c语言枚举类型例题_C语言笔记
IDE推荐
1、编译器仅使用GCC即可,IDE使用 VSCode、 Vim都可以。这样的好处是,能学到GCC命令行的一些用法,而不是只知道点一下按钮就运行了。
2、使用提示功能很强大的Clion、VS Studio、Xcode、Eclipse等IDE,编译的时候使用GCC命令行,尤其是初学的时候。
不建议使用已经过时的
TurboC、VisualC++6.0。
Hello World
示例程序:test.c
#include
int main(){
printf("Hello World");
return 0;
}
运行:
$ gcc main.c -o main && ./main
Hello World
1) 第1行引入 stdio库,因为 printf函数在 stdio库里。2) 第2行开始定义主函数 main。main 是程序的入口函数,一个C程序必须有 main 函数,而且只能有一个。3) 第3行调用 printf 函数向显示器输出字符串。4) 第4行是 main 函数的返回值。程序运行正确一般返回 0。
C语言规定,一个程序必须有且只有一个
main函数。main被称为主函数,是程序的入口函数,程序运行时从 main 函数开始,直到main函数结束(遇到return或者执行到函数末尾时,函数才结束)。
引入头文件使用 #include命令,并将文件名放在 < >中, #include 和 < > 之间可以有空格,也可以没有。库的名称也可以是 " "号,表示默认先从当前代码所在的文件夹找,找不到再到系统文件夹找。
较早的C语言标准库包含了15个头文件, stdio.h 和 stdlib.h 是最常用的两个:
stdio是standard input ouput的缩写,stdio.h被称为“标准输入输出文件”,包含的函数大都和输入输出有关,puts()就是其中之一。stdlib是standard library的缩写,stdlib.h被称为“标准库文件”,包含的函数比较杂乱,多是一些通用工具型函数,system()就是其中之一。
如果我们没有调用任何函数,所以不必引入头文件:
int main()
{
return 0;
}
GCC编译C
Linux下使用最广泛的C/C++编译器是GCC,大多数的Linux发行版本都默认安装,不管是开发人员还是初学者,一般都将GCC作为Linux下首选的编译工具。
输入下面的命令:
gcc test.c -o test
可以直接将C代码编译链接为可执行文件。
可以看到在当前目录下多出一个文件 test,这就是可执行文件。不像Windows,Linux不以文件后缀来区分可执行文件,Linux下的可执行文件后缀理论上是可以任意更改的。然后运行可执行文件:
./test
当然,也可以分步编译:
1) 预处理
gcc -E test.c -o test.i
在当前目录下会多出一个预处理结果文件 test.i,打开 test.i 可以看到,在 test.c 的基础上把stdio.h和stdlib.h的内容插进去了。
2) 编译为汇编代码
gcc -S test.i -o test.s
其中 -S参数是在编译完成后退出, -o为指定文件名。
3) 汇编为目标文件
gcc -c test.s -o test.o
.o就是目标文件。目标文件与可执行文件类似,都是机器能够识别的可执行代码,但是由于还没有链接,结构会稍有不同。
3) 链接并生成可执行文件
gcc test.o -o test
如果有多个源文件,可以这样来编译:
gcc -c test1.c -o test1.o
gcc -c test2.c -o test2.o
gcc test1.o test2.o -o test
注意:如果不指定文件名,GCC会生成名为a.out的文件,.out文件只是为了区分编译后的文件,Linux下并没有标准的可执行文件后缀名,一般可执行文件都没有后缀名。
编译后生成的test文件就是程序了,运行它:
./test
如果没有运行权限,可以使用sudo命令来增加权限(注意要在Linux的分区下):
sudo cdmod test 777
对于程序的检错,我们可以用 -pedantic、 -Wall、 -Werror选项:
-pedantic选项能够帮助程序员发现一些不符合 ANSI/ISO C标准的代码(并不是全部);-Wall可以让gcc显示警告信息;-Werror可以让gcc在编译中遇到错误时停止继续。
这3个选项都是非常有用的。
语法基础
字符串转义
看下面程序:
#include
int main(){
puts("C\tC++\tJava\nC first appeared!\a");
return 0;
}
运行结果:
C C++ Java
C first appeared!
