串联高频面试问题,触类旁通,一通百通!
前言
开宗明义,本瓜深知汝之痛点:前端面试知识点太杂,卿总为了面试而面试,忘了记,记了又忘,循环往复,为此叫苦不迭。
来,让本瓜带领各位都稍稍回顾一下,自己曾经在学生时代记忆元素周期表的光辉岁月。
氢、氦、锂、铍、硼、碳、氮、氧、氟、氖、钠、镁、铝、硅、磷、硫、氯、氩、钾、钙、钪、钛、钒、铬、猛、铁、钴、镍、铜、锌…
咱当初记这前三十位元素,是死记硬背的吗?答案是否定的,机智的我们用到了 串联记忆法 。
一定是像这样或类似这样去记:
第一周期:氢 氦 ———— 轻嗨:轻轻的打个了招呼:嗨!
第二周期:锂 铍 硼 碳 氮 氧 氟 氖 ———— 你皮捧碳 蛋养福奶:你很皮,手里捧了一把碳。鸡蛋能够滋养福气的奶妈
第三周期:钠 镁 铝 硅 磷 硫 氯 氩 ———— 那美女桂林留绿牙:那美女在桂林留绿色的牙齿
第四周期:钾 钙 钪 钛 钒 铬 猛 铁 钴 镍 铜 锌 ———— 贾盖坑太凡哥 猛铁骨裂痛心:“贾盖”坑了“太凡哥”,导致猛男铁汉骨头碎裂很痛心
串联联想与二元链式联想记忆的方法有相似之处,就是都要通过想象、创造和编故事来帮助我们达到双脑学习和记忆的目的。—— 出处
有木有?本瓜记得尤为清楚,以上串联起来的谐音故事简直可以写出一个狗血剧本了。尤其是“那美女(钠镁铝)”简单三字仿佛就能激起青春期的荷尔蒙。如此,学习能不有兴趣吗?兴趣是最好的老师!想忘掉都难啊!
于是乎,本瓜类比归化,将自己遇到过的高频面试问题运用串联联想法进行了“串联”整理,以期形成系统,与各位同好分享。
上图!

- 本文脑图支持:processon
我是掘金安东尼,愿一直与你同行!
我的个站:https://tuaran.site
My Blog:https://tuaran.github.io
串联一:
从输入URL到页面加载发生了什么?
此题是经典中的经典,可挖掘的点非常之多,亦非常之深。
一图胜万言

- 原创脑图,转载请说明出处
串联知识点:URL解析、DNS查询、TCP握手、HTTP请求、浏览器处理返回报文、页面渲染
串联记忆:共计六步,归并为一句话来记忆:UDTH,处理返回加渲染。
“UDTH” 即URL解析、DNS查询、TCP握手、HTTP请求,
“处理返回加渲染”,即浏览器处理返回报文,和页面渲染。
同时,本瓜倾情在脑图上标注了每个步骤可能考察的知识点“关键词”,真的是个个重点,不容错过!
一、URL 解析
URL(Uniform Resource Locator),统一资源定位符,用于定位互联网上资源,俗称网址。
// 示例引自 wikipedia
hierarchical part
┌───────────────────┴─────────────────────┐
authority path
┌───────────────┴───────────────┐┌───┴────┐
abc://username:[email protected]:123/path/data?key=value&key2=value2#fragid1
└┬┘ └───────┬───────┘ └────┬────┘ └┬┘ └─────────┬─────────┘ └──┬──┘
scheme user information host port query fragment
scheme - 定义因特网服务的类型。常见的协议有 http、https、ftp、file,
其中最常见的类型是 http,而 https 则是进行加密的网络传输。
host - 定义域主机(http 的默认主机是 www)
domain - 定义因特网域名,比如 baidu.com
port - 定义主机上的端口号(http 的默认端口号是 80)
path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
filename - 定义文档/资源的名称
query - 即查询参数
fragment - 即 # 后的hash值,一般用来定位到某个位置
更多可见:
- URL RFC
- Wikipedia-URI
URL 编码
一般来说,URL 只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。此在 URL RFC 已做硬性规定。
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致"URL编码"成为了一个混乱的领域。
阮老师早在 2010 年已解释了:关于URL编码- 阮一峰
这里可直接看结论:浏览器对 URL 编码会出现差异从而造成混乱,所以假设我们使用 Javascript 预先对 URL 编码,然后再向服务器提交。因为Javascript 的输出总是一致的,这样就保证了服务器得到的数据是格式统一的。
我们常使用到:encodeURI()、encodeURIComponent();前者对整个 URL 进行 utf-8 编码,后者是对 URL 部分进行编码。
本瓜请问:你能清楚的解释 ASCII、Unicode、UTF-8、GBK 含义和关系吗?
也许我们并不太了解我们常见、常用的东西。
| 类型 | 含义 |
|---|---|
| ASCII | 8位一个字节,1个字节表示一个字符.即: 2 ** 8 = 256,所以ASCII码最多只能表示256个字符。 |
| Unicode | 俗称万国码,把所有的语言统一到一个编码里.解决了ASCII码的限制以及乱码的问题。unicode码一般是用两个字节表示一个字符,特别生僻的用四个字节表示一个字符。 |
| UTF-8 | “可变长的编码方式”,如果是英文字符,则采用ASCII编码,占用一个字节。如果是常用汉字,就占用三个字节,如果是生僻的字就占用4~6个字节。 |
| GBK | 国内版本,一个中文字符 == 两个字节 英文是一个字节 |
强缓存、协商缓存
言外之音:本瓜起初是将强缓存、协商缓存放在第三步 “HTTP 请求”中,后来了解到:如果命中了强缓存则可不再走DNS解析这步。遂将其归到此处。浏览器强缓存是按照ip还是域名缓存的?
强缓存、协商缓存是必考题。具体流程如下:
-
浏览器在加载资源时,根据请求头的 expires和 cache-control判断是否命中强缓存,是则直接从缓存读取资源,不会发请求到服务器。
expires:HTTP/1.0 时期,根据对比本地时间和服务器时间来判断。
cache-control:HTTP/1.1 时期,根据相对时间来判断,如设置max-age,单位为秒。
-
如果没有命中强缓存,浏览器一定会发送一个请求到服务器,通过Etag和Last-Modified-If验证资源是否命中协商缓存,如果命中,服务器会将这个请求返回(304),告诉浏览器从缓存中读取数据。
【ETag、If-None-Match】成对:Etag 是服务器返回给浏览器的,If-None-Match 是浏览器请求服务器的。通过对比二者来判断,它们记录的是:文件生成的唯一标识。
【Last-Modified,If-Modified-Since】成对:Modified-Since 是服务器返回给浏览器的,If-Modified-Since 是浏览器请求服务器的。通过对比二者来判断,它们记录的是:最后修改时间。
注:ETag 的优先级比 Last-Modified 更高。大部分 web 服务器都默认开启协商缓存,而且是同时启用【ETag、If-None-Match】和 【Last-Modified,If-Modified-Since】。
-
如果前面两者都没有命中,直接从服务器加载资源。
综上,强缓存和协商缓存如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;不同的是:强缓存不会发请求到服务器,协商缓存会发请求到服务器进行对比判断得出是否命中。
- 借一个流程图,暂未找到真实出处,保留引用说明坑位。

以上还有另一个重点,就是cache-control的值的分类:如“no-cache”、“no-store”、“private”等,需要细扣。此处仅暂列二三、作初步释义。
- no-cache: 跳过当前的强缓存,发送HTTP请求,即直接进入协商缓存阶段。
- no-store:不进行任何形式的缓存。
- private: 这种情况就是只有浏览器能缓存了,中间的代理服务器不能缓存。
更多可见:
- Cache-Control - MDN
- 缓存(二)——浏览器缓存机制:强缓存、协商缓存 #41
二、DNS查询
递归查询
DNS 解析 URL(自右向左) 找到对应的 ip
// 例如:查找www.google.com的IP地址过程(真正的网址是www.google.com.):
// 根域名服务器 -> com顶级域名服务器 -> google.com域名服务器 -> www.google.com对应的ip
. -> .com -> google.com. -> www.google.com.
这是一个递归查询的过程。

