random 用于生成随机数
import random
print random.random() #生成0到1之间的随机数
print random.randint(1,5) #随机生成1到5之间的整数 1<=x,x<=5
print random.randrange(1,5) #随机生成1到5之间的整数 1<=x,x<5
*生成六位字母和数字组成的随机数:
code = [] #定义列表
for i in range(6):
if i == random.randint(1,5):
code.append(str(random.randint(1,5)))
else:
temp = random.randint(65,90)
code.append(chr(temp))
print ''.join(code) #把列表格式化成字符串
MD5加密
import hashlib #导入模块
hash = hashlib.md5() #创建一个对象
hash.update('admin') #对象中update方法,通过这个方法将admin当做一个秘钥去通过MD5加密
print hash.hexdigest()
print hash.digest()
#打印结果
21232f297a57a5a743894a0e4a801fc3
'!#/)zW\xa5\xa7c\x89J\x0eJ\x80\x1f\xc3'
序列化和json
- pickle
在程序运行的过程中,所有变量都是在内存中,比如,定义一个dict:
d = dict(name='Bob',age=20,score=88)
可以随时修改变量,比如把name改成‘Bill’,但是一旦程序结束,变量所占用的内存就被操作系统全部收回。如果没有把修改后的‘Bill’存储到磁盘上,下次重新运行程序,变量又被初始化为‘Bob’。
我们把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也称之为serialization,marshalling,flattening等待,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
Python提供两个模块来实现序列化:cPickle和pickle。这两个模块功能是一样的,区别在于cpickle是C语言写的,速度快,pickle是存Python写的,速度慢,跟cstringIO和StringIO一个道理。用的时候,先尝试导入cpickle,如果失败,再导入pickle:
try:
import cPickle as pickle
except ImportError:
import pickle
pickle.dumps()方法把任意对象序列化成一个str,然后就可以把这个str写入文件。或者用另一个方法pickle.dump()直接把对象序列化后写入一个file-like Object
当我们要把对象从磁盘读到内存中时,可以先把内容读到一个str,然后再用pickle.loads()方法反序列化出对象。也可以直接用pickle.load()方法从一个file-like Object中直接反序列化出对象。
import pickle
li = ['alex',11,22,'ok','sb']
#序列化
dumpsed = pickle.dumps(li)
print dumpsed
print type(dumpsed)
#反序列化
loadsed = pickle.loads(dumpsed)
print loadsed
print type(loadsed)
#打印结果
(lp0
S'alex'
p1
aI11
aI22
aS'ok'
p2
aS'sb'
p3
a.
['alex', 11, 22, 'ok', 'sb']
import pickle
li = ['alex',11,22,'ok','sb']
pickle.dump(li,open('D:/temp.pk','w'))
#在D盘生成temp.pk文件内容为
(lp0
S'alex'
p1
aI11
aI22
aS'ok'
p2
aS'sb'
p3
a.
result = pickle.load(open('D:/temp.pk','r'))
print result
#打印结果
['alex', 11, 22, 'ok', 'sb']
-
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是 序列化为json,因为json表现出来的就是一个字符串,可以被所有语言读取,也可以方便的存储到磁盘或者通过网络传输。json不仅是标准格式,并且比XML更快,而且可以直接在web页面中读取,非常方便。
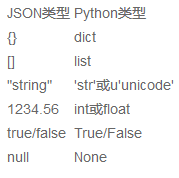
json表示的对象就是标准的JavaScript语言的对象,json和Python内置的数据类型对应如下:
 图片.png
图片.png
Python内置的json模块提供了非常完善的Python对象到json格式的转换,把一个Python对象变成一个json如下:
import json
d = dict(name='Bob',age=20,score=88)
result = json.dumps(d)
print result
print type(result)
#打印结果:
{"age": 20, "score": 88, "name": "Bob"}
dumps()方法返回一个str,内容就是标准的json。类似的,dump()方法可以直接把json写入一个file-like object。
要把json反序列化为Python对象,用loads()或者对应的load()方法,前者把json的字符串反序列化,后者从file-like object中读取字符串并反序列化:
import json
json_str = '{"age":20,"score":88,"name":"bob"}'
result = json.loads(json_str)
print result
print type(result)
#打印结果
{u'age': 20, u'score': 88, u'name': u'bob'}
- json进阶
Python的jict对象可以直接序列化为json的{},不过,很多时候,我们更喜欢用class表示对象,比如定义student类,然后序列化:
time模块
三种表达方式:
1、时间戳 1970年1月1日之后的秒
2、元组 包含了:年、日、星期等....time.struct_time
3、格式化的字符串:2014-11-11 11:11 print time.time()
import time
#时间戳
re = time.time()
print re
#格式化字符串
re2 = time.gmtime()
print re2
#字符串格式化之后的时间
re3 = time.strftime('%Y-%m-%d %H:%M:%S')
print re3
#打印结果
1505877440.01
time.struct_time(tm_year=2017, tm_mon=9, tm_mday=20, tm_hour=3, tm_min=17, tm_sec=20, tm_wday=2, tm_yday=263, tm_isdst=0)
2017-09-20 11:22:39
- 相互转换
#字符串格式转换结构化格式
print time.strptime('2017-09-20','%Y-%m-%d')
打印结果:
time.struct_time(tm_year=2017, tm_mon=9, tm_mday=20, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=2, tm_yday=263, tm_isdst=-1)
#结构化的时间转换为时间戳
print time.localtime()
print time.mktime(time.localtime())
#打印结果
time.struct_time(tm_year=2017, tm_mon=9, tm_mday=20, tm_hour=14, tm_min=20, tm_sec=46, tm_wday=2, tm_yday=263, tm_isdst=0)
1505888446.0
sys
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.maxunicode 最大的Unicode值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
print val
os
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间