当前表
my_db=# select * from users;
id | name | fullname | password
----+--------+----------------+----------
1 | ed | Ed Jones | 0000
2 | wendy | Wendy Williams | foobar
3 | mary | Mary Contrary | xxf12
4 | jack | Jack Bean | gjfdd
5 | rickyy | ricky yu | 1
my_db=# select * from addresses;
id | email_address | user_id
----+---------------+---------
1 | [email protected] | 4
2 | [email protected] | 4
3 | [email protected] | 5
4 | [email protected] | 5
(4 行记录)
删除
让我们删除rickyy用户,看看怎么回事,我们在会话中将该对象标记为已删除,然后我们发出查询,看看有没有剩余的行;
>>> session.delete('rickyy')
>>> session.query(User).filter_by(name='rickyy').count()
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password
FROM users
WHERE users.id = %(param_1)s
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine {'param_1': 5}
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine SELECT addresses.id AS addresses_id, addresses.email_address AS addresses_email_address, addresses.user_id AS addresses_user_id
FROM addresses
WHERE %(param_1)s = addresses.user_id ORDER BY addresses.id
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine {'param_1': 5}
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine UPDATE addresses SET user_id=%(user_id)s WHERE addresses.id = %(addresses_id)s
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine ({'addresses_id': 3, 'user_id': None}, {'addresses_id': 4, 'user_id': None})
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine DELETE FROM users WHERE users.id = %(id)s
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine {'id': 5}
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine SELECT count(*) AS count_1
FROM (SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password
FROM users
WHERE users.name = %(name_1)s) AS anon_1
2017-03-11 09:17:32,045 INFO sqlalchemy.engine.base.Engine {'name_1': 'rickyy'}
0L
我们可以看到,用户rickyy已经被删除了,我们再来看看Address表中的记录是否还在
>>> session.query(Address).filter(Address.email_address.in_(['[email protected]', '[email protected]'])).count()
2017-03-11 09:21:54,078 INFO sqlalchemy.engine.base.Engine SELECT count(*) AS count_1
FROM (SELECT addresses.id AS addresses_id, addresses.email_address AS addresses_email_address, addresses.user_id AS addresses_user_id
FROM addresses
WHERE addresses.email_address IN (%(email_address_1)s, %(email_address_2)s)) AS anon_1
2017-03-11 09:21:54,078 INFO sqlalchemy.engine.base.Engine {'email_address_2': '[email protected]', 'email_address_1': '[email protected]'}
2L
通过查询,发现Address表中和用户rikcyy关联的地址仍然存在,我们提交改动试试。
>>> session.commit()
2017-03-11 09:22:39,924 INFO sqlalchemy.engine.base.Engine COMMIT
>>>
提交后查看一下我们的数据库
my_db=# select * from addresses;
id | email_address | user_id
----+---------------+---------
1 | [email protected] | 4
2 | [email protected] | 4
3 | [email protected] |
4 | [email protected] |
(4 行记录)
我们可以看出,user_id列被置为NULL,但是行没有被删除,这是因为SQLAlchemy不会级联删除,我们必须告诉它这样做。
配置删除/级联删除
我们将在User.addresses关系上配置级联选项以更改行为。虽然SQLAlchemy允许我们在任何时间点添加新的属性和关系到映射,在这种情况下需要删除现有关系,因此我们需要完全拆除映射并重新开始 - 我们将关闭会话;
>>> session.close()
使用declarative_base()新建一个基类
>>> Base = declarative_base()
下面我们将重新定义User类,并添加addresses关系,包括级联配置。
>>> class User(Base):
... __tablename__ = 'users'
... id=Column(Integer, primary_key=True)
... name=Column(String)
... fullname=Column(String)
... password=Column(String)
... addresses = relationship('Address', back_populates="user",cascade='all,delete,delete-orphan')
... def __repr__(self):
... return "" % (self.name, self.fullname, self.password)
...
重新定义Address类
>>> class Address(Base):
... __tablename__ = 'addresses'
... id = Column(Integer, primary_key=True)
... email_address = Column(String, nullable=False)
... user_id = Column(Integer, ForeignKey('users.id'))
... user = relationship("User", back_populates="addresses")
... def __repr__(self):
... return "" % (self.email_address,)
...