关于根域名的更多知识,可见
根域名的知识-阮一峰。
DNS 缓存
请记住:有 DNS 的地方,就有 DNS 缓存。
DNS存在着多级缓存,从距离浏览器的距离排序的话,有以下几种:
1.浏览器缓存 2.系统缓存 3.路由器缓存 4.IPS 服务器缓存 5.根域名服务器缓存 6.顶级域名服务器缓存 7.主域名服务器缓存。
查看缓存:
-
浏览器查看 DNS 缓存:chrome://net-internals/#dns
-
win10 系统查看 DNS 缓存:win+R => cmd => ipconfig /displaydns
DNS 负载均衡
DNS负载均衡技术的实现原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时,DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。—— 百科
三、TCP握手
DNS解析返回域名的IP之后,接下来就是浏览器要和该IP建立TCP连接了。
言外之音:TCP 的相关知识在大学基础课程《计算机网络》都有,本瓜内心苦:出来混的迟早是要还的…
TCP/IP 模型:链路层-网络层-传输层-应用层。
与之对应,OSI(开放式系统互联模型)也不能忘。通常认为 OSI 模型的最上面三层(应用层、表示层和会话层)对应 TCP/IP 模型中的应用层。wiki
在 TCP/IP 模型中,像常用的 HTTP/HTTPS/SSH 等协议都在应用层上。

三次握手、四次挥手
所谓三次握手(Three-way Handshake),是指建立一个 TCP 连接时,需要客户端和服务器总共发送3个包。
三次握手就跟早期打电话时的情况一样:1、A:听得到吗?2、B:听得到,你呢?3、A:我也听到了。然后才开始真正对话。
1. 第一次握手(SYN=1, seq=x):
客户端发送一个 TCP 的 SYN 标志位置1的包,指明客户端打算连接的服务器的端口,以及初始序号 X,保存在包头的序列号(Sequence Number)字段里。
发送完毕后,客户端进入 SYN_SEND 状态。
2. 第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1):
服务器发回确认包(ACK)应答。即 SYN 标志位和 ACK 标志位均为1。服务器端选择自己 ISN 序列号,放到 Seq 域里,同时将确认序号(Acknowledgement Number)设置为客户的 ISN 加1,即X+1。 发送完毕后,服务器端进入 SYN_RCVD 状态。
3. 第三次握手(ACK=1,ACKnum=y+1)
客户端再次发送确认包(ACK),SYN 标志位为0,ACK 标志位为1,并且把服务器发来 ACK 的序号字段+1,放在确定字段中发送给对方,并且在数据段放写ISN的+1
发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手结束。

所谓四次挥手(Four-way handshake),是指 TCP 的连接的拆除需要发送四个包。
四次挥手像老师拖堂的场景:1、学生说:老师,下课了。2、老师:好,我知道了,我说完这点。3、老师:好了,说完了,下课吧。4、学生:谢谢老师,老师再见。
1. 第一次挥手(FIN=1,seq=x)
假设客户端想要关闭连接,客户端发送一个 FIN 标志位置为1的包,表示自己已经没有数据可以发送了,但是仍然可以接受数据。
发送完毕后,客户端进入 FIN_WAIT_1 状态。
2. 第二次挥手(ACK=1,ACKnum=x+1)
服务器端确认客户端的 FIN 包,发送一个确认包,表明自己接受到了客户端关闭连接的请求,但还没有准备好关闭连接。
发送完毕后,服务器端进入 CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态,等待服务器端关闭连接。
3. 第三次挥手(FIN=1,seq=y)
服务器端准备好关闭连接时,向客户端发送结束连接请求,FIN 置为1。
发送完毕后,服务器端进入 LAST_ACK 状态,等待来自客户端的最后一个ACK。
4. 第四次挥手(ACK=1,ACKnum=y+1)
客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT状态,等待可能出现的要求重传的 ACK 包。
服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
客户端等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。

