Conditional probability
The fundamental idea behind all Bayesian statistics is Bayes’s theorem, which is surprisingly easy to derive, provided that you understand conditional probability. So we’ll start with probability, then conditional probability, then Bayes’s theorem, and on to Bayesian statistics.
我们先从概率开始,然后到条件概率,然后是贝叶斯理论,再到贝叶斯分析。
A probability is a number between 0 and 1 (including both) that represents a degree of belief in a fact or prediction. The value 1 represents certainty that a fact is true, or that a prediction will come true. The value 0 represents certainty that the fact is false.
概率是一个位于包含0和1以及0,1之间的一个数,它代表这一个事实或者一个预测的可信度。
Intermediate values represent degrees of certainty. The value 0.5, often written as 50%, means that a predicted outcome is as likely to happen as not. For example, the probability that a tossed coin lands face up is very close to 50%.
A conditional probability is a probability based on some background information. For example, I want to know the probability that I will have a heart attack in the next year. According to the CDC, “Every year about 785,000 Americans have a first coronary attack (http://www.cdc.gov/heartdisease/facts.htm).”
一个条件概率是基于一些背景信息的可能性。下面开始使用一个例子了,每年大概有785000美国人犯心脏病。
The U.S. population is about 311 million, so the probability that a randomly chosen American will have a heart attack in the next year is roughly 0.3%.
美国人口大约在311百万 大概是3亿多。所以随意取一个美国人患心脏病的概率实在0.3% 也就是千分之三。
But I am not a randomly chosen American. Epidemiologists have identified many factors that affect the risk of heart attacks; depending on those factors, my risk might be higher or lower than average.
但是“我”不是一个随机选择的人。疾病学家认为有许多因素可以影响心脏病的风险。根据这些因素,“我”患心脏的可能性可能高于平均水平也可能低于平均水平。
I am male, 45 years old, and I have borderline high cholesterol. Those factors increase my chances. However, I have low blood pressure and I don’t smoke, and those factors decrease my chances.
“我”是一个男性,45岁,我有高固醇。这些因素增加了我患心脏病的概率。但是,我有低血压,我不抽烟,这些因素又会降低我的患病概率。
Plugging everything into the online calculator at http://hp2010.nhlbihin.net/atpiii/calculator.asp, I find that my risk of a heart attack in the next year is about 0.2%, less than the national average. That value is a conditional probability, because it is based on a number of factors that make up my “condition.”
把这些因素输入到测试网站上,的出来“我”下一年的患病几率大概在千分之2,这是低于国家平均水平的。这个值是一个条件概率,因为这是基于一些决定我状况的因素。
The usual notation for conditional probability is p(A|B), which is the probability of A given that B is true. In this example, A represents the prediction that I will have a heart attack in the next year, and B is the set of conditions I listed.
常见的条件概率的符号表达式就是 p(A|B)。这是假设B是真的情况下,A事件发生的概率。在上面的例子中,A代表着“我”下一年患心脏病的概率,B是我列举的一系列的条件。
Conjoint probability
Conjoint probability is a fancy way to say the probability that two things are true. I write p(A and B) to mean the probability that A and B are both true.
联合概率是一个很好的方式去表达两个事情为真的概率。用
p(A and B)来表达A事件和B事件都为真。
If you learned about probability in the context of coin tosses and dice, you might have learned the following formula:
p (A and B) =p (A) p (B) WARNING: not always true
如果你学过硬币正反面的概率的话,你就学学习到下面的式子。
For example, if I toss two coins, and A means the first coin lands face up, and B means the second coin lands face up, then p(A) =p(B) =0.5, and sure enough, p (A and B) =p(A) p(B) =0.25.
举个栗子来说,如果我抛两枚硬币,A事件代表着第一个硬币着地的时候是正面朝上,B事件代表着第二个硬币着地正面朝下,然后A事件和B事件的概率都是0.5,所以A事件和B事件都是真的概率为0.25.