同时会听到喇叭发出“嘟”的声音,这是使用 \a的效果。
转义字符表:
转义字符 意义 ASCII码值(十进制)
\a 响铃(BEL) 007
\b 退格(BS) ,将当前位置移到前一列 008
\f 换页(FF),将当前位置移到下页开头 012
\n 换行(LF) ,将当前位置移到下一行开头 010
\r 回车(CR) ,将当前位置移到本行开头 013
\t 水平制表(HT) (跳到下一个TAB位置) 009
\v 垂直制表(VT) 011
\\ 表示\本身
\" 表示"
负数的表示
#include
int main()
{
unsigned int a = 0x100000000;
int b = 0xffffffff;
printf("a=%u, b=%d\n", a, b);
return 0;
}
运行结果:a=0, b=-1
这里b为什么是-1呢?
在计算机中,负数以原码的补码形式表达。
原码:一个正数,按照绝对值大小转换成的二进制数;一个负数按照绝对值大小转换成的二进制数,然后最高位补1,称为原码。
反码:正数的反码与原码相同,负数的反码为对该数的原码除符号位外各位取反。
补码:正数的补码与原码相同,负数的补码为对该数的原码除符号位外各位取反,然后在最后一位加1。
变量 a,b 均为 int 类型,占用4个字节(32位),那么 -1的原码是 10000000000000000000000000000001, 反码是 11111111111111111111111111111110, 补码是 11111111111111111111111111111111, 即16进制的 0xFFFFFFFF。所以 0xFFFFFFFF就是表示 -1。
运算符优先级
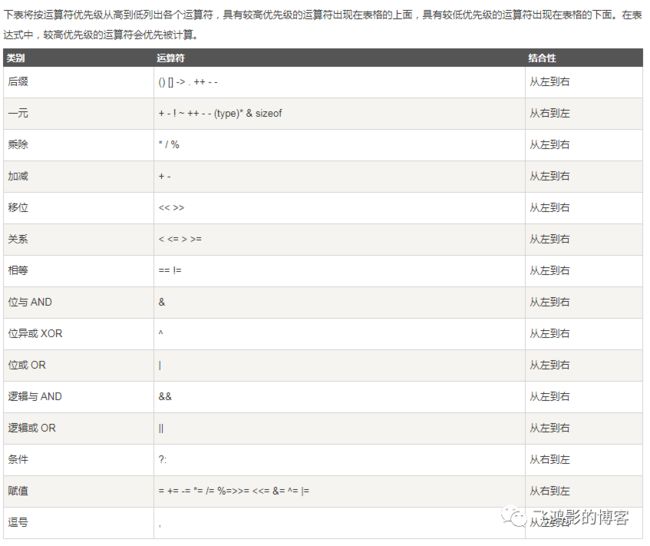
参考 c语言运算符优先级,结合性(左/右结合详解) - Colin丶 - CSDN博客 https://blog.csdn.net/hitwhylz/article/details/14526569
位运算
位运算符和移位运算符的计算主要用在二进制中。
位运算符主要包含:与(&)、或(|)、非(~)、异或(^),移位运算符主要包含左移(<>)。阅读本文,您应对二进制有了解。
位运算符

快速记忆:
与:全1为1
或:有1为1
异或:相异为1
非:取反
移位运算符
左移:相当于把一个数乘以2^n倍,即左移一次相当于乘以2。
右移:相当于把一个数除以2^n倍,即右移一次相当于除以2。
typedef
用于定义新类型。示例:
typedef unsigned int unit;
相当于给 unsignedint起了别名 uint,后面的代码直接使用 unit就可以了。
const
用于定义常量。常量一旦定义,不可修改。示例:
typedef unsigned int unit;
const unit IS_LONG = 1;
const unit IS_DOBULE = 2;
const unit IS_STRING = 3;
常量一般大写,用于和变量区分。
const 也可以和指针变量一起使用,这样可以限制指针变量本身,也可以限制指针指向的数据。示例:
const int *p1; //指针可写,但是指向的数据只读
int const *p2; //指针可写,但是指向的数据只读
int * const p3; //指针只读,但是指向的数据可写
const int * const p4; //指针和指向的数据都只可读
int const * const p5; //指针和指向的数据都只可读
大家可以这样来记忆:const 离变量名近就是用来修饰指针变量的,离变量名远就是用来修饰指针指向的数据;如果近的和远的都有,那么就同时修饰指针变量以及它指向的数据。
结构体
结构体定义示例:
struct stu{
char *name; //姓名
int num; //学号
};
定义的同时定义变量:
struct stu{
char *name; //姓名
int num; //学号
} stu1; //申明变量stu1
使用结构体定义变量:
struct stu stu1,stu2; //定义变量stu1,stu2
union
定义格式为:
union 共用体名{
成员列表
};
结构体和联合体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而联合体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),联合体占用的内存等于最长的成员占用的内存。