你若问我:三次握手、四次挥手的详细内容太难记了,还记不记?本瓜答:进大厂是必要的。
动图来源:两张动图-彻底明白TCP的三次握手与四次挥手
流量控制(滑动窗口)
为了增加网络的吞吐量,想将数据包一起发送过去,实现“流量控制”,这时候便产生了“滑动窗口”这种协议。
滑动窗口允许发送方在收到接收方的确认之前发送多个数据段。窗口大小决定了在收到目的地确认之前,一次可以传送的数据段的最大数目。窗口大小越大,主机一次可以传输的数据段就越多。当主机传输窗口大小数目的数据段后,就必须等收到确认,才可以再传下面的数据段。
窗口的大小在通信双方连接期间是可变的,通信双方可以通过协商动态地修改窗口大小。改变窗口大小的唯一根据,就是接收端缓冲区的大小。
拥塞控制
需求>供给 就会产生拥塞
通过“拥塞窗口”、“慢启动”、“快速重传”、“快速恢复”动态解决。
TCP 使用多种拥塞控制策略来避免雪崩式拥塞。TCP会为每条连接维护一个“拥塞窗口”来限制可能在端对端间传输的未确认分组总数量。这类似 TCP 流量控制机制中使用的滑动窗口。TCP在一个连接初始化或超时后使用一种“慢启动”机制来增加拥塞窗口的大小。它的起始值一般为最大分段大小(Maximum segment size,MSS)的两倍,虽然名为“慢启动”,初始值也相当低,但其增长极快:当每个分段得到确认时,拥塞窗口会增加一个MSS,使得在每次往返时间(round-trip time,RTT)内拥塞窗口能高效地双倍增长。—— TCP拥塞控制-wikipedia
滑动窗口(流量控制)和拥塞控制里的原理性的东西太多,本瓜表示无力,暂时要求尽力去理解去记忆。
推荐阅读:
- 一篇带你读懂TCP之“滑动窗口”协议
- TCP流量控制、拥塞控制
四、HTTP请求
HTTP是万维网的数据通信的基础 —— 维基百科
HTTP请求报文是由三部分组成: 请求行, 请求报头和请求正文。
HTTP响应报文也是由三部分组成: 状态码, 响应报头和响应报文。
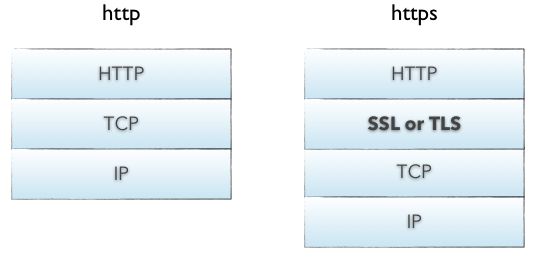
HTTP、HTTPS
HTTP 和 HTTPS 的区别?
HTTP报文是包裹在TCP报文中发送的,服务器端收到TCP报文时会解包提取出HTTP报文。但是这个过程中存在一定的风险,HTTP报文是明文,如果中间被截取的话会存在一些信息泄露的风险。
如果在进入TCP报文之前对HTTP做一次加密就可以解决这个问题了。HTTPS协议的本质就是HTTP + SSL(or TLS)。在HTTP报文进入TCP报文之前,先使用SSL对HTTP报文进行加密。从网络的层级结构看它位于HTTP协议与TCP协议之间。
HTTP2
http2 是完全兼容 http/1.x 的,并在此基础上添加了 4 个主要新特性:
- 二进制分帧:http/1.x 是一个文本协议,而 http2 是一个二进制协议。
- 头部压缩:http/1.x 中请求头基本不变,http2 中提出了一个 HPACK 的压缩方式,用于减少 http header 在每次请求中消耗的流量。
- 服务端推送:服务端主动向客户端推送数据。
- 多路复用:http/1.x,每个 http 请求都会建立一个 TCP 连接;http2,所有的请求都会共用一个TCP连接。
更多了解,可见 HTTP2 详解
GET、POST
直观区别:
- GET 用来获取数据,POST 用来提交数据。
- GET 参数有长度限制(受限于url长度,具体的数值取决于浏览器和服务器的限制,最长2M),而 POST 无限制。
- GET 请求的数据会附加在 URL 上,以"?“分割,多个参数用”&"连接,而 POST 请求会把请求的数据放在 HTTP 请求体中。都可被抓包。
- GET 请求会保存在浏览器历史记录中,还可能保存在 WEB 服务器的日志中。
隐藏区别(存在浏览器差异):
- GET 产生一个 TCP 数据包;POST 产生两个 TCP 数据包。
更多了解:
RESTful API 设计指南 - 阮一峰
Keep-Alive
我们都知道使用 Keep-Alive 是为了避免重新建立连接。
目前大部分浏览器都是用 http1.1 协议,默认都会发起 Keep-Alive 的连接请求了,所以是否能完成一个完整的 Keep-Alive 连接就看服务器设置情况。
HTTP 长连接不可能一直保持,它有两个参数,例如 Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。
Keep-Alive 模式发送数据 HTTP 服务器不会自动断开连接,所有不能使用返回EOF(-1)来判断。
基于此,抛问题:当 HTTP 采用 keepalive 模式,当客户端向服务器发生请求之后,客户端如何判断服务器的数据已经发生完成?
-
使用消息首部字段 Conent-Length:Conent-Length表示实体内容长度,客户端可以根据这个值来判断数据是否接收完成。
-
使用消息首部字段 Transfer-Encoding:如果是动态页面,服务器不可能预先知道内容大小,这时就可以使用Transfer-Encoding:chunk 模式来传输数据了。即如果要一边产生数据,一边发给客户端,服务器就需要使用"Transfer-Encoding: chunked"这样的方式来代替Content-Length。chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束
本瓜之前面试腾讯 PCG 就被问到 Transfer-Encoding:chunk 这个,请大家格外注意。
参考:
- Keep-Alive - MDN
- HTTP长连接和短连接
五、浏览器处理返回报文
状态码
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。
平时遇到比较常见的状态码有:200, 204, 301, 302, 304, 400, 401, 403, 404, 422, 500。
切分返回头和返回体(腾讯 PCG 考点)
这里的考点其实和 http keep-alive 中的问题重合,但是还是想着重强调,因为本瓜掉过这个坑,再三点出,以示后人。
最终归为这个问题:Detect end of HTTP request body - stackoverflow
解答:
1. If the client sends a message with Transfer-Encoding: Chunked, you will need to parse the somewhat complicated chunked transfer encoding syntax. You don not really have much choice in the matter -- if the client is sending in this format, you have to receive it. When the client is using this approach, you can detect the end of the body by a chunk with a length of 0.
2. If the client instead sends a Content-Length, you must use that.
即:如何获取 HTTP 返回体?
-
先把 header 直到 \r\n\r\n(两个换行)整个读取,即整个请求头;
-
如果返回 Transfer-Encoding: Chunked,则读取,直到遇到空 chunked 块,则结束。
-
如果返回 Content-Length,则读从请求头的末尾开始计算 Content-Length 长度的字节。
-
其他情况,等待返回。
了解更多:HTTP 之响应篇
本地数据存储
- cookie:4K,可以手动设置失效期。
- localStorage:5M,除非手动清除,否则一直存在。
- sessionStorage:5M,不可以跨标签访问,页面关闭就清理。
- indexedDB:浏览器端数据库,无限容量,除非手动清除,否则一直存在。
- Web SQL:关系数据库,通过SQL语句访问(已经被抛弃)。
浏览器缓存位置
按优先级从高到低:
- Service Worker:本质是一个web worker,是独立于网页运行的脚本。
- Memory Cache:Memory Cache指的是内存缓存,从效率上讲它是最快的。
- Disk Cache:Disk Cache就是存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,但是他的优势在于存储容量和存储时长。
- Push Cache:即推送缓存,是 HTTP/2 的内容。
更多:
- service worker 静态资源离线缓存实践
- HTTP/2 push is tougher than I thought
离线缓存:
HTML5-离线缓存(Application Cache)
注:“浏览器缓存位置”和“离线缓存”了解相关,有个概念/印象即可。
六、页面渲染
CssTree+DomTree
本瓜知道你知道过程是这样的:
dom tree + css tree = render tree => layout =>painting?
但是你真的吃透了吗?
HTML → DOM树 转化过程:
- 解码:浏览器从磁盘或网络读取HTML的原始字节,然后根据指定的文件编码格式(例如 UTF-8)将其转换为相应字符
- 令牌化:浏览器把字符转化成W3C HTML5 标准指定的各种确切的令牌,比如""、""以及其他在尖括号内的字符串。每个令牌都有特殊的含义以及它自己的一套规则
- 词法分析:生成的令牌转化为对象,这个对象定义了它们的属性及规则
- DOM树构建:最后,由于HTML标记定义了不同标签之间的关系(某些标签嵌套在其他标签中),创建的对象在树状的数据结构中互相链接,树状数据结构也捕获了原始标签定义的父子关系:HTML对象是body对象的父对象,body是p对象的父对象等等

CSS → CSSOM树 转化过程类同以上
CSSOM只输出包含有样式的节点,最终输出为:

Render Tree (生成渲染树,计算可见节点和样式)
- 不包括Header 、 script 、meta 等不可见的节点
- 某些通过 CSS 隐藏的节点在渲染树中也会被忽略,比如应用了 display:none 规则的节点,而visibility: hidden只是视觉不可见,仍占据空间,不会被忽略。
layout:依照盒子模型,计算出每个节点在屏幕中的位置及尺寸
painting:按照算出来的规则,通过显卡,把内容画到屏幕上。
回流、重绘
回流:
当可见节点位置及尺寸发生变化时会发生回流
重绘:
改变某个元素的背景色、文字颜色、边框颜色等等不影响它周围或内部布局的属性时,屏幕的一部分要重画,但是元素的几何尺寸没有变。
这里本瓜再抛两个问题。
Q1:浏览器在什么时候向服务器发送获取css、js外部文件的请求?
A1:解析DOM时碰到外部链接,如果还有connection,则立刻触发下载请求。
Q2:CSSOM DOM JavaScript 三者阻塞关系?
A2:CSSOM DOM互不影响,JavaScript会阻塞DOM树的构建但JS前的HTML可以正常解析成DOM树,CSSOM的构建会阻塞JavaScript的执行。对此句存疑?
- css 加载的阻塞情况:
css加载不会阻塞DOM树的解析
// DOM解析和CSS解析是两个并行的进程,所以这也解释了为什么CSS加载不会阻塞DOM的解析。css加载会阻塞DOM树的渲染
// 由于Render Tree是依赖于DOM Tree和CSSOM Tree的,所以他必须等待到CSSOM Tree构建完成,也就是CSS资源加载完成(或者CSS资源加载失败)后,才能开始渲染。因此,CSS加载是会阻塞Dom的渲染的。css加载会阻塞后面js语句的执行
// 由于js可能会操作之前的Dom节点和css样式,因此浏览器会维持html中css和js的顺序。因此,样式表会在后面的js执行前先加载执行完毕。所以css会阻塞后面js的执行。
参考阅读:
- css加载会造成阻塞吗?
- 浏览器页面渲染流程梳理
综合补充
web 性能优化
- 雅虎35条军规
串联二:
老生常谈,请你谈一下闭包?
假若你认为此题简单,一两句话就能说完?那当真浮于表面。此题实则一两天都说不完!它可以牵扯出 js 原理的大部分知识。是真正意义上的“母题”。
一图胜万言

