企业级大数据项目【2】数仓-流量域ODS-DWD开发篇
1数仓整体说明
什么数仓:一个面向分析的,反映历史变化的数据仓库;
数仓的技术手段:
1)传统数仓一般都是采用关系型数据库软件;
2)大数据领域中则尚无一站式解决方案,通常需要用到很多技术组件来实现不同环节:
- 使用HDFS做存储
- 使用 spark、mapreduce 作为底层计算引擎
- 使用hive或者sparksql,作为sql引擎
- 另外,还有impala/presto纯内存运算引擎,kylin,clickhouse 等各类组件
1.1技术选型
数据采集:flume
存储平台:hdfs
基础设施:hive
运算引擎:mapreduce/spark
资源调度:yarn
任务调度:azkaban/oozie
元数据管理:atlas(或自研系统)
OLAP引擎:kylin/presto (或clickhouse)
前端界面:superset(或自研javaweb系统)
1.2分层设计
分层原因
数据仓库中的数据表,往往是分层管理、分层计算的;
所谓分层,具体来说,就是将大量的数据表按照一定规则和定义来进行逻辑划分;
- ADS层: 应用服务层
- DWS层:数仓服务(service/summary)层(轻度聚合)
- DWD层:数仓明细层
- ODS层:操作数据(最原始的数据)层 – 贴源层
- DIM层:存储维表
ODS层:对应着外部数据源ETL到数仓体系之后的表!
DWD层:数仓明细层;一般是对ODS层的表按主题进行加工和划分;本层中表记录的还是明细数据; DWS层:数仓服务层; ADS层:
应用层,主要是一些结果报表!
分层的意义:数据管理更明晰!运算复用度更高!需求开发更快捷!便于解耦底层业务(数据)变化!
分层详解
ODS层
数据内容:存放flume采集过来的原始日志
存储格式:以json格式文本文件存储
存储周期:3个月
DWD层
数据内容:对ODS层数据做ETL处理后的扁平化明细数据
存储格式:以orc / parquet文件格式存储
存储周期:6个月
DWS层
数据内容:根据主题分析需求,从DWD中轻度聚合后的数据
存储格式:以ORC/PARQUET文件格式存储
存储周期:1年
ADS层
数据内容:根据业务人员需求,从DWS计算出来的报表
存储格式:以ORC/PARQUET文件格式存储
存储周期:3年
DIM层
存储各种维表
1.3模型设计
ODS层
与原始日志数据保持完全一致
我们有APP端日志,PC端日志,微信小程序端日志,分别对应ODS的三个表
ODS.ACTION_APP_LOG
ODS.ACTION_WEB_LOG
ODS.ACTION_WXAPP_LOG
建表时,一般采用外部表;
表的数据文件格式:跟原始日志文件一致
分区:按天分区(视数据量和计算频度而定,如数据量大且需每小时计算一次,则可按小时粒度分区)
DWD层
建模思想
通常是对ODS层数据进行精细化加工处理
不完全星型模型
事实表中,不是所有维度都按维度主键信息存储(维度退化)
- 地域维度信息:年月日周等时间维度信息,这些维度信息,基本不会发生任何改变,并且在大部分主题分析场景中,都需要使用,直接在事实表中存储维度值
- 页面信息:页面类别信息,频道信息,业务活动信息,会员等级信息等,可能发生缓慢变化的维度信息,事实表中遵循经典理论存储维度主键,具体维度值则在主题分析计算时临时关联
事实表
app_event_detail: APP-Event事件明细表
web_event_detail: WEB-Event事件明细表
wxapp_event_detail: 小程序-Event事件明细表
维度表
coupon_info
ad_info
campain_info
lanmu_info
page_info
page_type
pindao_info
promotion_location
huodong_info
miaosha_info
product
product_detail
product_type
shop_info
tuangou_info
user_info
DWS层
建模思想
- 主题建模
- 维度建模
最主要思路:按照分析主题,"汇总"各类数据成大宽表
也有一些做法是,将DWS层的表设计成“轻度聚合表”
主要表模型
流量会话聚合天/月表
日新日活维度聚合表
事件会话聚合天/月表
访客连续活跃区间表
新用户留存维度聚合表
运营位维度聚合表
渠道拉新维度聚合表
访客分布维度聚合表
用户事件链聚合表(支撑转化分析,高级留存分析等)
……更多
2埋点日志采集
2.1概述
埋点日志在本项目中,有3大类:
- App端行为日志
- PC web端行为日志
- 微信小程序端行为日志
日志生成在了公司的N台(5台)日志服务器中,现在需要使用flume采集到HDFS
2.2需求
- 3类日志采集后要分别存储到不同的hdfs路径
- 日志中的手机号、账号需要脱敏处理(加密)
- 不同日期的数据,要写入不同的文件夹,且分配应以事件时间为依据
- 因为日志服务器所在子网跟HDFS集群不在同一个网段,需要中转传输
2.3方案设计

