Spring boot集成ElasticSearch功能
ElasticSearch简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
ElasticSearch安装
本文仅介绍windows下单机部署,单机部署非常简单,只需要下载ElasticSearch对版本的zip包,解压直接执行解压目录下的elasticsearch.bat文件即可,前提是环境变量配置好JAVA_HOME,且版本正确即可。
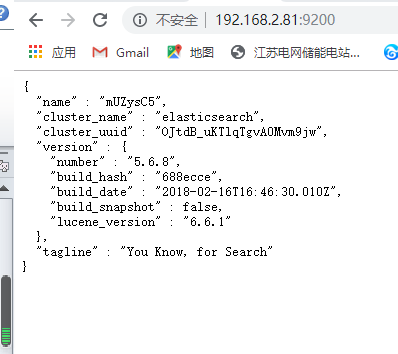
打开浏览器输入http://localhost:9200/出现一下结果就表示启动成功。
基于JPA方式实现集成
本文介绍的都是基于Spring boot的集成,其他的不考虑。
首先maven配置中增加spring-boot-starter-data-elasticsearch 依赖。
org.springframework.boot
spring-boot-starter-data-elasticsearch
然后就可以开始我们的开发了
和JPA类似,创建一个DTO和Mapper
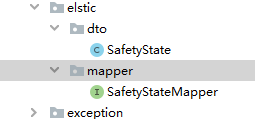
创建一个Entity文件,关联到ES中的document,

增加Document注解,indexName表示关联的索引名称,type是类型名称,类似数据库中的库和表。
注意:需要一个id字段,或者可以通过@Id注解,否则会执行不通过。这里有个问题,如果使用JPA方式的话,由于插入需要比较找个id,因此如果数据量大的话,会查询是否主键冲突,一次数据量大的情况下,我这里出现到后来,插入效率显著变低的情况。
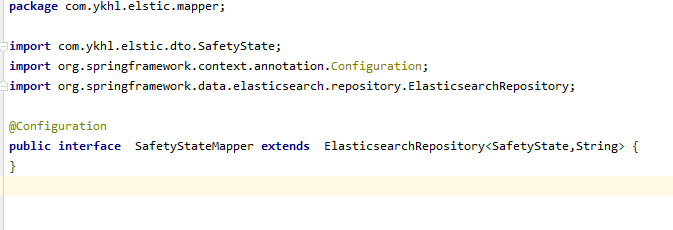
然后创建一个Mapper,继承ElasticsearchRepository,一行代码不需要写。
然后,注入这个对象,就可以和操作数据一样来对索引进行增加、删除、查询了,支持分页和排序。
使用ElasticsearchTemplate
由于,实际开发过程中发现随着插入的数据越来越多,插入速度越来越慢。因此将索引按时间存放了,JPA方式只能绑定固定的索引,因此采用了ElasticsearchTemplate方式来插入和查询。
批量插入数据
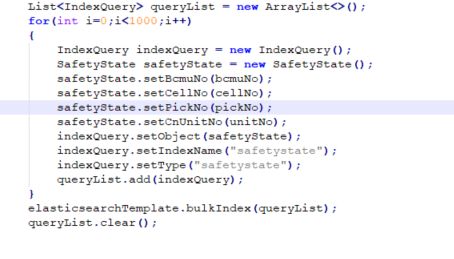
创建一个querylist,然后往里面填数据indexQuery,最后elasticsearchTemplate.bulkIndex批量将数据插入,这里得考虑内存消耗问题,如果超过一定的阈值的话,需要分批插入,否则可能会内存溢出。一般来说一秒钟大概是1W条数据。
2.查询
如下图

首先创建一个BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery;
根据需求不同增加如下内容
queryBuilder.must(QueryBuilders.termQuery(columName, value));
表示必须满足column对应的值为value的情况,该对象还有mustnot和should。mustnot大家都知道表示不等于,should是多个条件,只要满足一条即可。
创建一个Pageable对象
pageable = PageRequest.of(pagefrom(从第几页开始), pagesize(每一页多少条), Sort.Direction.DESC(排序方式), [“time”,”name”]排序字段));
然后创建一个NativeSearchQuery对象
searchQuery = new NativeSearchQueryBuilder
.withIndices(“indeces”) //索引名称
.withTypes(“type”) //type名称
.withQuery(queryBuilder)// 查询条件
.withPageable(pageable)//增加分页方式
.build;
然后开始执行查询
AggregatedPage aggregatedPage = elasticsearchTemplate.queryForPage(searchQuery, SafetyState.class);第一个参数是上面创建的查询条件,第二个是对应的实体类。这个查询包括了查询了多少条,当前为第几页等信息。aggregatedPage.getContent可以获得查询出来的结果。
也可以queryforlist方法,这个直接返回查询结果列表。
聚合查询

和查询类似首先创建一个查询条件
其次创建一个TermsAggregationBuilder,表示分组。
再次创建ValueCountAggregationBuilder对象,该对象表示统计个数,其他还有AvgAggregationBuilder等汇聚方式,可查看AggregationBuilders对象的工厂方法。

然后将汇聚countAgg,增加为agg分组的子聚合aggTime.subAggregation(countAgg);分组后面需要增加size否则只会查出10条数据。
从查询结果里面取数据比较啰嗦,大家可以参考我贴图修改既可以
bucket.getKeyAsString, bucket.getDocCount),for循环中中获取bucket的key就是汇聚分组字段值,docCount就是分组统计结果,我这里是统计的个数,写的是count。
注意事项
ElasticsearchTemplate查询如果不指定大小只会展示10条,page查询中可以设置pagesize和pagefrom来获取,聚合查询指定size来指定。
ElasticsearchTemplate 如果和radis一起使用的话,要在启动方法中增加System.setProperty("es.set.netty.runtime.available.processors","false");否则启动的时候会有报错:availableProcessors is already set to [8]
JPA方式插入索引,一定要指定id字段,且为全局唯一,否则会有插入失败的问题。
如果插入的对象有id值,插入效率会越来越低,因为需要判断key是否重复,并且生成的索引会比较大。
为了减少插入时间则需要让ES自动生成ID,目前来看只有ElasticsearchTemplate可以实现。
ES的查询效率还是可以的4千万条数据的查询在秒级