- 原创脑图,转载请说明出处
串联知识点:闭包、作用域、原型链、js继承。
串联记忆:此题并非像上文题“从输入URL到页面加载发生了什么?”,后者“串联点”是按解答步骤来递进的。而这里的“串联点”,更多是你中有我,我中有你,前后互相补充,互相完善。当你领略完的时候,一定会有一种“万物归宗”的感觉。
归并为一五言诗来记忆:
闭包作用域
原型多考虑
继承八大法
基础好好叙
一、闭包
闭包含义
一言以蔽之。
在一个函数内有另外一个函数可以访问它的内部变量,并且另外一个函数在外部被调用,这样的词法环境叫闭包。
- 作用:
- 读取函数内部的变量;(私有变量、不污染全局)
- 让变量始终保存在内存中。
闭包应用
- 最经典试题
for(var i = 0; i < 5; i++){
(function(j){
setTimeout(function(){
console.log(j);
},1000);
})(i);
}
console.log(i);
垃圾回收机制
- js 垃圾回收机制:标记清除和引用计数。
标记清除简单讲就是变量存储在内存中,当变量进入执行环境的时候,垃圾回收器会给它加上标记,这个变量离开执行环境,将其标记为“清除”,不可追踪,不被其他对象引用,或者是两个对象互相引用,不被第三个对象引用,然后由垃圾回收器收回,释放内存空间。
防抖、节流函数
- 防抖
function debounce(fn, delay) {
var timer; // 维护一个 timer
return function () {
var _this = this; // 取debounce执行作用域的this
var args = arguments;
if (timer) {
clearTimeout(timer);
}
timer = setTimeout(function () {
fn.apply(_this, args); // 用apply指向调用debounce的对象,相当于_this.fn(args);
}, delay);
};
}
- 节流
function throttle(fn, delay) {
var timer;
return function () {
var _this = this;
var args = arguments;
if (timer) {
return;
}
timer = setTimeout(function () {
fn.apply(_this, args);
timer = null; // 在delay后执行完fn之后清空timer,此时timer为假,throttle触发可以进入计时器
}, delay)
}
}
二、作用域
全局作用域
- 直接编写在script标签中的JS代码,都在全局作用域;
- 全局作用域在页面打开时创建,在页面关闭时销毁;
- 在全局作用域中有一个全局对象window,它代表的是一个浏览器的窗口,它由浏览器创建我们可以直接使用;
- 全局作用域中,创建变量都会作为window对象的属性保存;
- 创建的函数都会作为window对象的方法保存;
- 全局作用域中的变量都是全局变量,在页面的任何部分都可以访问的到;
我们可以在控制台直接打印试试看,正如以上所说:

函数作用域(局部作用域)
- 变量在函数内声明,变量属于局部作用域。
- 局部变量:只能在函数内部访问。
- 局部变量只作用于函数内,所以不同的函数可以使用相同名称的变量。
- 局部变量在函数开始执行时创建,函数执行完后局部变量会自动销毁。
块级作用域
块级作用域 : 块级作用域指的就是使用 if () { }; while ( ) { } …这些语句所形成的语句块 , 并且其中变量必须使用 let 或 const 声明,保证了外部不可以访问语句块中的变量。
注:函数作用域和块级作用域没有直接关系。
- const、let、var 区别
- const 声明则不能改变,块级作用域,不允许变量提升。
- let 块级作用域,不允许变量提升。
- var 非块级作用域,允许变量提升。
作用域链
出现函数嵌套函数,则就会出现作用域链 scope chain。
- 遍历嵌套作用域链的规则很简单:引擎从当前的执行作用域开始查找变量,如果找不到, 就向上一级继续查找。当抵达最外层的全局作用域时,无论找到还是没找到,查找过程都会停止。
- 局部作用域(如函数作用域)可以访问到全局作用域中的变量和方法,而全局作用域不能访问局部作用域的变量和方法。
用作用域链来解释闭包:
function outter() {
var private= "I am private";
function show() {
console.log(private);
}
// [[scope]]已经确定:[outter上下文的变量对象,全局上下文变量对象]
return show;
}
var ref = outter();
console.log(private); // outter执行完以后,private不会被销毁,并且只能被show方法所访问,
//直接访问它会出现报错:private is not defined
ref(); // 打印I am private
其实,我们要明白的是函数的声明和调用是分开的,如果不搞清楚这一点,很多基础面试题就容易出错。
- 深究:
JavaScript深入之词法作用域和动态作用域 #3
变量生命周期
一个变量的声明意味着就是我们在内存当中申请了一个空间用来存储。这个内存也就是我们电脑的运行内存,如果我们一直的声明变量,不释放的话。会占用很大的内存。
在 c/c++ 当中是需要程序员在合适的地方手动的去释放变量内存,而 javascript 和 java 拥有垃圾回收机制(咱们在上文已说明)。
js 变量分为两种类型:全局变量和局部变量
- 全局变量的生命周期:从程序开始执行创建,到整个页面关闭时,变量收回。
- 局部变量的生命周期:从函数开始调用开始,一直到函数调用结束。
但有的时候我们需要让局部变量的生命周期长一点,此时就用到了闭包。
三、原型链
实例与原型
一个原型对象的隐形属性指向构造它的构造函数的显示属性。
当一个对象去查找它的属性,找不到就去找他的构造函数的属性,一直向上找,直到找到 Object()。
判断数据类型
- typeof
- instanceof
- constructor
- Object.prototype.toString.call()
new 一个对象
步骤:
- 创建一个新对象
- 将构造函数的作用域赋给新对象(因此this指向了这个新对象)
- 执行构造函数中的代码(为这个新对象添加属性)
- 返回新对象
this 指向
this 指向 5 大规则:
- 如果 new 关键词出现在被调用函数的前面,那么JavaScript引擎会创建一个新的对象,被调用函数中的this指向的就是这个新创建的函数。
- 如果通过apply、call或者bind的方式触发函数,那么函数中的this指向传入函数的第一个参数。
- 如果一个函数是某个对象的方法,并且对象使用句点符号触发函数,那么this指向的就是该函数作为那个对象的属性的对象,也就是,this指向句点左边的对象
- 如果一个函数作为FFI被调用,意味着这个函数不符合以上任意一种调用方式,this指向全局对象,在浏览器中,即是window。
- 如果出现上面对条规则的累加情况,则优先级自1至4递减,this的指向按照优先级最高的规则判断。
参考:this指向记忆5大原则
- 箭头函数中的 this 指向:箭头函数中的this是在定义函数的时候绑定,而不是在执行函数的时候绑定。
更多:JS中的箭头函数与this
bind、call、apply
- call
call()方法接收的第一个参数和apply()方法接收的一样,变化的是其余的参数直接传递给函数。换句话说,在使用call()方法时,传递给函数的参数必须逐个列举出来。
function sum(num1 , num2){
return num1 + num2;
}
function callSum(num1 , num2){
return sum.call(this , sum1 , sum2);
}
console.log(callSum(10 , 10)); // 20
- apply
apply()方法接收两个参数:一个是在其中运行函数的作用域,另一个是参数数组,这里的参数数组可以是Array的实例,也可以是arguments对象(类数组对象)。
function sum(num1 , num2){
return num1 + num2;
}
function callSum1(num1,num2){
return sum.apply(this,arguments); // 传入arguments类数组对象
}
function callSum2(num1,num2){
return sum.apply(this,[num1 , num2]); // 传入数组
}
console.log(callSum1(10 , 10)); // 20
console.log(callSum2(10 , 10)); // 20
call和apply的区别在于二者传参的时候,前者是一个一个的传,后者是传数组或类数组arguments
- bind
bind()方法创建一个新的函数, 当被调用时,将其this关键字设置为提供的值,在调用新函数时,在任何提供之前提供一个给定的参数序列。
手写深浅拷贝
浅:
function clone(target) {
let cloneTarget = {};
for (const key in target) {
cloneTarget[key] = target[key];
}
return cloneTarget;
};
深(递归):
function clone(target) {
if (typeof target === 'object') {
let cloneTarget = Array.isArray(target) ? [] : {};
for (const key in target) {
cloneTarget[key] = clone(target[key]);
}
return cloneTarget;
} else {
return target;
}
};
了解更多,推荐阅读:如何写出一个惊艳面试官的深拷贝?
四、js 继承
八种继承方式,详细请看此篇:JavaScript常用八种继承方案。
本瓜不做赘述,此处仅列二三关键必记。
串联三:
请你谈谈 Vue 原理?
本瓜不装了,摊牌了。其实本文的目录结构编写时间线在 《 Vue(v2.6.11)万行源码生啃,就硬刚!》
这篇文章之前。当时就是因为似懂非懂,才定下心来“生啃源码”。现在源码看完了,体会的确又不一样了。但由于细节太多,篇幅受限。此处也仅列框架、点出要点、注释链接,以便记忆。
一图胜万言

