我们先从简单的抓取文本信息开始,来写我们的第一个爬虫程序,获取搜狐新闻的内容。
我们首先来介绍一下我们需要用到的库。
爬虫程序的步骤,一般可以分为三步:
1.获取网页源码(html源码);
2.从代码中搜索自己需要的资源的位置;
3.获取(下载)该资源。
当然,现在有很成熟的python爬虫库比如scrapy等直接带有这些模块,让你用非常少的代码写出自己的爬虫程序。但是,本教程还是希望教会大家最基本的原理,带领大家自己搭建爬虫框架,这样对于深入理解和后续学习是非常有好处的。同时,这样对python语言基础的要求也不会很深。
好啦,少啰嗦,在上述步骤中,我们需要用到的python的库分别是:
1.获取网页源码(html源码):requests
2.从代码中搜索自己需要的资源的位置: BeautifulSoup, re(正则表达式)
3.获取(下载)该资源: urlretrieve (from urllib.request) (这个是python自带的,用于下载网络文件,但今天爬取新闻的时候我们不会用到)
对于新手来说,安装各种库有时会出现各种bug,因此推荐大家使用ide来进行程序的编写。我们可以使用免费的pycharm 社区版本。 https://www.jetbrains.com/pycharm/
长这样:

直接在设置里面可以选择python解释器并添加我们需要的库:

接下来,导入我们需要用到的这些库:
import requests #用于获取网页
from bs4 import BeautifulSoup #用于分析网页
import re #用于在网页中搜索我们需要的关键字
好了,我们要开始按照步骤来编写爬虫了。
1.获取网页源代码
在chrome浏览器打开搜狐新闻的网页,单击右键,选中检查选项,进入检查界面

然后选中network标签,点击刷新按钮重新载入页面,注意network中的第一项,即是这个页面的获取方法。如图,显示这个页面是从 http://news.sohu.com/ 这个网址,用 GET这个方法得到的。
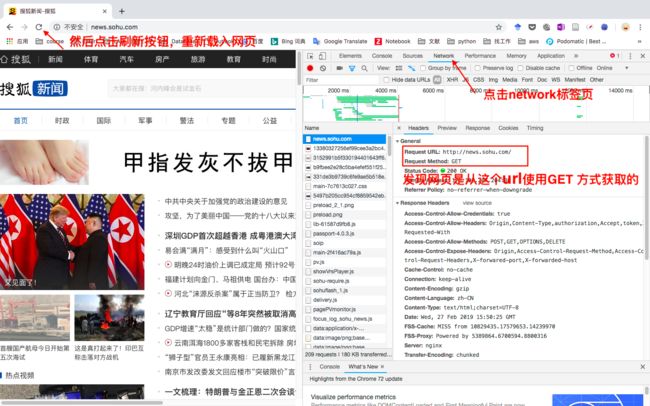
因此,我们在程序中使用requests库的get方法,获取网页元代码:
baseurl='http://news.sohu.com/'
html=requests.get(baseurl) #这是使用requests库的get方法,获取网页元代码
print(html.text) #我们打印出来看看对不对
#注意这里由于html是一个容器,他的内容放在text这个属性里面,因此要写html.text来取出里面的文字
运行一下:

我们已经成功获取了网页的源代码,第一步完成。
2.从代码中搜索自己需要的资源的位置
我们希望获取这个网页上的新闻的标题,来源,时间和链接这四个信息,因此,我们需要对网页进行解析。使用BeautifulSoup这个库。
soup=BeautifulSoup(html.text,'html.parser') #将html.text装进一个soup容器中
#此处html.parser为python自带的一个html解析器,用lxml也可以,不过要自己安装
然后,我们来发现一下我们需要获取的这些信息的特征。在chrome的检查页面,我们随便右击一个新闻标题,选择检查。然后我们发现自动跳到这一段高亮源代码,这就是这个新闻在网页源码中的位置。