union data{
int n;
char ch;
double f;
};
共用体 data 中,成员 f 占用的内存最多,为 8 个字节,所以该共用体占用8字节。
联合体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
下面是一个示例,用于模拟PHP变量的实现:
#include "stdio.h"
typedef unsigned int unit;
const unit IS_LONG = 1;
const unit IS_DOBULE = 2;
const unit IS_STRING = 3;
//联合体
typedef union _zvalue {
long lval;
double dval;
struct {
char *val;
unit len;
} str;
} zvalue;
//zval
struct zval {
unit type;
zvalue value;
};
//打印zval`
void print_zval(struct zval *var) {
if (var->type == IS_STRING) {
printf("type is string, val: %s\n", var->value.str.val);
} else if (var->type == IS_LONG) {
printf("type is long, val: %ld\n", var->value.lval);
} else if (var->type == IS_DOBULE) {
printf("type is double, val: %f\n", var->value.dval);
} else {
printf("unknow type\n");
}
};
int main() {
struct zval str = { IS_STRING, .value.str = { "hello nil", 5}};
struct zval myid = { IS_LONG, .value.lval = 123};
struct zval pi = { IS_DOBULE, .value.dval = 3.14159};
print_zval(&str);
print_zval(&myid);
print_zval(&pi);
str = pi;
print_zval(&str);
return 0;
}
注意:结构体嵌套共用体可以使用
.跟着成员名进行赋值,这样和顺序无关。
使用联合体的特性,使得 zval看起来可以存储其它类型的值。使用结构体也可以实现,但是会占用更多内存。
宏定义
宏(Macro)是预处理命令的一种,它允许用一个标识符来表示一个字符串。
示例:
#define N 100
#define M (n*n+3*n)
需要注意的是,在宏定义中表达式 (n*n+3*n)两边的括号不能少,否则在宏展开以后可能会产生歧义。下面是一个反面的例子:
#difine M n*n+3*n
引用的地方:
sum = 3*M+4*M+5*M;
在宏展开后将得到下述语句:
s=3*n*n+3*n+4*n*n+3*n+5*n*n+3*n;
这显然是不正确的。所以进行宏定义时要注意,应该保证在宏替换之后不发生歧义。
对宏定义的几点说明:
宏定义是用宏名来表示一个字符串,在宏展开时又以该字符串取代宏名,这只是一种简单粗暴的替换。字符串中可以含任何字符,它可以是常数、表达式、if 语句、函数等,预处理程序对它不作任何检查,如有错误,只能在编译已被宏展开后的源程序时发现。
宏定义不是说明或语句,在行末不必加分号,如加上分号则连分号也一起替换。
宏定义必须写在函数之外,其作用域为宏定义命令起到源程序结束。如要终止其作用域可使用
#undef命令。代码中的宏名如果被引号包围,那么预处理程序不对其作宏代替,例如:
#include
#define OK 100
int main(){
printf("OK\n");
return 0;
}
宏定义允许嵌套,在宏定义的字符串中可以使用已经定义的宏名,在宏展开时由预处理程序层层代换。
习惯上宏名用大写字母表示,以便于与变量区别。
可用宏定义表示数据类型,使书写方便。例如:
#define UINT unsigned int
枚举类型(Enum)
枚举类型定义示例:
enum week{ Mon, Tues, Wed, Thurs, Fri, Sat, Sun };