But this formula only works because in this case A and B are independent; that is, knowing the outcome of the first event does not change the probability of the second. Or, more formally, p (B|A) = p(B).
但是上面的式子只是在事件A和B都独立的时候才有效。也就是说A事件的结果不会改变B事件的概率,或者更加正式得,p(B|A) = p(B)。从这个式子的字面意思我们也可以看出来就是A事件发生的概率下B事件发生的概率还是B事件独立发生的概率,也就是A事件啥情况和B事件没什么关系。
Here is a different example where the events are not independent. Suppose that A means that it rains today and B means that it rains tomorrow. If I know that it rained today, it is more likely that it will rain tomorrow, so p (B|A) > p (B).
这里有一个不同的事件不是独立的例子。假设A事件代表今天下雨了,B事件代表着明天下雨。如果我知道今天下雨了,那么明天下雨的概率就要高一些所以也就有p (B|A) > p (B).
In general, the probability of a conjunction is
p (A and B) = p (A) p (B|A)
for any A and B. So if the chance of rain on any given day is 0.5, the chance of rain on two consecutive days is not 0.25, but probably a bit higher.
上面的式子适用于任意的A事件和B事件。所以如果给定的任何一天下雨的概率是0.5,那么连续两天下雨的概率不是0.25,而是更高一点。
The cookie problem
从字面我也不知道这是个什么问题。
We’ll get to Bayes’s theorem soon, but I want to motivate it with an example called the cookie problem. Suppose there are two bowls of cookies. Bowl 1 contains 30 vanilla cookies and 10 chocolate cookies. Bowl 2 contains 20 of each.
一个饼干问题。假定这里有两碗饼干,碗1里面有有30个香草的和10个巧克力的,而碗2里面各有20个香草的和巧克力的。
Now suppose you choose one of the bowls at random and, without looking, select a cookie at random. The cookie is vanilla. What is the probability that it came from Bowl 1?
那么现在假设你随机选一个碗,从这个碗里选一个饼干。这个饼干是香草的,那么这个饼干来自于碗1的概率是多少?
This is a conditional probability; we want p (Bowl 1|vanilla) , but it is not obvious how to compute it. If I asked a different question—the probability of a vanilla cookie given Bowl 1—it would be easy:
p (vanilla|Bowl 1) =3 / 4
这是一个条件概率的问题。我们想要的是p (Bowl 1|vanilla),但是不容易计算,如果我问一个不同的问题,假设来自碗1,一个香草饼干的概率,那么很简单我们会得出3/4。
Sadly, p (A|B) is not the same as p (B|A) , but there is a way to get from one to the other: Bayes’s theorem.
但是p (A|B)不同于p (B|A),但是我们可以用贝叶斯思维去解决这个问题。
Bayes’s theorem
At this point we have everything we need to derive Bayes’s theorem. We’ll start with the observation that conjunction is commutative; that is
p (A and B) =p (B and A)
for any events A and B.
我们从这个交换律开始。对于任意的事件A和事件B来说,A和B发生的概率与B和A发生的概率是一致的。
Next, we write the probability of a conjunction:
p (A and B) =p (A) p (B|A)
Since we have not said anything about what A and B mean, they are interchangeable. Interchanging them yields
p (B and A) =p (B) p (A|B)
因为我们没有说A和B是什么,他们是可交换的,交换他们所以产生了上面的式子。
That’s all we need. Pulling those pieces together, we get
p (B) p (A|B) =p (A) p (B|A)
我们把上面的两个式子结合在一起,然后我们就得到了这样的式子。
Which means there are two ways to compute the conjunction. If you have p (A) , you multiply by the conditional probability p (B|A) . Or you can do it the other way around; if you know p (B) , you multiply by p (A|B) . Either way you should get the same thing.
上面的两种的方法我们可以得到相同的结果。
Finally we can divide through by p (B) :
p (A|B) = p (A) p (B|A) / p (B)
And that’s Bayes’s theorem! It might not look like much, but it turns out to be surprisingly powerful.