- 原创脑图,转载请说明出处
串联知识点:Vue初始化和生命周期、虚拟DOM、响应式原理、组件编译、Vue常用补充、Vue全家桶。
串联记忆:编一顺口溜,见笑。
V U E 真容易
初始化 有生命
虚拟 dom 好给力
响应式 看仔细
组件化 大家利
全家桶 笑嘻嘻
会打包 挣一亿
- 邀大家来改编
一、init&render
挂载和初始化
new Vue()发生了什么?
Vue 实际上是一个类,类在 Javascript 中是用 Function 来实现的。Vue 只能通过 new 关键字初始化,然后会调用 this._init 方法。
初始化主要实现:合并配置(mergeOptions),初始化生命周期(initLifecycle),初始化事件中心(initEvents),初始化渲染(initRender),初始化 data、props、computed、watcher 等等。
流程图参考如下:

- 此图在组件编译环节少了 optimize ,可能由于版本差异。 Vue2.4.4 源码
- 借图,未找到真实出处,保留引用说明坑位。
实例生命周期
生命周期图示,还是得看官网文档。还记得这句话吗?
下图展示了实例的生命周期。你不需要立马弄明白所有的东西,不过随着你的不断学习和使用,它的参考价值会越来越高。
注释版:

推荐:源码解读
要点注释:
- beforeCreate 和 created 函数都是在实例化 Vue 的阶段,在 _init 方法中执行的。从源码中可以看到 beforeCreate 和 created 的钩子调用是在 initState 的前后,initState 的作用是初始化 props、data、methods、watch、computed 等属性。那么显然 beforeCreate 的钩子函数中就不能获取到 props、data 中定义的值,也不能调用 methods 中定义的函数。而 created 钩子函数可以。
Vue.prototype._init = function (options?: Object) {
// ...
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate') // beforeCreate 钩子
initInjections(vm) // resolve injections before data/props
initState(vm)
initProvide(vm) // resolve provide after data/props
callHook(vm, 'created') // created 钩子
// ...
}
-
在执行 vm._render() 函数渲染 VNode 之前,执行了 beforeMount 钩子函数,在执行完 vm._update() 把 VNode patch 到真实 DOM 后,执行 mounted 钩子。(此点重要)
-
beforeUpdate 的执行时机是在渲染 Watcher 的 before 函数中调用。update 的执行时机是在 flushSchedulerQueue 函数调用的时候。
-
beforeDestroy 和 destroyed 钩子函数的执行时机在组件销毁的阶段。
-
activated 和 deactivated 钩子函数是专门为 keep-alive 组件定制的钩子。
重点说明:
- 在 Vue2 中,所有 Vue 的组件的渲染最终都需要 render 方法,无论我们是用单文件 .vue 方式开发组件,还是写了 el 或者 template 属性,最终都会转换成 render 方法,用来把实例渲染成一个虚拟 Node(Virtual DOM)。
二、虚拟DOM
Vue 2.0 相比 Vue 1.0 最大的升级就是利用了 Virtual DOM。
vdom
vdom 其实就是一颗 js 对象树,最少包含标签名( tag)、属性(attrs)和子元素对象( children)三个属性。原本对 DOM 节点的操作(浏览器将 DOM 设计的非常复杂)转成了对 js 对象的操作,加快处理速度、提升性能。
VNode 的创建是由 createElement 方法实现的。
欲知原理,推荐阅读:snabbdom
diff & patch
在实际代码中,会对新旧两棵树进行一个深度的遍历,每个节点都会有一个标记。每遍历到一个节点就把该节点和新的树进行对比,如果有差异就记录到一个对象中。即用 diff 算法比较差异,然后调用 patch 应用到真实 DOM 上去。patch 的过程即一个打补丁的过程。

图片来源
diff 算法是一个交叉对比的过程,大致可以简要概括为:头头比较、尾尾比较、头尾比较、尾头比较。
入门级别 diff 详情推荐看此篇:LINK

图片来源
注意:render函数返回的是 vdom,patch生成的才是真实DOM。
三、响应式原理
官方生图,高屋建瓴。

本瓜曾在《简析 vue 的双向绑定原理》这篇文章写过,如今看又是一番心情。
当你把一个普通的 JavaScript 对象传入 Vue 实例作为 data 选项,Vue 将遍历此对象所有的 property,并使用 Object.defineProperty 把这些 property 全部转为 getter/setter。Object.defineProperty 是 ES5 中一个无法 shim 的特性,这也就是 Vue 不支持 IE8 以及更低版本浏览器的原因。
发布订阅者模式(字节考题)
class emit {
}
cosnt eeee = new emit()
eeee.on('aa' , function() { console.log(1)})
eeee.on('aa' , function() {console.log(2)})
eeee.emit('aa')
//class emit{}
// 要求手写发布者-订阅模式
class Subject{
constructor () {
this.observers =[]
}
add (observer) {
this.observers.push(observer)
}
notify () {
this.observers.map((item, index) => {
item.update()
})
}
}
class Observer {
constructor (name) {
this.name = name
}
update () {
console.log("I`m " + this.name)
}
}
var sub = new Subject()
var obs1 = new Observer("obs1")
var obs2 = new Observer("obs2")
sub.add(obs1)
sub.add(obs2)
sub.notify() // I`m obs1 I`m obs2
除了“发布者订阅模式”,你还知道哪些 js 设计模式?这里留个坑,以后再补,东西太多了…
Observe
Observe 的功能就是用来监测数据的变化。它的作用是给对象的属性添加 getter 和 setter,用于依赖收集和派发更新:
这里贴一下源码片段,咱可以感受下:
export class Observer {
value: any;
dep: Dep;
vmCount: number; // number of vms that has this object as root $data
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
...
}
walk (obj: Object) {
...
}
observeArray (items: Array) {
...
}
}
有没有觉得和上面提到的“发布订阅者模式”中的相似。Observer 首先实例化 Dep 对象,接着通过执行 def 函数把自身实例添加到数据对象 value 的 ob 属性上。(def 函数是一个简单的对 Object.defineProperty 的封装)。
Dep
Dep 是整个 getter 依赖收集的核心。

由于 Watcher 是有多个的,所以需要用 Dep 收集变化之后集中管理,再通知到对应的 Watcher。由此也好理解 Dep 是依赖于 Watcher 的。
贴源码片段,感受一下:
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array;
constructor () {
this.id = uid++
this.subs = []
}
addSub (sub: Watcher) {
this.subs.push(sub)
}
removeSub (sub: Watcher) {
remove(this.subs, sub)
}
depend () {
if (Dep.target) {
Dep.target.addDep(this)
}
}
notify () {
// stabilize the subscriber list first
...
}
Watcher
贴源码片段,感受一二:
export default class Watcher {
vm: Component;
expression: string;
cb: Function;
id: number;
deep: boolean;
user: boolean;
computed: boolean;
sync: boolean;
dirty: boolean;
active: boolean;
dep: Dep;
deps: Array;
newDeps: Array;
depIds: SimpleSet;
newDepIds: SimpleSet;
before: ?Function;
getter: Function;
value: any;
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
this.vm = vm
if (isRenderWatcher) {
vm._watcher = this
}
vm._watchers.push(this)
// options
...
// parse expression for getter
...
}
get () {
pushTarget(this)
...
}
addDep (dep: Dep) {
const id = dep.id
...
}
cleanupDeps () {
...
}
// ...
}
Watcher 会通知视图的更新 re-render。
常见视图更新场景:
- 数据变 → 使用数据的视图变(对应:负责敦促视图更新的render-watcher)
- 数据变 → 使用数据的计算属性变 → 使用计算属性的视图变(对应:执行敦促计算属性更新的computed-watcher)
- 数据变 → 开发者主动注册的watch回调函数执行(对应:用户注册的普通watcher(watch-api或watch属性))
四、组件编译
组件的思想也是 Vue 核心,将组件编译为 vdom ,则也是一重难点!