2.4具体实现
- 上游配置文件
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sources.r1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = g1 g2
a1.sources.r1.filegroups.g1 = /opt/data/logdata/app/event.*
a1.sources.r1.filegroups.g2 = /opt/data/logdata/wx/event.*
a1.sources.r1.headers.g1.datatype = app
a1.sources.r1.headers.g2.datatype = wx
a1.sources.r1.batchSize = 100
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.doitedu.flume.interceptor.EventTimeStampInterceptor$EventTimeStampInterceptorBuilder
a1.sources.r1.interceptors.i1.headerName = timestamp
a1.sources.r1.interceptors.i1.timestamp_field = timeStamp
a1.sources.r1.interceptors.i1.to_encrypt_field = account
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/data/flumedata/file-channel/checkpoint
a1.channels.c1.dataDirs = /opt/data/flumedata/file-channel/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hdp02.doitedu.cn
a1.sinks.k1.port = 41414
a1.sinks.k1.batch-size = 100
a1.sinks.k2.channel = c1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hdp03.doitedu.cn
a1.sinks.k2.port = 41414
a1.sinks.k2.batch-size = 100
# 定义sink组及其配套的sink处理器
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 1
a1.sinkgroups.g1.processor.maxpenalty = 10000
- 下游配置文件
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
a1.sources.r1.batchSize = 100
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/data/flumedata/file-channel/checkpoint
a1.channels.c1.dataDirs = /opt/data/flumedata/file-channel/data
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hdp01.doitedu.cn:8020/logdata/%{datatype}/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = DoitEduData
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.rollSize = 268435456
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.useLocalTimeStamp = false
- 拦截器类开发
3ODS层详细设计
3.1ODS层功能
ODS:操作数据层
- 主要作用:直接映射操作数据(原始数据),数据备份;
- 建模方法:与原始数据结构保持完全一致
- 存储周期:相对来说,存储周期较短;视数据规模,增长速度,以及业务的需求而定;对于埋点日志数据ODS层存储,通常可以选择3个月或者半年;存1年的是土豪公司(或者确有需要,当然,也有可能是数据量很小)
3.2数据规模
假如:公司用户规模1000万
平均日活400万
平均每天每个用户访问1.2次
每个用户平均每次访问时长10分钟
按经验,每个用户平均每 5~10 秒产生一条事件
则每次访问,将产生10分钟60秒/10 = 60条事件日志
则,每天产生的日志总条数: 400万1.2*60条 = 28800 *万=2.88亿条日志
每条日志大小平均为0.5k,则每日增量日志大小为:
28800万0.5k = 288005M= 144G
每月累积增量为:144G*30 = 4.3T
假如要存储1年的数据量,则1年的累计存储量为:51.6T
考虑,增长趋势: 预估每月增长20%
则1年的累计存储量为:接近100T
注:在这里也可以估算实时流式计算中的数据量,假如最高峰值时,每秒同时在线人数有10万,则在此峰值期间,每秒将有2万条日志产生
3.3数据采集
采集源:KAFKA
TOPIC:app_log, wx_log,web_log
采集工具:FLUME
4ODS层开发手册
4.1日志数据
4.1.1日志数据类型

4.1.2入库要求
- 原始日志格式
普通文本文件,JSON数据格式,导入hive表后,要求可以很方便地select各个字段
- 分区表
- 外部表
4.2创建外部表
4.2.1Json数据的hvie解析
由于原始数据是普通文本文件,而文件内容是json格式的一条一条记录
在创建hive表结构进行映射时,有两种选择:
1.将数据视为无结构的string
2.将数据按json格式进行映射(这需要外部工具包JsonSerde 的支持)
本项目采用方案2来进行建表映射
- @Deprecated
下载第三方JsonSerde工具包
JsonSerde 的 github 地址:https://github.com/rcongiu/Hive-JSON-Serde
JsonSerde 的 jar下载地址:http://www.congiu.net/hive-json-serde/
下载 json-serde-1.3.7-jar-with-dependencies.jar 并上传到 Hive的/lib库目录下
如果需要,也可以把本jar包安装到本地maven库
bin\mvn install:install-file -Dfile=d:/json-serde.1.3.8.jar
-DgroupId=“org.openx.data” -DartifactId=json-serde -Dversion=“1.3.8” -Dpackaging=jar
- 使用HIVE内置JsonSerDe
在hive3.0中,直接用hive内置的JsonSerDe也很方便

ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.JsonSerDe’ 官方文档:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-JSON
4.2.2知识补充:hive建表完整写法
create table t3(
id int,
name string
)
PARTITIONED BY (dt string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'line.delim'='\n'
)
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
TBLPROPERTIES(
'EXTERNAL'='TRUE',
'comment'='this is a ods table',
'orc.compress'='snappy'
)
;
4.2.3app事件日志建表
drop table if exists ods.app_event_log;
create external table ods.app_event_log
(
account string,
appId string,
appVersion string,
carrier string,
deviceId string,
deviceType string,
eventId string,
ip string,
latitude double,
longitude double,
netType string,
osName string,
osVersion string,
properties map,
releaseChannel string,
resolution string,
sessionId string,
`timeStamp` bigint
)
partitioned by (y string,m string,d string)
row format serde 'org.apache.hive.hcatalog.data.JsonSerDe'
stored as textfile
;
4.2.4web事件日志
drop table if exists ods.web_event_log;
create external table ods.web_event_log(
// TODO 自己补上
)
partitioned by (y string,m string,d string)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile;
4.2.5wxapp事件日志
drop table if exists ods.wxapp_event_log;
create external table ods.wxapp_event_log(
// TODO 自己补上
)
partitioned by (y string,m string,d string)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile;
4.3日志数据入库
4.3.1入库命令
load data inpath ‘/pa/th’ into table ods.app_event_log partition (y=’2020’,m=’06’,d=’22’);
load data inpath ‘/pa/th’ into table ods.web_event_log partition (y=’2020’,m=’06’,d=’22’);
load data inpath ‘/pa/th’ into table ods.wxapp_event_log partition (y=’2020’,m=’06’,d=’22’);
4.3.2脚本开发
5DIM层维表数据
用户信息,在业务系统的mysql数据库中
产品信息,在业务系统的mysql数据库中
活动信息,团购信息,秒杀信息等,在业务系统的mysql数据库中
频道,栏目信息,向app前端开发组发出需求,请求提供
6DWD层详细设计
6.1数据位置

6.2技术选型
由于本层数据ETL的需求较为复杂,用hive sql实现非常困难
因而此环节将开发spark程序来实现
6.3需求分析
清洗过滤
1,去除json数据体中的废弃字段(前端开发人员在埋点设计方案变更后遗留的无用字段):
2,过滤掉json格式不正确的(脏数据)
3,过滤掉日志中缺少关键字段(deviceid/properties/eventid/sessionid 缺任何一个都不行)的记录!
4,过滤掉日志中不符合时间段的记录(由于app上报日志可能的延迟,有数据延迟到达)
5,对于web端日志,过滤爬虫请求数据(通过useragent标识来分析)
数据解析
将json打平,解析成扁平格式

注:properties字段不用扁平化,转成Map类型存储即可
SESSION分割
1,对于web端日志,按天然session分割,不需处理
2,对于app日志,由于使用了会话保持策略,导致app进入后台很长时间后,再恢复前台,依然是同一个session,不符合session分析定义,需要按事件间隔时间切割(业内通用:30分钟)
3,对于wx小程序日志,与app类似,session有效期很长,需要按事件间隔时间切割(业内通用:30分钟)
数据规范处理
- Boolean字段,在数据中有使用1/0/-1标识的,也有使用true/false表示的,统一为Y/N/U
- 字符串类型字段,在数据中有空串,有null值,统一为null值
- 日期格式统一, 2020/9/2 2020-9-2 2020-09-02 都统一成 YYYY-MM-dd
- 小数类型,统一成decimal
- 字符串,统一成string
- 时间戳,统一成bigint
- ……
数据集成
1,将日志中的GPS经纬度坐标解析成省、市、县(区)信息;(为了方便后续的地域维度分析)
2,将日志中的IP地址解析成省、市、县(区)信息;(为了方便后续的地域维度分析)
注:app日志和wxapp日志,有采集到的用户事件行为时的所在地gps坐标信息
web日志则无法收集到用户的gps坐标,但可以收集到ip地址
gps坐标可以表达精确的地理位置,而ip地址只能表达准确度较低而且精度较低的地理位置
ID_MAPPING(全局用户标识生成)
为每一个用户每一条访问记录,标识一个全局唯一ID
(给匿名访问记录,绑定到一个id上)
选取合适的用户标识对于提高用户行为分析的准确性有非常大的影响,尤其是漏斗、留存、Session 等用户相关的分析功能。
因此,我们在进行任何数据接入之前,都应当先确定如何来标识用户。
新老访客标记
新访客,标记为1
老访客,标记为0
保存结果
最后,将数据输出为parquet格式,压缩编码用snappy
注:parquet和orc都是列式存储的文件格式,两者对于分析运算性的读取需求,都有相似优点
在实际性能测试中(读、写、压缩性能),ORC略优于PARQUET此处可以选择orc,也可以选择parquet,选择parquet的理由则是,parquet格式的框架兼容性更好,比如impala支持parquet,但不支持orc
6.4关键设计
GPS地理位置解析
gps坐标数据形如: (130.89892350983459, 38.239879283598)
怎样才能解析为地理位置: 河北省,石家庄市,裕华区
- GEOHASH编码介绍
Geohash编码是一种地理位置编码技术,它可将一个gps坐标(含经、纬度)点,转化为一个字符串;
wx3y569
wx3y569
通过编码后得到的字符串,表达的是:包含被编码gps坐标点的一个矩形范围;

