【论文解读】one-stage系列里程碑 | 目标检测real time改进篇 | YOLO V3详解
目录
- 1.简介
-
- 前言
- 链接汇总
- 2.主干网络
-
- 2.1 总体网络
- 2.2 bounding box预测
- 2.3 class prediction
- 2.4 3 different scales
- 3.实验数据
-
- 3.1 数据环比
- 4. 未竟之业
- 5. Reference
1.简介
前言
yolo系列是由Joseph Redmon为主导,跟他导师Ali合作的最后一个作品(2018年),也是当时目标检测一阶段的SOTA,做到了实时性和准确性的兼顾,可谓是火爆全球。但是因为其本人的政治(白左,所谓“反战“)和个人倾向原因(一夜暴富?!),这个喜好“粉红系pony”的作者直接退圈了。。。。最后的论文也是写的马马虎虎,没有点学术严格性,我感觉是这个系列写的最烂的一篇。。。。anyway,还是得旁征博引的解读一下,毕竟文章写的不行,但是代码还是可以。
darknet系列官方是使用C + CUDA完成,支持CPU和GPU运行,训练和运行的速度还是非常快的。
链接汇总
- 官方地址(可用于下载.weight等):https://pjreddie.com/darknet/yolo/
- github官方地址:https://github.com/pjreddie/darknet/tree/yolov3
- keras版本:https://github.com/qqwweee/keras-yolo3
- pytorch版本:https://github.com/ultralytics/yolov3
2.主干网络
2.1 总体网络
为了方便查看整体结构,此处引用别人的一些图例说明:
- 图例1
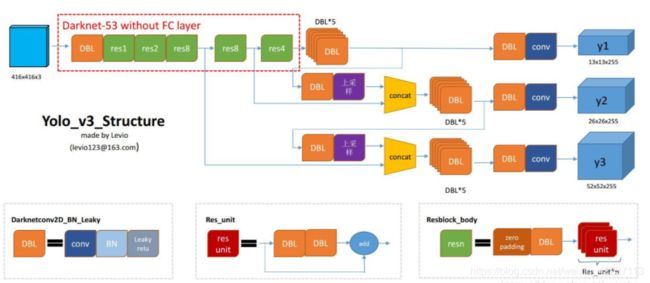
- 图例2:

说明:
1. 整体网络主要组成部分:
input: 320x320/ 416x416/ 608x608,支持3种模式的图片尺寸;
backbone: Dacknet53网络,主要进行feature extractor,提取高纬度图像特征;
neck: FPN结构,图像融合;
head: dense prediction,并且预测3种不同尺度的目标检测结果;
2.主干网络darknet53的详细结构:

2.2 bounding box预测

(1)网络预测输出:
tx -> x轴预测偏移量
ty -> y轴预测偏移量
tw -> 图片尺寸w预测偏移量
th -> 图片尺寸h预测偏移量
注意:
a.(tx,ty,tw,th)都是网络最后的输出值.但是这个并不是真实的预测的输出值,需要经过公式矫正和处理。最终的输出是(bx,by,bw,bh)。相关的公式如下所示:

b.公式说明:
(cx,cy) -> 中心点所处于的网格点的左上角的坐标
(pw,ph) -> 先验框原始长宽
σ -> sigmoid函数
(2) 真正的预测实际输出值,即bx, by, bw, bh,如上面所示:
bx -> bbox 中心点x轴预测值
by ->bbox 中心点y轴预测值
bw -> bbox 长w预测值
bh -> bbox 宽h预测值
(3)先验框的选择
只有先验框和ground truth的iou占比>iou阈值,并且阈值最大的一个才可以是先验框,这个一个ground truth是只有一个先验框,其他的先验框都no loss,即不做考虑。这个跟faster rcnn使用多个先验框不一样。
使用k-mean通过聚类的方法,找到不同尺度的3个不同尺寸的3个聚类中心的尺寸共9个。COCO的先验框尺寸是:
On the COCO dataset the 9 clusters were:
(10×13); (16×30); (33×23); (30×61); (62×45); (59×
119); (116 × 90); (156 × 198); (373 × 326)

416x416尺寸的大致示意图如下所示:



通过特定的、固定anchor的尺寸,可以得到3个不同尺寸的不同prior bounding box(先验框),从而可以通过2.2公式校准。
具体代码可以参见refenrence3
2.3 class prediction
并没有使用softmax做分类的score计算,因为类别存在多标签(例如女人,人),使用softmax默认前提是每个bounding box只属于一个分类的而现实并非如此.本初训练的时候使用二分类交叉熵,支持单目标的多标签情况。
2.4 3 different scales
预测的输出可以从2.1中的总体结构图中看出,网络结构每次是有3个不同尺寸的输出的,每个输出的结构包含 bounding box, objectness, and class predictions。
所以,对于COCO数据集(80分类),so the tensor is N × N × [3 ∗ (4 + 1 + 80)]。
注:
3个不同尺度的box
4个bounding box坐标
1个obj score值
80个分类
3.实验数据
3.1 数据环比

mAP

[email protected], 即AP50
具体数据如下表所示:

结果分析:
mAP相比于YOLOV2的时候提高了很多。现在的AP和SSD的水平相差不多,但是速度确实快乐2-3倍,并且在AP50的时候,和SOTA(即是RetinaNet)基本相差不多了,但是RetinaNet的检测速度要慢3.8倍。所以应该是在当时速度最快的、效果很好的检测模型。
另外,由于增加了多尺度、FPN的结构,YOLOV3在小物体的检测上有了较大提高(对比yolov2和yolov3的APs),但是跟SOTA的模型相比,对于大物体检测相比,还是存在较大差距(对比AP L数据可知)。
4. 未竟之业
Anchor box x, y offset predictions:如果使用平常的anchor box机制去预测x,y偏移量,即让x,y作为预测box的长、宽的线性函数。这样的结果并不稳定,效果不佳。
Linear x; y predictions instead of logistic:使用一个线性函数替代sigmoid函数,这样会让mAP下降几个点。
Focal loss:使用focal loss还会让mAP下降2个点。
Dual IOU thresholds and truth assignment:Faster RCNN使用2个IOU阈值在训练的时候:
即 >.7 正样本;
[.3, .7] 忽略;
<.3 负样本
尝试了类似的策略,效果并不好。
等等
5. Reference
1 yolo系列之yolo v3【深度解析】
2 睿智的目标检测11——Keras搭建yolo3目标检测平台
3 yolov3 先验框讲解与代码实现
4 YOLOv3目标检测原理