这就是powerful的贝叶斯定理。
For example, we can use it to solve the cookie problem. I’ll write B1 for the hypothesis that the cookie came from Bowl1 and V for the vanilla cookie. Plugging in Bayes’s theorem we get
p (B1|V) = p (B1) p (V|B1) / p (V)
举个栗子,我们可以用这个去解决饼干问题。我们用B1来代表假说——饼干来自于碗1,V代表香草饼干。代入贝叶斯定理得到上式。
The term on the left is what we want: the probability of Bowl 1, given that we chose a vanilla cookie. The terms on the right are:
- p (B1) : This is the probability that we chose Bowl 1, unconditioned by what kind of cookie we got. Since the problem says we chose a bowl at random, we can assume
p (B1) =1 / 2. - p (V|B1) : This is the probability of getting a vanilla cookie from Bowl 1, which is 3/4.
- p (V) : This is the probability of drawing a vanilla cookie from either bowl. Since we had an equal chance of choosing either bowl and the bowls contain the same number of cookies, we had the same chance of choosing any cookie. Between the two bowls there are 50 vanilla and 30 chocolate cookies, so p (V) = 5/8.
选择B1碗的概率就是1/2,p (V|B1)就是事件B1下的V事件概率也就是 3/4(一共40个饼干,30个香草饼干),V事件的概率就是碗1里的香草概率加上碗2里香草的概率,也可以按照原文中作者的意思,就是选择任何一个碗都是没区别的。一共80个饼干,50个是香草的,所以选到香草的概率就是 5/8。
Putting it together, we have
p (B1|V) = (1 / 2) (3 / 4) = (5 / 8)
which reduces to 3/5. So the vanilla cookie is evidence in favor of the hypothesis that we chose Bowl 1, because vanilla cookies are more likely to come from Bowl 1.
所以香草饼干支持了我们的假说——我们选择了碗1,因为香草饼干更有可能来自于碗1。
This example demonstrates one use of Bayes’s theorem: it provides a strategy to get from p (B|A) to p (A|B) . This strategy is useful in cases, like the cookie problem, where it is easier to compute the terms on the right side of Bayes’s theorem than the term on the left.
我们采用了一个策略,将p (B|A)转换到p (A|B)。在一些案子中很有用的,当贝叶斯定理的右侧比左边更好计算的情况下。
The diachronic interpretation
历时解释???
There is another way to think of Bayes’s theorem: it gives us a way to update the probability of a hypothesis, H, in light of some body of data, D.
这里还有另外一种方式思考贝叶斯定理:它给了我们一种方法去在一些数据的帮助下更新假说的可能性。
This way of thinking about Bayes’s theorem is called the diachronic interpretation. “Diachronic” means that something is happening over time; in this case the probability of the hypotheses changes, over time, as we see new data.
这种思考贝叶斯原理的方法被称为历时解释。历时的意思是经过一段时间,一些事情改变了。在这个例子中,随着我们看到新的数据,假说的可能性也发生了改变。
Rewriting Bayes’s theorem with H and D yields:
p (H|D) = p (H) p (D|H) / p (D)
In this interpretation, each term has a name:
- p (H) is the probability of the hypothesis before we see the data, called the prior probability, or just prior.
- p (H|D) is what we want to compute, the probability of the hypothesis after we see the data, called the posterior.
- p (D|H) is the probability of the data under the hypothesis, called the likelihood.
• p (D) is the probability of the data under any hypothesis, called the normalizing constant.
p (H)是我们看到数据之前的假说的概率,被称为先验概率。
p (H|D)是我们想去计算的,在我们看到新的数据后的假说的概率,我们称之为后验概率。。。或者就叫修正概率。
p (D|H)是假说下数据的概率,称之为可能性。
p (D)是任意假说下数据的可能性,称之为一般常量。
Sometimes we can compute the prior based on background information. For example, the cookie problem specifies that we choose a bowl at random with equal probability.
有时,我们可以计算基于背景信息的先验概率,举个栗子,饼干问题指出我们以相同的可能性选择任意一个碗。
In other cases the prior is subjective; that is, reasonable people might disagree, either because they use different background information or because they interpret the same information differently.