- GEOHASH编码原理
在地球经纬度范围内,不断通过二分来划分矩形范围,通过观察gps坐标点所落的范围,来反复生成0/1二进制码。
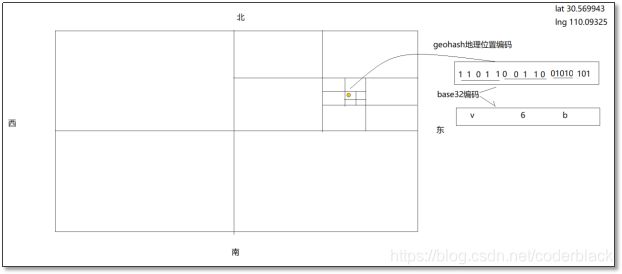
在满足精度要求后,将所得的二进制编码通过base32编码技术转成字符串码,如下所示:

- GEOHASH码的精度
字符串长度越长,表达的精度越高,矩形范围越小,越逼近原gps坐标点;
相反,长度越短,表达的精度越低,矩形范围越大;
geohash码的精确度对应表格:

- GEOHASH编码工具包
gps坐标 转码成 geohash编码,这个算法不需要自己手写,有现成的工具包
maven依赖坐标:
ch.hsr
geohash
1.3.0
api调用示例:
String geohashcode = GeoHash.withCharacterPrecision(45.667, 160.876547, 6).toBase32();
高德地图开放API
IP地址地理位置解析
ip地址数据形如:202.102.36.87
怎样才能解析为地理位置: 江苏省,南京市,电信
通过算法是无法从ip地址算出地理位置的
需要ip和地理位置映射字典才有可能做到,类似如下数据:

- IP查找算法
将字典中的起始ip和结束ip,都设法转成整数,这样,ip地址段就变成了整数段
接下来,将未知区域的ip按照相同方法转换成整数,则能相对方便地查找到字典数据了
具体的搜索算法,可以使用二分查找算法
- IP地理位置处理工具包
开源工具包ip2region(含ip数据库)
项目地址: https://gitee.com/lionsoul/ip2region

使用方法
引入jar包依赖:
Api调用代码
// 初始化配置参数
val config = new DbConfig
// 构造搜索器,dbFile是ip地址库字典文件所在路径
val searcher = new DbSearcher(config, “initdata/ip2region.db”)
// 使用搜索器,调用查找算法获取地理位置信息
val block = searcher.memorySearch(“39.99.177.94”)
println(block)
6.5难点设计ID_MAPPING
在登录状态下,日志中会采集到用户的登录id(account),可以做到用户身份的精确标识;
而在匿名状态下,日志中没有采集到用户的登录id
如何准确标识匿名状态下的用户,是一件棘手而又重要的事情;
困难原因
在事件日志中,对用户能产生标识作用的字段有:
app日志中,有deviceid,account
web日志中,有cookieid,ip,account
wxapp日志中,有openid,account
在现实中,一个用户,可能处于如下极其复杂的状态:
- 登录状态访问app
- 匿名状态访问app
- 登录状态访问web
- 匿名状态访问web
- 登录状态访问wx小程序
- 匿名状态访问wx小程序
- 一个用户可能拥有不止一台终端设备
- 一台终端设备上可能有多个用户使用
- 一个用户可能一段时间后更换手机
- ……
备选方案(了解)
1,只使用设备 ID
- 适用场景
适合没有用户注册体系,或者极少数用户会进行多设备登录的产品,如工具类产品、搜索引擎、部分小型电商等。
这也是绝大多数数据分析产品唯一提供的方案。
- 局限性
同一用户在不同设备使用会被认为不同的用户,对后续的分析统计有影响。
不同用户在相同设备使用会被认为是一个用户,也对后续的分析统计有影响。
但如果用户跨设备使用或者多用户共用设备不是产品的常见场景的话,可以忽略上述问题。