对应的值默认从0开始。更改默认值:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };
也可以全部自定义。
示例:
#include "stdio.h"
enum Week {
Mon, Tues, Wed, Thurs, Fri, Sat, Sun
};
void printWeekName(enum Week day){
switch (day){
case Mon:puts("Monday");break;
case Tues:puts("Tuesday");break;
case Wed:puts("Wednesday");break;
case Thurs:puts("Thursday");break;
case Fri:puts("Friday");break;
case Sat:puts("Saturday");break;
case Sun:puts("Sunday");break;
default:puts("Error!");
}
}
int main() {
printWeekName(Mon);
return 0;
}
上面的 printWeekName()方法虽然写了 enumWeek类型限制,但是你直接传int值也是可以的,但是传字符串就不行了。
需要注意的是:
枚举列表中的 Mon、Tues、Wed 这些标识符的作用范围是全局的(严格来说是
main()函数内部),不能再定义与它们名字相同的变量。Mon、Tues、Wed 等都是常量,不能对它们赋值,只能将它们的值赋给其他的变量。
预处理指令总结
| 指令 | 说明 |
|---|---|
# |
空指令,无任何效果 |
#include |
包含一个源代码文件 |
#define |
定义宏 |
#undef |
取消已定义的宏 |
#if |
如果给定条件为真,则编译下面代码 |
#ifdef |
如果宏已经定义,则编译下面代码 |
#ifndef |
如果宏没有定义,则编译下面代码 |
#elif |
如果前面的 #if给定条件不为真,当前条件为真,则编译下面代码 |
#endif |
结束一个 #if……#else条件编译块 |
柔性数组
指针
C语言数组指针
重点:
#include
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int i, *p = arr, len = sizeof(arr) / sizeof(int);
for(i=0; i
printf("%d ", *(p+i) );
}
printf("\n");
return 0;
}
1、arr用作右值,被转为指针。也就是 p, arr, &arr[0]都可以表示 数组首地址。
2、引入数组指针后,我们就有两种方案来访问数组元素了,一种是使用下标,另外一种是使用指针。
1) 使用下标 也就是采用 arr[i] 的形式访问数组元素。如果 p 是指向数组 arr 的指针,那么也可以使用 p[i] 来访问数组元素,它等价于 arr[i]。2) 使用指针 也就是使用 *(p+i) 的形式访问数组元素。另外数组名本身也是指针,也可以使用 *(arr+i) 来访问数组元素,它等价于 *(p+i)。
不管是数组名还是数组指针,都可以使用上面的两种方式来访问数组元素。不同的是,数组名是常量,它的值不能改变,而数组指针是变量(除非特别指明它是常量),它的值可以任意改变。也就是说,数组名只能指向数组的开头,而数组指针可以先指向数组开头,再指向其他元素。
3、数组指针指向的是数组中的一个具体元素,而不是整个数组,所以数组指针的类型和数组元素的类型有关,上面的例子中,p 指向的数组元素是 int 类型,所以 p 的类型必须也是 int*。
反过来想,p 并不知道它指向的是一个数组,p 只知道它指向的是一个整数,究竟如何使用 p 取决于程序员的编码。
数组在内存中只是数组元素的简单排列,没有开始和结束标志,在求数组的长度时不能使用 sizeof(p)/sizeof(int),因为 p 只是一个指向 int 类型的指针,编译器并不知道它指向的到底是一个整数还是一系列整数(数组),所以 sizeof(p) 求得的是 p 这个指针变量本身所占用的字节数,而不是整个数组占用的字节数。
也就是说,根据数组指针不能逆推出整个数组元素的个数,以及数组从哪里开始、到哪里结束等信息。不像字符串,数组本身也没有特定的结束标志,如果不知道数组的长度,那么就无法遍历整个数组。
4、假设 p 是指向数组 arr 中第 n 个元素的指针,那么 *p++、 *++p、 (*p)++ 分别是什么意思呢?
