背景
这篇文章的背景是在最近的工作中涉及到了一些计算密集型任务,这些计算密集型任务或多或少触发了一些之前几乎没有关心过的Python性能问题,所以写下这篇文章分析Python的性能问题,并调研了一些对应的改善方案(Numba、Cython)。
坦白地说,在过往用Objective-C写iOS应用的经历中,除了一些面试和工作中常见的关于一些UI组件渲染的性能问题外,几乎没有关心过代码执行的效率(性能)问题。这次也正好是一个契机使我有机会复习一些本科学过的知识。
二维数组求和
首先让我们看一段简单的Python代码,这段代码定义了一个函数,其功能是对一个np.ndarray类型的二维数组求和,并返回结果:
def arr_sum(src_arr):
res = 0
shape = src_arr.shape
for r in range(0, shape[0]):
for c in range(0, shape[1]):
res += src_arr[r][c]
return res
这段代码没什么特别的,如果我们的src_arr.shape是128x128,上面这个代码片段执行1000次,在我的机器上(i7 6700K、32G),大概需要3.7857s,同样的,没有对比就没有伤害,同样的代码,如果我们用C++重写一下,大概会是这个样子:
double sum(double arr[][128], int row) {
double res = 0;
for (int i = 0; i < row; ++i) {
for (int j = 0; j < 128; ++j) {
res += arr[i][j];
}
}
return res;
}
这段代码的执行时间将会是0.035s,即大约35ms,可以看出,在这个场景下(当然,在实际的项目或者研究中,根据问题规模的不同,某个代码片段的实现也会不尽相同),还是可以有一个粗糙的结论:大概Python比C++慢了100倍。
虽然这个结论不是非常严谨,例如,我们出于某种面向对象的考虑,希望这段代码不是非常的胶水,可能会用std::vector或者某些容器替换一个C风格的二维数组:
template
T sum(vector>& arr, int row, int col) {
T res = 0;
for (int i = 0; i < row; ++i) {
for (int j = 0; j < col; ++j) {
res += arr[row][col];
}
}
return res;
}
而上面这段粗糙的实现对应的执行时间将会是0.060s,即60ms,但是仍然要比Python快出两个数量级,依然没有问题。
甚至如果你不幸将:
T sum(vector>& arr, int row, int col)
写成了:
T sum(vector> arr, int row, int col)
而导致函数调用时复制整个二维数组,也只需要4.3s,而对比Python的3.75s,反而会感觉还没慢多少。
为什么Python慢?
那么为什么Python会显得慢呢?首先,Python通常被称作解释型语言,是相对于像C++这样的编译型语言来说的。
事实上py文件也会被编译,但是并不像C++,或者是其他静态强类型编译型语言那样,通过预处理、编译、汇编、链接这样的过程最终得到机器码。py文件,即Python的源代码通常会在运行时被解释器先解释为字节码,然后交由虚拟机将字节码翻译成机器码执行,而这一步就很尬了。
事实上,也正是因为这样,我们往往才因此获得Python在运行时一些非常强大的特性,例如generator,利用generator我们可以做一些非常神奇的事情,例如协程等。
但是另一方面,Python的解释器和虚拟机翻译并执行字节码的过程带来了很大的性能开销,一个直觉的解释是:由于没有原生的编译时类型检查,所有的类型的检查都被移交给了运行时,执行一行Python代码很可能需要做不只一行的类型检查、边界检查等等。
这里其实并不打算详细探究Python字节码的编译与执行,只是简单的通过一个例子大致说明一行Python代码是如何被解释和执行的,
考虑源文件test.py,他们的实现很简单,其中test.py的实现大概是这样的:
def add(x, y):
res = x + y
print('Res: ' + res)
如你所见的,计算两个值的和,然后将结果打印到标准输出。
我们通过dis模块将test.py翻译成可读的字节码指令,将会是这样:
Disassembly of add:
2 0 LOAD_FAST 0 (x)
3 LOAD_FAST 1 (y)
6 BINARY_ADD
7 STORE_FAST 2 (res)
3 10 LOAD_GLOBAL 0 (print)
13 LOAD_CONST 1 ('Res: ')
16 LOAD_FAST 2 (res)
19 BINARY_ADD
20 CALL_FUNCTION 1 (1 positional, 0 keyword pair)
23 POP_TOP
24 LOAD_CONST 0 (None)
27 RETURN_VALUE
即,首先Python的源代码py文件将会被解释器翻译成上类似上面的东西,但是具体可能会更加复杂一点,但是我想到这一步应该已经能说明一些问题了,然后这个字节码会被Python虚拟机尝试执行,而在执行时则会有很多运行时的检查,然后才是转化为真正的机器码交由CPU执行。
而C++就不同了,因为他没有这一步。
其实,字节码也不是每次都是从磁盘读py文件在运行时编译的,事实上,每个在运行时被编译的py文件将会产生PyCodeObject对象,这一步操作是在解释import语句时执行的,PyCodeObject对象创建后,一方面将会根据需要被虚拟机继续转化为PyFrameObject对象进行后续的机器码翻译和执行工作,另一方面会带着一个“最后修改日期”的字段被缓存在磁盘上,通常,这个位置是在源代码同级目录下__pycache__文件夹中,这些被缓存的PyCodeObject对象将与源文件同名,只是扩展名为pyc,以便下次运行时直接读取缓存,从而节约编译字节码的时间。
所以,一个粗糙的结论可能是这样的,Python由于要在运行时编译和解释执行字节码,而且这个过程中参与了很多类似运行时类型检查的操作等一系列其他操作,从而产生了很多额外开销,降低了性能。