2,关联设备 ID 和登录 ID(一对一)
- 适用场景
成功关联设备 ID 和登录 ID 之后,用户在该设备 ID 上或该登录 ID 下的行为就会贯通,被认为是一个 全局 ID 发生的。在进行事件、漏斗、留存等用户相关分析时也会算作一个用户。
关联设备 ID 和登录 ID 的方法虽然实现了更准确的用户追踪,但是也会增加复杂度。
所以一般来说,我们建议只有当同时满足以下条件时,才考虑进行 ID 关联:
需要贯通一个用户在一个设备上注册前后的行为。
需要贯通一个注册用户在不同设备上登录之后的行为。
- 局限性
一个设备 ID 只能和一个登录 ID 关联,而事实上一台设备可能有多个用户使用。
一个登录 ID 只能和一个设备 ID 关联,而事实上一个用户可能用一个登录 ID 在多台设备上登录。

3,关联设备 ID 和登录 ID(多对一)
- 适用场景
一个用户在多个设备上进行登录是一种比较常见的场景,比如 Web 端和 App 端可能都需要进行登录。支持一个登录 ID 下关联多设备 ID 之后,用户在多设备下的行为就会贯通,被认为是一个ID 发生的。
- 局限性
一个设备 ID 只能和一个登录 ID 关联,而事实上一台设备可能有多个用户使用。
一个设备 ID 一旦跟某个登录 ID 关联或者一个登录 ID 和一个设备 ID 关联,就不能解除(自动解除)。
而事实上,设备 ID 和登录 ID 的动态关联才应该是更合理的。

4,关联设备 ID 和登录 ID(动态修正)
基本原则,与方案3相同
修正之处,一个设备ID被绑定到某个登陆ID(A)之后,如果该设备在后续一段时间(比如一个月内)被一个新的登陆ID(B)更频繁使用,则该设备ID会被调整至绑定登陆ID(B)
咱们项目中,就采用最复杂的方案4
7DWD开发手册
7.1Maven知识扩展
父子工程
父工程的pom中会包含module定义:

子工程的pom中会有parent定义:

依赖继承
父工程中引入的依赖,所有子工程都会自动继承

依赖管理
父工程通过dependencyManagement声明依赖的相关属性(版本),但并不会真正引入依赖;
子工程在引入dependencyManagement所声明的依赖时,不需要指定版本,直接继承dependencyManagement中声明的版本!

属性定义
通过properties标签可以声明自定义属性(属性名、属性值)
在pom中的别的地方就可以用${属性名}来引用属性的值!
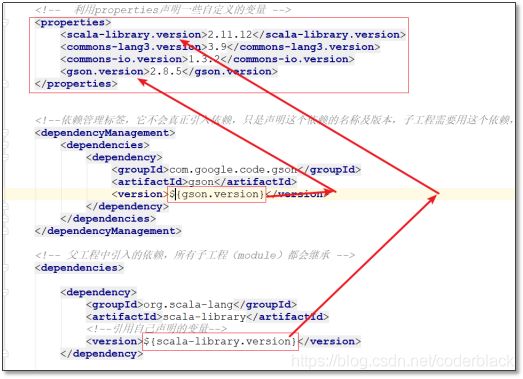
传递依赖的排除
如果我们直接引入了依赖A/B/C,都有传递依赖D,而且对D依赖的版本各不相同!就有可能在运行时产生依赖冲突!可以通过排除掉一些传递依赖来避免冲突!

7.2项目工程搭建


创建一个父工程;
父工程中引入公共的依赖和插件;
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.doitedu</groupId>
<artifactId>data_tiger</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>dataware</module>
<module>userprofile</module>
<module>recommend</module>
<module>streamingprocess</module>
<module>common</module>
</modules>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
</dependencies>
<pluginRepositories>
<pluginRepository>
<id>ali-plugin</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
<build>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${
project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
然后在父工程中创建各个子工程;

编写demo代码,测试工程;
项目的码云git地址:
https://gitee.com/hunter_d/doyiee.git
7.3Git版本协作管理
Git插件配置
机器上装好了git客户端

idea上的git插件,修改了git程序的本地安装目录

然后在idea中,通过settings->plugin ,搜索gitee插件,并安装
项目拉取


项目的git地址: https://gitee.com/hunter_d/doit12_yiee.git
以后,每当服务器上的项目有更新,本地可以通过pull命令来拉取、同步