在有的情况下,先验概率是主观的。也就是,客观的人可能不同意,或者因为他们选取不同的背景信息,或者是因为他们以不同的方式去解释同一个信息。
The likelihood is usually the easiest part to compute. In the cookie problem, if we know which bowl the cookie came from, we find the probability of a vanilla cookie by counting.
可能性一般是最容易去计算的部分。在饼干问题中,如果我们知道了选的是哪个碗,我们可以计算到香草饼干的可能性。
The normalizing constant can be tricky. It is supposed to be the probability of seeing the data under any hypothesis at all, but in the most general case it is hard to nail down what that means.
一般常量比较难以处理。它可以是在任意假说下的数据可能性,但是在大部分的例子中,这是最难的部分。
Most often we simplify things by specifying a set of hypotheses that are
Mutually exclusive: At most one hypothesis in the set can be true, and
Collectively exhaustive:There are no other possibilities; at least one of the hypotheses has to be true.
通常我们通过指定一组假设来简化事情
互斥:集合中至多有一个假设是真的,并且
总体上来说是详尽的:没有其他可能性;至少有一个假设是正确的。
上面不算很理解,往下看例子吧。
I use the word suite for a set of hypotheses that has these properties.
In the cookie problem, there are only two hypotheses—the cookie came from Bowl 1 or Bowl 2—and they are mutually exclusive and collectively exhaustive.
互斥 对立事件 —— 饼干来自于碗1或者碗2
In that case we can compute p (D) using the law of total probability, which says that if there are two exclusive ways that something might happen, you can add up the probabilities like this:
p (D) =p (B1) p (D|B1) +p (B2) p (D|B2)
在那个例子中我们可以用全概率定律计算D的概率,也就是说如果这有两个事情可能发生的互斥的方式,我们可以像这样加概率。这里就明白了,选择碗1和碗2是一个对立互斥事件,也就是选择了碗1就不能选择碗2,但是我们需要的是选择香草饼干的概率。那么就是在选了碗1的情况下,我们选到香草饼干的概率加上选到碗2的情况下,我们选到香草饼干的概率。
Plugging in the values from the cookie problem, we have
p (D) = (1 / 2) (3 / 4) + (1 / 2) (1 / 2) =5 / 8
which is what we computed earlier by mentally combining the two bowls.
The M&M problem
M&M’s are small candy-coated chocolates that come in a variety of colors. Mars, Inc., which makes M&M’s, changes the mixture of colors from time to time.
不算理解这是什么问题。
In 1995, they introduced blue M&M’s. Before then, the color mix in a bag of plain M&M’s was 30% Brown, 20% Yellow, 20% Red, 10% Green, 10% Orange, 10% Tan. Afterward it was 24% Blue , 20% Green, 16% Orange, 14% Yellow, 13% Red, 13% Brown.
那大概就是巧克力产品里面前后的巧克力的颜色比例的变化
Suppose a friend of mine has two bags of M&M’s, and he tells me that one is from 1994 and one from 1996. He won’t tell me which is which, but he gives me one M&M from each bag. One is yellow and one is green. What is the probability that the yellow one came from the 1994 bag?
所以问题就是有一个人买了一袋94年的糖果袋和一袋96年的,我们怎么区分的问题。从每个糖果袋里面拿出来一个巧克力糖,一个是黄色,一个是绿色的,那么黄色的来自94年包的可能性有多大。
This problem is similar to the cookie problem, with the twist that I draw one sample from each bowl/bag. This problem also gives me a chance to demonstrate the table method, which is useful for solving problems like this on paper. In the next chapter we will solve them computationally.
The first step is to enumerate the hypotheses. The bag the yellow M&M came from I’ll call Bag 1; I’ll call the other Bag 2. So the hypotheses are:
- A: Bag 1 is from 1994, which implies that Bag 2 is from 1996.
- B: Bag 1 is from 1996 and Bag 2 from 1994.