如何提速?
那么如何提速?在本文我们调研了两种方案,分别是Numba和Cython,接下来我们将分别简述它们的加速原理,并给出一些示例代码,并做一些简单的性能对比实验。
Numba
首先我们介绍Numba,先引一段官网文档的介绍:
Numba is a just-in-time compiler for Python that works best on code that uses NumPy arrays and functions, and loops. The most common way to use Numba is through its collection of decorators that can be applied to your functions to instruct Numba to compile them. When a call is made to a Numba decorated function it is compiled to machine code “just-in-time” for execution and all or part of your code can subsequently run at native machine code speed!
其中有两句话比较重要:
Numba is a just-in-time compiler for Python that works best on code that uses NumPy arrays and functions, and loops.
Numba是一个JIT编译器,它和Numpy的数组和函数以及循环一起用时,效果最佳。
另一句是:
When a call is made to a Numba decorated function it is compiled to machine code “just-in-time” for execution and all or part of your code can subsequently run at native machine code speed!
如果一个调用被Numba装饰器修饰,那么它将被JIT机制编译成机器码执行,性能堪比本地机器码的速度。
同样,它的原理简介也能在官网文档中找到:
Numba reads the Python bytecode for a decorated function and combines this with information about the types of the input arguments to the function. It analyzes and optimizes your code, and finally uses the LLVM compiler library to generate a machine code version of your function, tailored to your CPU capabilities. This compiled version is then used every time your function is called.
简要的概括即是,Numba通过一个装饰器读某些调用的字节码,并为它们的参数等添加类型信息,尝试优化代码后,通过LLVM编译器直接生成对应的机器码。
思想其实很明确,一方面是在字节码被执行前添加类型信息,然后省去原始调用的字节码被执行的过程,通过LLVM直接编译机器码,从而节省了性能开销,事实也确实如此。
通过引入numba模块,原始的Python代码将会被改写成这样:
import numba as nb
@nb.njit()
def arr_sum(src_arr):
res = 0
shape = src_arr.shape
for r in range(0, shape[0]):
for c in range(0, shape[1]):
res += src_arr[r][c]
return res
可以发现其实没什么变化,除了加了一个@nb.njit()的装饰器外,没有对原函数做任何改动,这其实也是numba的方便之处(与后续的Cython方案对比),事实上@nb.njit()会尽其所能去寻找能被numba的JIT机制添加类型信息并翻译成机器码的对象,如果失败了,运行起来的效果甚至会比原始的Python代码还慢。
在它的文档的开头也就提到,它和Numpy的数组和函数以及循环一起用时,效果最佳,同时文档也给出了一个暂时不支持pandas类型的例子。
详细的numba实现原理已经超出了本文做简单调研的范围,可能我们会有后续几篇文章讨论这个问题。
一个快速的入门文档可以参见:
https://numba.pydata.org/numba-doc/latest/user/5minguide.html
最后,添加numba装饰器后,代码片段对大小为128x128的二维数组求和,运行1000次时间为0.017122s,即17ms,比CXX还要快。
而JIT首次尝试编译求和函数代码的约为0.151606s,即150ms,所以,一个粗糙的结论是,如果这段代码确实性能开销较大,且被调用频率相对较高,那么一个短暂的编译时间还是可以被接受的。
Cython
接下来我们介绍Cython,
Cython是在Python中实现C-Extensions的一种方案,简单的理解是,Python提供了一些与CXX的Lib相互调用的机制,而能通过import作为模块来进行调用的C或者C++的Lib,就是C-Extensions,有很多方案可以用来实现C-Extensions,例如Swig等,而Cython就是其中一种。
同样引一段官方文档中关于Cython的介绍:
Cython is an optimising static compiler for both the Python programming language and the extended Cython programming language (based on Pyrex). It makes writing C extensions for Python as easy as Python itself.