接下来删除用户jack,可以从上面的表内容看出我们的用户jack有两个地址。
# 通过主键查询jack
>>> jack=session.query(User).get(4)
2017-03-11 09:42:16,760 INFO sqlalchemy.engine.base.Engine SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password
FROM users
WHERE users.id = %(param_1)s
2017-03-11 09:42:16,762 INFO sqlalchemy.engine.base.Engine {'param_1': 4}
>>> jack
# 删除jack的一个地址
>>> del jack.addresses[1]
# 查询删除后还有几个地址
>>> session.query(Address).filter(Address.email_address.in_(['[email protected]','[email protected]'])).count()
2017-03-11 09:43:46,957 INFO sqlalchemy.engine.base.Engine DELETE FROM addresses WHERE addresses.id = %(id)s
2017-03-11 09:43:46,957 INFO sqlalchemy.engine.base.Engine {'id': 2}
2017-03-11 09:43:47,000 INFO sqlalchemy.engine.base.Engine SELECT count(*) AS count_1
FROM (SELECT addresses.id AS addresses_id, addresses.email_address AS addresses_email_address, addresses.user_id AS addresses_user_id
FROM addresses
WHERE addresses.email_address IN (%(email_address_1)s, %(email_address_2)s)) AS anon_1
2017-03-11 09:43:47,003 INFO sqlalchemy.engine.base.Engine {'email_address_2': '[email protected]', 'email_address_1': '[email protected]'}
1L
我们删除jack,和他关联的所有地址将会被删除:
>>> session.delete(jack)
>>> session.query(User).filter_by(name='jack').count()
2017-03-11 09:44:21,401 INFO sqlalchemy.engine.base.Engine DELETE FROM addresses WHERE addresses.id = %(id)s
2017-03-11 09:44:21,404 INFO sqlalchemy.engine.base.Engine {'id': 1}
2017-03-11 09:44:21,407 INFO sqlalchemy.engine.base.Engine DELETE FROM users WHERE users.id = %(id)s
2017-03-11 09:44:21,408 INFO sqlalchemy.engine.base.Engine {'id': 4}
2017-03-11 09:44:21,413 INFO sqlalchemy.engine.base.Engine SELECT count(*) AS count_1
FROM (SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password
FROM users
WHERE users.name = %(name_1)s) AS anon_1
2017-03-11 09:44:21,414 INFO sqlalchemy.engine.base.Engine {'name_1': 'jack'}
0L
>>> session.query(Address).filter(Address.email_address.in_(['[email protected]','[email protected]'])).count()
2017-03-11 09:44:25,979 INFO sqlalchemy.engine.base.Engine SELECT count(*) AS count_1
FROM (SELECT addresses.id AS addresses_id, addresses.email_address AS addresses_email_address, addresses.user_id AS addresses_user_id
FROM addresses
WHERE addresses.email_address IN (%(email_address_1)s, %(email_address_2)s)) AS anon_1
2017-03-11 09:44:25,980 INFO sqlalchemy.engine.base.Engine {'email_address_2': '[email protected]', 'email_address_1': '[email protected]'}
0L
最后我们提交到数据库。
>>> session.commit()
再来看看当前的表内容:
my_db=# select * from addresses;
id | email_address | user_id
----+---------------+---------
3 | [email protected] |
4 | [email protected] |
(2 行记录)
my_db=# select * from addresses;
id | email_address | user_id
----+---------------+---------
3 | [email protected] |
4 | [email protected] |
(2 行记录)
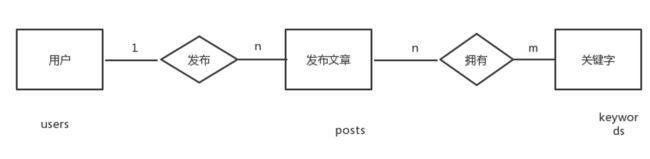
建立多对多的关系
在数据库中建立n:m的关系,需要新增加一个关系表。
我们再定义一个BlogPost类,多对多关系我们要创建一个没有映射的表作为关联表:
>>> from sqlalchemy import Table, Text
>>> post_keywords = Table('post_keywords', Base.metadata,
... Column('post_id', ForeignKey('posts.id'), primary_key=True),
... Column('keyword_id', ForeignKey('keywords.id'), primary_key=True)
... )
我们上面创建了一个表,只有两个字段分别参照两个不同的表,posts keywords表。
接下来我们定义这两个类
>>> class BlogPost(Base):
... __tablename__ = 'posts'
...