*p++ 等价于 *(p++),表示先取得第 n 个元素的值,再将 p 指向下一个元素,上面已经进行了详细讲解。
*++p等价于*(++p),会先进行 ++p 运算,使得 p 的值增加,指向下一个元素,整体上相当于 *(p+1),所以会获得第 n+1 个数组元素的值。
(*p)++ 就非常简单了,会先取得第 n 个元素的值,再对该元素的值加 1。假设 p 指向第 0 个元素,并且第 0 个元素的值为 99,执行完该语句后,第 0 个元素的值就会变为 100。
参考:http://c.biancheng.net/cpp/html/76.html
C语言字符串指针
C语言中没有特定的字符串类型,我们通常是将字符串放在一个字符数组中。字符数组属于数组,上节讲到的关于指针和数组的规则同样也适用于字符数组。
#include
#include
int main(){
char str[] = "http://c.biancheng.net";
char *pstr = str;
int len = strlen(str), i;
//使用*(pstr+i)
for(i=0; i
printf("%c", *(pstr+i));
}
printf("\n");
//使用pstr[i]
for(i=0; i
printf("%c", pstr[i]);
}
printf("\n");
//使用*(str+i)
for(i=0; i
printf("%c", *(str+i));
}
printf("\n");
return 0;
}
除此之外,C语言一共有两种表示字符串的方法,一种是字符数组,另一种是字符串常量,它们在内存中的存储位置不同,使得字符数组可以读取和修改,而字符串常量只能读取不能修改。
字符数组存储在全局数据区或栈区,第二种形式的字符串存储在常量区。全局数据区和栈区的字符串(也包括其他数据)有读取和写入的权限,而常量区的字符串(也包括其他数据)只有读取权限,没有写入权限。
字符串常量则比较特殊:
#include
int main(){
char *str = "Hello World!";
str = "I love C!"; //正确
str[3] = 'P'; //错误
return 0;
}
这段代码能够正常编译和链接,但在运行时会出现段错误(Segment Fault)或者写入位置错误。
常用函数
限于篇幅,仅列出函数名以供参考。
内存管理
malloc
free
memcmp
memcpy
memset
字符串
C语言快速入门——使用安全版本的字符串函数 - 云+社区 - 腾讯云 https://cloud.tencent.com/developer/news/73897
strlen
strcat
strdup
数据结构
七大经典排序算法总结(C语言描述)
https://www.cnblogs.com/maluning/p/7944809.html
单链表/双向链表的实现
https://www.cnblogs.com/corvoh/p/5595130.html
LeetCode刷题
https://github.com/begeekmyfriend/leetcode
LeetCode 200道,纯C,刷题实战,让你懂得怎么用十几行C实现链表和哈希表
应用
C语言编程实例
http://c.biancheng.net/c/example/
实现HTTP的GET和POST请求
https://www.jianshu.com/p/867632980b65
C语言使用hiredis访问redis
https://www.cnblogs.com/52fhy/p/9196527.html
C语言操作mysql
https://www.cnblogs.com/siqi/p/4810369.html
实现TCP Select Server
https://www.jianshu.com/p/3126d689cbe0
Glibc
https://www.cnblogs.com/guoxiaoqian/p/3984970.html
http://www.gnu.org/software/libc/
开源项目
uthash
https://github.com/troydhanson/uthash
如果你关注的是 ISO C 本身而不是那些杂七杂八的、平台相关的 syscall lib 的话,uthash 值得一阅。它是一个短小精悍、平台无关的数据结构库,只包含了几个零星的头文件,却实现了哈希表、动态数组与字符串等常用的数据结构。
B+树磁盘存储
https://github.com/begeekmyfriend/bplustree
B+树磁盘存储,1K行,附测试以及可视化调试:begeekmyfriend/bplustree
https://www.zhihu.com/question/20792016
参考
http://c.biancheng.net/cpp/html/80.html