你可以发现在 Vue 这一节有很多引用的图,其实它们有的相似,更多的是侧重点不同,建议都可按照流程图理解理解,做到融会贯通。
组件
官方示例:
// 定义一个名为 button-counter 的新组件
Vue.component('button-counter', {
data: function () {
return {
count: 0
}
},
template: ''
})
组件还涉及:组件之间的通信、插槽、动态组件等内容。后续再表(OS:
这是自己给自己挖了个多大的坑)。
parse
编译过程首先就是对模板做解析,生成 AST,它是一种抽象语法树,是对源代码的抽象语法结构的树状表现形式。在很多编译技术中,如 babel 编译 ES6 的代码都会先生成 AST。这个过程会用到大量的正则表达式对字符串解析,源码很难读。
但是我们需要知道的是 start、end、comment、chars 四大函数。
对于普通标签的处理流程大致:
- 识别开始标签,生成匹配结构match。
- 处理attrs,将数组处理成 {name:‘xxx’,value:‘xxx’}
- 生成astElement,处理for,if和once的标签。
- 识别结束标签,将没有闭合标签的元素一起处理。
- 建立父子关系,最后再对astElement做所有跟Vue 属性相关对处理。slot、component等等。
参考阅读:Vue parse之 从template到astElement 源码详解
optimize
当我们的模板 template 经过 parse 过程后,会输出生成 AST 树,那么接下来我们需要对这颗树做优化 —— optimize。
optimize 中最重要的是标记静态根(markStaticRoots )、静态节点(markStatic )。如果是静态节点则它们生成的DOM永远不需要改变,这让模板的更新更搞笑(不变的节点不用更新)。
问题:为什么子节点的元素类型是静态文本类型,就会给 optimize 过程加大成本呢?
首先来分析一下,之所以在 optimize 过程中做这个静态根节点的优化,目的是什么,成本是什么?目的:在 patch 过程中,减少不必要的比对过程,加速更新。
成本:a. 需要维护静态模板的存储对象。b. 多层render函数调用。
推荐阅读
codegen
编译的最后一步就是把优化后的 AST 树转换成可执行的代码,即在 codegen 环节。
主要步骤(调用函数):
- generate
- genIf
- genFor
- genData & genChildren
此节考的不多,仅做了解。了解更多,得看源码。
五、常用补充
keep-alive(常考)
keepalive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,或避免重新渲染 。也就是所谓的组件缓存。
v-if、v-show、v-for
三个高频子问题:
- v-if、v-show 区别?
答:v-if 相当于 display; v-show 相当于 visibility; 前者会控制是否创建,后者仅控制是否隐藏显示。
- v-if、v-for 为什么不能放一起用?
答:因为 v-for 优先级比 v-if 高,所以在每次重新渲染的时候会先遍历整个列表,再进行 if 判断是否展示,消耗性能。
- v-for 中能用 index 作 key 吗?
答:key 是 diff 算法中用来对比的,用 index 作为 key 并未唯一识别,当插入元素时,key 也会变化。index 作为 key,只适用于不依赖子组件状态或临时 DOM 状态 (例如:表单输入值) 的列表渲染输出(官网说明)。
本瓜这里不做细答,想了解更多请自行解决。
自定义指令
Vue 中的混入(Minxin)、自定义指令(directive)、过滤器(filter)有共通之处,在注册的时候,需要平衡局部注册和全局注册的优劣。
transition
本瓜读源码的过程中,发现源码中有较大的篇幅在描述关于transition。在官方文档中,transition 也是作为独立的重要一节来说明。进入/离开 & 列表过渡,Vue 动画&过渡,是容易忽视的点。
六、全家桶
自从用上了 Vue 全家桶,腿也不疼了,腰也不酸了。咦,一口气写五个页面,妈妈再也不用担心我的学习了。(好像有点串广告了…)
Vue-Router
官方的路由管理器
分为两种模式:hash 和 history
- 默认 hash 模式,通过加锚点的方式
- history 利用 history.pushState API实现
原生:
HTML5引入了 history.pushState() 和 history.replaceState() 方法,它们分别可以添加和修改历史记录条目。这些方法通常与window.onpopstate 配合使用。详情链接
Vuex
官方状态管理
由以下几部分核心组成:
- state:数据状态;
- mutations:更改状态(计算状态);
- getters:将state中的某个状态进行过滤然后获取新的状态;
- actions:执行多个mutation,它可以进行异步操作(async );
- modules:把状态和管理规则分类来装,让目录结构更清晰;
VueCLI
官方脚手架
- VueCLI4中很重要的是 vue.config.js 这个文件的配置。
VuePress
静态网站生成器
- 采用 Vue + webpack,可以在 Markdown 中使用 Vue 组件,页面简洁大方,与 Vue 官网风格统一。
NuxtJS
服务端渲染
七、webpack
只要你做前端有两年经验左右,那一样就得要求自己掌握一款打包工具了。
webpack 原理
官方解释:
webpack 是一个现代 JavaScript 应用程序的静态模块打包工具。当 webpack 处理应用程序时,它会在内部构建一个 依赖图(dependency graph),此依赖图会映射项目所需的每个模块,并生成一个或多个_bundle_。
核心概念:
- Entry:入口,Webpack 执行构建的第一步将从 Entry 开始,可抽象成输入。
- Module:模块,在 Webpack 里一切皆模块,一个模块对应着一个文件。Webpack 会从配置的 Entry 开始递归找出所有依赖的模块。
- Chunk:代码块,一个 Chunk 由多个模块组合而成,用于代码合并与分割。
- Loader:模块转换器,用于把模块原内容按照需求转换成新内容。
- Plugin:扩展插件,在 Webpack 构建流程中的特定时机会广播出对应的事件,插件可以监听这些事件的发生,在特定时机做对应的事情。
功能:
代码转换、文件优化、代码分割、模块合并、自动刷新、代码校验、自动发布。
优化打包速度
- 搭载 webpack-parallel-uglify-plugin 插件,加速“压缩JS=>编译成 AST=>还原JS”的过程。
- 使用 HappyPack 提升 loader 解析速度。
- 使用 DLLPlugin 和 DLLReferencePlugin 插件,提前打包。
- tree-shaking 用来消除无用模块。
AMD、CMD
前端模块化有四种规范:CommonJS、AMD、CMD、ES6。
- AMD(异步模块定义)
- CMD(通用模块定义)
| AMD(异步模块定义) | CMD(通用模块定义) |
|---|---|
| 速度快 | 性能较差 |
| 会浪费资源 | 只有真正需要才加载依赖 |
| 预先加载所有的依赖,直到使用的时候才执行 | 直到使用的时候才定义依赖 |
-
Node.js是commonJS规范的主要实践者:module、module.exports(exports)、require、global。
-
ES6 在语言标准的层面上,实现了模块功能,主要由两个命令构成:export和import。export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。
问:比较 import 和 require 的区别?
| import | require |
|---|---|
| ES6标准中的模块化解决方案 | 是node中遵循CommonJS规范的模块化解决方案 |
| 不支持动态引入 | 支持动态引入 |
| 是关键词 | 不是关键词 |
| 编译时加载,必须放在模块顶部 | 运行时加载,理论上来说放在哪里都可以 |
| 性能较好 | 性能较差 |
| 实时绑定方式,即导入和导出的值都指向同一个内存地 | 导出时是值拷贝,就算导出的值变化了,导入的值也不会变化 |
| 会编译成require/exports来执行 | - |
更多:前端模块化:CommonJS,AMD,CMD,ES6
实现plugin插件(腾讯WXG考点)
- 创建 plugins/demo-plugin.js 文件;
- 传递参数 Options;
- 通过 Compilation 写入文件;
- 管理 Warnings 和 Errors
从零实现一个 Webpack Plugin
串联四:
你最喜欢什么算法?
其实本瓜想回答:我最喜欢减法!因为幸福生活需要用减法。
算法这一个 part 也已久远,既然逃不掉,那就正面挑战它!其实也没那么难。
一图胜万言
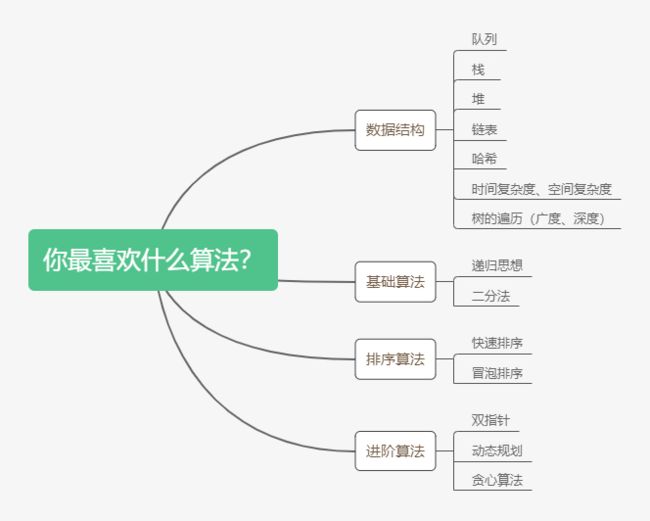
- 原创脑图,转载请说明出处
串联知识点:数据结构、基础算法、排序算法、进阶算法。
串联记忆:
算法算法我不怕
数据结构打趴下
遍历排序我最溜
指针动态贪心刷
一、数据结构
队列
先入先出。
栈
先入后出。
堆
堆通常是一个可以被看做一棵树的数组对象。
堆总是满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
- 完全二叉树:在一颗二叉树中,若除最后一层外的其余层都是满的,并且最后一层要么是满的,要么在右边缺少连续若干节点,则此二叉树为完全二叉树(Complete Binary Tree)—— wiki。