... id = Column(Integer, primary_key=True)
... user_id = Column(Integer, ForeignKey('users.id'))
... headline = Column(String(255), nullable=False)
... body = Column(Text)
...
... # many to many BlogPost<->Keyword
... keywords = relationship('Keyword',
... secondary=post_keywords,
... back_populates='posts')
...
... def __init__(self, headline, body, author):
... self.author = author
... self.headline = headline
... self.body = body
...
... def __repr__(self):
... return "BlogPost(%r, %r, %r)" % (self.headline, self.body, self.author)
>>> class Keyword(Base):
... __tablename__ = 'keywords'
...
... id = Column(Integer, primary_key=True)
... keyword = Column(String(50), nullable=False, unique=True)
... posts = relationship('BlogPost',
... secondary=post_keywords,
... back_populates='keywords')
...
... def __init__(self, keyword):
... self.keyword = keyword
因为发布文章表和关键词表时n:m的关系,所以需要使用relationship()建立关系,这里使用了secondary来定义多对多的关系。
我们也希望我们的BlogPost类有一个作者字段。我们将它添加为另一个双向关系,除了一个问题,我们将有一个单一的用户可能有很多博客文章。当我们访问User.posts时,我们希望能够进一步过滤结果,以便不加载整个集合。为此,我们使用一个被relationship()称为lazy ='dynamic'的设置,该属性在属性上配置一个备用加载器策略。
>>> BlogPost.author = relationship(User, back_populates="posts")
>>> User.posts = relationship(BlogPost, back_populates="author", lazy="dynamic")
创建一个新表
>>> Base.metadata.create_all(engine)
现在我们发布博客
>>> wendy = session.query(User).\
... filter_by(name='wendy').\
... one()
>>> post = BlogPost("Wendy's Blog Post", "This is a test", wendy)
>>> session.add(post)
我们将关键字存储在数据库中,但是现在还没有,所以我们可以创建它们:
>>> post.keywords.append(Keyword('wendy'))
>>> post.keywords.append(Keyword('firstpost')
我们现在可以使用关键字firstpost查找所有博文。我们将使用any运算符来定位“任何关键字具有关键字字符串firstpost的博客帖子
>>> session.query(BlogPost).filter(BlogPost.keywords.any(keyword='firstpost')).all()
2017-03-11 10:23:44,809 INFO sqlalchemy.engine.base.Engine INSERT INTO keywords (keyword) VALUES (%(keyword)s) RETURNING keywords.id
2017-03-11 10:23:44,809 INFO sqlalchemy.engine.base.Engine {'keyword': 'wendy'}
2017-03-11 10:23:44,809 INFO sqlalchemy.engine.base.Engine INSERT INTO keywords (keyword) VALUES (%(keyword)s) RETURNING keywords.id
2017-03-11 10:23:44,809 INFO sqlalchemy.engine.base.Engine {'keyword': 'firstpost'}
2017-03-11 10:23:44,809 INFO sqlalchemy.engine.base.Engine INSERT INTO posts (user_id, headline, body) VALUES (%(user_id)s, %(headline)s, %(body)s) RETURNING posts.id
2017-03-11 10:23:44,825 INFO sqlalchemy.engine.base.Engine {'body': 'This is a test', 'headline': "Wendy's Blog Post", 'user_id': 2}
2017-03-11 10:23:44,857 INFO sqlalchemy.engine.base.Engine INSERT INTO post_keywords (post_id, keyword_id) VALUES (%(post_id)s, %(keyword_id)s)
2017-03-11 10:23:44,857 INFO sqlalchemy.engine.base.Engine ({'keyword_id': 2, 'post_id': 1}, {'keyword_id': 1, 'post_id': 1})
2017-03-11 10:23:44,872 INFO sqlalchemy.engine.base.Engine SELECT posts.id AS posts_id, posts.user_id AS posts_user_id, posts.headline AS posts_headline, posts.body AS posts_body
FROM posts
WHERE EXISTS (SELECT 1
FROM post_keywords, keywords
WHERE posts.id = post_keywords.post_id AND keywords.id = post_keywords.keyword_id AND keywords.keyword = %(keyword_1)s)
2017-03-11 10:23:44,872 INFO sqlalchemy.engine.base.Engine {'keyword_1': 'firstpost'}
[BlogPost("Wendy's Blog Post", 'This is a test', )]
补充上面关系E-R图
参考官方文档:http://docs.sqlalchemy.org/en/latest/orm/tutorial.html#building-a-relationship