再换一个新闻试一下,
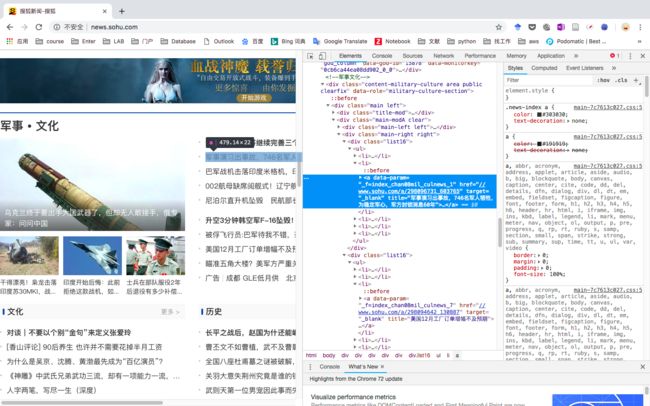
我们发现在这些代码的上级都有一个
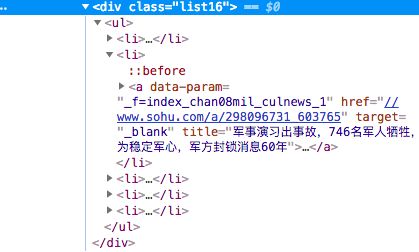
那么,这个class应该代表的就是每一个新闻的类别了。我们只要把class=list16这个类别找出来,就能找出这个页面中所有的新闻了。我们使用BeautifulSoup的find_all功能。
newslist=soup.find_all(class_='list16') #注意find_all返回的是一个列表
print(newslist) #打印出来看一下

果然,这个列表中的每一项,都包含一个title,是新闻的标题,一个href,是新闻的链接。
因此我们将这两个信息提取出来。
for news in newslist: #写一个循环
news_title=news.li.a['title'] #这是BeautifulSoup的功能,‘.’属性返回当前标签的第一个子标签。
#因为上面我们发现 news= 
很好,我们提取到了新闻标题和它对应的链接,但是我们发现有一个报错,他说,在这个报错中,news.li.a不存在。因此我们使用try语句来应对这个报错,将上面的代码修改为:
for news in newslist:
try:
news_title=news.li.a['title']
news_link=news.li.a['href']
except:
print('无法处理')
else:
print(news_title,news_link)
好了,这次报错的信息显示无法处理了,程序没有被中断。

我们现在已经获得了新闻的标题和链接。但是,注意有一些链接是完整的,有一些链接,如 www.sohu.com/a/298082723_106391并不完整,因此我们需要将不完整的链接补全,前面加上‘http:‘。做个判断。
if re.match(r'http:',news.li.a['href']):
#re.match 用于判news.li.a['href']是否含有‘http:’字符串,如果没有,加上
news_link = news.li.a['href']
else:
print('加上')
news_link = 'http:' + news.li.a['href']
现在链接都正常了。
现在我们想获得它的时间和来源。我们需要点到这个新闻的页面去。


同样的,我们发现了时间对应的代码(class=time)。同理可以获得作者对应的代码(tag:
)。
但是,别忘了,这是一个新的网页,因此我们要重新获取网页源代码,并进行解析。因此在for循环内部续写:
for news in newslist:
try:
news_title=news.li.a['title']
if re.match(r'http:',news.li.a['href']):
news_link = news.li.a['href']
else:
news_link = 'http:' + news.li.a['href']
except:
print('无法处理')
else:
# 在此循环内部续写
newshtml=requests.get(news_link)
newssoup=BeautifulSoup(newshtml.text,'html.parser')
news_time=newssoup.find_all(class_='time')[0].text
#前面提到,find_all返回一个列表,所以[0]取出列表中第一个元素,然后我们取出标签的内容属性'.text'。
news_author=newssoup.find_all('h4')[0].text
print(news_title, news_time, news_author, news_link)
for news in newslist:
try:
news_title=news.li.a['title']
if re.match(r'http:',news.li.a['href']):
news_link = news.li.a['href']
else:
news_link = 'http:' + news.li.a['href']
except:
print('无法处理')
else:
# 在此循环内部续写
newshtml=requests.get(news_link)
newssoup=BeautifulSoup(newshtml.text,'html.parser')
news_time=newssoup.find_all(class_='time')[0].text
#前面提到,find_all返回一个列表,所以[0]取出列表中第一个元素,然后我们取出标签的内容属性'.text'。
news_author=newssoup.find_all('h4')[0].text
print(news_title, news_time, news_author, news_link)
运行一下:

有的正常,有的报错,同样,用try解决一下。把代码更改为:
# 在此循环内部续写
newshtml=requests.get(news_link)
newssoup=BeautifulSoup(newshtml.text,'html.parser')
try:
news_time=newssoup.find_all(class_='time')[0].text
news_author=newssoup.find_all('h4')[0].text
except:
print('无法处理')
else:
print(news_title, news_time, news_author, news_link)

好了,这下好了。第二部,解析并获取我们需要的信息,完成。
3.存储信息
我们希望将这下抓取到的信息保存下来,而不是直接print在terminal里面。
所以,我们定义一个写入文件的函数。注意,这段代码要放在主程序代码之前,不然我们调用函数的时候程序会找不到它在哪。
def writefile(news_title,news_author,news_time,news_link):
#我们要传入四个数据,分别就是新闻的标题,作者,时间,链接
file = open('newstoday.txt', 'a') #打开文件‘newstoday.txt’,以‘a’续写的方式写入
file.write(news_title+'\t'+news_author+'\t'+news_time+'\t'+news_link+'\n')
#写入数据,‘\t’为tab,'\n'为换行符
file.close() #打开文件后一定记住关闭,不然程序会一直卡在这里不走
然后,我们在for循环里,每抓取到一个新闻的信息就调用这个函数写文件:
writefile(news_title,news_author,news_time,news_link)
好了,代码已经写完了。完整代码长这样:
import requests # 用于获取网页
from bs4 import BeautifulSoup # 用于分析网页
import re # 用于在网页中搜索我们需要的关键字
#写入文件
def writefile(news_title,news_author,news_time,news_link):
file = open('newstoday.txt', 'a')
file.write(news_title+'\t'+news_author+'\t'+news_time+'\t'+news_link+'\n')
file.close()
#获取网页
baseurl = 'http://news.sohu.com/'
html = requests.get(baseurl)
print(html.text)
#解析网页
soup=BeautifulSoup(html.text,'html.parser')
newslist=soup.find_all(class_='list16')
print(newslist)
for news in newslist:
try:
news_title=news.li.a['title']
if re.match(r'http:',news.li.a['href']):
news_link = news.li.a['href']
else:
news_link = 'http:' + news.li.a['href']
except:
print('无法处理')
else:
# 在此循环内部续写
newshtml=requests.get(news_link)
newssoup=BeautifulSoup(newshtml.text,'html.parser')
try:
news_time=newssoup.find_all(class_='time')[0].text
news_author=newssoup.find_all('h4')[0].text
except:
print('无法处理')
else:
print(news_title, news_time, news_author, news_link)
writefile(news_title,news_author,news_time,news_link)
print('抓取完毕')
运行一下,抓取完毕。

然后我们打开我们这个脚本所在的目录,发现newstoday.txt 已经生成了。

打开看看,我们抓取到的信息全都写进去了。
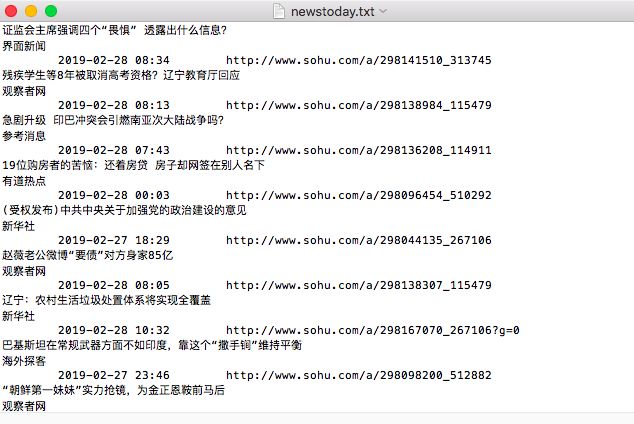
到这里,第三步完成。我们这个爬虫程序算是完成了。
好啦。感谢大家的阅读。如果你喜欢我的爬虫教程,可以关注我的账号,后续还会有更多的更新。如果有什么建议,也欢迎在评论区留言,我会悉心听取。
声明:本教程及代码仅作教学之用,无意侵犯其它网站或公司版权。本节爬取的搜狐新闻内容,版权为搜狐新闻网站所有。对于套用本教程代码非法爬取其他网站或公司非公开数据而导致的损害,本教程不承担任何责任。