(本瓜曾被拷问过这个点,大厂就是会考《数据结构》,别逃避,出来混迟早是要还的)。
链表
- 循环列表(考点)
// 循环链表
function Node(element){
this.element = element;
this.prev = null;
this.next = null;
}
function display(){
var current = this.head;
//检查头节点当循环到头节点时退出循环
while(!(current.next == null) && !(current.next.element=='head')){
print(current.next.element);
current = current.next;
}
}
function Llist(){
this.head = new Node('head');
this.head.next = this.head;
this.find = find;
this.insert = insert;
this.display = display;
this.findPrevious = findPrevious;
this.remove = remove;
}
哈希
散列函数(英语:Hash function)又称散列算法、哈希函数。以 Key:Value 的方式存储数据。
哈希表最大的特点是可以快速定位到要查找的数据,查询的时间复杂度接近O(1)。本瓜建议大家可以把这里所有的数据结构的“增删改查”操作的时间复杂度都理一下,也是会被考的。
时间复杂度、空间复杂度
简单理解:
- 循环的次数写成 n 的表达式,就是时间复杂度。
- 申请的变量数量写成 n 的表达式,就是空间复杂度。
时间复杂度更多重要一点,常见的时间复杂度:O(1)、O(n)、O(logn)、O(n2)。本瓜小TIP:面试/笔试如果不知道怎么算,就在这里面猜吧。实在不行就答:O(n) ~ O(n2) 之间,大概率不会错。
树的遍历(广度、深度)
广度优先遍历(BFS):
需要用到队列(Queue)来存储节点对象,队列的特点就是先进先出。示例
深度优先遍历(DFS):
- 前序(根结点 -> 左子树 -> 右子树)
- 中序(左子树 -> 根结点 -> 右子树)
- 后序(左子树 -> 右子树 -> 根结点)
二、基础算法
递归思想
- 著名的斐波那契数列,你要知道!
function result(){
if(n==1||n==2){
return 1
}
return reslt(n-2)+result(n-1)
}
- 函数柯里化,你也要知道!
函数柯里化:是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。—— wiki
// 普通方式
var add1 = function(a, b, c){
return a + b + c;
}
// 柯里化
var add2 = function(a) {
return function(b) {
return function(c) {
return a + b + c;
}
}
}
// demo
var foo = function(x) {
return function(y) {
return x + y
}
}
foo(3)(4) // 7
这样处理参数,可以直接追加,而不需要初始传参就写完全。这里只是浅谈,更多请自行探索。
二分法
要求手写二分法,实在不行,能默写也可以啊!
// 二分法:先排序,再找目标
function binary_search(arr,target) {
let min=0
let max=arr.length-1
while(min<=max){
let mid=Math.ceil((min+max)/2)
if(arr[mid]==target){
return mid
}else if(arr[mid]>target){
max=mid-1
}else if(arr[mid]三、排序算法
排序是比较常用也比较重要的一块,此处并未全列出。仅强调快排和冒泡,会用双循环也行啊。
快速排序
// 快排:选取基准,比基准大的放右边,比基准小的放左边,然后两边用递归
function quickSort(arr, i, j) {
if(i < j) {
let left = i;
let right = j;
let pivot = arr[left];
while(i < j) {
while(arr[j] >= pivot && i < j) { // 从后往前找比基准小的数
j--;
}
if(i < j) {
arr[i++] = arr[j];
}
while(arr[i] <= pivot && i < j) { // 从前往后找比基准大的数
i++;
}
if(i < j) {
arr[j--] = arr[i];
}
}
arr[i] = pivot;
quickSort(arr, left, i-1);
quickSort(arr, i+1, right);
return arr;
}
}
冒泡排序
// 冒泡:双层循环
var arr=[10,20,50,100,40,200];
for(var i=0;iarr[j+1]){
var temp=arr[j]
arr[j]=arr[j+1]
arr[j+1]=temp
}
}
}
console.log(arr)
四、进阶算法
双指针
看到“有序”和“数组”。立刻把双指针法调度进你的大脑内存。普通双指针走不通,立刻想对撞指针!
示例:合并两个有序数组(双指针解法)
示例: 输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
输出: [1,2,2,3,5,6]
/**
* @param {number[]} nums1
* @param {number} m
* @param {number[]} nums2
* @param {number} n
* @return {void} Do not return anything, modify nums1 in-place instead.
*/
const merge = function(nums1, m, nums2, n) {
// 初始化两个指针的指向,初始化 nums1 尾部索引k
let i = m - 1, j = n - 1, k = m + n - 1
// 当两个数组都没遍历完时,指针同步移动
while(i >= 0 && j >= 0) {
// 取较大的值,从末尾往前填补
if(nums1[i] >= nums2[j]) {
nums1[k] = nums1[i]
i--
k--
} else {
nums1[k] = nums2[j]
j--
k--
}
}
// nums2 留下的情况,特殊处理一下
while(j>=0) {
nums1[k] = nums2[j]
k--
j--
}
};
高级!
动态规划
动态规划的思想就是把一个大的问题进行拆分,细分成一个个小的子问题,且能够从这些小的子问题的解当中推导出原问题的解。
同时需要满足以下两个重要性质才能进行动态规划:
- 最优子结构性
- 子问题重叠性质
动态规划实例:斐波拉契数列(上文有提到)
斐波拉契数列:采用递归,虽然代码很简洁,但是明显随着次数的增加,导致递归树增长的非常庞大,耗时较久。
用动态规划实现斐波拉契数列,代码如下
function feiBoLaQie(n) {
//创建一个数组,用于存放斐波拉契数组的数值
let val = [];
//将数组初始化,将数组的每一项都置为0
for(let i =0 ;i<=n;i++){
val[i] = 0;
}
if (n==1 || n==2){
return 1;
} else{
val[1] = 1;
val[2] = 2;
for (let j =3; j<=n;j++){
val[j] = val[j-1] + val[j-2];
}
}
return val[n-1];
}
console.log(feiBoLaQie(40));//102334155
通过数组 val 中保存了中间结果, 如果要计算的斐波那契数是 1 或者 2, 那么 if 语句会返回 1。 否则,数值 1 和 2 将被保存在 val 数组中 1 和 2 的位置。
循环将会从 3 到输入的参数之间进行遍历, 将数组的每个元素赋值为前两个元素之和, 循环结束, 数组的最后一个元素值即为最终计算得到的斐波那契数值, 这个数值也将作为函数的返回值。
动态规划解决速度更快。
- 参考阅读
- 更多动态规划示例
贪心算法
贪心算法遵循一种近似解决问题的技术,期盼通过每个阶段的局部最优选择(当前最好的解),从而达到全局的最优(全局最优解)。
注:贪心得到结果是一个可以接受的解,不一定总是得到最优的解。
示例:最少硬币找零问题
是给出要找零的钱数,以及可以用硬币的额度数量,找出有多少种找零方法。
如:美国面额硬币有:1,5,10,25
我们给36美分的零钱,看能得怎样的结果?
function MinCoinChange(coins){
var coins = coins;
var cache = {};
this.makeChange = function(amount){
var change = [], total = 0;
for(var i = coins.length; i >= 0; i--){
var coin = coins[i];
while(total + coin <= amount){
change.push(coin);
total += coin;
}
}
return change;
}
}
var minCoinChange = new MinCoinChange([1, 5, 10, 25]);
minCoinChange.makeChange(36);
//[25, 10, 1] 即一个25美分、一个10美分、一个1美分
串联五:
web 安全你知道那些?
一图胜万言

