点代表实体, 边代表关系。 目前可以用两种形式来表示知识图谱。 第一种就是 RDF, 第二种就是属性图的形式。
1、RDF
RDF是 W3C 提出的描述网络资源的方法, 网络上的资源都会有唯一的、 统一的一个资源标识符(URI) 去表示, 例如, 网址“http://www.baidu.com/” 就表示百度网站的首页, 那么通过这个地址就可以找到百度网站的首页。 接着它的属性就可以通过属性值对(属性-属性值) 的方式来表示,

根据 RDF 定义, 资源本身就是 subject(主语) , 属性就是 predicate(谓语) ,
属性值就是 object(宾语) 。 即(subject, predicate, object) 就表示一条 RDF 格式
的数据。 其中 subject 和 object 表示知识图谱中的节点, predicate 表示知识图谱中的
边。
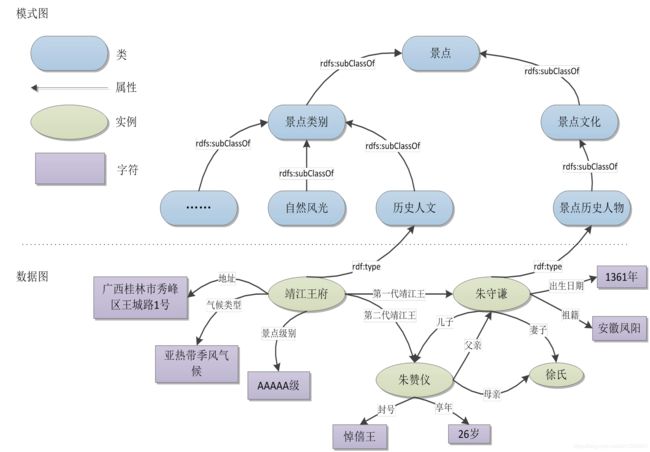
2、属性图(proprtty Graph) 模型
属性图(proprtty Graph) 模型的方式, 是通过每一个节点和每一条边的唯一标识符, 采用属性值对的方式去标识每个节点和每一条边所具有的属性。 下图描述了我们在构建桂林旅游知识图谱上采用的属性图模型示例:
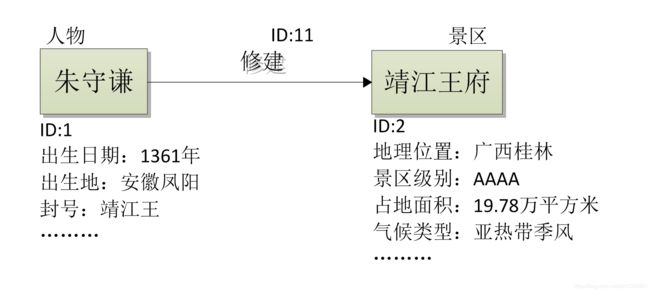
图中, ID=1, ID=2, ID=11 分别唯一的标识人物实体“朱守谦” 、 景区实体“靖江王府” 和关系“修建” 。 “出生日期: 1361 年” 、 “地理位置: 广西桂林”、“气候类型: 亚热带季风” 等这些就是他们各自的属性值对。
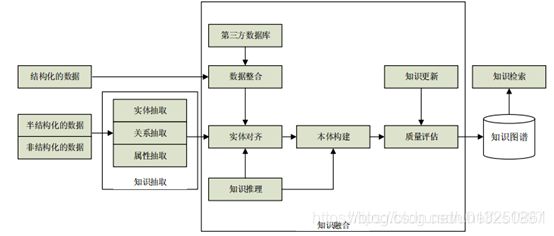
四、知识融合
通过知识抽取, 我们已经得到了海量的实体、 关系, 但是由于来源的不同, 会存在很多噪声数据, 重复的数据, 因此我们还需要对其进行清理和整合, 这个过程称为知识融合。
知识融合包含两个过程: 第一个过程是实体链接, 第二个过程是知识合并。 通过这两个过程可以消除噪声数据, 冗余数据, 合并相关的数据, 从而提高知识的质量。
1、实体链接
实体链接是指将我们获得的所有的相同实体、 相关实体都对应到知识库中同一个正确的实体上的操作。 首先, 我们判断现有知识库中的实体是否有相同实体或者相关实体, 也就是说将表示相同含义的实体合并为一个正确的实体; 接着通过实体抽取的相关技术获取到实体对象; 最后将实体对象对应到知识库中正确的实体上。
比如分别从携程、 途牛和驴妈妈三个旅游领域网站中拿到了广西所有的旅游景点信息, 从数据上可以发现存在一些问题。 例如携程网上有一个景点叫“七星景区” , 途牛网上有一个叫“七星公园” 的景区, 它们虽然名字不同, 但都是一个景区。
为了解决上面这个问题, 进行第一次数据融合, 其中会使用到一个开源的中文自然语言处理工具 Synonyms( https://github.com/huyingxi/Synonyms#synonyms) ,Synonyms 可以用于自然语言理解的很多任务例如: 文本对齐、 推荐算法、 相似度计算、 语义偏移、 关键字提取、 概念提取、 自动摘要、 搜索引擎等等。 它现在的词容量达到了 125792, 被誉为最好用的中文同义词词库。 使用示例如下:
word1="七星景区"
word2="七星公园"
r=synonyms.compare(word1, word2, seg=fales)
synonyms.compare 会返回 word1 和 word2 的相似度, seg 表示是否需要分词。
在实体合并部分仍然会使用到 Synonyms。 具体实现算法分为 3 部分, 第一部分实体链接、 第二部分属性链接、 第三部分属性值链接。
2、知识合并
知识合并主要是指当我们构建好自己的知识图谱时, 可以把第三方的知识库融入到我们自己的知识图谱中。 当然融入外部的知识库, 需要分别融入数据层和模式层。 模式层的融合包括: 概念的融合、 概念上下位关系的融合、 概念属性定义的融合。 数据层的融合包括: 实体的融合、 实体属性的融合。
融合算法如下所示: (携程网、 途牛网、 驴妈妈网获得的数据列表分别是 a、 b、 c),输入: a、 b、 c 任意 2 个:

算法执行两次, 每次输入为任意两个列表, 合并的结果再与第三个列表再作为算法的输入。 其中 r>0.7 是我们设定的阈值, 当两个词相似的概念大于 0.7 是, 认为是同义词, 是同一个景点, 反之则不是。
将 d 列表中的景点信息取出, 作为百度百科、 互动百科以及搜狗百科的输入,得到了广西所有旅游景点的 inforbox, 为了爬取方便, 最后所得到的结果都是以“==||****” 这样的形式保存, 因此现在需要对这样的数据先进行预处理,也就是说将数据格式处理为“实体, 属性, 属性值”的形式。 仔细观察得到数据, 会发现下图中红色框出的情况:
漓江的别称后应该对应一个实体, 而得到的数据对应的实体有 3 个, 因此需要对这种情况进行值分割,最后得到的结果如下图 所示, 从左到右分别是百度百科、 互动百科、 搜狗百科的数据。
ResultSet rs = statement.executeQuery(sql);
while(rs.next()){
String temp = rs.getString("shuju");
String name1 = temp.split("==")[0];
String name2 = temp.split("==")[1].split("\\|\\|")[0];
String name3 = temp.split("==")[1].split("\\|\\|")[1];
if(name3.indexOf("、 ") > -1){
nameAry = name3.split("、 ");}
if(name3.indexOf(", ") > -1){
nameAry = name3.split(", ");}
if(name3.indexOf("。 ") > -1){
nameAry = name3.split("。 ");}
}
最后得到的结果如下图 3-14 所示, 从左到右分别是百度百科、 互动百科、 搜狗百科的数据:
在预处理和第一次数据融合之后, 需要进行第二次数据融合, 也就是需要对百科的数据进行融合。 从上图中可以看出, 实体、 属性、 属性值都会出现指代相同但是名词不一样的情况例如: “七星景区” 和“七星公园” , “中文名称” 和“中文名” , “所在地” 和“地理位置” , “广西壮族自治区” 和“广西桂林” 等等。
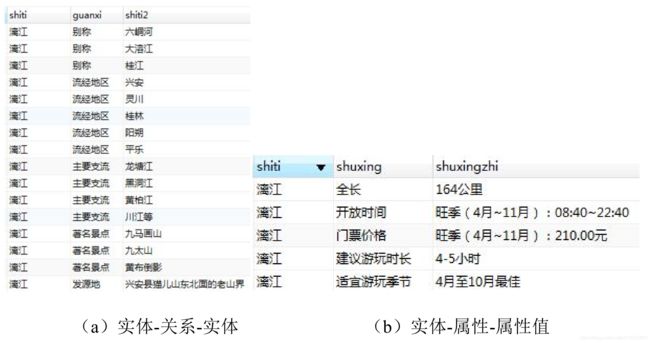
其次, 我们可以发现在这些三元组中其实包含了两种类型的三元组, 一种是(实体、 属性、 属性值) , 另外一种是(实体、 关系、 实体) 。 我们一直认为上图中所有的三元组都是(实体、 属性、 属性值) , 这样显然是不正确的, 注意用红色虚线框出的部分, 例如“流经地区、 只要主流、 地理位置” 等这些“属性” 划分为关系, 更为恰当。 因此在第二次数据融合中, 除了要融合相同的实体, 还要对从中提取出(实体、 关系、 实体) 。
在实体合并部分仍然会使用到 Synonyms。 具体实现算法分为 3 部分, 第一部分实体链接、 第二部分属性链接、 第三部分属性值链接。 (a、 b、 c 分别表示百度、互动和搜狗百科拿到的数据)


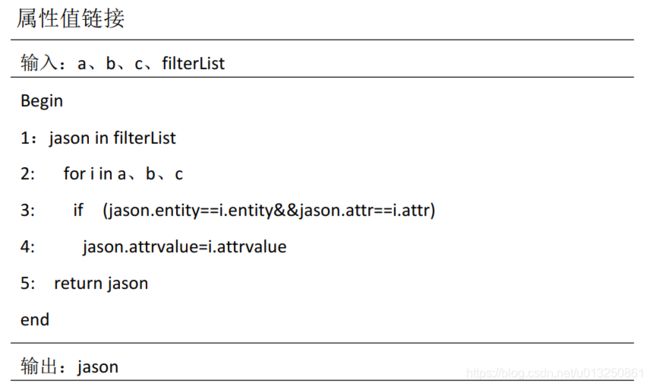
最后在通过人工的校验得到了最后合并的结果, 如图 3-15 所示
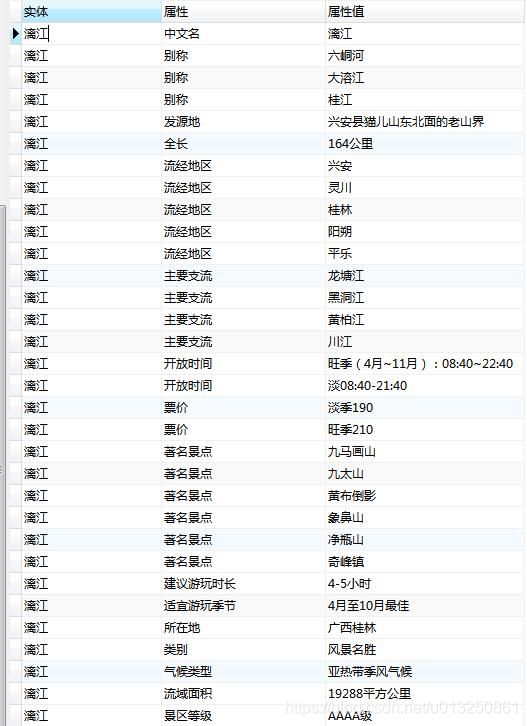
3、【实体-关系-实体 】v.s. 【实体-属性-属性值】
最后需要从需要从合并结果出划分出(实体、 关系、 实体) 。 这里使用 StanfordNLP 也就是斯坦福大学的自然语言处理工具, 因为是需要处理中文文本, 所以需要选用 PKU 训练资料, 也就是北京大学提供的训练资料。 再训练好模型之后, 使用Stanford NLP 从属性值中识别出命名实体, 最后处理结果如图所示:
五、 知识存储
知识图谱存储主要可以通过三种方式: 第一种是关系数据库(MySQL); 第二种是文档数据库(MongoDB); 第三种是图数据库(Neo4j)。
Neo4j 的优势在于:
- 它有一套自带的类似于 SQL 的查询语言 Cypher, 通过 Cypher就可以实现在数据库上增删查改;
- Neo4j 不使用 schema, 因此可以满足用户任何类型的数据需求;
- 在高度关联的数据上查询速度要比在关系数据库中进行查询快很多;
- 提供了一个可以支持大规模数据量的查询的模型。
- 提供了一个可视化的查询平台。
通过上一节的处理, 就得到了两种类型的三元组,
- 第一种是(实体、 关系、 实体) ,
- 第二种是(实体、 属性、 属性值) 。
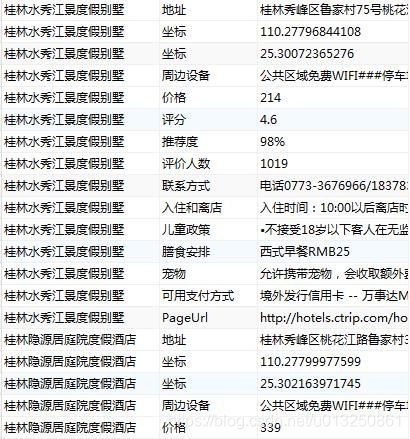
根据两种类型各自的特点, 考虑使用图数据库 neo4j 存储(实体、 关系、 实体) , 存储结果如下图所示:
使用关系数据库存储(实体、 属性、 属性值) , 存储结果如下图所示
参考资料:
知识图谱构建(概念,工具,实例调研)
8个最高效的Python爬虫框架,你用过几个?