注意力机制代码_深入理解图注意力机制

我和人民邮电出版社搞了图神经网络的课程,刚上线,打折中。。。有兴趣的可以看一下 https://www.epubit.com/courseDetails?id=PCC72369cd0eb9e7


本文主要从下面3个方面分析了 18ICLR 图注意力网络 Graph Attention Network, 并附上了代码解析.
- 非对称的注意权重
- 可有可无的LeakyRelu?
- Transformer Vs GAT
介绍
图神经网络已经成为深度学习领域最炽手可热的方向之一。作为一种代表性的图卷积网络,Graph Attention Network (GAT)引入了注意力机制来实现更好的邻居聚合。 通过学习邻居的权重,GAT可以实现对邻居的加权聚合。因此,GAT不仅对于噪音邻居较为鲁棒,注意力机制也赋予了模型一定的可解释性。
下图概述了Graph Attention Network主要做的事情。
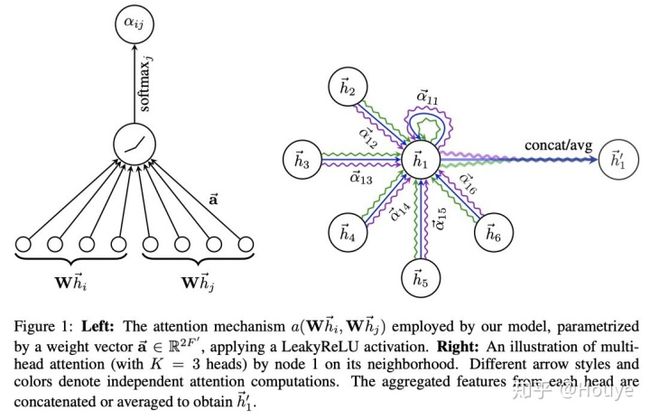
针对节点
深入理解图注意力机制
非对称的注意权重
首先,介绍下如何学习节点对
其中,
注意力网络可以有很多的设计方式,这里作者将节点
除了拼接操作以外,聚合邻居信息时,需要对每个节点的所有邻居的注意力进行归一化。归一化之后的注意力权重
这里的归一化进一步导致了注意力权重的非对称性。因为在归一化的过程中,每个节点的归一化对象并不一样。
综上,在求解注意力权重
这种非对称性在图数据上有什么用呢?一个简单的例子:在社交网络中,有一个大V和一个普通用户互相关注。但是,大V对于普通用户的重要性和普通用户对大V的重要性明显是不一样的。
完整的图注意力公式如下:
也有文章18ArXiv_AGNN_Attention-based Graph Neural Network for Semi-supervised Learning尝试为节点对
这里,
可有可无的LeakyRelu?
在求
我们先拿掉LeakyReLU,再看一下公式中最核心的一项
假设注意力向量
如果在没有LeakyReLU的时候对邻居进行归一化
也就是说,分子分母同时约去了节点
如果加上激活函数
后面的归一化就不会约去节点
这里对原始GAT论文中的公式进行了展开解读,一是为了更深入的理解图注意力机制,二是后面的代码解读需要用到这种展开。
Transformer Vs GAT
NLP中大火的Transformer和GAT本质在做一样的事情。Transformer利用self-attention机制将输入中的每个单词用其上下文的加权来表示,而GAT是利用self-attention机制将每个节点用其邻居的加权来表示。下面是经典的Transformer公式,
这里的
因此,
上述过程和GAT的核心思想非常相似:都是通过探索输入之间的关联性(注意力权重),通过对上下文信息(句子上下文/节点邻居)进行聚合,来获得各个输入(单词/节点)的表示。
Transformer和GAT的主要区别是:
- 在GAT中,作者对自注意力进行了简化。每个节点无论是作为中心节点/上下文/聚合输出,都只用一种表示
。也就是说,在GAT中,
。
- 在图上,节点的邻居是一个集合,具有不变性。Transformer将文本隐式的建图过程中丢失了单词之间的位置关系,这对NLP的一些任务是很致命的。为了补偿这种建图损失的位置关系,Transformer用了额外了的位置编码来描述位置信息。
核心代码解读
Graph Attention Network的作者开源了代码 https://github.com/PetarV-/GAT。但是,这份代码对于初学者来说较难理解。这里对GAT的核心代码进行简要的解读和介绍。
作者在GAT/utils/layers.py中的attn_head实现了GAT核心模块:注意力机制。
def attn_head(seq, out_sz, bias_mat,
activation, in_drop=0.0, coef_drop=0.0, residual=False):
这里有3个比较核心的参数:
- seq 指的是输入的节点特征矩阵,大小为[num_graph, num_node, fea_size]
- out_sz指的是变换后的节点特征维度,也就是
后的节点表示维度。
- bias_mat是经过变换后的邻接矩阵,大小为[num_node, num_node]。
作者首先将原始节点特征seq进行变换得到了seq_fts。这里,作者使用卷积核大小为1的1D卷积模拟投影变换,投影变换后的维度为out_sz。注意,这里投影矩阵
seq_fts = tf.layers.conv1d(seq, out_sz, 1, use_bias=False)
也就是说,seq_fts的大小为[num_graph, num_node, out_sz]。
回顾前面的公式展开
f_1 = tf.layers.conv1d(seq_fts, 1, 1)
f_2 = tf.layers.conv1d(seq_fts, 1, 1)
经过tf.layers.conv1d(seq_fts, 1, 1)之后的f_1和f_2维度均为[num_graph, num_node, 1]。
将f_2转置之后与f_1叠加,通过广播得到的大小为[num_graph, num_node, num_node]的logits,就是一个注意力矩阵,
按照GAT的公式,我们只要对logits进行softmax归一化就可以拿到注意力权重
coefs = tf.nn.softmax(tf.nn.leaky_relu(logits) + bias_mat)
因为的logits存储了任意两个节点之间的注意力值,但是,归一化只需要对每个节点的所有邻居的注意力进行(下式标红的部分)。所以,引入了bias_mat就是将softmax的归一化对象约束在每个节点的邻居上,如下式的红色部分。
那么,bias_mat是如何实现的呢?直接的想法就是只含有0,1的邻接矩阵与注意力矩阵相乘,从而对邻居进行mask。但是,直接用0,1mask会有问题。
假设注意力权值[1.2, 0.3, 2.4]经过[0,1,1]的乘法mask得到[0, 0.3, 2.4],再送入到softmax归一化,实际上变为
作者这里用一个很大的负数,如
def adj_to_bias(adj, sizes, nhood=1):
...
...
return -1e9 * (1.0 - mt)
然后,将bias_mat和注意力矩阵相加,进而将非节点邻居进行mask。
例如,[1.2, 0.3, 2.4]经过
因为
vals = tf.matmul(coefs, seq_fts)
代码中的train_mask,val_mask,test_mask
train_mask,val_mask,test_mask是为了划分训练,验证和测试的。因为AX一次会得到所有节点的表示,但是计算loss只在部分节点上进行(训练集)。
总结
Graph Attention Network作为首次将图注意力机制引入到图神经网络中的工作,已经在很多领域得到了广泛应用。 受益于注意力机制,GAT能够过滤噪音邻居,提升模型表现并可以对结果实现一定的解释。
更多关于图神经网络/图表示学习/推荐系统, 欢迎关注我的公众号 【图与推荐】