- 原创脑图,转载请说明出处
串联知识点:跨域、XSS(跨站脚本攻击)、CRFS(跨站请求伪造)、SQL 注入、DNS 劫持、HTTP 劫持。
串联记忆:三跨两劫持一注入
一、跨域
跨域定义
当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域。
跨域限制 是浏览器的一种保护机制,若跨域,则:
- 无法读取非同源网页的 Cookie、LocalStorage 和 IndexedDB。
- 无法接触非同源网页的 DOM。
- 无法向非同源地址发送 AJAX 请求
跨域解决
跨域解决:
- JSONP;
- CORS(跨域资源分享);
// 普通跨域请求:只需服务器端设置 Access-Control-Allow-Origin。
// 带cookie跨域请求:前后端都需要进行设置。
// 如前端在 axios 中设置
axios.defaults.withCredentials = true
- vue项目 设置 proxy 代理;
- nginx 代理;
- 设置document.domain解决无法读取非同源网页的 Cookie问题;
- 跨文档通信 API:window.postMessage();
二、XSS
XSS 原理
XSS的原理是WEB应用程序混淆了用户提交的数据和JS脚本的代码边界,导致浏览器把用户的输入当成了JS代码来执行。XSS的攻击对象是浏览器一端的普通用户。
示例:
">
您搜索的关键词是:<%= getParameter("keyword") %>
当浏览器请求
http://xxx/search?keyword=">
恶意代码,就会其执行
反射型 XSS
存储型 XSS 的攻击步骤:
- 攻击者将恶意代码提交到目标网站的数据库中。
- 用户打开目标网站时,网站服务端将恶意代码从数据库取出,拼接在 HTML 中返回给浏览器。
- 用户浏览器接收到响应后解析执行,混在其中的恶意代码也被执行。
- 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
这种攻击常见于带有用户保存数据的网站功能,如论坛发帖、商品评论、用户私信等。
存储型 XSS
反射型 XSS 的攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。
- 用户打开带有恶意代码的 URL 时,网站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。
- 用户浏览器接收到响应后解析执行,混在其中的恶意代码也被执行。
- 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
反射型 XSS 跟存储型 XSS 的区别是:存储型 XSS 的恶意代码存在数据库里,反射型 XSS 的恶意代码存在 URL 里。
DOM型 XSS
DOM 型 XSS 的攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。
- 用户打开带有恶意代码的 URL。
- 用户浏览器接收到响应后解析执行,前端 JavaScript 取出 URL 中的恶意代码并执行。
- 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
DOM 型 XSS 跟前两种 XSS 的区别:DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞,而其他两种 XSS 都属于服务端的安全漏洞。
XSS 防御
- 输入过滤,不要相信任何客户端的输入;
- 对 HTML 做充分转义;
- 设置 HTTP-only:禁止 JavaScript 读取某些敏感 Cookie,攻击者完成 XSS 注入后也无法窃取此 Cookie。
- 验证码:防止脚本冒充用户提交危险操作。
- 谨慎使用:.innerHTML、.outerHTML、document.write();
三、CSRF
CSRF 原理
跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
曾在 09 年发生了著名的“谷歌邮箱窃取”事件,利用的就是 “CSRF”。
主要流程:
- 受害者登录a.com,并保留了登录凭证(Cookie)。
- 攻击者引诱受害者访问了b.com。
- b.com 向 a.com 发送了一个请求:a.com/act=xx。浏览器会默认携带a.com的Cookie。
- a.com接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求。
- a.com以受害者的名义执行了act=xx。
- 攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让a.com执行了自己定义的操作。
注:攻击者无法直接窃取到用户的信息(Cookie,Header,网站内容等),仅仅是冒用 Cookie 中的信息。
这告诉我们冲浪的时候不能随便点链接,是有风险哒。
CSRF 防御
防御策略:
- 自动防御策略:同源检测(Origin 和 Referer 验证)。
- 主动防御措施:Token验证 或者 双重Cookie验证 以及配合Samesite Cookie。
- 保证页面的幂等性,后端接口不要在GET页面中做用户操作。
四、SQL 注入
SQL 注入原理
Sql 注入攻击是通过将恶意的 Sql 查询或添加语句插入到应用的输入参数中,再在后台 Sql 服务器上解析执行进行的攻击,它目前黑客对数据库进行攻击的最常用手段之一。
SQL 注入防御
防御:用sql语句预编译和绑定变量,是防御sql注入的最佳方法。还可以通过严格检查参数的数据类型的方式来防御。
五、DNS 劫持
DNS 劫持原理
DNS劫持又称域名劫持,是指在劫持的网络范围内拦截域名解析的请求,分析请求的域名,把审查范围以外的请求放行,否则返回假的IP地址或者什么都不做使请求失去响应,其效果就是对特定的网络不能访问或访问的是假网址。其实本质就是对DNS解析服务器做手脚
DNS 劫持防御
解决办法:
DNS的劫持过程是通过攻击运营商的解析服务器来达到目的。我们可以不用运营商的DNS解析而使用自己的解析服务器或者是提前在自己的App中将解析好的域名以IP的形式发出去就可以绕过运营商DNS解析,这样一来也避免了DNS劫持的问题。
六、HTTP 劫持
HTTP 劫持原理
在运营商的路由器节点上,设置协议检测,一旦发现是HTTP请求,而且是html类型请求,则拦截进行恶意处理。
常见有两种:
- 类似DNS劫持返回302让用户浏览器跳转到另外的地址。(钓鱼网站就是这么干)
- 在服务器返回的HTML数据中插入js或dom节点(广告)。(常见)
HTTP 劫持防御
防御方法:
- 使用HTTPS;
- 使用禁止转码申明;
- 在开发的网页中加入代码过滤:用 js 检查所有的外链是否属于白名单;
- 联系运营商;
这一 part 更多的是概念上的东西,不求完全记住,但是也要大致上能说一下。咱老话说的好:知之为知之 不知为不知,面试官在非关键性的问题上是不做严格要求的,千万别满嘴跑火车或者直接说不知道,这是两个极端,都不可取。
小结
显然,前端面试“串联”问题不仅局限以上,本瓜会继续按照这个“串联联想”的思路去整理,不断去打破体系、形成体系(自己给自己挖的天坑呐)。期待在这个反复的过程中找寻真理的痕迹!
如果你对此文有更多想法(持续完善中),或是想与本瓜同行,可以加![]() Ifuckinghigh,期待更多交流 ~
Ifuckinghigh,期待更多交流 ~
我是掘金安东尼,一个会持续输出的个人站长。