7.4工具代码开发
IP地址地理位置解析
String ip = "202.102.36.87";
DbConfig config = new DbConfig();
// 加载ip字典库文件为一个字节数组
File file = new File("initdata\\ip2region.db");
RandomAccessFile ra = new RandomAccessFile(file, "r");
byte[] b = new byte[(int)file.length()];
ra.readFully(b);
// 构造一个ip2region搜索器
DbSearcher dbSearcher = new DbSearcher(config, b);
DataBlock block = dbSearcher.memorySearch(ip);
String region = block.getRegion();
System.out.println(region);
GPS坐标地理位置解析
val geo = GeoHash.geoHashStringWithCharacterPrecision(lat,lng,6)这里插入代码片
时间戳解析
将时间戳解析成年月日时分秒,本处理需求也可以在入仓后用sql进行处理
7.5IdBind绑定评分计算
步骤:
1.加载T日日志数据,抽取 设备id、登录账号、会话id、时间戳
2.根据设备id+登录账号account分组,计算每个设备上每个登录账号的登陆次数(评分)
3.加载T-1日的绑定评分结果
4.将T日评分表 full join T-1日评分表,根据情况进行取值
原则:两边都有,分数累加;
T-1有,T无,则分数衰减;
代码片段,完整代码见项目工程
object IdBind {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val spark = SparkSession.builder()
.config("spark.sql.shuffle.partitions","2")
.enableHiveSupport() // 开启hive整合支持(同时,需要引入spark-hive的依赖;引入hadoop和hive的配置文件)
.appName("地理位置知识库加工")
.master("local")
.getOrCreate()
// 加载T日日志数据
val logDf = spark.read.table("ods17.app_action_log").where("dt='2020-10-07'")
logDf.createTempView("logdf")
// 计算T日的 设备->账号 绑定得分
val loginCnts = spark.sql(
"""
|
|select
|deviceid,
|if(account is null or trim(account)='',null,account) as account,
|-- count(distinct sessionid) as login_cnt,
|min(timestamp) as first_login_ts,
|count(distinct sessionid)*100 as bind_score
|from logdf
|group by deviceid,account
|
|""".stripMargin)
loginCnts.createTempView("today")
println("当天评分结果")
loginCnts.show(100)
// 加载 T-1的 绑定得分 (从hive的绑定评分表中加载)
// val bindScorePre = spark.read.parquet("dataware/data/idbind/output/day01")
val bindScorePre = spark.read.table("dwd17.id_account_bind").where("dt='2020-10-06'")
println("历史评分结果")
bindScorePre.show(100)
bindScorePre.createTempView("yestoday")
// 全外关联两个绑定得分表
// 并将结果写入hive表的当天分区(T-1日分区就无用了)
val combined = spark.sql(
"""
|
|insert into table dwd17.id_account_bind partition(dt='2020-10-07')
|
|select
|if(today.deviceid is null,yestoday.deviceid,today.deviceid) as deviceid,
|if(today.account is null,yestoday.account,today.account) as account,
|if(yestoday.first_login_ts is not null,yestoday.first_login_ts,today.first_login_ts) as first_login_ts,
|-- if(today.account is null,yestoday.login_cnt,today.login_cnt+yestoday.login_cnt) as login_cnt,
|if(today.account is null,yestoday.bind_score*0.9,today.bind_score+if(yestoday.bind_score is null,0,yestoday.bind_score)) as bind_score
|from
| today
|full join
| yestoday
|on today.deviceid=yestoday.deviceid and today.account=yestoday.account
|
|""".stripMargin)
spark.close()
}
}
7.6ODS_2_DWD ETL主程序开发
7.6.1逻辑设计
- 加载数据
从hive仓库的ods表读取源数据
从hive仓库读取维表geohash字典,并进行广播
从hive仓库读取全局用户id表,并进行广播
从hdfs读取ip地理位置字典,并进行广播
- 清洗,集成
将每行数据封装成case class
按照要求进行过滤
提取gps,从geohash字典匹配省市区信息
如果gps匹配失败,则提取ip地址匹配省市区信息
如果account为空,则根据deviceid,去全局guid字典匹配account
- 新老访客标记
- session切割
7.6.2完整代码
代码片段,完整代码见项目工程
package cn.doitedu.dwetl
import java.text.SimpleDateFormat
import java.util.UUID
import ch.hsr.geohash.GeoHash
import cn.doitedu.dwetl.beans.AppLogBean
import cn.doitedu.dwetl.utils.Row2AppLogBean
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{
FSDataInputStream, FileStatus, FileSystem, Path}
import org.apache.log4j.{
Level, Logger}
import org.apache.spark.SparkFiles
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{
DataFrame, Dataset, Row, SparkSession}
import org.lionsoul.ip2region.{
DbConfig, DbSearcher}
/**
* @author 涛哥
* @nick_name "deep as the sea"
* @contact qq:657270652 wx:doit_edu