它的核心精神是,Cython将Cython语言(一种基于Python的扩展语言)写的pyx文件直接编译成C extensions,从而获得近乎于写CXX语言的性能。
我们直接看一个Cython改写的二维数组求和代码片段,这个代码片段的文件名将会是func.pyx,可以注意到到与*.py结尾的文件不同,Cython的代码将是以pyx结尾。
cimport cython
@cython.boundscheck(False)
@cython.wraparound(False)
def arr_sum(double[:, :] src_arr):
cdef double res = 0
cdef Py_ssize_t[:] shape = src_arr.shape
cdef Py_ssize_t r = 0
cdef Py_ssize_t c = 0
for r in range(0, shape[0]):
for c in range(0, shape[1]):
res += src_arr[r][c]
return res
我们用了一些cdef关键字,来在定义变量时指明它们的类型,同时,我们使用了形如double[:, :]这样的关键字,它代表了Python中的MemoryView,即内存视图。简而言之,内存视图可以快速索引值,通过内存视图,我们可以避开繁琐的Python对象引用流程,直接访问一个二维数组某个下标值,如果不经转置,它在内存上应该是连续的,永远是通过一个基地址加上一个偏移量。
Cython文档在Typed Memory Views一节详细的介绍了这个机制,这里就不在赘述了。
https://cython.readthedocs.io/en/latest/src/userguide/memoryviews.html
看上去我们在写带类型标识符的Python,实际上这些代码都会被Cython先解释称CXX,然后编译成.so(Linux),通过编写对应的setup.py:
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize(["playground/cyfunc/func.pyx"], annotate=True)
)
打开annotate=True,Cython会替我们生成一份源码分析,如下图,详细的展示了pyx文件是如何生成CXX代码的,同时,黄色对应的行说明这行有Python调用,可能会影响能:
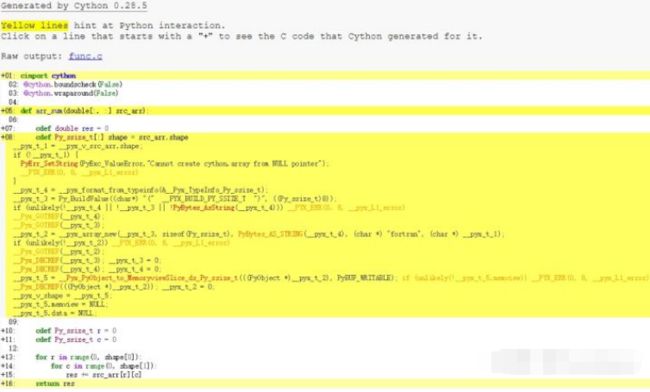
通过这种方式,代码片段对大小为128x128的二维数组求和,运行1000次时间为0.0181s,约18ms。
性能对比
最后我们给出了四组实验的结果,代码片段对大小为128x128的二维数组求和,运行1000次时间如下:
Total cost time for func: py_func, call 1000 times: 3.803216s.
Total cost time for func: np_func, call 1000 times: 0.343562s.
Total cost time for func: nb_func, call 1000 times: 0.017122s.
Total cost time for func: cy_func, call 1000 times: 0.018159s.
它们分别代表了原始Python、Numpy、Numba、Cython对应的性能。
需要注意的是,numba的编译时间约为150ms:
Time cost for numba first call: 0.151606s.
希望在之后的几篇文章中,将讨论Numba与Cython的实现细节。
以上。