第一步是把可能性都枚举出来。从后面的结果看,其实这一步还是挺重要的,因为结论不能单独而存在,只是考虑黄色的而不考虑绿色的回事不同的情况。
所以我们的假说是 袋子1是94年的,那么袋子2就是96年的,或者袋子1是96的,袋子2是94的。
Now we construct a table with a row for each hypothesis and a column for each term in Bayes’s theorem:
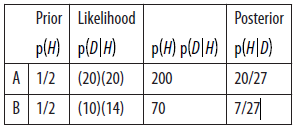
The first column has the priors. Based on the statement of the problem, it is reasonable to choose p (A) =p (B) =1 / 2.
The second column has the likelihoods, which follow from the information in the problem. For example, if A is true, the yellow M&M came from the 1994 bag with probability 20%, and the green came from the 1996 bag with probability 20%. Because the selections are independent, we get the conjoint probability by multiplying.
因为选择是独立的,所以我们可以用相乘得到联合概率。
The third column is just the product of the previous two. The sum of this column, 270, is the normalizing constant. To get the last column, which contains the posteriors, we divide the third column by the normalizing constant.
第三格的和就是一般常量。
That’s it. Simple, right?
Well, you might be bothered by one detail. I write p (D|H) in terms of percentages, not probabilities, which means it is off by a factor of 10,000. But that cancels out when we divide through by the normalizing constant, so it doesn’t affect the result.
作者在式子上就是对百分比这个集体成了100,对结果没有影响。
When the set of hypotheses is mutually exclusive and collectively exhaustive, you can multiply the likelihoods by any factor, if it is convenient, as long as you apply the same factor to the entire column.
The Monty Hall problem
The Monty Hall problem might be the most contentious question in the history of probability. The scenario is simple, but the correct answer is so counterintuitive that many people just can’t accept it, and many smart people have embarrassed themselves not just by getting it wrong but by arguing the wrong side, aggressively, in public.
这是一个游戏节目的问题。
Monty Hall was the original host of the game show Let’s Make a Deal. The Monty Hall problem is based on one of the regular games on the show. If you are on the show, here’s what happens:
- Monty shows you three closed doors and tells you that there is a prize behind each door: one prize is a car, the other two are less valuable prizes like peanut butter and fake finger nails. The prizes are arranged at random.
- The object of the game is to guess which door has the car. If you guess right, you get to keep the car.
- You pick a door, which we will call Door A. We’ll call the other doors B and C.
- Before opening the door you chose, Monty increases the suspense by opening either Door B or C, whichever does not have the car. (If the car is actually behind Door A, Monty can safely open B or C, so he chooses one at random.)
- Then Monty offers you the option to stick with your original choice or switch to the one remaining unopened door.
这个游戏就是猜门后面有没有车,如果猜对了,那么就可以把车开走。再打开你选择的门之前,主持人会打开门B或者门C,那个没有车的那个门,如果车在A门后,那么主持人可以很放心的打开门B和门C的任意一个。所以他就随便选一个。然后主持人就给你一个选择的机会,去坚持你原来的选择或者换到另外一个没有打开的门。
The question is, should you “stick” or “switch” or does it make no difference?
问题就是坚持或者改变会有什么不同吗?
Most people have the strong intuition that it makes no difference. There are two doors left, they reason, so the chance that the car is behind Door A is 50%.
很多人认为这中间并没区别。只剩下两扇门,所以任意一个门的几率是50%。
But that is wrong. In fact, the chance of winning if you stick with Door A is only 1/3; if you switch, your chances are 2/3.
但是这是错误的。事实上,坚持获胜的概率是1/3,而改变获胜的概率是2/3。
By applying Bayes’s theorem, we can break this problem into simple pieces, and maybe convince ourselves that the correct answer is, in fact, correct.
运用贝叶斯定理,我们可以将问题拆分到简单的模块,并且说服我们正确答案事实上是正确的。
To start, we should make a careful statement of the data. In this case D consists of two parts: Monty chooses Door B and there is no car there.