* @site www.doitedu.cn
* @date 2021-01-14
* @desc ods层app端行为日志数据,处理为dwd明细表
*
* 目标表建表语句
CREATE TABLE dwd.event_app_detail (
account String ,
appid String ,
appversion String ,
carrier String ,
deviceid String ,
devicetype String ,
eventid String ,
ip String ,
latitude Double ,
longitude Double ,
nettype String ,
osname String ,
osversion String ,
properties Map ,
releasechannel String ,
resolution String ,
sessionid String ,
`timestamp` BIGINT ,
newsessionid String ,
country String ,
province String ,
city String ,
region String ,
guid String ,
isnew String
)
PARTITIONED BY (dt string)
STORED AS parquet
TBLPROPERTIES("parquet.compress"="snappy")
;
*
*/
object EventAppLog2DwdTable {
def main(args: Array[String]): Unit = {
if(args.size<3){
println(
"""
|
|wrong number of parameters
|usage:
| args(0) : T-1日
| args(1) : T日
| args(2) : T+1日
|
|""".stripMargin)
}
val DT_PRE = args(0)
val DT_CUR = args(1)
val DT_NEXT = args(2)
//Logger.getLogger("org").setLevel(Level.FATAL)
val spark = SparkSession.builder()
.appName("ods层app端行为日志数据,处理为dwd明细表")
//.master("local[*]")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
/**
* 加载各种字典数据,并广播
*/
// 1.geohash字典
val geodf: Dataset[Row] = spark.read.parquet("/dicts/geodict")
val geomap = geodf.rdd.map(row => {
val geohash: String = row.getAs[String]("geohash")
val province: String = row.getAs[String]("province")
val city: String = row.getAs[String]("city")
val region: String = row.getAs[String]("region")
(geohash, (province, city, region))
}).collectAsMap()
val bc1 = spark.sparkContext.broadcast(geomap)
// 2.ip2region.db字典
/*
// 添加缓存文件
spark.sparkContext.addFile("/dicts/ip2region/ip2region.db")
// 在算子中使用缓存文件
geodf.rdd.map(row=>{
val path = SparkFiles.get("ip2region.db")
new DbSearcher(new DbConfig(),path)
})
*/
// 自己读文件,存入一个字节数组,并广播
val fs = FileSystem.get(new Configuration())
val path = new Path("/dicts/ip2region/ip2region.db")
// 获取文件的长度(字节数)
val statuses: Array[FileStatus] = fs.listStatus(path)
val len = statuses(0).getLen
// 将字典文件,以字节形式读取并缓存到一个字节buffer中
val in: FSDataInputStream = fs.open(path)
val buffer = new Array[Byte](len.toInt)
in.readFully(0, buffer)
val bc2 = spark.sparkContext.broadcast(buffer)
// 3.设备账号关联评分字典
// val relation = spark.read.table("dwd.device_account_relation").where("dt='2021-01-10'")
//d01,c01,1000
//d01,c02,800
// 上面的数据,需要加工成: d01,c01 加工逻辑:求分组top1
val relation = spark.sql(
s"""
|
|select
| deviceid,
| account
| from
| (
| select
| deviceid,
| account,
| row_number() over(partition by deviceid order by score desc,last_time desc) as rn
| from dwd.device_account_relation
| where dt='${DT_CUR}'
| ) o
|where rn=1
|
|""".stripMargin)
val relationMap = relation.rdd.map(row => {
val deviceid = row.getAs[String]("deviceid")
val account = row.getAs[String]("account")
(deviceid, account)
}).collectAsMap()
val bc3 = spark.sparkContext.broadcast(relationMap)
// 3.历史设备、账号标识(用户判断新老访客)
val ids = spark.read.table("dwd.device_account_relation")
.where(s"dt='${DT_PRE}' ")
.selectExpr("explode (array(deviceid,account)) as id")
.map(row=>row.getAs[String]("id")).collect().toSet
val bc4 = spark.sparkContext.broadcast(ids)
/**
* 加载T日的ODS日志表数据
*/
val ods = spark.read.table("ods.event_app_log").where(s"dt='${DT_CUR}'")
val beanRdd = ods.rdd.map(row => {
Row2AppLogBean.row2AppLogBean(row)
})
/**
* 根据规则清洗过滤
*/
val filtered: RDD[AppLogBean] = beanRdd.filter(bean => {
var flag = true
// deviceid/properties/eventid/sessionid
if (!StringUtils.isNotBlank(bean.deviceid) && bean.properties != null && StringUtils.isNotBlank(bean.eventid) && StringUtils.isNotBlank(bean.sessionid)) flag = false
// 判断数据的时间是否正确
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val validStart = sdf.parse(s"${DT_CUR}").getTime
val validEnd = sdf.parse(s"${DT_NEXT}").getTime
if (bean.timestamp < validStart || bean.timestamp >= validEnd) flag = false
flag
})
/**
* session分割,添加新的newsessionid字段
*/
val sessionSplitted: RDD[AppLogBean] = filtered.groupBy(bean => bean.sessionid).flatMapValues(iter => {
val sortedEvents = iter.toList.sortBy(bean => bean.timestamp)
var tmpSessionId = UUID.randomUUID().toString
for (i <- 0 until sortedEvents.size) {
sortedEvents(i).newsessionid = tmpSessionId
if (i < sortedEvents.size - 1 && sortedEvents(i + 1).timestamp - sortedEvents(i).timestamp > 30 * 60 * 1000) tmpSessionId = UUID.randomUUID().toString
}
sortedEvents
}).map(_._2)
//sessionSplitted.toDF.show(100,false)
// 验证切割效果
/*sessionSplitted.toDF.createTempView("tmp")
spark.sql(
"""
|
|select
|sessionid,count(distinct newsessionid) as cnt
|from tmp
|group by sessionid
|having count(distinct newsessionid) >1
|
|""".stripMargin).show(100,false)*/
/**
* 集成数据(地理位置)
*/
val aread: RDD[AppLogBean] = sessionSplitted.mapPartitions(iter => {
val geoDict: collection.Map[String, (String, String, String)] = bc1.value
val ip2RegionDb: Array[Byte] = bc2.value
val searcher = new DbSearcher(new DbConfig(), ip2RegionDb)
iter.map(bean => {
// 定义临时记录变量
var country: String = "UNKNOWN"
var province: String = "UNKNOWN"
var city: String = "UNKNOWN"
var region: String = "UNKNOWN"
// 查询GEO字典获取省市区信息
try {
val lat = bean.latitude
val lng = bean.longitude
val geo = GeoHash.geoHashStringWithCharacterPrecision(lat, lng, 5)
val area = geoDict.getOrElse(geo, ("UNKNOWN", "UNKNOWN", "UNKNOWN"))
country = "CN"
province = area._1
city = area._2
region = area._3
} catch {
case e: Exception => e.printStackTrace()
}
// 如果在geo字典中查询失败,则用ip地址再查询一次
if ("UNKNOWN".equals(province)) {
val block = searcher.memorySearch(bean.ip)
// 中国|0|上海|上海市|电信
try {
val split = block.getRegion.split("\\|")
country = split(0)
province = split(2)
city = split(3)
} catch {
case e: Exception => e.printStackTrace()
}
}
bean.country = country
bean.province = province
bean.city = city
bean.region = region
bean
})
})
/**
* guid绑定生成,新老访客标记
*/
val guided: RDD[AppLogBean] = aread.mapPartitions(iter => {
val deviceBindAccountDict = bc3.value
// guid绑定
iter.map(bean => {
var guid: String = null
// 如果该条数据中,有登录账号,则直接用该登录账号作为这条数据的全局用户标识
if (StringUtils.isNotBlank(bean.account)) {
guid = bean.account
}
// 如果该条数据中,没有登录账号,则用设备id去关联账号表中查找默认的账号,作为guid
else {
val findedAccount = deviceBindAccountDict.getOrElse(bean.deviceid, null)
// 如果查询到的结果为不为null,则用查询到的account作为guid,否则用deviceid作为guid
if(findedAccount != null) guid = findedAccount else guid=bean.deviceid
}
bean.guid = guid
bean
})
})
/**
* 新老访客
*/
val result = guided.mapPartitions(iter=>{
val idSet = bc4.value
iter.map(bean=>{
var isnew = "1"
if(idSet.contains(bean.deviceid) || idSet.contains(bean.account)) isnew = "0"
bean.isnew = isnew
bean
})
}).toDF()
/**
* 保存结果到目标表
*/
result.createTempView("result")
spark.sql(
"""
|
|insert into table dwd.event_app_detail partition(dt='2021-01-10')
|select
|account ,
|appid ,
|appversion ,
|carrier ,
|deviceid ,
|devicetype ,
|eventid ,
|ip ,
|latitude ,
|longitude ,
|nettype ,
|osname ,
|osversion ,
|properties ,
|releasechannel ,
|resolution ,
|sessionid ,
|timestamp ,
|newsessionid ,
|country ,
|province ,
|city ,
|region ,
|guid ,
|isnew
|
|from result
|
|""".stripMargin)
spark.close()
}
}