首先,我们必须明确一个数据声明。在这个例子中,数据由两部分组成,主持人选择了门B,并且后面没有车。
Next we define three hypotheses: A, B, and C represent the hypothesis that the car is behind Door A, Door B, or Door C. Again, let’s apply the table method:
接下来我们定义三个假说,A B C代表这个车在A门,B门,C门门后。下面开始制表:

Filling in the priors is easy because we are told that the prizes are arranged at random, which suggests that the car is equally likely to be behind any door.
先验概率因为是随机的,所以就是每个门的几率都是1/3.
Figuring out the likelihoods takes some thought, but with reasonable care we can be confident that we have it right:
- If the car is actually behind A, Monty could safely open Doors B or C. So the probability that he chooses B is 1/2. And since the car is actually behind A, the probability that the car is not behind B is 1.
- If the car is actually behind B, Monty has to open door C, so the probability that he opens door B is 0.
- Finally, if the car is behind Door C, Monty opens B with probability 1 and finds no car there with probability 1.
其实上面的描述过程就是:首先我们还是要明确各项的含义。prior是先验项,也就是在新的信息发生之前,假说的概率。likelihood其实就是对应假说成立的情况下D发生的概率。比如对于A的可能性就是,如果真的A后有车,那么B和C门后就没有车,从而新信息B门打开且没有车的概率就是1/2,因为可以选择B或者C。对于B的likelihood就是不可能,因为B门后有车的情况下,主持人不会打开B门。C的likelihood的话,如果C后有车,观众选择的是A,主持人打开B门的概率就是100%了。其实主要就是理解这一项的含义就是“在假说对应的N门后有车的情况下,主持人打开B的概率”。
Now the hard part is over; the rest is just arithmetic. The sum of the third column is 1/2. Dividing through yields p (A| D) =1 / 3 and p (C|D) =2 / 3. So you are better off switching.
从结果看,我们最好换一下。
There are many variations of the Monty Hall problem. One of the strengths of the Bayesian approach is that it generalizes to handle these variations.
汽车门问题有很多变种。
For example, suppose that Monty always chooses B if he can, and only chooses C if he has to (because the car is behind B). In that case the revised table is:
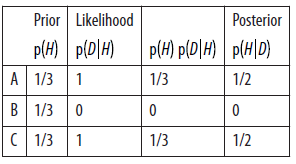
The only change is p (D|A) . If the car is behind A, Monty can choose to open B or C. But in this variation he always chooses B, so p (D|A) =1.
唯一的不同就在于p (D|A),也就是车在A门后面,主持人打开B门的概率,因为主持人不会打开C门,所以此时的概率不是1/2而是1。
As a result, the likelihoods are the same for A and C, and the posteriors are the same: p (A|D) =p (C|D) =1 / 2. In this case, the fact that Monty chose B reveals no information about the location of the car, so it doesn’t matter whether the contestant sticks or switches.
这句话其实表达的很好就是主持人选择B门并没有带来更多的信息。带有信息的选择才有可能昭示事情的实际概率。
On the other hand, if he had opened C, we would know
p (B|D) =1.
但是从另外一方面,如果他打开了C那么我们就知道车在B门后面了。
I included the Monty Hall problem in this chapter because I think it is fun, and because Bayes’s theorem makes the complexity of the problem a little more manageable. But it
is not a typical use of Bayes’s theorem, so if you found it confusing, don’t worry!
Discussion
For many problems involving conditional probability, Bayes’s theorem provides a divide-and-conquer strategy. If p (A|B) is hard to compute, or hard to measure experimentally, check whether it might be easier to compute the other terms in Bayes’s theorem,
p (B|A) , p (A) and p (B).
实际上贝叶斯思维采取的是一种分而治之的策略。
If the Monty Hall problem is your idea of fun, I have collected a number of similar problems in an article called “All your Bayes are belong to us,” which you can read at http://allendowney.blogspot.com/2011/10/all-your-bayes-are-belong-to-us.html.
作者很友好的附上了习题集。